






在前期的文章中我们已经介绍了很多关于核酸和蛋白质之间互作的验证方法,那么如何证明蛋白和蛋白之间存在相互作用呢?蛋白质作为生命活动的主要承担者,其功能的发挥往往依赖于与其他蛋白质的相互作用,蛋白与蛋白的互作验证对于理解蛋白质功能、疾病发生机制以及药物研发具有重要意义。今天我们就来介绍3种关于蛋白与蛋白互作的验证实验,分别是Co-IP、GST pull-down和酵母双杂交。
No.1
免疫共沉淀(Co-IP)
1.1 实验原理
免疫共沉淀是利用抗体特异性反应纯化富集目的蛋白的一种方法。抗体与细胞裂解液或表达上清中相应的蛋白结合后,再与蛋白A/G(Protein A/G)偶联的 agarose 或Sepharose珠子孵育,通过离心得到珠子-蛋白A/G-抗体-目的蛋白复合物,在高温及还原剂的作用下,抗原与抗体解离,收集上清,上清中包括抗体、目的蛋白和少量的杂蛋白,再通过Western blot 或质谱等方法进一步对复合物中的靶蛋白进行分析。
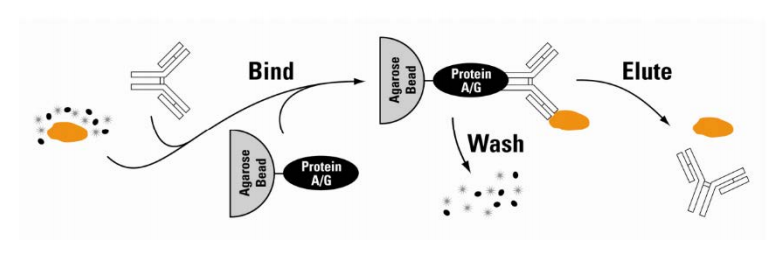
Co-IP实验原理图
1.2 实验流程

1.3 结果解读
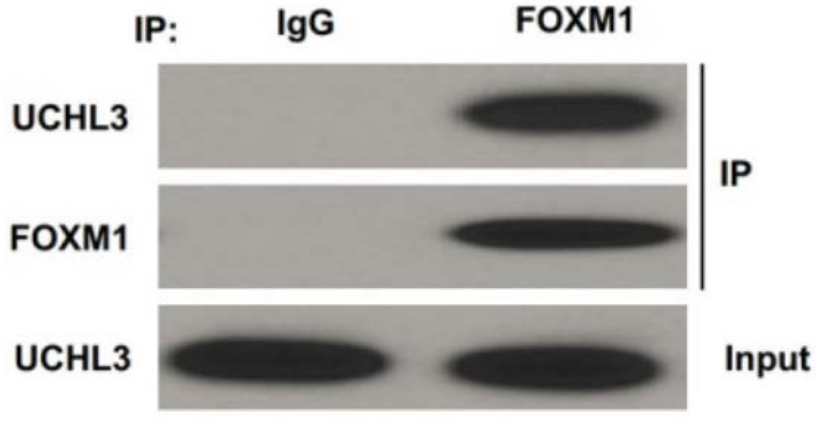
常用术语:①Input:阳性对照,诱饵蛋白与靶蛋白表达的检测确认;②IgG:阴性对照;③IP:免疫沉淀;上图检测FOXM1与UCHL3之间的互作,FOXM1是诱饵蛋白,靶蛋白是UCHL3。
结果解读:①用FOXM1蛋白的IP级抗体拉蛋白FOXM1,因为存在互作,还有其它蛋白会被拉下来。在WB检测时,下拉蛋白中能用FOXM1的抗体检测到FOXM1;②验证FOXM1和UCHL3是否有相互作用。首先在Input蛋白中可以用UCHL3的抗体检测到UCHL3;其次,在FOXM1抗体下拉的蛋白物中也可以用UCHL3的抗体检测到UCHL3。结果满足上述两个条件,则说明FOXM1和UCHL3之间存在相互作用。
No.2
GST pull-down
2.1、技术原理
Pull-down技术的核心在于,将目标蛋白质固定在一种基质(譬如Sepharose)上。当细胞提取液通过这种基质时,可以与固相化蛋白产生相互作用的配体蛋白就会被吸附,而其他没有发生作用的蛋白则会随洗脱液一起被冲洗掉。然后,通过改变洗脱液的组成或者洗脱条件,就可以将那些被吸附的目标蛋白回收。
