







正态分布的概率密度函数(Probability Density Function, PDF)是描述正态分布特征的数学公式。正态分布是一种连续概率分布,广泛应用于统计学、自然科学、社会科学等领域。其概率密度函数的标准形式如下:
正态分布的概率密度函数公式

正态分布的特性
- 对称性:正态分布是关于均值 μ 对称的,均值、众数和中位数相等。
- 68-95-99.7 规则:在正态分布中:
- 约68%的数据落在均值 ± 1 个标准差的范围内。
- 约95%的数据落在均值 ± 2 个标准差的范围内。
- 约99.7%的数据落在均值 ± 3 个标准差的范围内。
- 渐近性:正态分布的尾部逐渐接近于横轴,但永远不会与之相交。
应用
正态分布的概率密度函数在许多领域中都有广泛的应用,包括:
- 统计推断:许多统计检验(如t检验、方差分析)假设数据服从正态分布。
- 质量控制:在制造业中,正态分布用于监控产品质量。
- 金融分析:在风险管理和投资组合优化中,正态分布用于建模资产收益率。
- 自然科学:许多自然现象(如测量误差、身高、智商等)都近似服从正态分布。
示例
假设某个班级学生的考试成绩服从正态分布,均值为 75 分,标准差为 10 分。我们可以使用上述概率密度函数来计算特定分数范围内的概率,或者绘制出成绩的分布曲线。
总结
正态分布的概率密度函数是理解和应用正态分布的基础。它不仅帮助我们描述数据的分布特征,还为统计推断和决策提供了重要的理论支持。
案例
正态分布的概率密度函数(PDF)在许多实际应用中都能找到案例。以下是几个具体的案例分析,展示正态分布如何在不同领域中应用。
案例 1:人的身高
背景
假设我们对某个国家成年男性的身高进行研究,已知该国成年男性的身高服从正态分布,均值为 175 cm,标准差为 7 cm。
应用
-
描述数据分布:
- 使用正态分布的PDF,可以绘制出身高的分布曲线,显示大多数人的身高集中在175 cm附近,随着身高的增加或减少,概率逐渐降低。
-
计算概率:

案例 2:考试成绩
背景
某大学的统计学期末考试成绩服从正态分布,均值为 75 分,标准差为 10 分。
应用
-
描述数据分布:
- 绘制考试成绩的PDF,显示大多数学生的成绩集中在75分附近。
-
计算特定概率:

案例 3:产品质量控制
背景
某工厂生产的零件直径服从正态分布,均值为 10 mm,标准差为 0.2 mm。工厂希望控制产品质量,确保95%的零件直径在 9.6 mm 到 10.4 mm 之间。
应用
-
计算控制范围:

-
质量控制决策:
- 如果发现某批次的零件直径超过10.4 mm,工厂可以决定停止生产并检查生产设备,以确保产品质量。
正态分布的概率密度函数推导
正态分布的概率密度函数(PDF)是通过一些数学推导和假设得出的。以下是推导正态分布概率密度函数的基本思路和步骤:
1. 正态分布的基本形式
正态分布的概率密度函数通常表示为:

2.2. 对称性和形状
正态分布的一个重要特性是它的对称性。我们假设这个分布是关于某个均值μ 对称的,并且随着离均值的距离增加,概率密度逐渐减小。我们可以假设 ( f(x) ) 的形式与(x−μ) 2
有关,因为平方项在均值处达到最小值(0),并且随着 ( x ) 离开均值而增加。
2.3. 选择指数函数

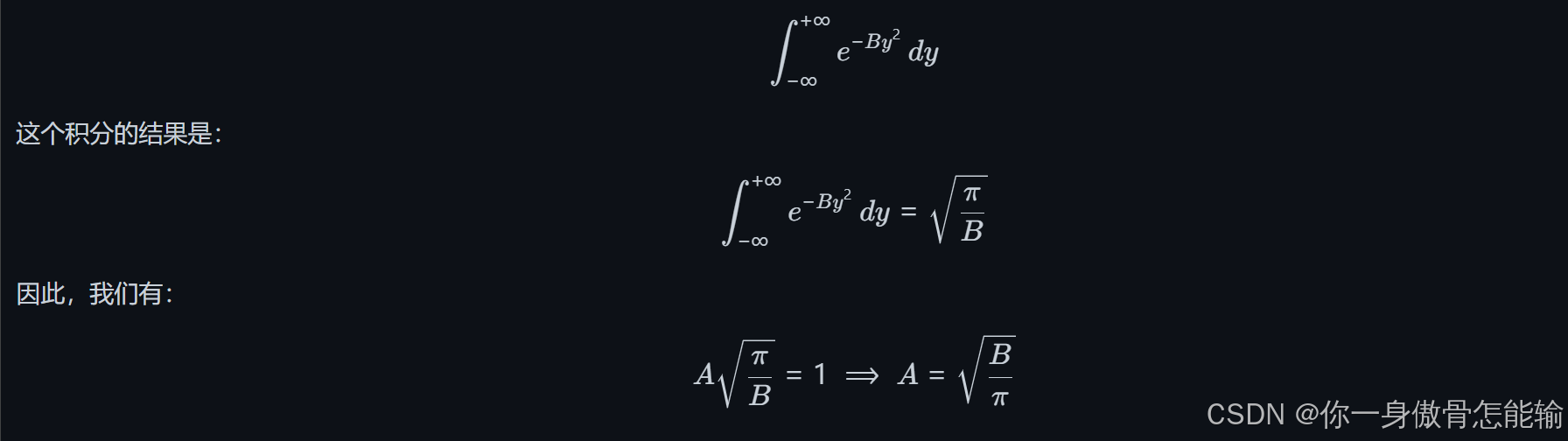
2.5. 选择 ( B )

3. 总结
通过上述推导,我们得到了正态分布的概率密度函数。这个函数不仅满足概率密度的基本性质(非负性和归一化),而且反映了数据在均值附近的集中趋势和随着离均值的距离增加而迅速减小的特性。正态分布的广泛应用和重要性使得这一推导在统计学和自然科学中具有重要意义。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











