







损失函数,又叫代价函数(成本函数,cost function),是应用优化算法解决问题的关键。
1. 0-1 损失函数
误分类的概率为:
P(Y≠f(X))=1−P(Y=f(X))
我们不妨记 m≜fθ(x)⋅y (其中 y∈{−1,1} 。对于二分类问题,最理想的损失函数是 0/1 损失函数,
- 当 fθ(x) 与 y 有相同符号时,损失为 0;
- 当
fθ(x) 与 y 符号不同时,损失为 1;
0/1 损失函数既不是处处可微(乘积,也即
2. 多类 SVM 的损失函数(Multiclass SVM loss)
在给出类别预测前的输出结果是实数值, 也即根据 score function 得到的 score( s=f(xi,W) ),
Li=∑j≠yimax(0,sj−syi+1)
- yi 表示真实的类别, syi 在真实类别上的得分;
- sj,j≠yi 在其他非真实类别上的得分,也即预测错误时的得分;
则在全体训练样本上的平均损失为:
L=1N∑i=1NLi
scores = np.dot(W, X)
correct_scores = scores[y, np.arange(num_samples)]
loss = score - correct_scores + 1
loss[y, np.arange(num_samples)] = 03. hinge 函数(折页函数)
仍然作如下记号, m≜fθ(x)⋅y ,hinge 函数的形式为:
Jhinge=min{0,1−m}
二者的几何图形为:
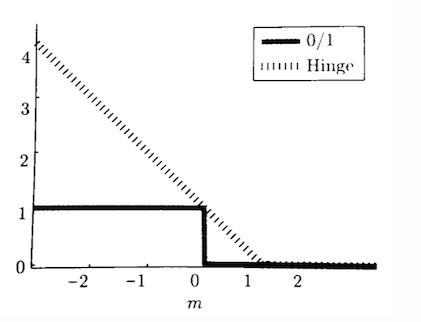
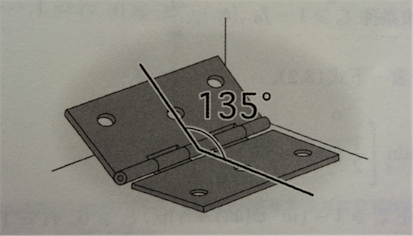
Hinge 损失的名字是源自它跟打开 135° 的折叶(hinge)长得很像。
















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











