







 该文描述了一种使用BERT模型处理命名实体识别(NER)任务的方法,通过构建针对不同实体类型的训练样本,如药物组、症状等,采用标签平滑技术缓解过拟合问题。训练时,每种类型实体构建一个样本,并在解码输出时不限制标签,以提高召回率。
该文描述了一种使用BERT模型处理命名实体识别(NER)任务的方法,通过构建针对不同实体类型的训练样本,如药物组、症状等,采用标签平滑技术缓解过拟合问题。训练时,每种类型实体构建一个样本,并在解码输出时不限制标签,以提高召回率。
-
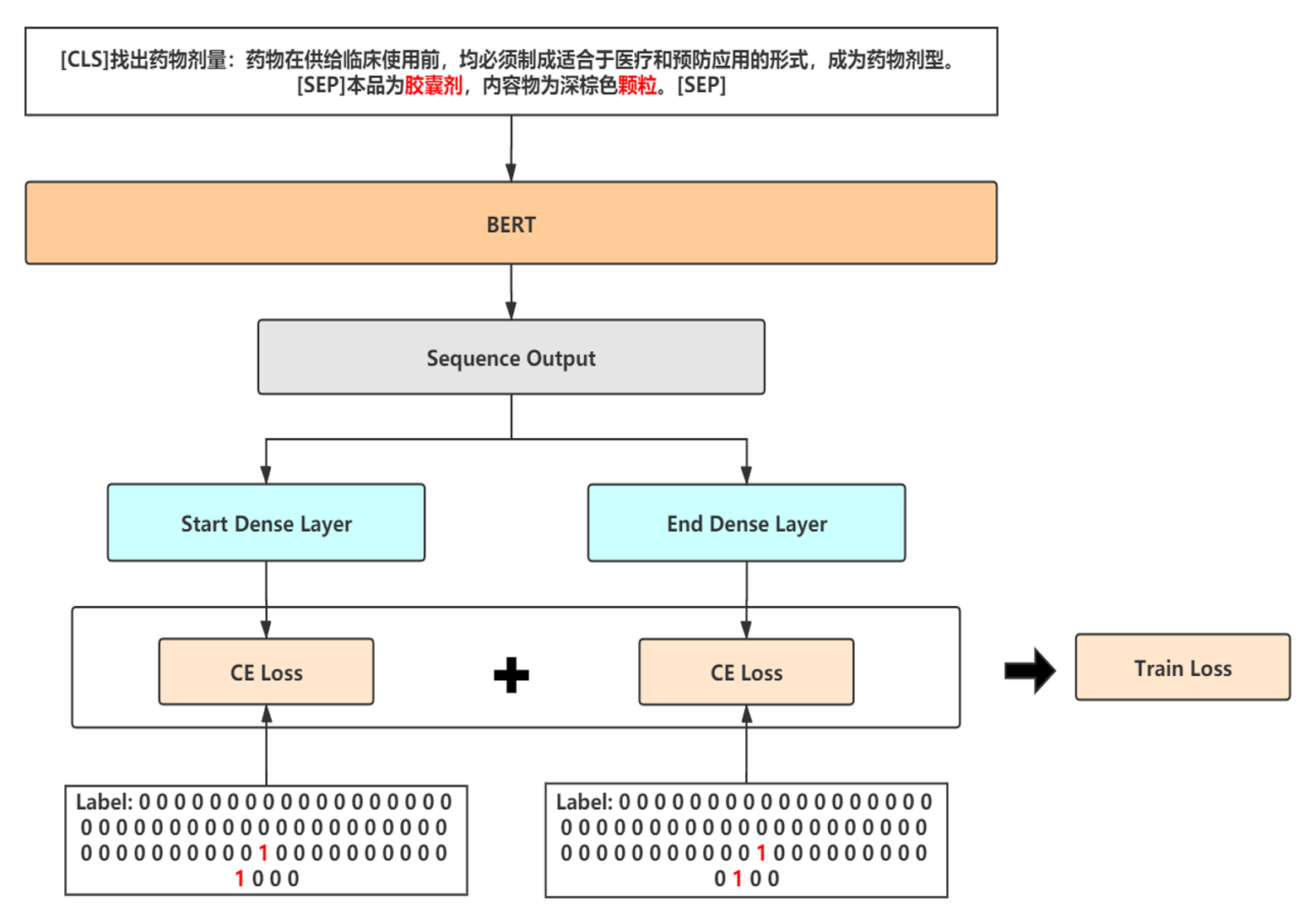
基于阅读理解的方式处理NER任务
-
query:实体类型的描述来作为query
-
doc:分句后的原始文本作为doc
-
-
针对每一种类型构造一个样本,训练时有大量负样本,可以随机选取30%加入训练,其余丢弃,保证效率
-
预测时对每一类都需构造一次样本,对解码输出不做限制,保证召回率
-
使用label smooth缓解过拟合问题
实体类型:
ENTITY_TYPES = ['DRUG', 'DRUG_INGREDIENT', 'DISEASE', 'SYMPTOM', 'SYNDROME', 'DISEASE_GROUP', 'FOOD', 'FOOD_GROUP', 'PERSON_GROUP', 'DRUG_GROUP', 'DRUG_DOSAGE', 'DRUG_TASTE', 'DRUG_EFFICACY']
每种实体类型构建一个问句:
{
"DRUG": "找出药物:用于预防、治疗、诊断疾病并具有康复与保健作用的物质。",
"DRUG_INGREDIENT": "找出药物成分:中药组成成分,指中药复方中所含有的所有与该复方临床应用目的密切相关的药理活性成分。",
"DISEASE": "找出疾病:指人体在一定原因的损害性作用下,因自稳调节紊乱而发生的异常生命活动过程,会影响生物体的部分或是所有器官。",
"SYMPTOM": "找出症状:指疾病过程中机体内的一系列机能、代谢和形态结构异常变化所引起的病人主观上的异常感觉或某些客观病态改变。",
"SYNDROME": "找出症候:概括为一系列有相互关联的症状总称,是指不同症状和体征的综合表现。",
"DISEASE_GROUP": "找出疾病分组:疾病涉及有人体组织部位的疾病名称的统称概念,非某项具体医学疾病。",
"FOOD": "找出食物:指能够满足机体正常生理和生化能量需求,并能延续正常寿命的物质。",
"FOOD_GROUP": "找出食物分组:中医中饮食养生中,将食物分为寒热温凉四性,同时中医药禁忌中对于具有某类共同属性食物的统称,记为食物分组。",
"PERSON_GROUP": "找出人群:中医药的适用及禁忌范围内相关特定人群。",
"DRUG_GROUP": "找出药品分组:具有某一类共同属性的药品类统称概念,非某项具体药品名。例子:止咳药、退烧药",
"DRUG_DOSAGE": "找出药物剂量:药物在供给临床使用前,均必须制成适合于医疗和预防应用的形式,成为药物剂型。",
"DRUG_TASTE": "找出药物性味:药品的性质和气味。例子:味甘、酸涩、气凉。",
"DRUG_EFFICACY": "找出中药功效:药品的主治功能和效果的统称。例子:滋阴补肾、去瘀生新、活血化瘀"
}样本
# example:
# {
# 'text': '子宫疾病用药 如与其他药物同时使用可能会发生药物相互作用,详情请咨询医师或药师。 0.4g*15粒*4盒 口服,一次4粒,一日3次。 国家基本药物目录(2012) 丸剂(大蜜丸) 用于妇人宿有瘕块,或血瘀经闭,行经腹痛,产后恶露不尽经闭,行经腹痛,产后恶露不尽 补肾益气,化瘀通淋。用于肾脾双虚,气滞血瘀,前列腺增生,慢性前列腺炎血瘀,前列腺增生,慢性前列腺炎;面色晃白,神疲乏力,腰膝疲软无力,小腹坠胀,小便不爽,点滴不出,或尿频、尿急、尿道涩痛 临江市宏大药业有限公司',
# 'labels': [('DRUG_GROUP', '子宫疾病用药', 1), ('SYMPTOM', '宿有瘕块', 101), ('SYNDROME', '血瘀', 107), ('SYMPTOM', '行经腹痛', 112), ('SYMPTOM', '经闭', 123), ('DRUG_DOSAGE', '丸剂', 88), ('DRUG_DOSAGE', '大蜜丸', 91), ('SYMPTOM', '补肾益气', 139), ('SYMPTOM', '化瘀通淋', 144), ('SYNDROME', '肾脾双虚', 151), ('SYNDROME', '气滞', 156), ('DISEASE', '慢性前列腺炎', 167), ('SYNDROME', '血瘀', 173), ('SYMPTOM', '面色晃白', 