






论文译读|伯克利人形机器人:基于学习控制的研究平台
-
原文地址:https://berkeley-humanoid.com/static/berkeley_humanoid.pdf
-
摘要:我们介绍了伯克利人形机器人,这是一种可靠且低成本的中型人形机器人研究平台,专为基于学习的控制设计。我们轻量化的自制机器人专门针对低仿真复杂性的学习算法,具有拟人化运动和对摔倒的高度可靠性。机器人狭窄的仿真到现实差距使其能够在各种户外环境中实现灵活而强大的移动,使用轻量域随机化的简单强化学习控制器。此外,我们展示了机器人行走数百米、在陡峭的未铺路面小径上行走以及单腿和双腿跳跃,以证明其在动态行走中的高性能。我们的系统能够进行全方向运动,并能在紧凑的设置下承受大的干扰,旨在实现基于学习的人形系统的可扩展仿真到现实部署。
-

-
图1:我们定制的人形机器人设计、训练和基于学习的控制器的仿真到现实部署。
-
-
1. 引言
-
市场上对中型人形机器人有强烈需求,这些机器人需要能够快速部署基于学习的控制策略,能抗摔抗故障,而且价格低廉,还能进行高动态运动。目前大多数双足和人形机器人较大,不安全,需要一组人来操作。短腿机器人的实验更容易,因为它们重量轻,不需要起重机,可以由一个人携带。摔倒通常不会损坏环境或机器人,使得实验设置更宽容。这些机器人可以在狭窄的实验室空间中进行测试,而且由于地面间隙有限,为实验验证创建粗糙地形相对简单。我们认为市场对机械可靠、低成本的短腿人形机器人有着巨大需求,这些机器人需要配备定制的高扭矩密度驱动器,专为快速学习策略迭代设计。
-
由于空间有限,短腿人形机器人的机械设计更具挑战性,需要安装如电机、传感器和布线等组件,因此需要使用紧凑高密度的驱动器,而这些驱动器往往非常昂贵或市场上没有现成的。在不牺牲性能或成本的前提下将所有组件集成在紧凑的体积中是困难的。此外,中型机器人更易操作,通常用于推动动态和灵活任务的极限,需要更高的扭矩重量比和更大的冲击可靠性。
-
中型人形机器人的控制更具挑战性,因为它们的重心低,对干扰的敏感性高,导致不稳定。它们的质量和惯性较低,使得这些机器人更灵活,但也更敏感,即使是小力量也会产生大的运动。较短的腿导致步幅减小,通常需要多步来抵消干扰。此外,这些机器人需要更高频率的腿部运动来快速调整脚的放置,要求精确的协调和控制。这些特性意味着关节的驱动必须快速准确以支持高频运动,控制策略需要异常精确和强大以匹配动态的短时常数。此外,基于学习的算法在控制人形机器人方面面临显著的仿真到现实差距,特别是在执行快速和动态运动时。因此,使用基于学习的控制来控制中型人形机器人提出了额外的挑战。
-
