







在各类大数据研究中,有一类数据是按照时间顺序排列、随时间迁移不断变化的,称为时间序列(Time Series)。时间序列广泛的存在于各行各业中,如 医学医疗、金融财经、水文分析、电力等领域。此外,在生物 基因、物体形态识别等与时间顺序无明显关联的数据类型中,也可以按照一定的规则将其转换成时间序列模式,进而利用时间序列数据挖掘技术进行分析。鉴于时间序列具有数据量大、数据维度高、持续积累等特性,如何从中挖掘潜在的规律和信息已经成为学术界与工业界的研究热点。时间序列数据挖掘已经成为了二十一世纪十大最具挑战性数据挖掘领域的研究内容之一。
随着时间的推移,时间序列表现出来的波动趋势、周期、波峰、波谷等特征中都蕴含着重要的规律和信息,国内外研究人员一直致力于寻求有效的技术路线对时间序列进行探索。
传统的时间序列数据挖掘是基于统计学的理论来进行的。
然而,传统的时间序列挖掘着重于全局,即是构建模型来拟合分析整条时间序列数据。
相对于传统的大数据分析,时间序列数据自有其特性,将传统的方法直接应用于时间序列数据挖掘中尚存在一些不足:
- 其一,传统的分析模型要求数据的分布符合一定的规则,否则,分析结论难免出现较大失真;
- 其二,时间序列具有数据量大、维度高的特征,基于全局的分析往往耗时特别长,且会产生“维灾”问题,导致分析性能大幅下降;
- 其三,实际应用中的时间序列数据挖掘往往更注重于时序数据的局部特征,如相似的波动趋势、异常的数据区间、预测趋势变化等。
时间序列挖掘领域主要包括时间序列的降维表示、相似性检索、分类、聚类、异常检测、预测等研究方向。每个研究方向有其特色的研究内容,各研究方向之间又相互关联、相辅相成。例如,通过时间序列降维表示,将高维度的时间序列数据转换为低维度的特征表示,进而用于优化序列相似性检索:时间序列的分类、聚类研究成果,可延伸用于时间序列的异常检测等。
一、时间序列降维表示
时间序列降维表示方法整体上可以分为四大类:
- 基于模型的降维表示方法;
- 数据非自适应的降维表示方法;
- 数据自适应的降维表示方法;
- 数据驱动的降维表示方法;
1、基于模型的降维表示
基于模型的降维表示方法通常基于时间序列是由某种模型产生的假设,然后使用模型的相关系数或参数来实现降维表示,比较常用的如统计模型【98】、马尔科夫链模型199】、隐马尔可夫模型【100】、回归模型【36’101]等等。Nanopoulos等人在文献198J中提出了一种利用特征抽取(Feature Extrac- tion)的统计模型,并将其应用到多层感知机(Multi Layer Perceptron)神经 网络中进行时间序列分类研究。马尔科夫链是一种基础的基于模型的降维表示方法。隐马尔可夫模型相较于马尔科夫链稍显复杂,Panuccio等人在文 献[100l中提出了一种基于隐马尔科夫模型的时间序列聚类方法,Cheng等人在 文献【89】中提出了一种概率性平滑的隐马尔可夫模型(Probablistic Smoothing HMM,psHMM)用于预测时间序列。时间序列位图(Time Series Bitmaps) 【94】也是一种基于模型的降维表示方法,它主要用来可视化时间序列。在回归模型研究方面,李爱国等人提出了一种分段多项式表示(Piecewise Polynomial Representation,PPR)的回归分析模型【102】。 总体而言,合适的模型能够很好地表达时间序列的数据特征,其在研究不定长、有噪声的时间序列数据上有一定优势。然而,模型假设、模型评估以及参数设定等过程往往耗时过长,且需要配合相关领域的先验知识,存在一定的领域局限性。
2、数据非自适应的降维表示
数据非自适应的降维表示方法是将原始时间序列转换到不同的空间,而转换的方法、参数系数的设定均与数据无关(Independent of Data)[103】。
在数据非自适应降维表示方法中,基于域变换的表示方法和分段聚合近似表示方法(PAA)是最具代表性的两类方法。
2.1 基于域变换的表示方法
