






Unigram, Bigram, Trigram 均是自然语言处理(NLP)中的问题(N-gram问题衍生而来)。
Unigram:单word
Bigram:双word
Trigram:三word
比如西安交通大学:
Unigram 形式为:西/安/交/通/大/学
Bigram 形式为:西安/安交/交通/通大/大学(n-1)
bag of words:
词袋模型,文档和文档之间是独立可交换的,同一个文档内的词也是独立可交换的。
我们在日常生活中,总是产生大量的文本,如果每一个文本存储为一篇文档,那每篇文档以人的观点即是有序的词的序列 d=(w 1 ,w 2 ,…,w n ) (d:documentation,w:word)。
对于一篇文档,
d=w ⃗ =(w 1 ,w 2 ,…,w n )
,该文档被生成(出现或者存在)的概率为:
p(w ⃗ )=p(w 1 ,w 2 ,…,w n )=p(w 1 )p(w 2 )⋯p(w n )
第二个等号意味着文档中的词是 独立的(也即 可交换的)(显然这是一个 极强的假设)。
一个语料 W=(w 1 → ,w 2 → ,…,w m → ) 由 m 篇文档组成,则该语料被生成的概率为:
以上即为较为简单的Unigram Model,也即假设文档之间也是独立可交换的。
PLSA(Probabilistic Latent Semantic Analysis)
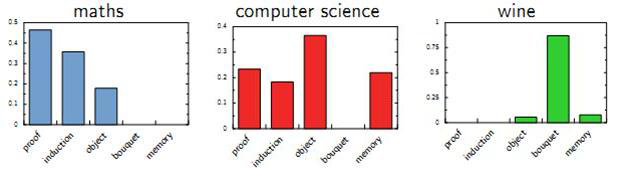
一篇文档(Document)可以由多个主题(Topic)混合而成,而每个Topic都是词汇上(关于词汇)的概率分布(也即一个Topic不再是简单的一个关键字keyword,而是一些词的概率分布)。文章中的每个词都由一个固定的Topic(Topic对应于一个概率分布嘛)生成的(混合主题,正如混合高斯?)。
















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