为了解决这些问题,我们提议定制一个中型人形机器人平台,特别强调促进基于学习的控制。为了实现精确、可靠和灵活的控制,我们利用基于学习的算法,专注于通过适当的硬件设计来缩小仿真到现实的差距。基于学习的算法使我们能够利用更便宜、更嘈杂的传感器来降低成本。为了优化仿真性能和准确性,同时实现高性能驱动,我们使用定制的模块化驱动器,集成传动装置、中空轴和EtherCAT通信。我们的贡献总结如下:
-

-
(i) 我们提出了一个可靠、低成本的中型人形机器人研究平台,重点是通过设计考虑缩小仿真到现实的差距,特别是为基于学习的控制设计。
-
(ii) 我们展示了我们的设计选择使我们能够使用一个最小组成的控制策略在复杂地形上执行动态和可靠的运动,特别是走在陡峭、狭窄、未铺路的小径上的挑战任务。
-
(iii) 最近的Isaac Lab发布的策略训练代码库将在被接受后开源,以支持未来的人形机器人研究。
-
-
-
2. 相关工作
-
人形机器人设计。我们将人形机器人分为三种主要尺寸:
-
(a) 全尺寸,相当于普通成年人的尺寸,
-
b) 中等尺寸,相当于孩子的大小,
-
© 小型,不是人类大小的小机器人。
-
-
全尺寸人形或双足研究平台通常重量较大,使用高齿轮比的谐波驱动器。这些平台主要能够行走和进行简单的手臂操作。一些平台利用用于高负载关节的循环驱动器,结合弹簧和连杆设计。这种设置简化了简化阶次、逐步模型控制器的设计。然而,对于最近的基于学习的算法,这些优化用于基于模型的控制的设计无意中影响了训练和部署。相比之下,最近开发了更多轻量化的平台,采用准直接驱动(QDD)驱动器,主要是虚拟手臂,能够执行更多动态任务。除了全尺寸人形机器人外,中型或小型人形机器人研究平台近年来也越来越受欢迎。这些平台都选择了QDD驱动器,设计上以更好的动态性能为目标,但大多数缺乏完全关节化的腿。另一方面,一些公司的新型人形机器人偏离了QDD:例如,Tesla Optimus使用线性驱动器和谐波驱动器,一些配有力传感器的负载单元,具有关节与驱动器之间复杂的传动装置。Boston Dynamics的液压Atlas在高度动态任务中表现出色,最新发布的电动Atlas展示了具有大范围运动的简化关节设计。这些公司的机器人设计精良,经过充分测试,但遗憾的是,大多数不向实验室研究人员提供,或不提供修改或改进底层系统的访问权限。
-
-
3. 系统概述
-
通信系统是我们机器人设计的另一个关键组件。为了实现准确且最低延迟的通信,我们选择了高带宽的EtherCAT协议。我们为定制的电机驱动器和IMU开发了定制的EtherCAT客户端。车载PC运行EtherCAT主控,并以1 kHz到4 kHz的频率与外围设备通信。USB和以太网连接也支持外部接口传感器,如深度摄像头、激光雷达或其他传感器。对于用户开发和调试接口,躯干内的路由器提供了有线和无线连接到车载PC。
-
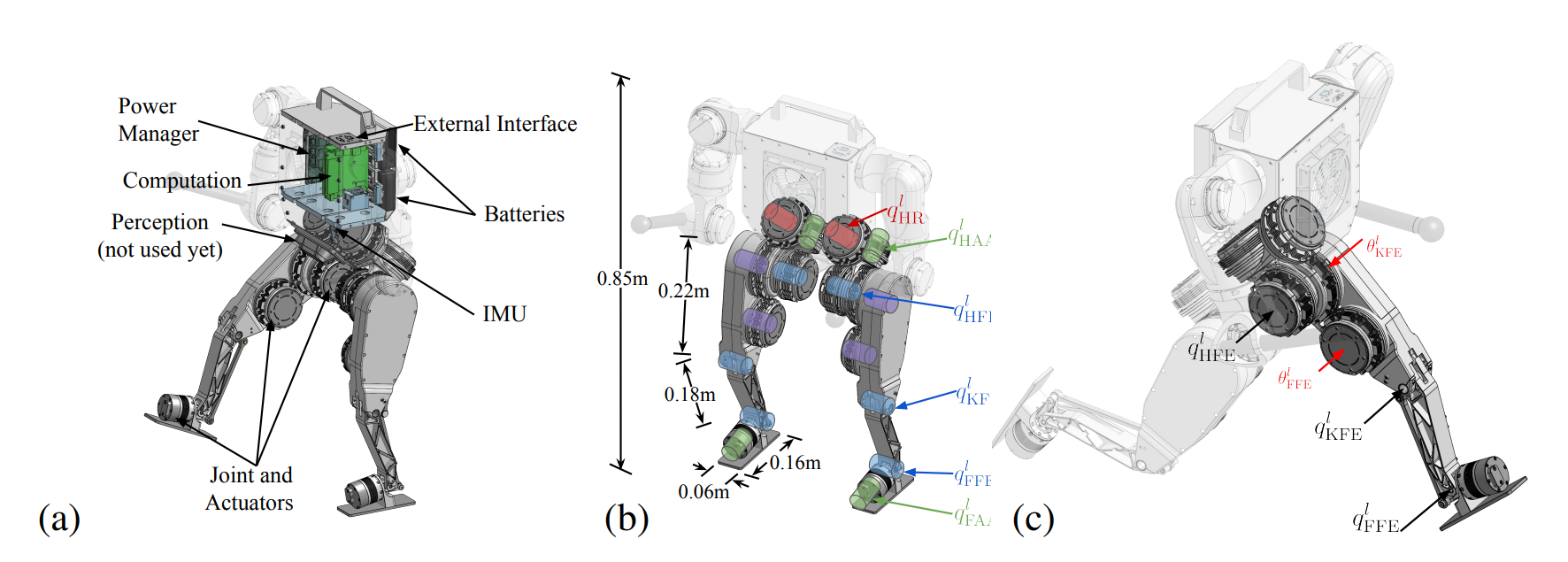
