







1.背景
2024年,R Sowmya等人受到Newton-Raphson方法启发,提出了牛顿-拉弗森优化算法(Newton-Raphson-Based Optimizer, NRBO)。


2.算法原理
2.1算法思想
NRBO受到Newton-Raphson方法的启发,它使用两个规则来探索整个搜索过程:Newton-Raphson搜索规则(NRSR)和陷阱避免算子(TAO),并使用几组矩阵来进一步探索最佳结果。NRSR采用Newton-Raphson方法来提高NRBO的探索能力,提高收敛速度以达到改进的搜索空间位置。TAO帮助NRBO避免局部最优陷阱。
2.2算法过程
牛顿-拉弗森方法是一种在实数域和复数域上近似求解方程的方法,利用泰勒级数展开:
x
n
+
1
=
x
n
−
f
′
(
x
n
)
f
′
′
(
x
n
)
,
n
=
1
,
2
,
3
,
.
.
.
(1)
x_{n+1}=x_n-\frac{f'(x_n)}{f''(x_n)}, n=1,2,3,...\tag{1}
xn+1=xn−f′′(xn)f′(xn),n=1,2,3,...(1)
牛顿-拉弗森搜索规则 NRSR
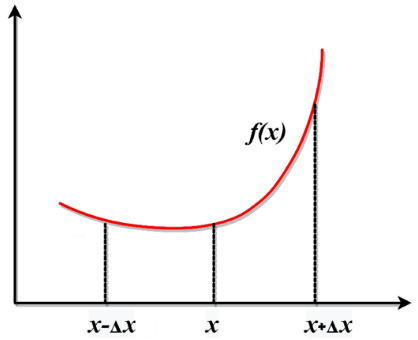
NRSR控制向量允许更准确地探索可行区域并获得更好的位置,二阶导数表述为:
f
(
x
+
Δ
x
)
=
f
(
x
)
+
f
′
(
x
0
)
Δ
x
+
1
2
!
f
′
′
(
x
0
)
Δ
x
2
+
1
3
!
f
′
′
(
x
0
)
Δ
x
3
+
⋯
f
(
x
−
Δ
x
)
=
f
(
x
)
−
f
′
(
x
0
)
Δ
x
+
1
2
!
f
′
′
(
x
0
)
Δ
x
2
−
1
3
!
f
′
′
(
x
0
)
Δ
x
3
+
⋯
(2)
\begin{gathered} f(x{+}\Delta x)= f(x)+f^{'}(x_{0})\Delta x+{\frac{1}{2!}}f^{''}(x_{0})\Delta x^{2}+{\frac{1}{3!}}f^{''}(x_{0})\Delta x^{3}+\cdots \\ f(x{-}\Delta x)= f(x)-f^{'}(x_{0})\Delta x+\frac{1}{2!}f^{''}(x_{0})\Delta x^{2}-\frac{1}{3!}f^{''}(x_{0})\Delta x^{3}+\cdots \end{gathered}\tag{2}
f(x+Δx)=f(x)+f′(x0)Δx+2!1f′′(x0)Δx2+3!1f′′(x0)Δx3+⋯f(x−Δx)=f(x)−f′(x0)Δx+2!1f′′(x0)Δx2−3!1f′′(x0)Δx3+⋯(2)
上述整理可得f’(x),f’'(x)表达式:
f
′
(
x
)
=
f
(
x
+
Δ
x
)
−
f
(
x
−
Δ
x
)
2
Δ
x
f
′
(
x
)
=
f
(
x
+
Δ
x
)
+
f
(
x
−
Δ
x
)
−
2
×
f
(
x
)
Δ
x
2
(3)
\begin{aligned} &f^{'}(x)= \frac{f(x+\Delta x)-f(x-\Delta x)}{2\Delta x} \\ &f^{^{\prime}}(x)= \frac{f(x+\Delta x)+f(x-\Delta x)-2\times f(x)}{\Delta x^{2}} \end{aligned}\tag{3}
f′(x)=2Δxf(x+Δx)−f(x−Δx)f′(x)=Δx2f(x+Δx)+f(x−Δx)−2×f(x)(3)