189), ('SYMPTOM', '神疲乏力', 194), ('SYMPTOM', '腰膝疲软无力', 199), ('SYMPTOM', '小腹坠胀', 206), ('SYMPTOM', '小便不爽', 211), ('SYMPTOM', '尿频', 222), ('SYMPTOM', '尿急', 225), ('SYMPTOM', '尿道涩痛', 228)]
# }对每一种实体类型构建一个训练样本,比如针对“DRUG_GROUP”类型,构建样本:
# [CLS]['找', '出', '药', '品', '分', '组', ':', '具', '有', '某', '一', '类', '共', '同', '属', '性', '的', '药', '品', '类', '统', '称', '概', '念', ',', '非', '某', '项', '具', '体', '药', '品', '名', '。', '例', '子', ':', '止', '咳', '药', '、', '退', '烧', '药'][SEQ]['[BLANK]', '子', '宫', '疾', '病', '用', '药', '[BLANK]', '[BLANK]', '如', '与', '其', '他', '药', '物', '同', '时', '使', '用', '可', '能', '会', '发', '生', '药', '物', '相', '互', '作', '用', ',', '详', '情', '请', '咨', '询', '医', '师', '或', '药', '师', '。', '[BLANK]', '[BLANK]', '0', '.', '4', 'g', '*', '1', '5', '粒', '*', '4', '盒', '[BLANK]', '[BLANK]', '口', '服', ',', '一', '次', '4', '粒', ',', '一', '日', '3', '次', '。', '[BLANK]', '[BLANK]', '国', '家', '基', '本', '药', '物', '目', '录', '(', '2', '0', '1', '2', ')', '[BLANK]', '[BLANK]', '丸', '剂', '(', '大', '蜜', '丸', ')', '[BLANK]', '[BLANK]', '用', '于', '妇', '人', '宿', '有', '瘕', '块', ',', '或', '血', '瘀', '经', '闭', ',', '行', '经', '腹', '痛', ',', '产', '后', '恶', '露', '不', '尽', '经', '闭', ',', '行', '经', '腹', '痛', ',', '产', '后', '恶', '露', '不', '尽', '[BLANK]', '[BLANK]', '补', '肾', '益', '气', ',', '化', '瘀', '通', '淋', '。', '用', '于', '肾', '脾', '双', '虚', ',', '气', '滞', '血', '瘀', ',', '前', '列', '腺', '增', '生', ',', '慢', '性', '前', '列', '腺', '炎', '血', '瘀', ',', '前', '列', '腺', '增', '生', ',', '慢', '性', '前', '列', '腺', '炎', ';', '面', '色', '晃', '白', ',', '神', '疲', '乏', '力', ',', '腰', '膝', '疲', '软', '无', '力', ',', '小', '腹', '坠', '胀', ',', '小', '便', '不', '爽', ',', '点', '滴', '不', '出', ',', '或', '尿', '频', '、', '尿', '急', '、', '尿', '道', '涩', '痛', '[BLANK]', '临', '江', '市', '宏', '大', '药', '业', '有', '限', '公', '司', '[BLANK]'][SEQ]
通过Bert进行序列化后:
# feature =
# {
# 'token_ids': [101, 2823, 1139, 5790, 1501, 1146, 5299, 8038, 1072, 3300, 3378, 671, 5102, 1066, 1398, 2247, 2595, 4638, 5790, 1501, 5102, 5320, 4917, 3519, 2573, 8024, 7478, 3378, 7555, 1072, 860, 5790, 1501, 1399, 511, 891, 2094, 8038, 3632, 1495, 5790, 510, 6842, 4173, 5790, 102, 100, 2094, 2151, 4565, 4567, 4500, 5790, 100, 100, 1963, 680, 1071, 800, 5790, 4289, 1398, 3198, 886, 4500, 1377, 5543, 833, 1355, 4495, 5790, 4289, 4685, 757, 868, 4500, 8024, 6422, 2658, 6435, 1486, 6418, 1278, 2360, 2772, 5790, 2360, 511, 100, 100, 121, 119, 125, 149, 115, 122, 126, 5108, 115, 125, 4665, 100, 100, 1366, 3302, 8024, 671, 3613, 125, 5108, 8024, 671, 3189, 124, 3613, 511, 100, 100, 1744, 2157, 1825, 3315, 5790, 4289, 4680, 2497, 8020, 123, 121, 122, 123, 8021, 100, 100, 709, 1177, 113, 1920, 6057, 709, 114, 100, 100, 4500, 754, 1967, 782, 2162, 3300, 100, 1779, 8024, 2772, 6117, 4595, 5307, 7308, 8024, 6121, 5307, 5592, 4578, 8024, 772, 1400, 2626, 7463, 679, 2226, 5307, 7308, 8024, 6121, 5307, 5592, 4578, 8024, 772, 1400, 2626, 7463, 679, 2226, 100, 100, 6133, 5513, 4660, 3698, 8024, 1265, 4595, 6858, 3900, 511, 4500, 754, 5513, 5569, 1352, 5994, 8024, 3698, 4005, 6117, 4595, 8024, 1184, 1154, 5593, 1872, 4495, 8024, 2714, 2595, 1184, 1154, 5593, 4142, 6117, 4595, 8024, 1184, 1154, 5593, 1872, 4495, 8024, 2714, 2595, 1184, 1154, 5593, 4142, 8039, 7481, 5682, 3230, 4635, 8024, 4868, 4558, 726, 1213, 8024, 5587, 5607, 4558, 6763, 3187, 1213, 8024, 2207, 5592, 1785, 5515, 8024, 2207, 912, 679, 4272, 8024, 4157, 4017, 679, 1139, 8024, 2772, 2228, 7574, 510, 2228, 2593, 510, 2228, 6887, 3886, 4578, 100, 707, 3736, 2356, 2131, 1920, 5790, 689, 3300, 7361, 1062, 1385, 100, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'attention_masks': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'ent_type': 9,
# 'start_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'end_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# }Bert-MRC模型结构
class MRCModel(BaseModel):
def __init__(self, bert_dir, dropout_prob=0.1, use_type_embed=False, loss_type='ce', **kwargs):
"""
tag the subject and object corresponding to the predicate
:param use_type_embed: type embedding for the sentence
:param loss_type: train loss type in ['ce', 'ls_ce', 'focal']
"""