几乎每个机器人部件都是定制设计和制造的,包括驱动器、机械组件、电机驱动器、IMU、通信和电源管理板。这种对整个系统的全面了解使我们能够探索具有狭窄仿真到现实差距的新控制策略,并考虑到基于学习的算法对硬件的具体要求,即仿真友好、可靠和低成本、实验友好和拟人化。
-
3.1 仿真友好
-
动机:由于现代基于学习的运动策略趋势利用了无模型强化学习,并以大规模可并行化的模拟器作为学习平台,我们机器人的一个关键考虑因素是其仿真成本。例如,设计具有单向弹簧的传动连杆可能会减少关节电机的负荷,并吸收大冲击,但产生的机制涉及求解额外的动力方程,这些方程模拟起来异常困难,并导致并行计算成本高。此外,大多数模拟器通常以多刚体动力学模拟机器人,有些只能直接在关节空间应用扭矩,而不考虑驱动器传动,而另一些则需要更多的计算来解决传动中涉及的闭链运动学。然而,在执行高度动态任务时,驱动器和传动因素(如扭矩、速度、位置限制、传感器噪声、摩擦和连杆和转子的惯量)会显著改变驱动动态,这在关节空间中准确且高效地映射和随机化非常具有挑战性。此外,需要更多的计算和更小的时间步长来模拟通信延迟、马达/驱动器动态和不准确的执行速率,这进一步减慢了仿真速度。
-
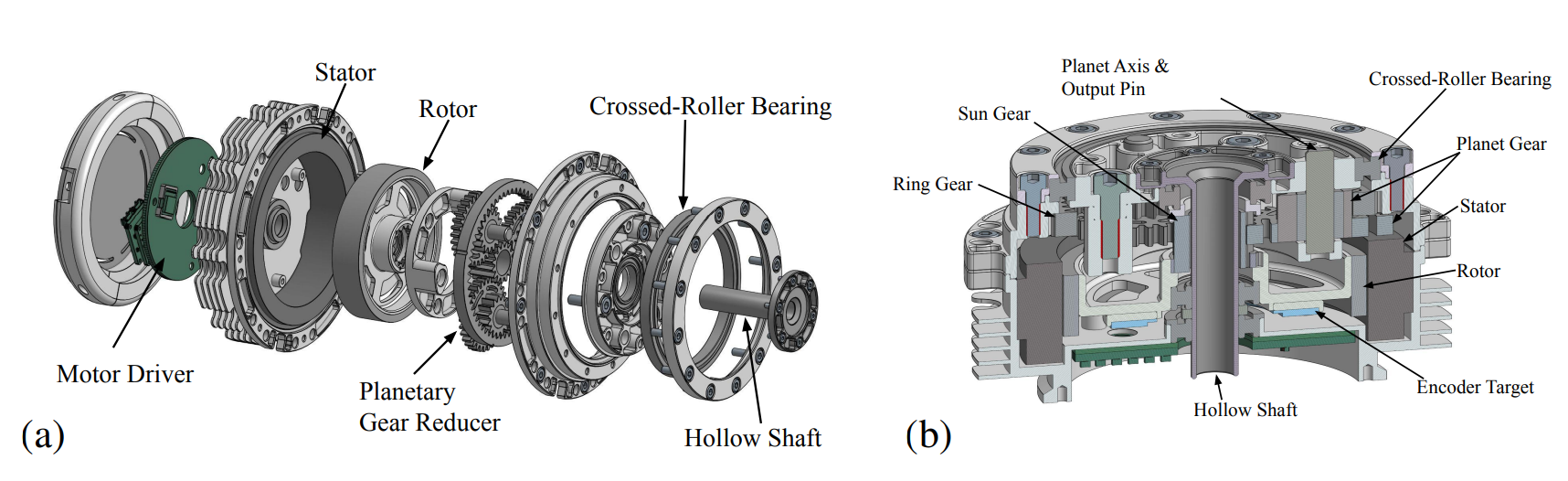
我们的方法:为避免这些困难,我们选择去除所有柔性或吸能组件,如弹簧或阻尼器,以及机器人运动链中的任何闭链运动学链,并使用最简单的驱动器-关节传动。正如图3所示,所有驱动器都配备了交叉滚子轴承,使得驱动器可以直接安装并用作关节。因此,可以通过将电枢添加到关节质量矩阵的对角线上来轻松模拟转子惯量,其他驱动器因素也可以像关节一样建模。一个例外是图2所示的FFE关节,使用了一个传动连杆来提供大扭矩,导致KFE和FFE之间的耦合但线性关节-驱动器映射。这种设计允许我们在仿真中将驱动器视为关节。此外,我们在驱动器中选择了具有QDD齿轮比的行星齿轮箱,这仅引入了易于在关节空间建模的轻微摩擦不确定性。通过在训练期间结合这些设计,我们可以专注于关节仿真,而无需考虑驱动器动态。为了避免模拟系统延迟,我们使用EtherCAT进行通信。这确保了最大延迟从0.5毫秒到2毫秒不等。电机扭矩控制带宽设置为1 kHz,使得驱动器可以作为扭矩源进行无延迟仿真。这些设计使得我们的机器人能够在NVIDIA A4500 GPU上以超过每秒90,000步的效率实现准确仿真。
-

-
图2:设计概述:(a) 主要组件,(b) 关节和关键尺寸,© 左腿的关键执行器和关节。
-
图3:(a)我们定制执行器的外观图,(b)我们定制执行器的剖视图。
-
-
-
3.2 可靠和低成本
-
动机:过去,人形机器人运动研究需要高端机器人、精确的传感器、仔细的保护和长时间的维修,限制了该领域的发展。