基于域变换的时间序列表示方法是根据信息处理的方式将时间序列数据在时间域与频率域之间进行转换,然后利用在频率域下有限个特征数据表示原始时间序列数据。其中,离散小波变换(Discrete Wavelet Transform,DWT)和离散傅里叶变换(Discrete Fourier Transform,DFT)是最典型的两种基于域变换的表示方法,它们 既有一定的联系,又有所区别。Agrawal等人在文献【20】中首次利用DFT 变换后的前m个系数作为时间序列的降维表示以解决全序列匹配问题。 DFT变换的核心思想在于将时间序列看作离散的数据信号,然后将其从时间域映射到频率域上。相较于DFT方法,DWT方法通常采用Haard’波 变换[104】来实现时间序列的降维表示,它不仅包含频率域信息,同时也包含了时间域信息,也就是说DWT具有时频局部化能力。然而,DWT在转化时要求时间序列数据长度必须是2的倍数,在实际应用中需要对原始数据做一些必要的预处理工作。需要说明的是,基于域变换的表示方法根据特征系数的选择量不同,亦可归属为数据自适应的降维表示方法。
2.2 分段聚合近似表示方法
时间序列的分段聚合近似表示方法是一种非常高效、简便的降维表示方法,它将时间序列分割为长度相等的分段,然后利用分段均值组成的一组向量来降维表示原始时间序列【25】。PAA的降维表示过程是非常高效的,其降维表示的关键在于分段数Ⅳ。Ⅳ越大,PAA降维表示的精度越高,丢失的信息越少,反之,其降维表示后的序列越粗糙,丢失的信息也就越多。综合来看,PAA的主要问题在于利用均值降维表示后的时间序列,丢失了原始数据的极值、趋势等关键特征信息。为此,Hung等人⋯在PAA的基础上做了改进,增加了分段数据 序列的趋势特征,即斜率。
3、数据自适应的降维表示
数据自适应的降维表示方法通常是利用任意长度的序列分段来近似表示原始时间序列,在近似表示时尽量最小化拟合误差。典型的数据自适应的降维表示方法主要有以下四种。
3.1 分段线性表示方法(Piecewise Linear Representation,PLR)
分段线性 表示方法是一种简单、直观的时间序列降维表示方法。该方法使用拟合直线来近似表示原始时间序列,能够保留数据的趋势特征,其在时间序列数据挖掘分析中具有广泛的应用场景。分段线性表示一般有两种实现方法,即线性插值(Linear Interpolation)㈨105】和线性回归(Linear Regression)[21】。线性插值方法利用首尾相连的线段来近似表示;线性 回归则是用最优的拟合线段来进行表示,该方式能够保证拟合精度、降低表示误差,但是在视觉上会出现线段脱节(不连续)的现象。尽管方法名称和实现细节略有不同,整体上可将分段线性表示方法的实现方式分为三类:基于滑动窗口的方法(Sliding Window,SW)、基于 自顶向下的方法(Top.Down)和基于自底向上的方法(Bottom-Up)。
- 基于滑动窗口的方法是一种在线的(Online)分段线性表示方法,即 是其能够持续地对时间序列数据进行降维表示(时间序列流数据)。
该方法以时间序列分段的最左端为处理起始点,随着窗口的不断扩大,利用直线段来近似拟合窗口内的数据,并计算拟合误差,直到窗口内数据点的拟合误差超过设定的阈值,则获取到了当前分段。重复以上过程,持续对时间序列数据进行分段线性表示。 - 基于自顶向下的方法首先在时间序列中找到能够使拟合误差最小的分段点,然后在该分段点处进行分割。递归地对每一个分段进行如上分割操作,直至分段的拟合误差小于设定的阈值。
- 基于自底向上的方法的实现过程与自顶向下的方法相反,其首先在时间序列中找到具有最小合并误差的两个相邻的数据子序列,然后将此两条数据子序列合并形成一条新的数据子序列。如此重复以上过程,直至最小合并误差超过设定的阈值。
3.2 符号化表示方法(Symbolic Representation)
时间序列符号化表示方法是 将数值型的时间序列数据转换为字符串序列的过程。Lin等人【27】首次提 出了支持下界距离且可用于时间序列流数据降维的符号化表示方法,即基于分段聚合近似的符号表示方法(Symbolic Aggregate approXimation, SAX)。SAX方法首先需要将原始时间序列Z.标准化,即将其转换为均值为0、标准差为1的数据序列。接着,将标准化后的数据利用PAA方法处理,得到每个分段的均。最后将每个分段均值映射到符合正态分布的区域中以确定最终的符号表示。符号化表示方法可以充分利用文本挖掘的相关算法来解决时间序列数据挖掘分析问题,如Keogh等人结合SAX 表示方法提出了一种启发式的异常检测算法HOT SAX[no】,用于高效 发现时间序列中的异常序列。Xi等人将物体形状数据转换为时间序列 数据模式,并提出了利用SAX表示方法进行物体识别的研究方法[111】。从SAX的降维表示过程中可以发现,其利用了PAA的方法获取分段均值,因此SAX也同样具有PAA的缺陷,即忽略了原始时间序列中的极值信息和趋势信息等。基于这种情况,国内外研究人员对符号化表示做了优化与改进,闫秋艳等人提出了一种基于关键点的SAX改进算法(KP_SAX),能够有效提升符号化表示后的序列区分度。