super(MRCModel, self).__init__(bert_dir, dropout_prob=dropout_prob)
self.use_type_embed = use_type_embed
self.use_smooth = loss_type
out_dims = self.bert_config.hidden_size
if self.use_type_embed:
embed_dims = kwargs.pop('predicate_embed_dims', self.bert_config.hidden_size)
self.type_embedding = nn.Embedding(13, embed_dims)
self.conditional_layer_norm = ConditionalLayerNorm(out_dims, embed_dims, eps=self.bert_config.layer_norm_eps)
mid_linear_dims = kwargs.pop('mid_linear_dims', 128)
self.mid_linear = nn.Sequential(
nn.Linear(out_dims, mid_linear_dims),
nn.ReLU(),
nn.Dropout(dropout_prob)
)
out_dims = mid_linear_dims
self.start_fc = nn.Linear(out_dims, 2) # 2处为0或1,1表示当前token位置为实体的头index
self.end_fc = nn.Linear(out_dims, 2) # 2处为0或1,1表示当前token位置为实体的尾index
reduction = 'none'
if loss_type == 'ce':
self.criterion = nn.CrossEntropyLoss(reduction=reduction)
elif loss_type == 'ls_ce':
self.criterion = LabelSmoothingCrossEntropy(reduction=reduction)
else:
self.criterion = FocalLoss(reduction=reduction)
self.loss_weight = nn.Parameter(torch.FloatTensor(1), requires_grad=True)
self.loss_weight.data.fill_(-0.2)
init_blocks = [self.mid_linear, self.start_fc, self.end_fc]
if self.use_type_embed:
init_blocks.append(self.type_embedding)
self._init_weights(init_blocks)
# token_ids: torch.Size([batch_size, seq_len])
# attention_masks: torch.Size([batch_size, seq_len])
# token_type_ids: torch.Size([batch_size, seq_len])
def forward(self, token_ids, attention_masks, token_type_ids, ent_type=None, start_ids=None, end_ids=None, pseudo=None):
# 使用Bert预训练模型进行Embedding
bert_outputs = self.bert_module(input_ids=token_ids, attention_mask=attention_masks, token_type_ids=token_type_ids)
seq_out = bert_outputs[0] # torch.Size([batch_size, seq_len, bert_dim])----torch.Size([6, 512, 768])
if self.use_type_embed:
assert ent_type is not None, 'Using predicate embedding, predicate should be implemented'
predicate_feature = self.type_embedding(ent_type)
seq_out = self.conditional_layer_norm(seq_out, predicate_feature)
seq_out = self.mid_linear(seq_out) # torch.Size([batch_size, seq_len, out_dims])----torch.Size([6, 512, 128])
