







【国盛金工】量化专题:基于深度学习的指数增强策略
原创 缪铃凯、刘富兵 留富兵法 2023-11-09 03:20
收录于合集#主动量化选股5个
0
摘要
低频因子模型的挑战
基本面因子是低频多因子模型的重要alpha来源,然而我们发现2021年以来业绩类因子出现普遍性的大面积回撤。对此,我们曾经提出过三个维度的应对方案:深入基本面、拥抱beta以及量价+AI。
前两者基于逻辑驱动,依托于投资人对于财务、宏观风格的深入理解,我们曾做过深入覆盖。而量价+AI基于数据驱动,从模型层面捕捉市场短期的定价不充分,我们在本篇报告中展开初步探索。
深度学习模型与特征构建
金融数据具有显著的时序关联性,而深度学习中RNN类模型对于时序数据的建模表现最为亮眼。我们认为模型绩效的提升可以从三个维度入手:
-
通过调整超参数选取、label构建、数据预处理方式等精进单一模型;
-
对同一数据集根据不同模型训练,堆叠多模型的输出;
-
对同一模型构建差异化数据集输入,堆叠多数据集的输出;
基于RNN类模型中的LSTM,我们以第三个维度为切入点,希望通过构建差异化的数据集作为模型输入,捕捉具有增量性的信息。
深度学习选股因子
通过构建6个不同的数据集,我们训练了6个深度学习指标,综合6个指标后的深度学习因子绩效良好。2017年以来多空年化收益100.8%,多头超额收益38.2%,因子周度IC均值12.7%,ICIR达到1.23。
基于深度学习模型的指数增强策略
基于深度学习因子我们构建周度调仓的中证500/1000指数增强组合:
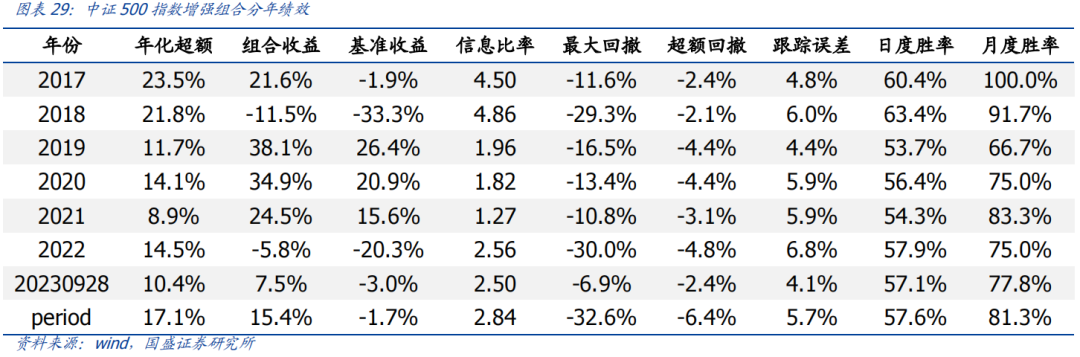
1. 中证500指数增强组合2017年以来,组合年化收益15.4%,超额中证500指数17.1%,跟踪误差5.7%,信息比率2.84。
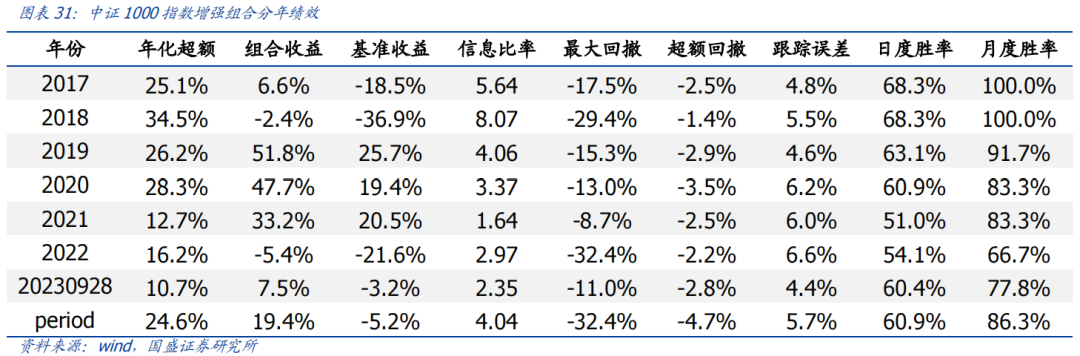
2. 中证1000指数增强组合2017年以来,组合年化收益19.4%,超额中证1000指数24.6%,跟踪误差5.7%,信息比率4.04。
1
低频因子模型的挑战
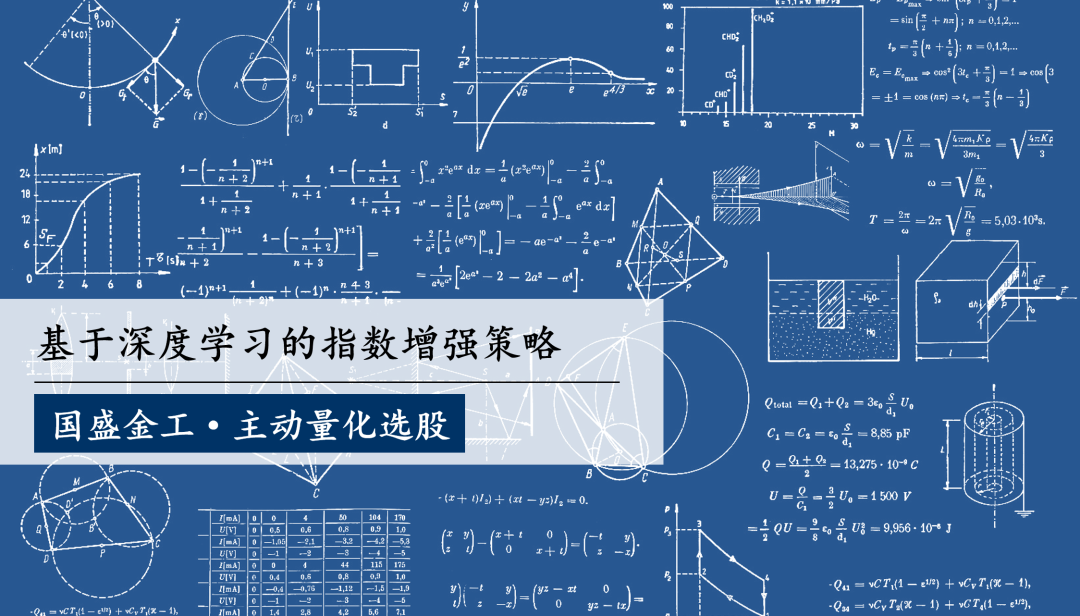
基本面因子是低频多因子模型的重要alpha来源,然而我们发现2021年开始业绩类因子普遍出现大规模的回撤。其中盈利、成长、预期调升类因子失效最为明显,多头回撤显著,这种现象在中证800指数成分股中更为强烈。