-
为了进一步加速该领域并做出改变,我们的机器人必须可靠且可访问,意味着它应该耐用且成本低。更可访问和可靠的机器人也为在人类环境中扩展人形机器人学习铺平了道路。
-
我们的方法:为了提高耐用性,我们使用高性能材料构建机器人。我们使用7075和6061铝材构建大部分主要组件,并使用SKD11钢材构建齿轮箱和连杆,使机器人能够在轻量结构下承受重击。电源和信号的电缆耐久性是机器人可靠性的关键因素,与环境的接触会由于摩擦和振动造成撕裂,给电缆耐久性带来显著挑战。为克服这一问题,我们选择在大多数驱动器中使用中空轴设计,电源和通信电缆通过关节的中空轴穿过两个运动体,最大限度地减少关节运动造成的撕裂。此外,使用定制的QDD驱动器使我们能够在不添加应变计的情况下估算关节扭矩。通过可靠的关节扭矩传感,可以使用广义动量观测器来估算每个脚的接触扳手,无需接触传感器或力/扭矩传感器,这进一步提高了机器人的可靠性。
-
完全定制的硬件使我们能够将机器人的成本降至最低,如表3所示。通过学习算法,我们通常能够增强对硬件不准确性的鲁棒性,从而使用更便宜的传感器并进一步降低成本。因此,与大多数先前工作中IMU成本约为1,000美元不同,我们可以使用成本不到一美元的手机级IMU ICM42688。这些设计有助于将整台机器人的成本降低到10,000美元以下,不包括手臂。请注意,表3中显示的大多数成本将在规模化生产中降低。唯一非定制的组件是计算机(Intel i7-1255U)和电池(DJI TB50),它们是为性能和安全而商用的。
-
-
3.3 实验友好
-
动机:过去,人形机器人的大小和重量特别麻烦。传统的全尺寸人形机器人通常比同等大小的人还重,这意味着处理机器人需要至少两到三个人的帮助。更重要的是,实验这种高扭矩驱动器(约300 Nm)的机器人是危险的,可能导致附近人员严重受伤。
-
我们的方法:通过适当选择机器人尺寸和定制的轻质材料,我们将重量减轻到仅16公斤,这使得我们在室内环境中只需一个机器人操作员就能进行实验,在室外环境中则可选配一个摄像师,包括指挥机器人、收集数据、拍摄视频,有时还要从故障中重置机器人。本文中报告的所有实验都是在这种设置下进行的。
-
-
3.4 拟人化
-
动机:使用拟人化设计的优势显著:通过具有与人体相似的主要自由度,可以实现更高的静态稳定性和类人动作。这带来了更广泛的适用性、更丰富的任务选择,以及更容易从广泛可用的人类演示中学习。
-
我们的方法:我们机器人使用每条腿6个自由度的拟人化设计,复制了人类腿部常见的自由度建模。相比之下,在踝关节的滚动方向上提供驱动提高了机器人在挑战性静态姿势(如操作远距离物体时)的稳定性,并使其能够平衡在一只脚上。此外,每个关节限位的设计与人体的相应物理限位紧密对齐。这使我们能够在确保足够的运动范围以模仿人类动作的同时,进一步保护硬件。