位置更新:
x
n
+
1
=
x
n
−
(
f
(
x
n
+
Δ
x
)
−
f
(
x
n
−
Δ
x
)
)
×
Δ
x
2
×
(
f
(
x
n
+
Δ
x
)
+
f
(
x
n
−
Δ
x
)
−
2
×
f
(
x
n
)
)
(4)
x_{n+1}=x_n-\frac{(f(x_n+\Delta x)-f(x_n-\Delta x))\times\Delta x}{2\times(f(x_n+\Delta x)+f(x_n-\Delta x)-2\times f(x_n))}\tag{4}
xn+1=xn−2×(f(xn+Δx)+f(xn−Δx)−2×f(xn))(f(xn+Δx)−f(xn−Δx))×Δx(4)
NRSR是NRBO的主要组成部分,考虑基于种群搜索方式,进行一定修正:
N
R
S
R
=
r
a
n
d
n
×
(
X
w
−
X
b
)
×
Δ
x
2
×
(
X
w
+
X
b
−
2
×
x
n
)
(5)
\mathrm{NRSR}=randn\times\frac{(X_w-X_b)\times\Delta x}{2\times(X_w+X_b-2\times x_n)}\tag{5}
NRSR=randn×2×(Xw+Xb−2×xn)(Xw−Xb)×Δx(5)
其中,Xw为最差位置,Xb为最佳位置。δ的自适应系数平衡了探索和开发能力:
δ
=
(
1
−
(
2
×
I
T
M
a
x
I
T
)
)
5
(6)
\delta=\left(1-\left(\frac{2\times IT}{Max_IT}\right)\right)^5\tag{6}
δ=(1−(MaxIT2×IT))5(6)
Δx的表达:
Δ
x
=
r
a
n
d
(
1
,
d
i
m
)
×
∣
X
b
−
X
n
I
T
∣
(7)
\Delta x=rand(1,dim)\times\left|X_b-X_n{}^{IT}\right|\tag{7}
Δx=rand(1,dim)×
Xb−XnIT
(7)
Xb表示目前得到的最优解,NRSR表述为:
x
n
+
1
=
x
n
−
N
R
S
R
(8)
x_{n+1}=x_n-NRSR\tag{8}
xn+1=xn−NRSR(8)
参数ρ来改进所提出的NRBO的利用,该参数将种群引向正确的方向:
ρ
=
a
×
(
X
b
−
X
n
′
T
)
+
b
×
(
X
r
1
′
T
−
X
r
2
′
T
)
(9)
\rho=a\times\left(X_b-X_n^{\prime T}\right)+b\times\left(X_{r_1}^{\prime T}-X_{r_2}^{\prime T}\right)\tag{9}
ρ=a×(Xb−Xn′T)+b×(Xr1′T−Xr2′T)(9)
其中a和b是(0,1)之间的随机数,r1和r2是从总体中随机选择的不同整数。向量(Xn IT)的当前位置:
X
1
n
T
=
x
n
I
T
−
(
r
a
n
d
n
×
(
X
w
−
X
b
)
×
Δ
x
2
×
(
X
w
+
X
b
−
2
×
X
n
)
)
+
(
a
×
(
X
b
−
X
n
I
T
)
)
+
b
×
(
X
r
1
I
T
−
X
r
2
I
T
)
(10)
\begin{aligned} X1_{n}^{T}= x_{n}^{IT}-\left(randn\times\frac{(X_{w}-X_{b})\times\Delta x}{2\times(X_{w}+X_{b}-2\times X_{n})}\right)+\left(a\times\left(X_{b}-X_{n}{}^{IT}\right)\right) +b\times\left(X_{r_{1}}^{IT}-X_{r_{2}}^{IT}\right) \end{aligned}\tag{10}
