






加州大学伯克利分校等发表的RouteLLM:利用偏好数据学习路由大语言模型
原创 无影寺 AI帝国 2024年07月18日 08:03 广东

一、结论写在前面
论文标题:RouteLLM: Learning to Route LLMs with Preference Data
论文链接:https://arxiv.org/pdf/2406.18665v2
LLM在广泛的任务中展现出令人印象深刻的能力,然而在选择使用哪个模型时,往往需要在性能和成本之间做出权衡。更强大的模型虽然有效,但成本更高,而能力较弱的模型则更具成本效益。
为了解决这一难题,论文提出了几种高效的路由模型,这些模型在推理过程中动态选择更强大或较弱的LLM,旨在优化成本与响应质量之间的平衡。论文开发了一个利用人类偏好数据和数据增强技术的训练框架来提升这些路由器的性能。
论文在广泛认可的基准测试中评估了论文的方法,结果显示,论文的方法在某些情况下显著降低了成本——超过2倍——同时不牺牲响应质量。论文的结果还突出了数据集增强在提高路由器性能方面的有效性。仅在Arena数据集上训练路由器会导致在MMLU和GSM8K上的性能不佳,而通过使用LLM判断或领域内数据增强训练数据,论文的路由器能够在所有基准测试中超越随机基线。当训练数据与评估数据高度相似时,性能提升最大,这一点由基准数据集相似性得分所表明。论文相信,这一框架为特定用例提升路由性能提供了一条清晰且可扩展的路径。
尽管论文的工作展示了强大的成果,但仍存在一些局限性。首先,虽然论文在多样化的基准测试上进行了评估,但现实世界的应用可能与这些基准存在显著差异。其次,虽然本工作聚焦于双模型路由设置,但未来的一个有前景的方向是将此工作扩展到多模型等等。
二、论文的简单介绍
2.1 论文的背景
LLMs的最新进展在广泛的天然语言任务中展示了卓越的能力。从开放式对话和问答到文本摘要和代码生成,LLMs展示了令人印象深刻的流畅性和理解能力。这一快速进步得益于架构创新,如Transformer架构,以及在扩展数据和训练基础设施方面的改进。
然而,并非所有大型语言模型(LLMs)都一视同仁——LLMs在成本和规模上存在显著差异,其规模可以从十亿到数千亿参数不等。LLMs在训练数据方面也各不相同,这进而导致了不同模型在优势、劣势和能力上的差异。总体而言,规模较大的模型往往能力更强,但成本也更高;而规模较小的模型虽然能力较弱,但部署成本更为低廉。
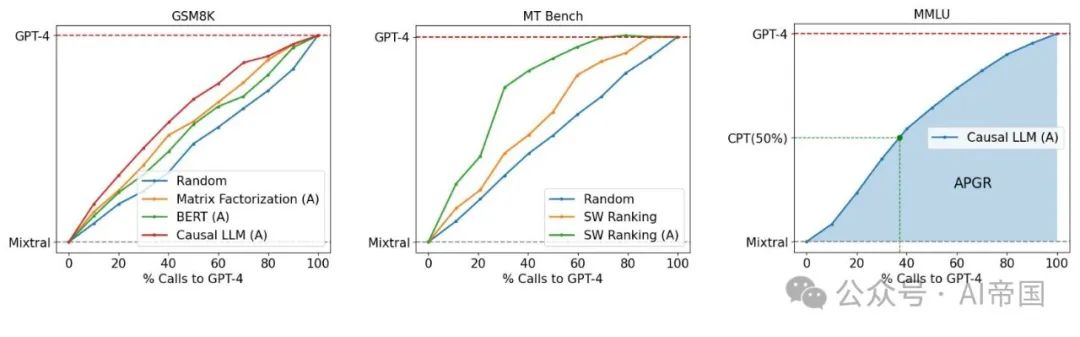
图1:GPT-4与Mixtral-8x7B在路由性能/成本之间的权衡。(左)论文展示了在OOD评估GSM8K上优于随机基线的几种路由器。(中)论文通过数据增强(标记为(A))在MT Bench上展示了路由器性能的提升。(右)论文展示了主要考虑的指标:调用性能阈值(CPT,以绿色表示)和平均性能增益恢复(APGR,以蓝色阴影区域表示)
这一异构环境在实际部署LLM于现实应用中提出了一个难题。虽然将所有用户查询路由到最大、最有能力的模型可以确保高质量的结果,但这成本高昂。相反,将查询路由到较小的模型可以节省成本——高达50倍以上(例如,Llama-3-70b对比GPT-4,或Claude-3 Haiku对比Opus-)——但可能导致响应质量较低,因为较小的模型可能无法有效处理复杂查询。