-
-
-
4 一个简洁的基于学习的控制器
-
通过一个为基于学习的控制设计的人形机器人平台,我们能够使用一个简洁的RL(强化学习)控制器实现稳健和灵活的运动。在本节中,我们首先介绍RL控制器的设计。然后,详细说明我们的人形机器人平台如何缩小RL控制器的仿真到现实差距。
-
4.1 强化学习公式
-
我们将任务公式化为马尔可夫决策过程(MDP),并利用RL来解决它们,因为在控制人形机器人方面,RL表现出很好的效果。我们通过以下方式创建了一个简洁的基于学习的控制器。我们用最小的观测和动作空间来公式化MDP。具体来说,我们只使用即时状态反馈作为输入,不使用短期或长期历史或教师-学生训练来估计环境参数。同样,我们不使用预定义的相位信号或参考运动来减少人为偏差。即时状态反馈包括原始的本体感知读数(基本角速度,投影重力矢量,关节位置,速度),来自状态估计器的基本线速度,速度命令和先前的动作。同样,动作空间仅包含期望的关节位置,这些位置由电机驱动器上的PD控制器直接转换为扭矩。
-
我们还只设计了具有最基本多层感知器(MLP)网络的演员-评论家结构。具体来说,每个网络的隐藏层大小为[512,256,128]个神经元,并使用ELU激活。策略通过PPO优化,并在Isaac Lab中训练。RL策略以50 Hz执行,状态估计器以1 kHz执行,PD控制器以25 kHz执行。
-
这个简洁的RL控制器有助于验证我们的硬件设计对于基于学习的控制的适用性。在没有在线系统识别或参考运动指导的情况下,我们的策略依靠硬件和学习算法的协同作用来实现狭窄的仿真到现实差距,确保训练中的稳健和灵活的运动性能能够在真实世界的机器人上完全展示。此外,它还可以作为我们平台上开发的其他算法的有效基准。
-
-
4.2 缩小仿真到现实的差距
- 硬件方面。我们通过硬件设计选择来缩小仿真到现实的差距。仿真到现实的差距的主要因素,除了传感器噪音外,还有建模误差和命令执行率、准确性和延迟。为了减少建模误差,我们将驱动器直接安装为关节或设计线性关节-驱动器映射,避免仿真可能导致不准确建模的结构。为了改进命令执行,我们采用高带宽扭矩控制,这导致了精确的执行率,并且透明的QDD驱动器动力学使得命令的扭矩能准确跟踪,并且通信延迟可以忽略不计。所有这些都导致硬件和仿真动力学之间的差异更小。
-
-
5 实验验证
-
在我们的实验中,我们旨在从三个方面验证我们的人形机器人设计如何促进学习运动控制:(1)我们的简洁RL控制器在学习人形机器人运动任务中的有效性。(2)通过我们的充分硬件设计,最小RL算法的仿真到现实的差距。(3)机器人的硬件可靠性。
-
5.1 学习控制性能
-