关于业绩类因子的回撤是短期现象还是长期持续,众说纷纭。风格呈现出周期性波动,而基本面因子在长期虽有alpha,但短期更像是beta,其绩效受到众多因素的影响。
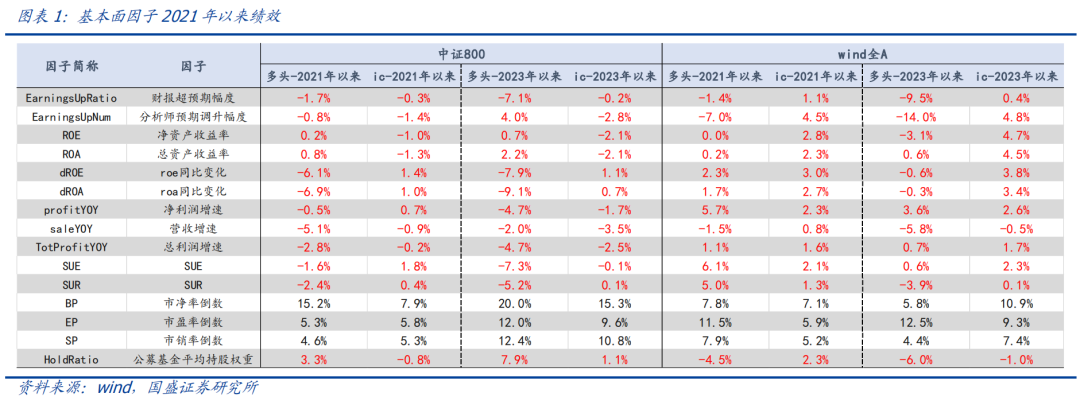
例如,机构资金流入与价值、成长风格绩效呈现出明显相关性。主动权益基金规模环比增速与当季度成长因子(dROE)多头超额收益表现出明显正相关,序列相关性达到32.8%,而其与估值因子(BP)多头超额收益序列相关性则为-17.8%。
因此,我们相信长期而言业绩类因子终将回归,那么短期我们可以做些什么应对?
关于业绩类因子的失效,我们曾经提出过三个维度的应对方案:
-
深入基本面:在基本面数据中挖掘仍未失效的alpha;
-
拥抱beta:在组合维度应用行业轮动、主动量化等策略;
-
量价+AI: 提高换手,运用机器学习、深度学习捕捉短期的量价信息;
关于前两个维度,在以往的报告中我们有所涉及:
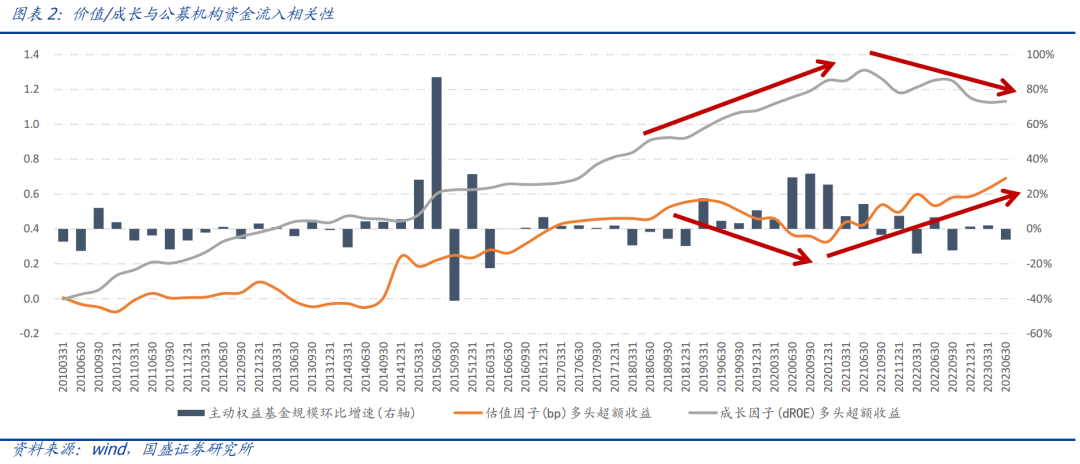
关于深入基本面,我们在前期报告中提出基于财报中的政府补助信息构建的政府补助因子,其可以作为盈利类因子的优秀补助。政府补助因子与因子的截面相关性接近50%,但是在盈利类因子多头普遍失效的情形下,因子多头在近3年均保持每年约10%的年超额收益。
因此,我们相信基本面信息中仍然存在有效的alpha信息,但是对于这些信息的挖掘需要深入财报、对基本面有深刻理解,寻找增量的信息具有较高的难度。
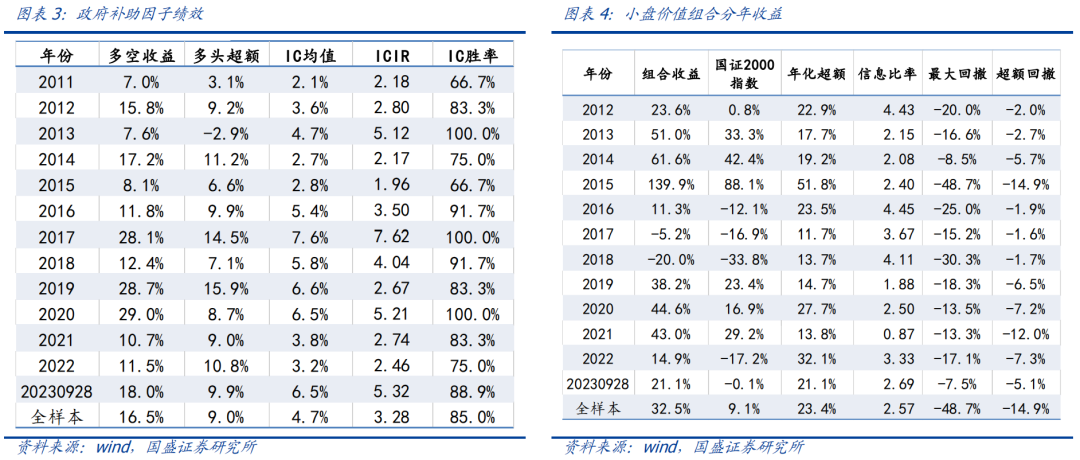
关于拥抱beta,在对应的市场风格下一些smart beta类的主动量化策略能取得亮眼的收益表现。我们跟踪的小盘价值组合历经1年多的样本外跟踪,今年以来截至20230928日,组合取得绝对收益21.1%,超额国证2000指数21.1%,超额显著。
但是,拥抱beta需要我们对于市场风格具有一定的敏感性,在对应的市场状态下配置可行的主动量化策略,而对于风格的判断从来都不是一件简单的事情。
关于量价+AI,与前两者最大的差异点在于我们将获取超额收益的方式从理解市场、理解基本面切换到了数据建模层面。随着算力的发展与技术的进步,深度学习模型已经从传统的统计学中脱离,我们不再追求逻辑层面的可解释性,基于数据建模分析维度同样也能捕获到金融市场中短期的定价不足。
本文,我们将对于第三个维度“量价+AI”展开初步的探索,希望补充基本面模型对于市场短期alpha捕捉的不足。
2
深度学习模型与特征构建