X1nT=xnIT−(randn×2×(Xw+Xb−2×Xn)(Xw−Xb)×Δx)+(a×(Xb−XnIT))+b×(Xr1IT−Xr2IT)(10)
(Weerakoon and Fernando, 2000)提出的NRM进一步完善了NRSR:
N
R
S
R
=
r
a
n
d
n
×
(
y
w
−
y
b
)
×
Δ
x
2
×
(
y
w
+
y
b
−
2
×
x
n
)
y
w
=
r
1
×
(
M
e
a
n
(
Z
n
+
1
+
x
n
)
+
r
1
×
Δ
x
)
y
b
=
r
1
×
(
M
e
a
n
(
Z
n
+
1
+
x
n
)
−
r
1
×
Δ
x
)
Z
n
+
1
=
x
n
−
r
a
n
d
n
×
(
X
w
−
X
b
)
×
Δ
x
2
×
(
X
w
+
X
b
−
2
×
x
n
)
(11)
\begin{aligned} &\mathrm{NRSR}=randn\times\frac{(y_w-y_b)\times\Delta x}{2\times(y_w+y_b-2\times x_n)} \\ &y_w=r_1\times(\mathrm{Mean}(Z_{n+1}+x_n)+r_1\times\Delta x) \\ &y_b=r_1\times(\mathrm{Mean}(Z_{n+1}+x_n)-r_1\times\Delta x) \\ &Z_{n+1}= x_{n}-randn\times{\frac{(X_{w}-X_{b})\times\Delta x}{2\times(X_{w}+X_{b}-2\times x_{n})}} \end{aligned}\tag{11}
NRSR=randn×2×(yw+yb−2×xn)(yw−yb)×Δxyw=r1×(Mean(Zn+1+xn)+r1×Δx)yb=r1×(Mean(Zn+1+xn)−r1×Δx)Zn+1=xn−randn×2×(Xw+Xb−2×xn)(Xw−Xb)×Δx(11)
其中yw和yb为zn1和xn生成的两个向量的位置,NRSR表述为:
X
1
n
T
=
x
n
I
T
−
(
r
a
n
d
n
×
(
y
w
−
y
b
)
×
Δ
x
2
×
(
y
w
+
y
b
−
2
×
x
n
)
)
+
(
a
×
(
X
b
−
X
n
I
T
)
)
+
b
×
(
X
r
1
I
T
−
X
r
2
I
T
)
(12)
\begin{aligned} X1_{n}^{T}= x_{n}^{IT}-\left(randn\times{\frac{(y_{w}-y_{b})\times\Delta x}{2\times(y_{w}+y_{b}-2\times x_{n})}}\right)+\left(a\times\left(X_{b}-X_{n}{}^{IT}\right)\right) +b\times\left(X_{r_{1}}^{IT}-X_{r_{2}}^{IT}\right)\end{aligned}\tag{12}
X1nT=xnIT−(randn×2×(yw+yb−2×xn)(yw−yb)×Δx)+(a×(Xb−XnIT))+b×(Xr1IT−Xr2IT)(12)
通过最佳向量Xb构造新向量X2nIT:
X
2
n
T
=
X
b
−
(
r
a
n
d
n
×
(
y
w
−
y
b
)
×
Δ
x
2
×
(
y
w
+
y
b
−
2
×
x
n
)
)
+
(
a
×
(