为了提高Pull-down技术的效能,我们可以将要纯化的蛋白以融合蛋白的形式进行表达,即将“诱饵”蛋白和一种易于纯化的配体蛋白结合。1988年Smith等研究者利用谷胱甘肽-S-转移酶(GST)作为融合标签,从细菌中纯化出GST融合蛋白。GST pull-down技术,即GST融合蛋白沉降法,其原理是利用谷胱甘肽亲和树脂将靶蛋白-GST融合蛋白亲和固化,使其作为与目的蛋白亲和的支撑物,扮演“诱饵蛋白”的角色。当含有目标蛋白的溶液过柱,可以捕获与之相互作用的“捕获蛋白”(即目标蛋白)。然后,通过SDS-PAGE电泳分析洗脱结合物,可以验证两种蛋白间的相互作用,或筛选相应的目标蛋白。
2.2 实验流程
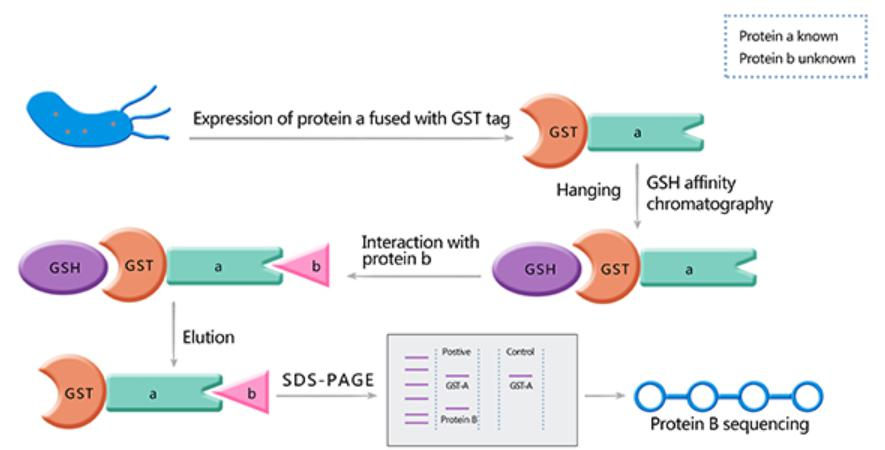
GST pull-down实验流程
2.3 结果解读
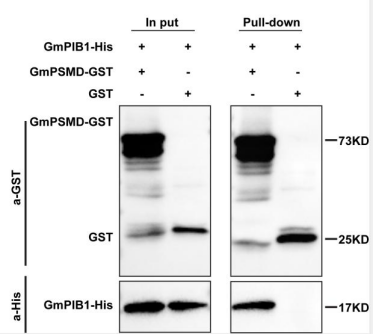
常用术语:Input:全细胞裂解液,诱饵蛋白与靶蛋白表达的检测确认。Pull-down:即免疫沉淀,这一步主要是为了纯化富集目的蛋白。GST、His均为蛋白标签。
结果解读:GST的N端融合GmPSMD蛋白,在GmPIB1蛋白添加His标签便于免疫印迹。
Input + GST/His IB组:表示不经过GST pull down实验,直接对实验前各组的混合体系用GST或者His抗体进行免疫印迹,是阳性对照组表明各组有GST或者His相关组分。
Pull down+GST IB组:表示GST pull down实验后用GST抗体进行免疫印迹。发现两组均有条带,表明GST pull down实验体系可以正常发挥功能,也表明各组体系中含有GST相关的组分。
Pull down+His IB组:表示GST pull down实验后用HIs抗体进行免疫印迹。发现GST + GmPIB1-His组无条带,表明GST pull down体系中的GST空载与GmPIB1-His之间无互作,是阴性对照组。GmPSMD-GST + GmPIB1-His组有条带,表明两种蛋白之间存在互作。
No.3
酵母双杂交
3.1 技术原理