基于多因子模型的框架,我们通常构建因子预测股票截面收益,进而通过组合优化得到股票持仓,在此机器学习/深度学习与传统框架契合。
传统选股因子来源于手工构建的基本面或者交易指标等,而机器学习/深度学习算法则能自动化搜索挖掘有效信号。区别于基本面特征更多的基于逻辑驱动,对于量价特征我们可以利用各类算法基于数据驱动挖掘增量信息。
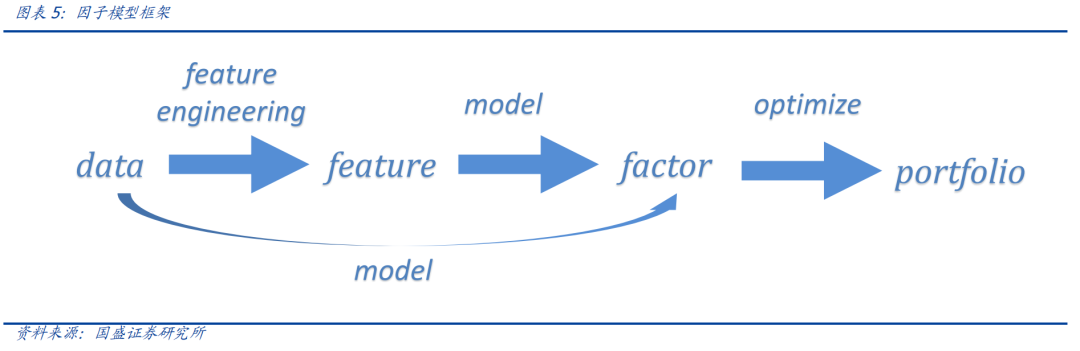
对于“数据->特征->因子”模式,通常数据源最为关键,其次是特征设计,模型的重要性则要弱于前两者。完成数据准备和特征构建后,遗传规划、神经网络等经典算法可以帮助我们挖掘一些有效信号。
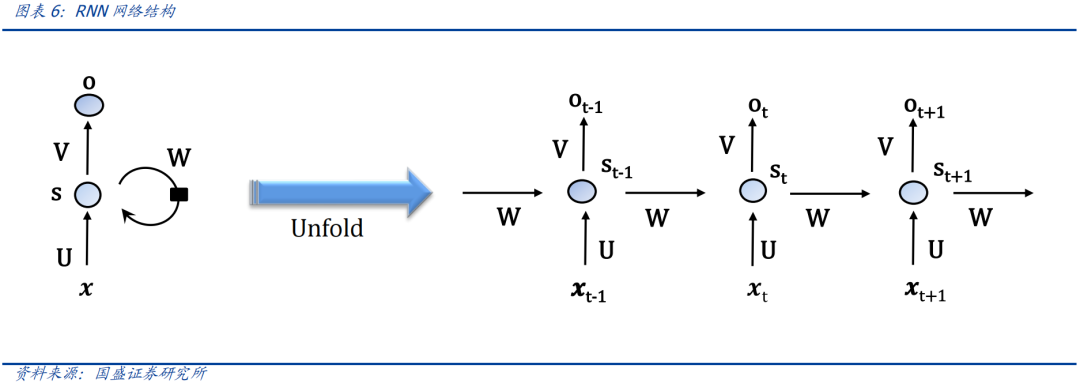
金融数据具有明显的时序特征,深度学习模型中的RNN模型,在基于时序信息建模中表现出优异效果,RNN模型的基本结构如下:
输入:
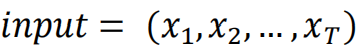
,T为序列长度,
![]()
,m为特征数,;
隐藏层:
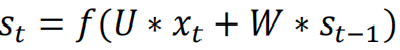
输出层:
![]()
损失函数:
![]()
用loss度量预测值和真实值之间的误差,根据误差反向传播,训练参数矩阵U,W,V。
由于RNN面对长序列数据存在梯度消失等缺陷,因此在RNN基础上衍生出了LSTM、GRU等模型。本文以LSTM为例,探索深度学习模型对于股票时序数据中的alpha信息捕捉。
首先,以往我们在线性模型中的输入特征向量通常为因子截面,通过因子加权,得到股票收益预测/因子,输入样本为一维数据:
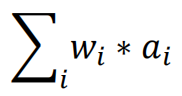
相比而言,RNN的输入刻画了特征的时序变化,其包含特征间的截面关系以及特征自身的时序关系两维度信息,输入样本为二维数据矩阵:
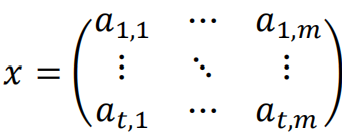
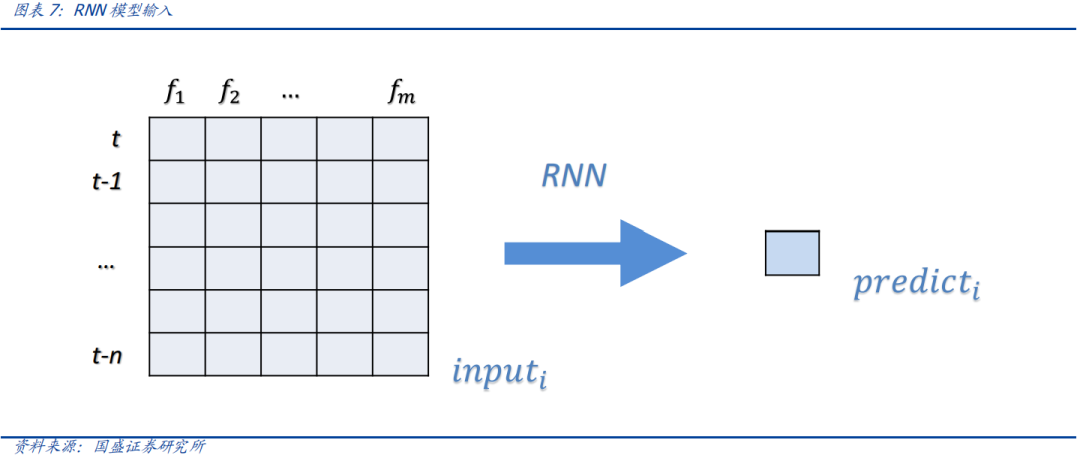
模型经过计算之后得到股票收益预测/因子得分f(x)。
此外,近年来transformer在自然语言学习等领域展现出良好表现,其核心在于注意力机制的引入。因此,在LSTM基础上,我们在隐藏层后设计了一个简易自注意力机制。
假设hidden为序列的隐藏层,我们通过线性层提取Q、K、V矩阵:

将输出output进行截面zscore标准化后,接入权重恒为1的线性层转换为因子值:
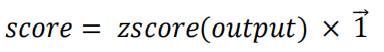
利用score作为最终的因子值,以上则为本文所设计的模型结构。
最后,具体训练模型时,考虑到模型输出信号的可交易性,我们以股票T+1至T+11的vwap价格计算的收益率为预测目标:
1. 模型每年滚动训练,在每年年初以股票过去8年的历史数据为数据集,按照时间先后,拆分后10%数据作为验证集,其余为训练集;
2. 我们假设在不同日期的股票样本是有差异的,即训练时每个batch的input为T日所有股票样本;
3. 预测目标label为股票收益率对行业、市值回归之后的残差zscore值;
4. 损失函数loss定义为pred与label之间的pearson correlation;
5. 采取early stop机制防止训练过拟合,验证集loss多次不下降时停止训练,返回验证效果最好的参数组合;
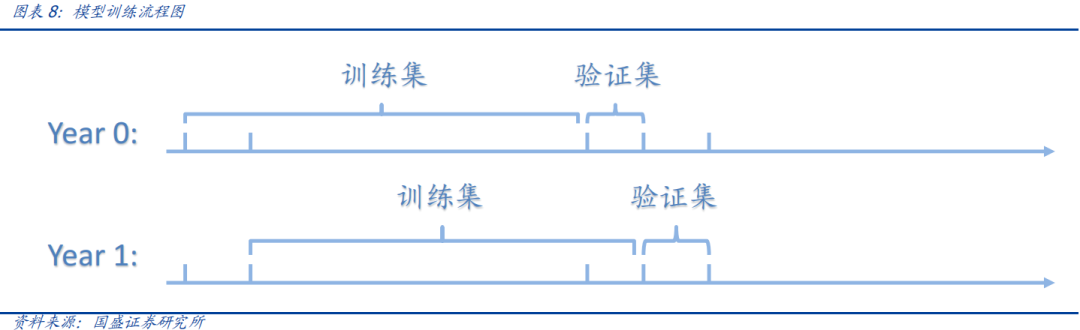
而对于模型绩效的提升,一般通过几个维度展开:
1. 通过调整超参数选取、label构建、数据预处理方式等精进单一模型;
2. 对同一数据集根据不同模型训练,堆叠多模型的输出;
3. 对同一模型构建差异化数据集输入,堆叠多数据集的输出;
本文将探索第三个维度,尝试构建不同数据集提取不同是alpha信息。我们基于端到端建模最常使用的是股票的日行情数据,日级别的价格和成交额、量等信息。
微观角度看,日行情特征集合是股票高频逐笔交易数据根据成交的价/量信息降频后衍生出的日频特征。按照这个思路,我们可以把特征工程建立在从高频数据中降频生成类似的特征集合。
日/周/分钟频率行情数据集合:价格的开、高、低、收、成交额/量等。
资金流特征集合:逐笔成交数据根据订单的金额大小拆分,衍生得到日频率资金流特征:特大、大、中、小单买入/卖出金额。
日内收益特征集合:日内数据按照30分钟窗口拆分,可以得到区间收益的开高低收分布:开盘收益率,早盘收益率、尾盘收益率、最高收益率、最低收益率、平均收益率。
由于训练具有随机性,不同随机数种子训练出的模型结果存在差异。分析表明,相同模型下堆叠不同随机数种子训练出的结果可以提升模型绩效。
但是,受限于算力限制,本文所有结果均在CPU上训练、推理,因此我们只展示根据单一随机数种子训练的结果。
因子检验时,我们计算T日因子对于T+1至T+6日vwap价格计算的收益的预测能力,即检验因子对于周度窗口的预测有效性,并展示因子20分组多头的扣费前超额收益。
3
深度学习选股因子
3.1 低频行情数据集
数据集:
股票日行情bar_daily、周行情bar_weekly
数据特征:
开盘价、最高价、最低价、收盘价、均价、5/10/20日均线、成交量、成交额;
数据预处理:
-
数据滚动30日窗口取数据构建数据集,数据序列长度为30;
-
价格数据先除以最新收盘价标准化,而后整体在面板上zscore;
-
成交量/额数据除以序列均值标准化,而后单独在面板上取zscore;
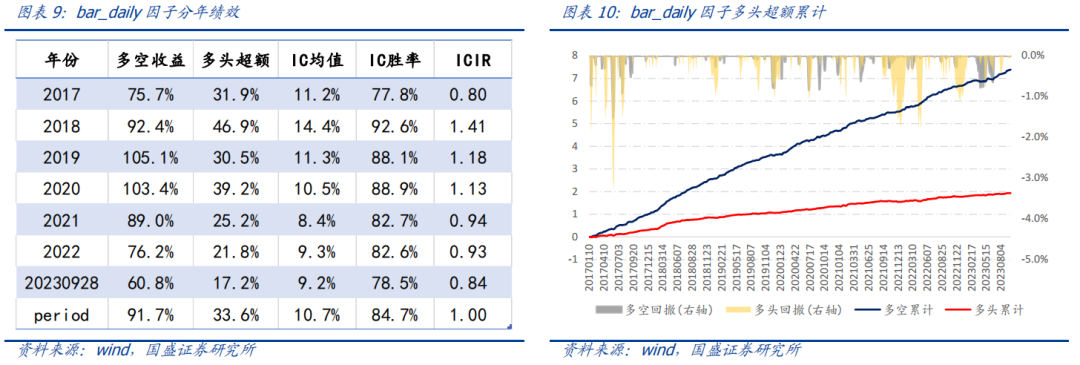
日线因子bar_daily在2017年以来多空年化收益91.7%,多头超额收益33.6%,因子IC均值10.7%,IC周度胜率为84.7%,ICIR为1.00。
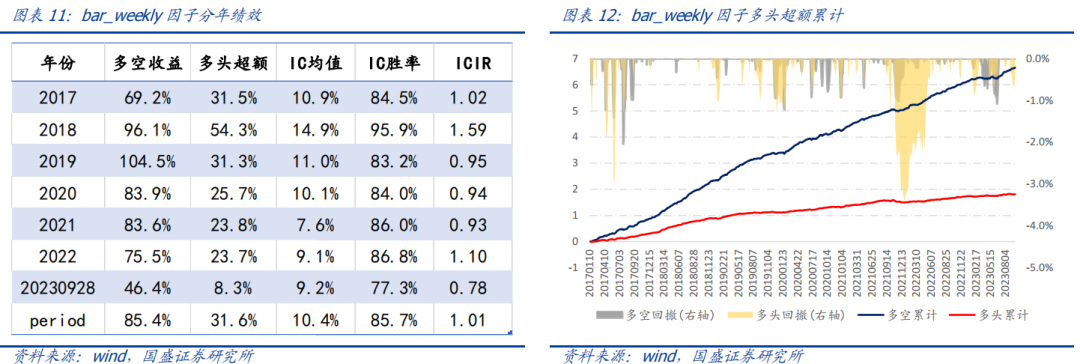
周线因子bar_weekly在2017年以来多空年化收益85.4%,多头超额收益31.6%,因子IC均值10.4%,IC周度胜率为85.7%,ICIR为1.01。
3.2 日内行情数据集
数据集:
股票日内行bar_minutely、日内收益分布intra_return:
数据特征:
bar_minutely:开盘价、最高价、最低价、收盘价、均价、成交量、成交额;
intra_return:股票日开盘收益率、早盘30分钟收益率、日内最高收益率、日内最低收益率、尾盘30分钟收益率、日内平均收益率;
数据预处理:
-
30分钟K线滚动5日窗口取数据构建数据集,数据序列长度为40,价格和成交量数据特征标准化方式与3.1中一致;
-
intra_return数据集中6个收益率特征一起面板上zscore;
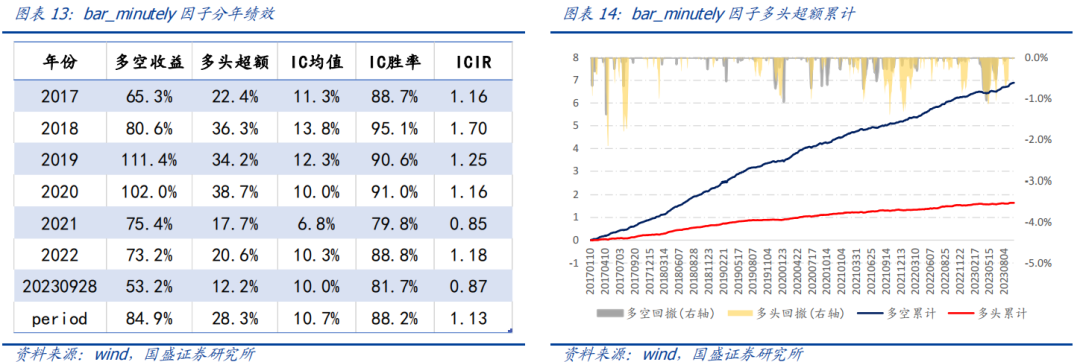
分钟线因子bar_minutely在2017年以来多空年化收益84.9%,多头超额收益28.3%,因子IC均值10.7%,IC周度胜率为88.2%,ICIR为1.13。
日内收益分布因子intra_return在2017年以来多空年化收益80.6%,多头超额收益25.6%,因子IC均值10.3%,IC周度胜率为86.7%,ICIR为1.10。
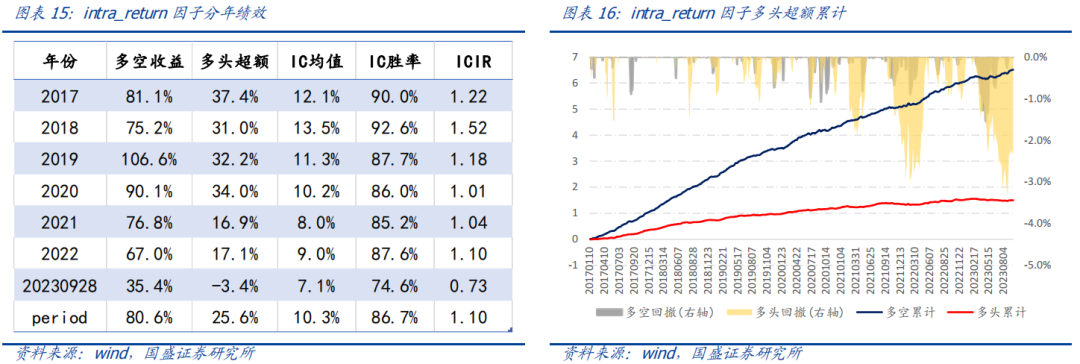
3.3 其他衍生数据集合
数据集:
资金流数据集合money_flow、量价因子衍生集合pv_factor:
数据特征:
money_flow:特大单、大单、中单、小单买入/卖出金额;
pv_factor:日收益率、开盘收益率、换手率、非流动冲击、振幅、3/5日收益率、3/5日波动率、日内波动率等11个日频特征;