与以往利用先进架构的工作相比,在本工作中,我们强调我们的最小设计如何通过专注于适应基于学习的控制算法,利用第四节中介绍的基本RL控制器实现稳健和灵活的运动性能。
-
全方向行走
-
我们通过遵循矢状和横向方向上的线速度命令以及偏航角速度命令来训练我们的机器人执行全方向运动。在图4中,我们展示了前进、后退和左右转弯的例子。在接下来的段落中,我们重点展示了这个全方向控制器在各种地形上的性能以及对外界干扰的抵抗力。
-

-
图4:全方向行走。 (a-c) 机器人在实验室环境中向前走、原地转弯和向后走。 (d, e) 机器人在野外环境中向前和向侧面走。
-
-
-
在各种地形上行走
-
也许最能展示人形机器人先进性能的是它在各种日常环境中稳健行走的能力。如图5(a)所示,我们的机器人能够在各种户外地形上稳健行走,如草地、砖块人行道、未铺设的小径、沥青路、桥梁、混凝土路、跑道和瓷砖表面,以及楼梯和坡道。
-

-
图5:在不同地形上行走。(a) 机器人在八种不同类型的地形上行走。(b) 机器人攀爬相对陡峭且狭窄的未铺砌小径,上面覆盖着灰尘和石块。© 机器人在不平坦的道路上行走。(d) 机器人在岩石楼梯上转弯。
-
-
在这些环境中,我们想强调两个最具挑战性的地形。首先,如图5(b)及配套视频所示,我们惊讶地发现我们的机器人能够攀爬一条相对陡峭和狭窄、覆盖着尘土和石块的未铺设小径。即使对于成年人来说,这条小径也有点陡峭,更不用说我们的机器人,它的大小仅类似于一个5岁的孩子。具体来说,这条小径的坡度平均为20度,高于踝关节的向上俯仰范围,因此它必须向后走才能使躯干保持直立姿势,并稳固地踩在地面上。尽管如此,我们的机器人能够稳步行走、转弯,并从踩在松动的石块上恢复过来。
-
其次,如图5©所示,我们经常在城市环境中发现有明显裂缝和高度变化的不平道路。这些裂缝和滑溜的地板需要孩子和老人特别注意,有时会导致他们摔倒。在这种具有挑战性的地形上,我们的机器人能够在高度变化的楼梯间的小路中前后移动,并从滑倒中恢复过来。
-
为了进一步展示不平地形,我们制作了一组高度为4厘米(相当于全腿长的10%)的石阶,发现我们的机器人能够平稳地穿越这些石阶并在上面转弯,如图5(d)所示。能够应对这些具有挑战性的地形显示了我们人形机器人在运动控制方面的先进性能,即使使用的是这样一个基本的RL控制器,这归功于硬件设计中对基于学习的控制算法的精心调整。
-
-
扰动抗拒
-
测试策略的稳健性和硬件可靠性的一个关键方法是其从外部干扰中恢复的能力。我们通过随机踢机器人的不同部位施加瞬时力,同时它在原地踏步。如图6所示,这种扰动导致了显著的偏离正常行走姿势,使机器人几乎跌倒。然而,我们的机器人能够立即做出反应,在几步内从扰动中恢复稳定,并继续踏步。
-
除了在受控实验室环境中的平地上进行测试外,我们还在户外环境中重复了此测试,如在不平的草地上。在这些条件下,我们的机器人也能够从强烈的外力中恢复,如图6(b)所示。这进一步展示了我们人形机器人在现实场景中的稳健性。
