







0. 实际意义
一个 m×n 的 word-doc 矩阵,经 SVD 奇异值分解之后,得到 (m×k)×(k×n) 的两个子矩阵的乘积,这里的维度信息 k ,表示的正是从全部 word 中提炼出来的 topic,提取在某种程度上含义近似于压缩,自然这里提炼出来的 topic 也是去除近义词后的结果。这也正是 LSA(latent semantic analysis)(隐语义/潜藏语义/潜在语义分析)所做的工作。
1. 基本理论
矩阵的奇异值分解首先适用于矩阵非方阵的情形。
设
其中 CCT 和 CTC 的特征值相同,为 λ1,λ2,…,λr 。
Λ 为 m×n ,其中 Λii=λ√i ,其余位置为0, Λii 的值按大小降序排列
U
的每一列,
SVD 分解两端同时右乘
恰为对称矩阵的分解。
奇异值分解的图形表示如下:
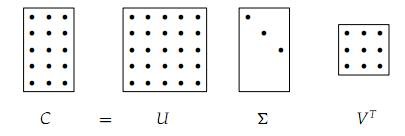
从图中可以看到 Σ <script type="math/tex" id="MathJax-Element-30">Σ</script>虽然为M x N矩阵(M>N),但从第N+1行到M行全为零,因此可以表示成 N x N 矩阵,又由于右式为矩阵相乘,因此 U 可以表示为 M x N 矩阵,VT 可以表示为 N x N 矩阵。
2. 在推荐系统中的应用
比如用户对电影的评价矩阵,可以采用 SVD 的方式,其基于这样一个假设:
- SVD is based on the assumptions that the ratings are distributed on a linear hyperplane.
References
[1] SVD奇异值分解
















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