数据预处理
-
将各类型金额除以当日成交总额标得到比例值;
-
数据滚动30日窗口取数据构建数据集,数据序列长度为30;
-
资金流数据集中8个资金流比例特征在面板上标准化;
-
衍生因子数据集中各个指标单独在面板标准化;
资金流因子money_flow在2017年以来多空年化收益62.0%,多头超额收益13.7%,因子IC均值7.2%,IC周度胜率为82.4%,ICIR为0.86。
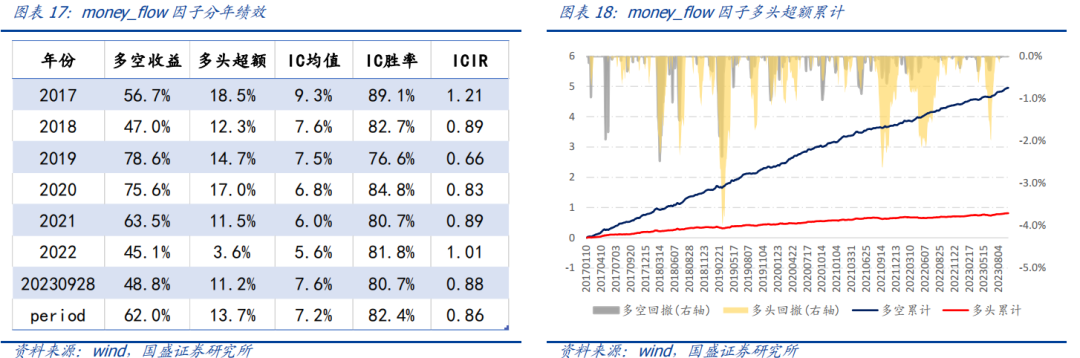
量价因子衍生数据集因子在2017年以来多空年化收益85.0%,多头超额收益29.3%,因子IC均值9.9%,IC周度胜率为88.4%,ICIR为1.13。
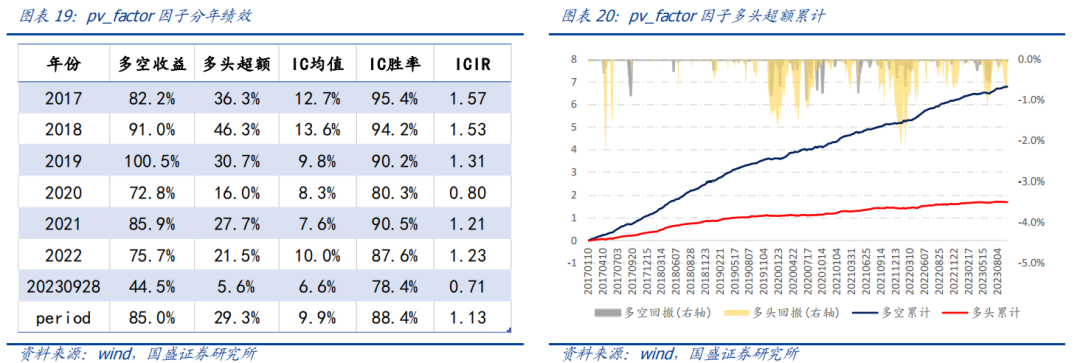
3.4 综合因子nn_score
根据前文,我们根据6个不同数据集基于LSTM模型训练了6个因子。下图展示了这6个因子之间相关性的矩阵图。
整体而言,6个因子间存在较明显的截面相关性,基于量价信息衍生出的各数据集因子相关性均在50%左右,而资金流因子与其他因子相关性较低,平均相关性在30%以下。
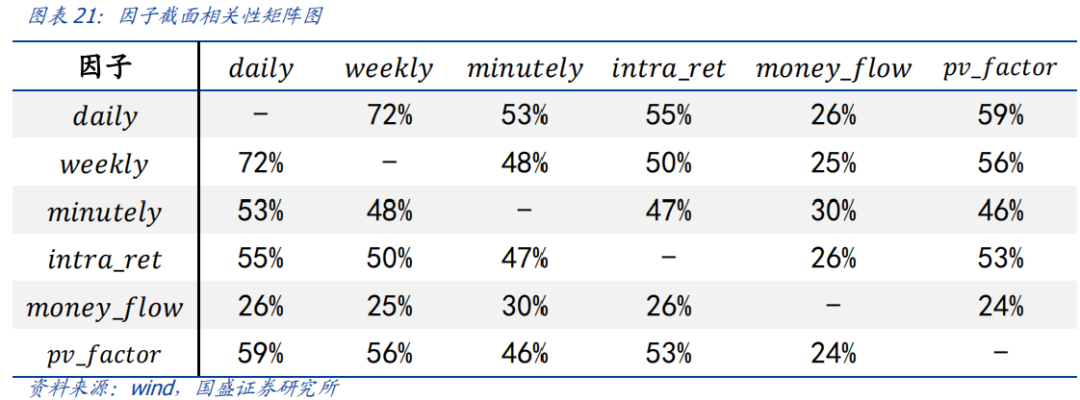
通常我们会基于xgboost、lightgbm等树模型进一步拟合因子之间的非线性信息,得到综合打分。但考虑到我们目前因子数据较少,我们直接将6个因子等权线性相加,得到综合深度学习因子nn_score。
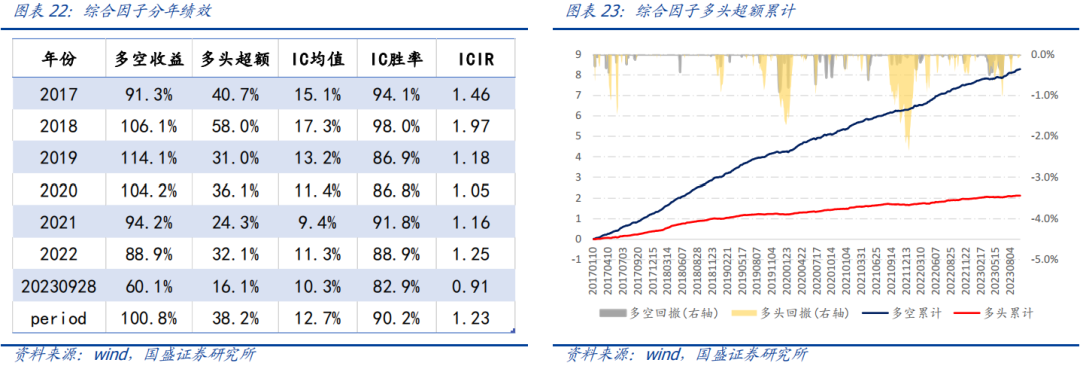
综合因子绩效相较于单一指标均呈现出一定程度的提升,因子稳定性改善。在2017年以来多空年化收益100.8%,多头超额收益38.2%,因子IC均值12.7%,IC周度胜率为90.2%,ICIR为1.23。
值得注意的是,从模型分年绩效角度我们发现在2020年以后模型整体绩效出现比较明显衰减,并且呈现出逐年衰减的趋势。这类端到端的模型值得警惕的风险点在于模型容易产生较高的同质性。
相似的数据输入、相似的模型结构往往容易产生同质化的结果,同时由于底层alpha来源的相似性,实际模型收益的时序相关性可能要远高于模型打分的截面相关性。因此,设法做出差异化的结果可能是此类模型需要重点探究的方向。
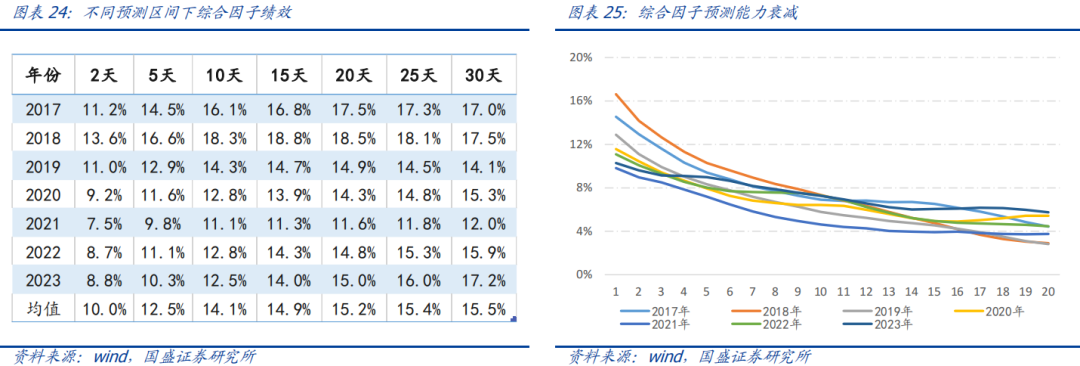