-
图6:干扰抑制。机器人能够从大的外部干扰中恢复,例如 (a) 在实验室行走时从后面被踢,和 (b) 在野外行走时从侧面被踢。
-
-
-
长距离行走
-
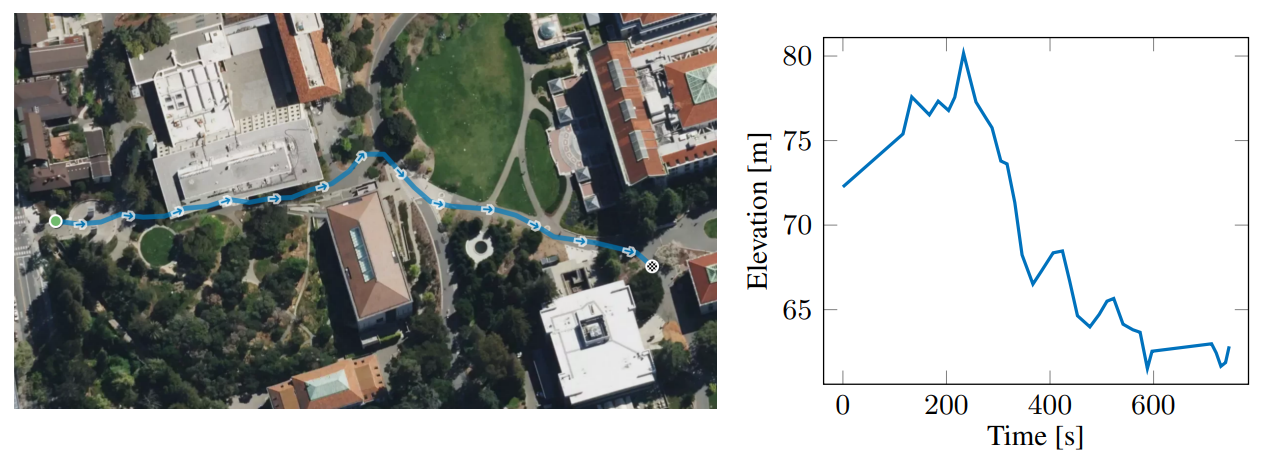
具有穿越地形和抗拒扰动的能力,机器人能够在多种地形上执行数百米的相对长距离行走。如图7所示,机器人在UC Berkeley校园自由行走10分钟,总距离为364米,包括上坡和下坡。此外,机器人能够在图5(b)所示的粗糙地形上稳步攀爬超过5分钟,覆盖距离为96米,海拔上升10.5米。校园行走的视频可见:https://youtu.be/STbB12-oc_w,粗糙地形行走的视频可见:https://youtu.be/Z2Bzslmu7DA。
-

-
图7:长距离行走的记录GPS可视化图。
-
-
-
-
5.2 仿真到现实的转移评估
-
由于大多数基于学习的算法完全在仿真中训练,仿真到现实的差距成为学习控制器在现实世界中性能的关键组成部分。我们从两个方面展示了我们机器人的小仿真到现实差距:(i)对运动任务指标的定量分析。(ii)执行高度动态运动任务的能力。
-
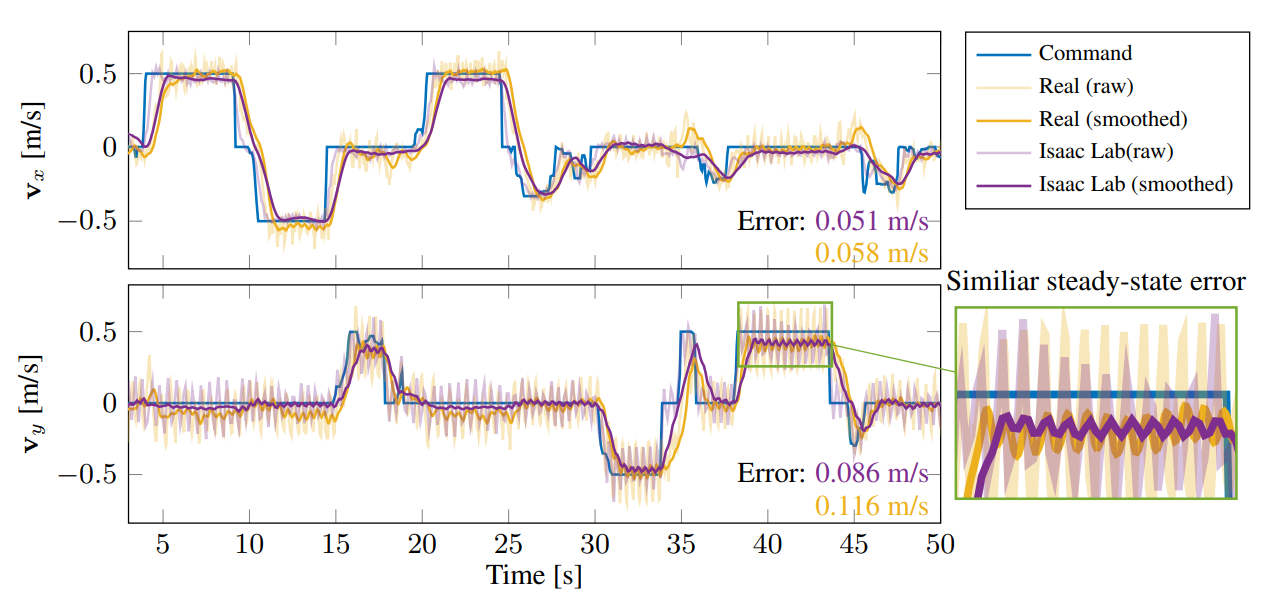
首先,我们通过绘制操作者给出的随机速度命令的跟踪性能来呈现仿真到现实转移的定量分析。如图8所示,我们的机器人能够在矢状和横向方向上紧密跟随快速变化的命令,具有小的稳态误差。在60秒的试验中,矢状方向上的平均跟踪误差为仿真中为0.051 m/s,硬件上为0.058 m/s。在横向方向上,仿真中误差为0.086 m/s,硬件上为0.1156 m/s。请注意,我们的RL控制器无法执行在线系统识别或适应,因为它在训练或部署期间无法访问历史数据。因此,这些小的跟踪误差差异表明训练期间的仿真MDP和现实世界部署的MDP之间的差距确实很小,这确认了我们硬件设计的狭窄仿真到现实差距。
-

-
图8:仿真到现实的差距评估。图中显示了指令的(蓝色)和实际的(黄色)基础线速度轨迹。实际值经过移动平均滤波器平滑处理,以更好地展示稳态误差。
-
-
其次,我们通过展示一个与第四节设置相同但奖励不同的跳跃控制器来展示执行高度动态运动的能力。如图9(a)所示,我们的机器人可以执行全方向跳跃、加速和减速,同时保持平衡。值得注意的是,机器人还能通过单腿跳跃展示出色的灵活性,这是一个非常具有挑战性的壮举。如图9(b)所示,尽管在单腿跳跃实验中使用了安全绳并需要少量平衡辅助,但绳子大部分时间是松弛的,机器人能够自行保持平衡。与之前工作的复杂算法设计相比,这进一步显示了硬件设计使我们能够通过简单的算法设计执行灵活的动作。