3.3 自适应分段常量近似方法(Adaptive Piecewise Constant Approximation,APCA)
方法利用时间序列的趋势特征将原始时间序列进行不等长分割,然后利用分段均值近似表示。相较于PAA方法,APCA具有更小的拟合误差。需要说明的是,根据原始时间序列特征选择合适的方法进行不等长分割是一项复杂的工作,常用的方法有动态时间规划、小波变换
方法、滑动窗口方法等。
3.4 奇异值分解方法(Singular Value Decomposition,SVD)
SVD方法以主 成分分析(Principal Component AnMysis,PCA)方法为驱动,利用数 值计算中KL分解将高维度的时间序列转换为低维度数据。该方法已广泛应用于模式识别、图像索引等领域。需要说明的是,SVD方法降维表示的时间复杂度为O(Nm2),其中Ⅳ是时间序列数据库的序列数目,m为每条 时间序列的长度。与此同时,SVD是对整个时间序列数据库的降维方法,当需要插入或删除一条时间序列时,整个时间序列数据库都需要重新计算,耗时较长。
4、数据驱动的降维表示
数据驱动的降维表示方法的特点在于降维表示的程度完全由数据自身驱动【7EI’103】。裁剪表示方法(Clipping Representation)[113]是将时间序列离散 化为0、1组成的二进制字符串。Son等人对剪裁表示方法进行了优化,提出 TIPIP[114】、MP—C[115】的裁剪表示方法,并理论证明了IPIP和MP—C方法的距离计算方法均满足下界定理,可用于高效构建索引结构,加速时间序列的相似性检索过程。基于网格的表示(Grid—based Representation)1116]也是一种典型 的数据决定的降维表示方法。此类表示方法的主要优势在于空间和时间复杂度较低,可有效应用于海量的时间序列数据挖掘分析。
二、时间序列相似性度量
时间序列相似性度量是时间序列数据挖掘的一项重要的基础工具,它主要用于衡量时间序列数据对象之间的相似性,亦称为距离。
时间序列相似性度量的五类方法包括:
- 基于形状的距离、
- 基于编辑的距离
- 基于特征 的距离
- 基于模型的距离
- 基于压缩的距离
1、欧氏距离
欧氏距离是一种易于理解、便于实现且计算简单的相似性度量方法,它是闵可夫斯基距离(Minkowski Distance)的一种特殊情况。计算时间序列的闵可 夫斯基距离时,是将长度为n的时间序列看作rt维数据空间中的每一个数据点, 则距离即为此rt维数据空间中两个数据点的距离,且要求两条时间序列的长度是一致的。假设两条时间序列分别为Q={ql,q2,⋯,gn)和C=C1,C2,⋯,%), 其中n为序列长度,则Q与C的闵可夫斯基距离可由公式2.1计算得出。
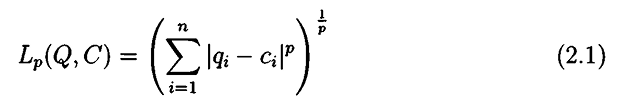
2、动态时间弯曲距离
动态时间弯曲(DTW)允许通过弯曲时间轴来找到最好的对齐方式,而不是像欧氏距离那样要求按照时间轴一一对应,因此DTW是一种在时间轴上“一对多”的相似性度量方法。图2.1所示为DTW距离的计算过程,可以看出数据点的映射在时间轴上出现了弯曲,以便找到最优的距离对齐方式。
3、符号化距离
符号化表示方法将数值型的时间序列数据转换为字符串序列,其相应的相似性度量方法也就从数值型的距离度量转换为基于符号的距离度量。如前文所述,基于分段聚合近似的符号表示方法(SAX)是一种典型的符号化表示方法,其符号化距离度量是基于欧氏距离的,字符间的距离可通过一个基于正态分布的查找表获得。
三、时间序列异常检测