X
b
−
X
n
I
T
)
)
+
b
×
(
X
r
1
I
T
−
X
r
2
I
T
)
(13)
\begin{aligned} X2_{n}^{T}= X_{b}-\left(randn\times{\frac{(y_{w}-y_{b})\times\Delta x}{2\times(y_{w}+y_{b}-2\times x_{n})}}\right)+\left(a\times\left(X_{b}-X_{n}{}^{IT}\right)\right) +b\times\left(X_{r_{1}}^{IT}-X_{r_{2}}^{IT}\right) \end{aligned}\tag{13}
X2nT=Xb−(randn×2×(yw+yb−2×xn)(yw−yb)×Δx)+(a×(Xb−XnIT))+b×(Xr1IT−Xr2IT)(13)
位置向量:
x
n
I
T
+
1
=
r
2
×
(
r
2
×
X
1
n
I
T
+
(
1
−
r
2
)
×
X
2
n
I
T
)
+
(
1
−
r
2
)
×
X
3
n
I
T
X
3
n
I
T
=
X
n
I
T
−
δ
×
(
X
2
n
I
T
−
X
1
n
I
T
)
(14)
\begin{aligned}&x_{n}^{IT+1}=r_{2}\times\left(r_{2}\times X1_{n}^{IT}+(1-r_{2})\times X2_{n}^{IT}\right)+(1-r_{2})\times X3_{n}^{IT}\\&X3_{n}^{IT}=X_{n}^{IT}-\delta\times\left(X2_{n}^{IT}-X1_{n}^{IT}\right)\end{aligned}\tag{14}
xnIT+1=r2×(r2×X1nIT+(1−r2)×X2nIT)+(1−r2)×X3nITX3nIT=XnIT−δ×(X2nIT−X1nIT)(14)
陷阱避免算子 TAO
TAO是采用(ahmadanfar等人,2020)改进和增强的优化方式,使用TAO可以显著改变x1n的位置。通过结合最佳位置Xb和当前矢量位置xitn,它产生了一个具有增强质量的解决方案:
{
X
T
A
O
T
T
=
X
n
T
T
+
1
+
θ
1
×
(
μ
1
×
x
b
−
μ
2
×
X
n
T
T
)
+
θ
2
×
δ
×
(
μ
1
×
M
e
a
n
(
X
T
T
)
−
μ
2
×
X
n
T
T
)
,
i
f
μ
1
<
0.5
X
T
A
O
T
T
=
x
b
+
θ
1
×
(
μ
1
×
x
b
−
μ
2
×
X
n
T
T
)
+
θ
2
×
δ
×
(
μ
1
×
M
e
a
n
(
X
T
T
)
−
μ
2
×
X
n
T
T
)
,
O
t
h
e
r
w
i
s
e
(15a)
\begin{cases}X_{TAO}^{TT}=X_{n}^{TT+1}+\theta_{1}\times\left(\mu_{1}\times x_{\mathrm{b}}-\mu_{2}\times X_{n}^{TT}\right)+\theta_{2}\times\delta\times\left(\mu_{1}\times\mathrm{Mean}\left(X^{TT}\right)-\mu_{2}\times X_{n}^{TT}\right), \mathrm{if} \mu_{1}<0.5\\X_{TAO}^{TT}=x_{\mathrm{b}}+\theta_{1}\times\left(\mu_{1}\times x_{\mathrm{b}}-\mu_{2}\times X_{n}^{TT}\right)+\theta_{2}\times\delta\times\left(\mu_{1}\times\mathrm{Mean}\left(X^{TT}\right)-\mu_{2}\times X_{n}^{TT}\right),\quad\mathrm{Otherwise}\end{cases}\tag{15a}