以T+1日均价为撮合价格,分别以未来2天、5天、10天、15天、20天、25天、30天收益率为预测窗口,因子ic整体随着预测窗口宽度增加而上升:周频ic均值12.5%,双周频ic为14.1%,月频ic均值为15.2%,30日频ic均值为15.5%。
固定5天为预测窗口,分别计算T日因子在T+1至T+20日买入的绩效,因子选股能力随着滞后期增加而衰减,滞后期在10天附近因子ic衰减一半,在滞后20日后衰减至约25%水平。深度学习因子alpha的衰减速度并不快,也正因此随着预测窗口增加ic反而出现进一步提升。
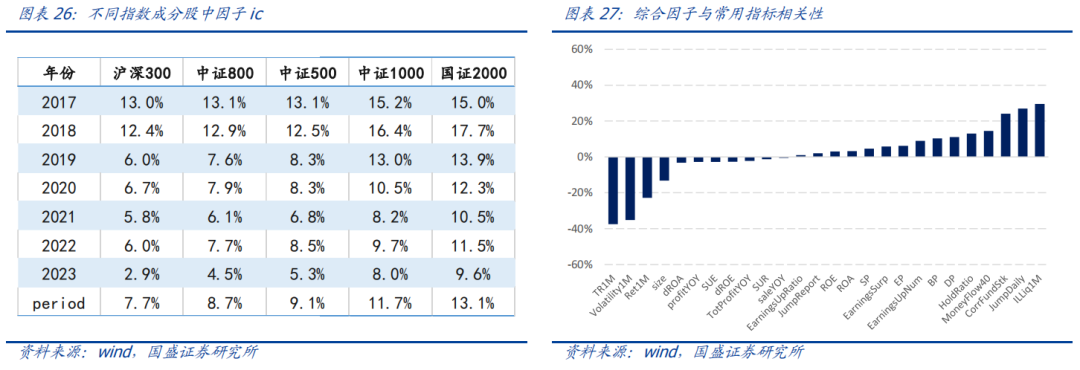
统计因子在沪深300、中证800、中证500、中证1000和国证2000指数成分股中的ic,因子选股能力随着股票域市值的减少而增加,这与量价信息更适用于中小市值股票相一致。此外,这类模型绩效2019年以后在中大市值股票域中的衰减速度显著更快,这可能与量化基金规模的迅速增长存在一定联系。
计算综合因子与我们常用的低频指标的截面相关性,我们发现深度学习因子与基本面信息之间几乎不存在相关性,但是其与我们常用的反转、换手、波动等量价因子之间存在较明显的相关性。
本质上,我们通过模型在量价信息中构建了逻辑无法解释的特征,但这些特征的alpha源与量价风格还是存在明显关联,因此在实际构建组合过程中,常用风险模型所无法刻画的短期量价类风险的控制可能是值得注意的点。
4
基于深度学习模型的指数增强策略
基于综合因子,我们分别构建中证500/1000指数增强组合,组合周度调仓,以最大化预期收益为目标,约束单次换手不超过20%,次日均价撮合,双边千3计费。
4.1 中证500指数增强
具体的,对于中证500指数,风险维度我们约束:
-
个股维度:个股权重偏离不超过0.8%;
-
行业偏离:中信一级行业权重偏离不超过2%;
-
风格偏离:SIZE、BTOP、GROWTH不超过0.3倍标准差;
-
成分股权重:指数成分股权重下限不低于80%;
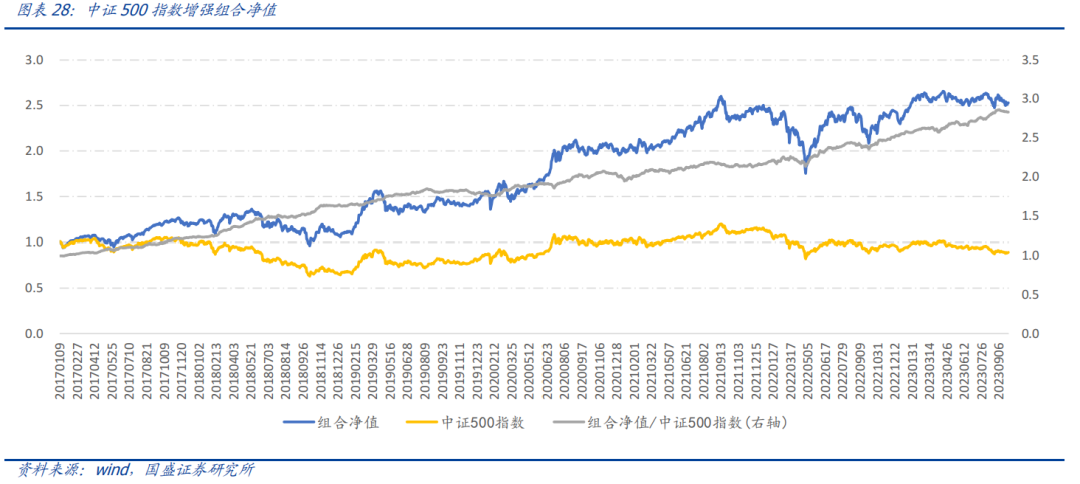
中证500指数增强组合2017年以来,组合年化收益15.4%,超额中证500指数17.1%,跟踪误差5.7%,信息比率2.84,月度胜率为81.3%,年单边换手约10倍。
4.2 中证1000指数增强
同样的,对于中证1000指数,风险维度我们约束:
-
个股维度:个股权重偏离不超过0.5%;
-
行业偏离:中信一级行业权重偏离不超过2%;
-
风格偏离:SIZE、BTOP、GROWTH不超过0.2倍标准差;
-