时间序列异常检测是时间序列数据挖掘领域的重要研究方向之一,其目标是从海量的时间序列数据中找出那些“不正常”的数据点或数据序列。相对于庞大的时间序列数据来说,异常的数据量虽然较少,但是其重要程度不可忽视,往往在这些异常数据中隐含着重要信息。例如,银行系统出现异常的流水数据可能来自于信用卡诈骗11311;交通管理系统出现的异常时间序列数据可能是由于发生了交通事故1132】等。因此,在实际应用中,及时发现异常情况,有利于保障相关系统的正常运行、降低各类损失,是一项非常有意义的研究工作。
研究时间序列异常检测,首先应该确定什么是异常。目前学术界对Hawkins 等人提出的异常定义是普遍认可的[1331。以这个定义为基础,国内外研究人员从实际问题出发对异常检测做了大量研究,因其研究的知识领域不同,对异常的称呼或定义也略有不同,主要有异常(Anomaly)【78’85]、反常(Deviant) ⋯、奇异(Surprise)【79]、新颖(Novelty)Is2】、不和谐(Discordant)[4】等。 在以上术语中,Anomaly和Outlier是国外对时间序列异常检测中最常用的两个 术语【84】,本文统一使用“异常”予以描述。
1、异常类型
对于时间序列异常的检测研究,总体上可以分为以下三类:
1.1 数据点异常(Point Anomalies)
在时间序列中存在着一些特殊的数据点,这些数据点的波动规律与其他数据点有明显的不同,因此,从时间序列中发现这些具有罕见行为的数据点即为数据点异常检测。数据点异常的一个关键特征在于时间序列可以在很短 的时间内恢复到“正常”的状态,即是说,异常数据点的前后时间域内的数据点基本都是正常的。
1.2 下文异常(Contextual Anomalies)
如果时间序列的某个数据在特定的时间域内是异常的,而在其他时间域是正常的话,则称其为上下文异常(或条件异常)。简单来讲,即是说异常发生的位置与其前、后时间域的形态特征有较大出入。
1.3 序列列异常(Collective or Pattern Anomalies)
序列异常即是在时间序列中找出那些与其他子序列差异最大的序列。在异常序列中,单独其中的数据点也许不是异常的,但是当将序列整体与其他子序列相比较时,就可发现异常序列在趋势形态、数据域范围等方面与其他子序列有明显的不同。
2、异常检测技术分类
就时间序列数据来讲,可以根据是否有标签(Label)来将异常检测的 方法分为三种模式:
- 监督式异常检测(Supervised Anomaly Detection)、
- 半监 督式异常检测(Semi—supervised Anomaly Detection)
- 非监督式异常检测 (Unsupervised Anomaly Detection)。
需要说明的是,标签是指用于描述时间序 列是“正常”或“异常”的数据标记,亦可称为类别(Class)。
2.1 监督式异常检测(Supervised Anomaly Detection)
监督式异常检测技术需要有一组时间序列训练数据集,在这组数据集中明确的标注了每条时间序列的标签或类别,即“正常”或“异常”。基于训练数据集来构建异常检测模型。最后,利用此模型来判断待检测时间序列是正常或异常的。监督式异常检测方法主要面临两个问题:
- 其一是在训练数据中,相对于正常时间序列来讲,异常的数据量太小,会对检测效果产生影响;
- 其二实际操作中很难精确地标注数据是正常或异常,而且异常的情况也难以全部覆盖。
2.2 半监督式异常检测(Semi-supervised Anomaly Detection)
与监督式异常检测相同,半监督式异常检测也需要一组时间序列训练数据集。与之不同的是,此训练数据集中仅需包含正常的时间序列。
半监督式异常检测技术的一种典型方法是基于训练数据集为正常时间序列数据建立模型,然后利用该模型识别待检测数据中的异常。
由于训练中不需要标注异常序列,半监督式异常检测方法的应用相对更广泛。
2.3 监督式异常检测(Unsupervised Anomaly Detection)
相对于以上两种异常检测技术,非监督式异常检测不需要训练数据集。
此类技术的核心思想在于异常的情况相对于正常的情况而言是很少的,且其与正常情况存在较大的差异,这种差异可以体现在数据之间的距离远近、分布密度、偏离程度等方面。
