









实现我们在概率论与数理统计课上学过的二项(binomial)分布,属于一种离散型随机变量(discrete random variable),其概率质量函数(probability mass function)为:
f(k;n,k)=Pr(K=k)=(nk)pk(1−p)n−k
其 E[X]=np,Var[X]=np(1−p)
import scipy.stats as st
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)计算数字特征
计算其常用矩(或者说是数字特征,比如一阶矩:期望,二阶矩:方差):
>>> n, p = 5, .4
>>> mean, var, skew, kurt = st.binom.stats(n, p, moments='mvsk')
# 'mvsk': mean, var, skew, kurt
>>> mean
array(2.0) # n*p = 5*0.4 = 2.
>>> var
array(1.2) # n*p*(1-p)=1.2或者我们首先创建一个服从二项分布(离散型)的随机变量,通过调用其成员函数的形式进行各种操作(也即是一种面向对象的编程方式):
>>> n, p = 5, .4
>>> rv = st.binom(n, p)
>>> mean, var, skew, kurt = rv.stats(moments='mvsk')计算概率质量函数(pmf:probability mass function)
>>> x = np.arange(rv.ppf(0.01), rv.ppf(0.99))
# ppf: percent point function
# ppf与cdf互为反函数
>>> x
array([ 0., 1., 2., 3., 4.])
>>> ax.plot(x, rv.pmf(x), 'bo', ms=8, label='binomial pmf')
>>> ax.vlines(x, 0, rv.pmf(x), color='b', lw=5, alpha=.5)
>>> ax.legend(loc='best', frameon=False)
>>>plt.show()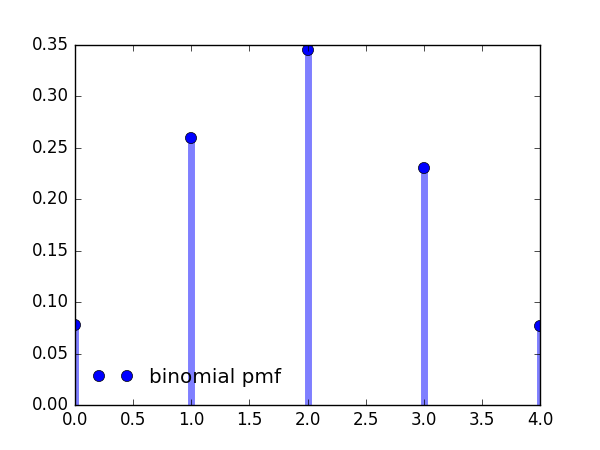
计算累计密度函数(cdf:cumulative density function)
>>> prob = rv.cdf(x)
>>> prob
array([ 0.07776, 0.33696, 0.68256, 0.91296, 0.98976])
>>> np.allclose(x, rv.ppf(prob))
True















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