{XTAOTT=XnTT+1+θ1×(μ1×xb−μ2×XnTT)+θ2×δ×(μ1×Mean(XTT)−μ2×XnTT),ifμ1<0.5XTAOTT=xb+θ1×(μ1×xb−μ2×XnTT)+θ2×δ×(μ1×Mean(XTT)−μ2×XnTT),Otherwise(15a)
X
n
I
T
+
1
=
X
T
A
O
I
T
(15b)
X_n^{IT+1}=X_{TAO}^{IT}\tag{15b}
XnIT+1=XTAOIT(15b)
DF为控制NRBO性能的决定因子,μ1和μ2为随机数:
μ
1
=
{
3
×
r
a
n
d
,
i
f
Δ
<
0.5
1
,
O
t
h
e
r
w
i
s
e
μ
2
=
{
r
a
n
d
,
i
f
Δ
<
0.5
1
,
O
t
h
e
r
w
i
s
e
(16)
\left.\mu_{1}=\left\{\begin{array}{cc}{3\times rand,}&{{\mathrm{if}}\Delta<0.5}\\{1,}&{{\mathrm{Otherwise}}}\end{array}\right.\right.\\\mu_{2}=\left\{\begin{array}{cc}{rand,}&{{\mathrm{if}}\Delta<0.5}\\{1,}&{{\mathrm{Otherwise}}}\end{array}\right.\tag{16}
μ1={3×rand,1,ifΔ<0.5Otherwiseμ2={rand,1,ifΔ<0.5Otherwise(16)
其中rand表示(0,1)之间的随机数,Δ表示(0,1)之间的随机数。上述等式进一步简化:
μ
1
=
β
×
3
×
r
a
n
d
+
(
1
−
β
)
μ
2
=
β
×
r
a
n
d
+
(
1
−
β
)
(17)
\mu_{1}=\beta\times3\times rand+(1-\beta)\\\mu_{2}=\beta\times rand+(1-\beta)\tag{17}
μ1=β×3×rand+(1−β)μ2=β×rand+(1−β)(17)
流程图
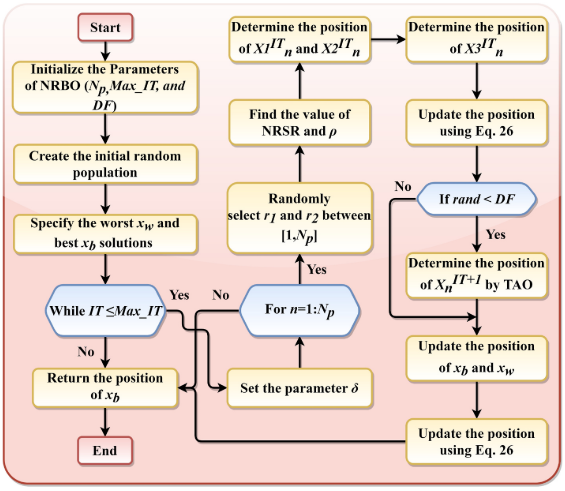
伪代码

3.结果展示
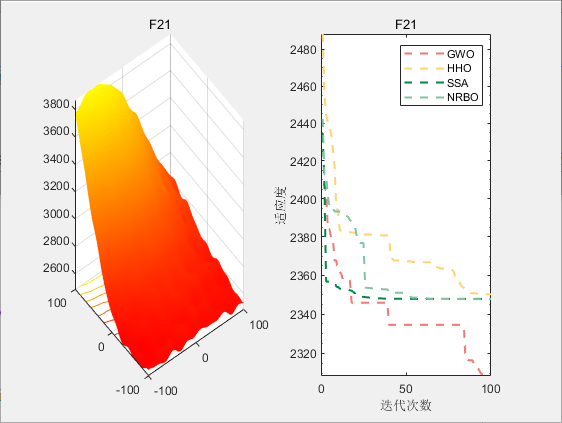
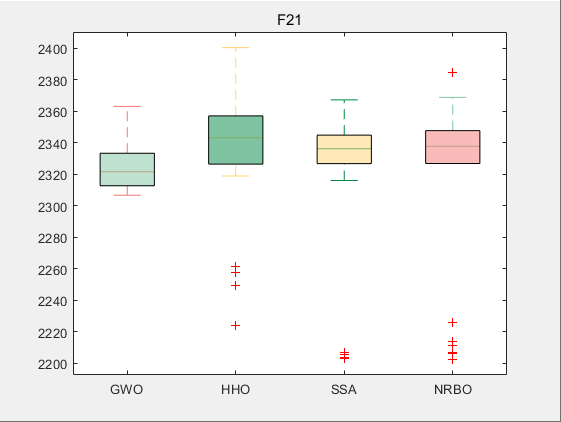
使用测试框架,测试NRBO性能 一键run.m
CEC2017-F21

4.参考文献
[1] Sowmya R, Premkumar M, Jangir P. Newton-Raphson-based optimizer: A new population-based metaheuristic algorithm for continuous optimization problems[J]. Engineering Applications of Artificial Intelligence, 2024, 128: 107532.


















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











