







大家好,我是秃头了依然在敲代码的小鱼。
最近小鱼又整了一个开源库,结合YOLOV5订阅图像数据和相机参数,直接给出一个可以给出识别物品的坐标信息,方便进行识别和抓取,目前适配完了2D相机,下一步准备适配3D相机。
开源地址:https://github.com/fishros/yolov5_ros2
YoloV5_ROS2
基于YoloV5的ROS2封装,给定模型文件和相机参数可以直接发布三维空间置进行抓取操作。
1.安装依赖
sudo apt update
sudo apt install python3-pip ros-humble-vision-msgs
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple yolov5
2.编译运行
colcon build
source install/setup.bash
ros2 run yolov5_ros2 yolo_detect_2d --ros-args -p device:=cpu -p image_topic:=/image
使用真实相机,修改默认话题image_topic:=/image
ros2 run image_tools cam2image --ros-args -p width:=640 -p height:=480 -p frequency:=30.0 -p device_id:=-1

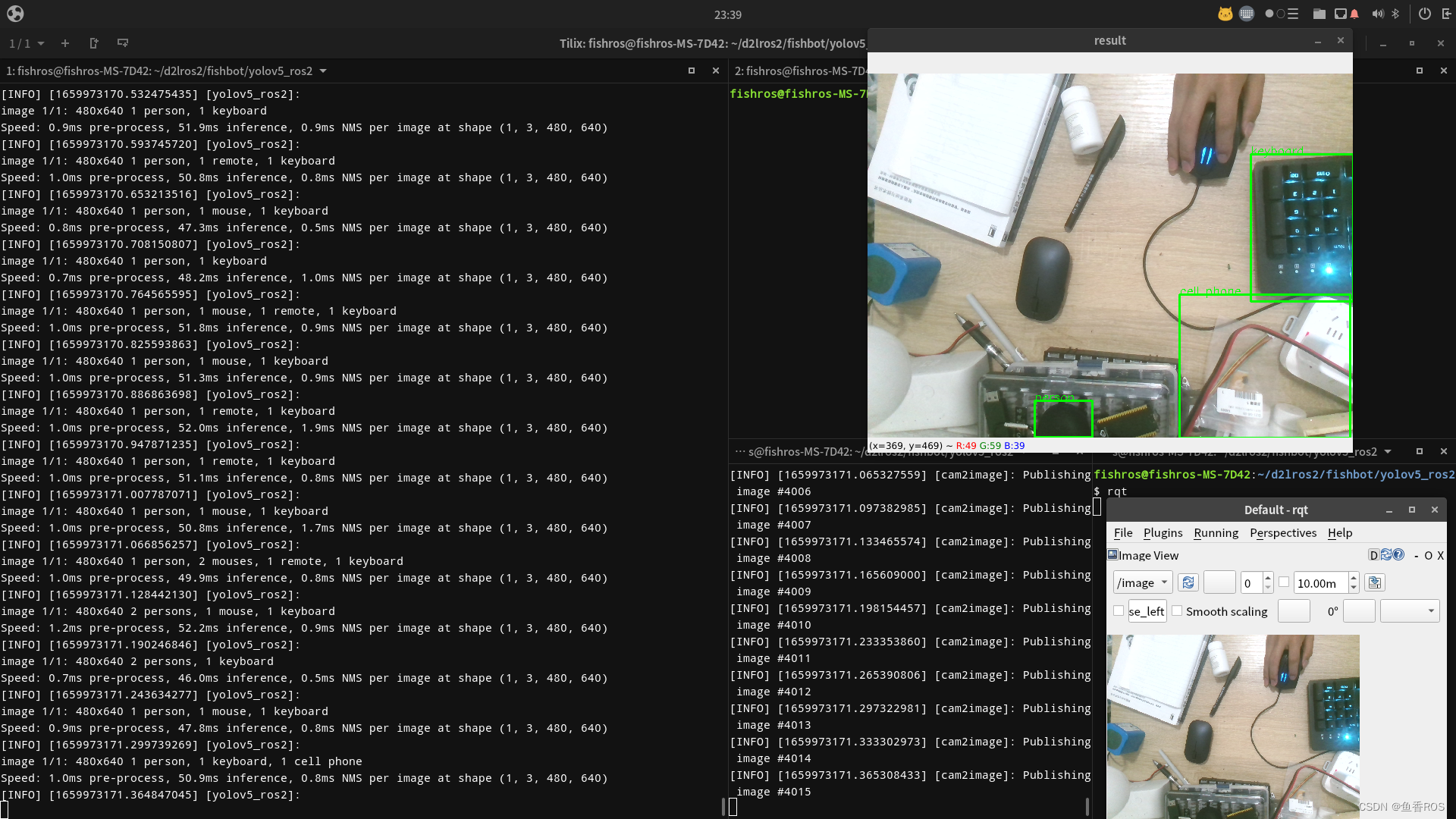
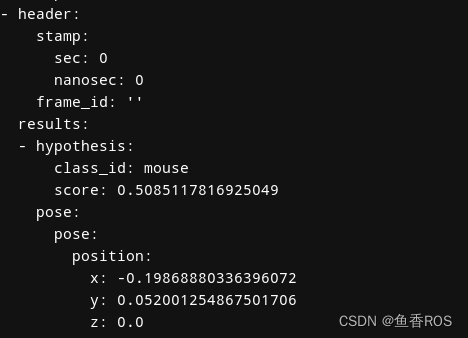
3.订阅结果
识别结果通过/yolo_resutl话题发布出去,包含原始的像素坐标、和归一化后的x和y坐标(相机坐标系下)。
ros2 topic echo /yolo_result

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