结合实际应用领域与时间序列的特征可知,精确标注正常或异常时间序列的可操作性是难以保证的,这主要由于不同领域时间序列数据的波动频率、幅度、周期等有所不同,且随着时间的推移和技术的改进,时间序列的特征是会变化的。
因此,非监督式异常检测技术具有重要的研究价值和广阔的应用前景。
3、异常检测方法
以上分析了时间序列异常检测的研究内容和技术分类,异常检测作为时间序列数据挖掘分析的一个重要研究领域,也越来越受到国内外研究人员的关注,目前时间序列的异常检测方法大体可以分为以下几类:
3.1 基于统计的异常检测
此类方法是基于统计学理论基础,假设待检测的数据集存在一个分布或者某种概率模型,如正态分布、泊松分布等,然后处于分布的低概率区域或边缘区域的数据即判定为异常。
基于统计的异常检测一般需要充分的数据基础和相应的先验知识,此时检测效果可能是非常有效的,然而,基于统计的异常检测方法一般是针对单个属性或低维数据的,而对于高维度的时间序列数据就难以估计其真实的分布。
3.2 基于聚类的异常检测
此类方法利用聚类算法(如K-means、DBSCAN等) 对待检测数据进行聚类,通过聚类的结果来分辨正常与异常的数据,是一种典型的非监督式异常检测技术。
通常来讲,基于聚类的异常检测可基于三种假设来分辨异常数据,即:
- 不属于任何簇(Cluster)的 数据即为异常;
- 距离簇中心很远的数据即为异常;
- 归属于数据点少或稀疏簇的数据即为异常。
使用聚类算法进行异常检测,可利用大量已有的聚类研究成果。
但是,聚类与异常检测还是有较大差异的,异常检测的目标在于寻找不正常的数据,而聚类的目的在于确定数据归属的类别。
而且,很多聚类算法并未针对时间序列数据做优化,算法执行效率往往不高。
3.3 基于分类的异常检测
此类方式是通过训练数据集来构建一个分类模型(分类器),然后利用此分类模型对待检测数据进行分析并判断是否异常。
根据训练数据集中数据标签的分类情况,可将基于分类的异常检测分为:
- 多类别(Multi-class)异常检测方法:训练集中包含多种类别的正常数据,使用此分类器进行异常检测时,不属于正常类别的数据即判定为异常
- 单类别(One-class)异常检测:方法的训练集中只包含正常(或异常)数据,此分类器会训练得出正常(或异常)的边界,在此边界之外的即为异常(或正常)。
基于分类的异常检测方法需要充分的训练数据集来训练分类器,以确保异常检测的有效性和精度,然而在实际应用中,难以精确标注数据是正常或异常,而且正常或异常的情况也难以全部覆盖。
3.4 基于距离的异常检测
此类方法的核心思想在于利用某种相似性度量方法,计算数据对象之问的相似性(距离),当某个数据对象与其他对象距离较远时,可判定其为异常。
基于距离的异常检测克服了基于统计分布的异常检测方法的主要缺陷,且其实现简便、易于理解,国内外对此类方法已经有了大量研究和应用。
很多相似性度量方法都可应用到此类异常检测中,如欧氏距离、动态时间弯曲、符号化距离等。
此外,为了有效提升基于距离的异常检测算法的运行效率,一般需要与时间序列降维表示配合使用。
因此,一种高效、拟合效果好的时间序列降维表示方法也是此类异常检测的关键,是需要注重研究的内容。
3.5 基于密度的异常检测
此类方法的关键在于计算数据对象的异常得分来反映其异常程度,异常得分取决于一个数据对象相对于周围相邻数据对象的孤立程度,可通过计算当前数据对象周围数据对象所处位置的平均密度与当前数据对象所处位置的密度的比值得出。
以上即是局部异常因子(Local Outlier Factor,LOF)的核心理念,LOF认为异常不应该是一种二元属性,而应该是一种程度的度量,LOF值越大表明其异常程度越高,越有可能是异常。
相对于基于距离的异常检测,基于密度的异常检测思路更贴近于Hawkins对异常的定义。
然而,此类异常检测方法的时间复杂度通常较高,因此,如何提高基于密度的异常检测算法效率是一项具有挑战性的研究工作。
参考资料:
《基于时间序列挖掘的异常检测关键技术研究》
时间序列预测/相似性搜索/异常检测
KDD 2021丨时间序列相关研究论文汇总
【时间序列】时间序列预测算法总结














 6746
6746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