成分股权重:指数成分股权重下限不低于80%;
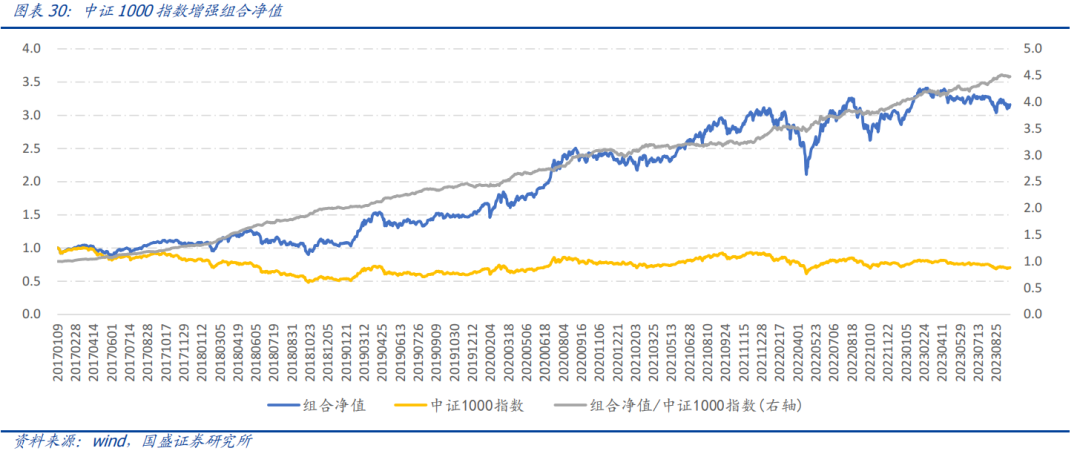
中证1000指数增强组合2017年以来,组合年化收益19.4%,超额中证1000指数24.6%,跟踪误差5.7%,信息比率4.04,月度胜率为86.3%,年单边换手约10倍。
5
总结
基本面因子是低频多因子模型的重要alpha来源,然而我们发现2021年以来业绩类因子出现普遍性的大面积回撤。对此,我们曾经提出过三个维度的应对方案:深入基本面、拥抱beta以及量价+AI。
前两者基于逻辑驱动,依托于投资人对于财务、宏观风格的深入理解,我们曾做过深入覆盖。而量价+AI基于数据驱动,从模型层面捕捉市场短期的定价不充分,我们在本篇报告中展开初步探索。
金融数据具有显著的时序关联性,而深度学习中RNN类模型对于时序数据的建模表现最为亮眼。我们认为模型绩效的提升可以从三个维度入手:
1. 通过调整超参数选取、label构建、数据预处理方式等精进单一模型;
2. 对同一数据集根据不同模型训练,堆叠多模型的输出;
3. 对同一模型构建差异化数据集输入,堆叠多数据集的输出;
基于RNN类模型中的LSTM,我们以第三个维度为切入点,希望通过构建差异化的数据集作为模型输入,捕捉具有增量性的信息。
通过构建6个不同的数据集,我们训练了6个深度学习指标,综合6个指标后的深度学习因子绩效良好。2017年以来多空年化收益100.8%,多头超额收益38.2%,因子IC均值12.7%,ICIR达到1.23。
基于深度学习因子我们构建周度调仓的中证500/1000指数增强组合:
1.中证500指数增强组合2017年以来,组合年化收益15.4%,超额中证500指数17.1%,跟踪误差5.7%,信息比率2.84。
2.中证1000指数增强组合2017年以来,组合年化收益19.4%,超额中证1000指数24.6%,跟踪误差5.7%,信息比率4.04。
风险提示:结论基于历史数据统计和模型推演,存在失效风险。
本文节选自国盛证券研究所于2023年11月6日发布的报告《基于深度学习的指数增强策略》,具体内容请详见相关报告。
缪铃凯 S0680521120003 miaolingkai@gszq.com
刘富兵 S0680518030007 liufubing@gszq.com

















 2817
2817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