酵母转录因子GAL4包括两个结构域,分别为DNA结合结构域(DNA-binding domain,BD)和转录激活结构域(Activating domain,AD)。BD能够识别位于GAL4-responsive gene的上游激活序列(Upstream activating sequence,UAS)并与之结合,AD可以启动UAS下游的基因进行转录。当BD或AD单独作用时不能激活转录,只有AD和BD在空间上充分接近时,GAL4转录因子才具有活性并激活下游基因的转录。酵母双杂技术利用酵母转录因子GAL4的特性,将AD与X蛋白融合,BD与Y蛋白融合,如果X、Y互作形成蛋白复合物,那么AD与BD会在空间上充分接近,使GAL4转录因子激活并启动报告基因的转录。
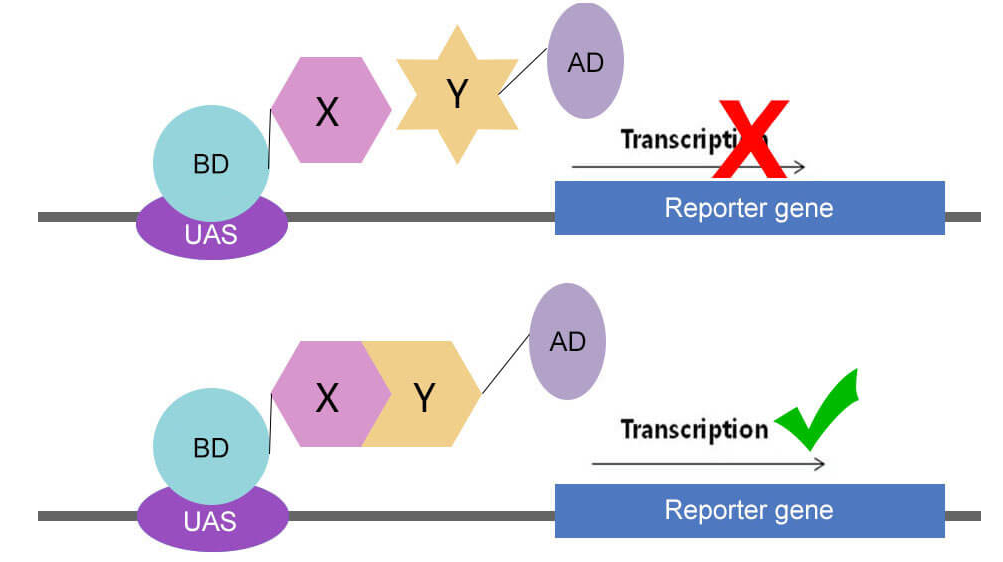
酵母双杂交技术原理
3.2 实验流程
1)AD与BD载体构建:
目的基因克隆或目的基因合成;限制性内切酶酶切骨架载体并纯化;目的基因插入骨架载体;转化大肠杆菌,筛选阳性克隆并测序鉴定;
2)共转酵母细胞:
将目的AD载体与BD载体共同转化到酵母细胞中;
3)二缺培养基培养转化的产物:
将共转的酵母细胞均匀涂布在二缺板(SD/-Leu/-Trp)上培养;
4)影印三缺和四缺板:
将二缺平板上生长的酵母单克隆影印至三缺板(SD/-His/-Leu/-Trp)和四缺板(SD/-Ade/-His/-Leu/-Trp)上培养;
5)筛选与检测:
通过观察酵母生长情况和报告基因的活性,判断两个蛋白质是否相互作用。
三种方法比较
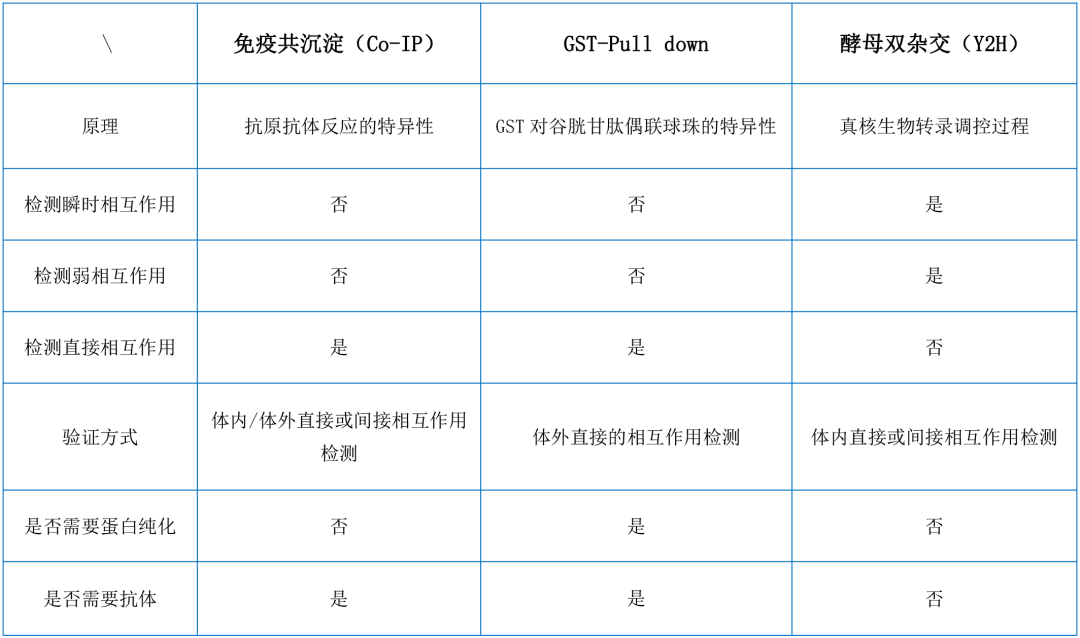
如何选择?
Co-IP,GST-pull down和酵母双杂交是研究蛋白互作最常用的三种方法,一般Y2H常用来筛选,Co-IP和GST pulldown用来验证。研究不仅在整体蛋白层面,还包括蛋白的结构域层面,GST pulldown是用来验证蛋白A与B的直接结合的,而Y2H和Co-IP结果则还有间接作用以及非特异性作用。















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