# 实体span的start位置的映射
start_logits = self.start_fc(seq_out) # torch.Size([batch_size, seq_len, out_dims])---->torch.Size([batch_size, seq_len, 2])
# 实体span的end位置的映射
end_logits = self.end_fc(seq_out) # torch.Size([batch_size, seq_len, out_dims])---->torch.Size([batch_size, seq_len, 2])
out = (start_logits, end_logits, )
if start_ids is not None and end_ids is not None:
start_logits = start_logits.view(-1, 2) # torch.Size([batch_size*seq_len, 2])
end_logits = end_logits.view(-1, 2) # torch.Size([batch_size*seq_len, 2])
# 去掉 text_a 和 padding 部分的标签,计算真实 loss
active_loss_mask = token_type_ids.view(-1) == 1 # torch.Size([batch_size*seq_len])
active_start_logits = start_logits[active_loss_mask]
active_end_logits = end_logits[active_loss_mask]
active_start_labels = start_ids.view(-1)[active_loss_mask]
active_end_labels = end_ids.view(-1)[active_loss_mask]
if pseudo is not None:
start_loss = self.criterion(start_logits, start_ids.view(-1)).view(-1, 512).mean(dim=-1) # torch.Size([batch_size])
end_loss = self.criterion(end_logits, end_ids.view(-1)).view(-1, 512).mean(dim=-1) # torch.Size([batch_size])
# nums of pseudo data
pseudo_nums = pseudo.sum().item()
total_nums = token_ids.shape[0]
# learning parameter
rate = torch.sigmoid(self.loss_weight)
if pseudo_nums == 0:
start_loss = start_loss.mean()
end_loss = end_loss.mean()
else:
if total_nums == pseudo_nums:
start_loss = (rate*pseudo*start_loss).sum() / pseudo_nums
end_loss = (rate*pseudo*end_loss).sum() / pseudo_nums
else:
start_loss = (rate*pseudo*start_loss).sum() / pseudo_nums + ((1 - rate) * (1 - pseudo) * start_loss).sum() / (total_nums - pseudo_nums)
end_loss = (rate*pseudo*end_loss).sum() / pseudo_nums + ((1 - rate) * (1 - pseudo) * end_loss).sum() / (total_nums - pseudo_nums)
else:
start_loss = self.criterion(active_start_logits, active_start_labels)
end_loss = self.criterion(active_end_logits, active_end_labels)
loss = start_loss + end_loss
out = (loss, ) + out
return out
















 3000
3000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