-

-
图9:跳跃 (a) 双腿跳跃和 (b) 单腿跳跃,具有明显的飞行阶段。能够用简单的强化学习控制器完成动态任务,展示了硬件设计的小仿真到现实差距。紫色框表示机器人处于单腿支撑阶段。
-
-
-
5.3 硬件可靠性
-
最后,对于基于学习的方法,硬件的可靠性至关重要。在整个工作中,我们记录了机器人在各种地形上共摔倒38次,包括混凝土路面和未铺设道路,如附录表4所示。由于可靠且轻量的设计,除了两次因螺丝松动和胶水问题引起的故障外,我们没有遇到任何硬件损坏。在大多数摔倒中,我们能够在3到5秒内重置机器人并恢复控制策略。易于快速重置不仅减轻了实验的负担,更重要的是,实现大规模现实世界部署的最终目标是必要的。
-

-
表4:在不同表面上记录的跌倒次数。
-
-
-
-
6. 结论与未来工作
-
在本工作中,我们介绍了伯克利人形机器人,这是一种可靠且低成本的中型人形机器人研究平台,专为基于学习的控制设计。我们的平台通过适当的硬件设计来缩小仿真到现实的差距,使得机器人能够使用最小组成的RL控制器在各种地形上实现稳健和灵活的运动。我们通过展示机器人执行动态任务的能力(如全方向行走、在不平地形上导航以及从外部干扰中恢复)来验证我们的设计。此外,我们还展示了机器人能够进行长距离行走和执行高度动态的动作(如跳跃)。
-
我们的研究结果表明,简单但适应良好的硬件设计可以促进基于学习的控制策略,从而实现稳健和灵活的人形机器人运动。这为进一步开发能够利用可靠硬件平台的更复杂的学习算法打开了可能性。
-
未来工作
-
虽然我们的结果是有希望的,但未来工作有几个方向可以增强伯克利人形机器人的能力:
-
高级学习算法:开发和集成更先进的学习算法,以进一步提高机器人在复杂和动态环境中的性能。
-
改进的硬件组件:探索使用更先进的硬件组件来增强机器人的性能,如更高扭矩密度的驱动器和更精确的传感器。
-
人机交互:研究人机交互功能的集成,以实现更自然和直观的控制方法。
-
自主导航:增强机器人的自主导航能力,使其能够在非结构化环境中独立操作。
-
能源效率:研究提高机器人的能源效率的方法,以延长其运行时间并减少能耗。
-
可扩展生产:探索可扩展的生产方法,以进一步降低成本,使平台更容易被更多的研究人员和开发者访问。
-
-
-
总之,伯克利人形机器人代表了在开发可靠且低成本的基于学习控制的人形机器人方面的重大进展。我们的平台为未来的研究和开发提供了坚实的基础,通过集成复杂的学习算法和稳健的硬件设计,推动人形机器人技术的发展。
-











































 2486
2486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