为此,LLM路由是解决这一问题的有前景的方案,其中每个用户查询首先由一个路由器模型处理,然后决定将查询路由到哪个LLM。这有可能将较简单的查询路由到较小的模型,将较困难的查询路由到较大的模型,优化模型响应质量同时最小化成本。然而,最优LLM路由——定义为在给定成本目标下实现最高质量或在给定质量目标下最小化成本——是一个具有挑战性的问题。一个强大的路由器模型需要推断传入查询的意图、复杂性和领域,并理解候选模型的能力,以将查询路由到最合适的模型。此外,路由器模型需要经济、快速且适应不断演变的模型环境,其中不断引入具有改进能力的新模型。
论文提出了一种基于原则的大型语言模型(LLM)间查询路由框架。如图1所示,论文的设置涉及学习在更强的模型和较弱的模型之间进行路由。论文的目标是通过智能地将简单查询路由到较弱的模型,并将复杂查询保留给较强的模型,以最小化成本同时达到特定的性能目标,例如达到较强模型性能的90%。论文开发了一种利用人类偏好数据和数据增强技术的路由系统训练框架。
2.2 LLM路由
2.2.1 问题定义
考虑一组N个不同的LLM模型 ( M = {M_1, M_2, ..., M_N} )。每个模型 ( M_i ) 可以抽象为一个将查询映射到答案的函数。路由函数 ( R) 是一个 ( N ) 路分类器,它接收一个查询 ( q ) 并选择一个模型来回答 ( q ),答案为 ( a )。路由的挑战在于在提高响应质量和降低成本之间实现最佳平衡。假设论文有权访问偏好数据: ( D_pref = {(q, l_i,j) | q ∈ Q, i, j ∈ N, l_i,j ∈ C} ),其中 ( q ) 是一个查询, ( l_i,j ) 是一个标签,表示在 ( q ) 上比较 ( M_i ) 和 ( M_j ) 的质量结果。区分奖励建模 和路由至关重要。奖励建模在LLM生成响应后评估其质量,而路由要求路由器在看到响应之前选择适当的模型。这需要深入理解问题的复杂性以及可用LLMs的优势和劣势。
论文专注于两种模型类别之间的路由问题:(1) 强模型(M_strong),由能够生成高质量响应但成本较高的模型组成。这一类别主要包含最先进的闭源模型,如GPT-4。(2) 弱模型(M_weak),由质量相对较低且成本较低的模型组成,例如Mixtral-8x7B。这种二元路由问题在实践中相当常见,特别是当LLM应用的开发者努力平衡质量和成本时。此外,解决这一问题构成了解决更一般的N路路由问题的基础。
论文提出了一种基于原则的框架,用于从偏好数据中学习一个二元路由函数R,以在M_weak和M_strong之间进行路由。为此,论文定义了R,它包含两个组成部分:
(1) 胜出预测模型,该模型预测强模型Mstrong的胜出概率。在论文的二元分类设置中,这一概率捕捉了两类模型的胜/负概率。论文可以在偏好数据上使用最大似然估计来学习该模型的参数:
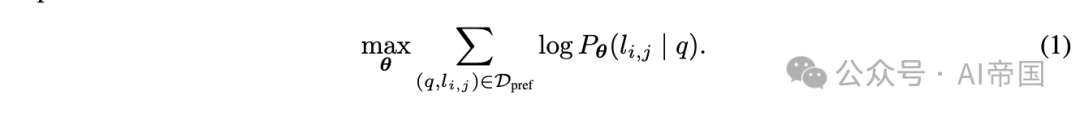
通过在偏好数据上学习胜出概率,论文捕捉了两类模型在各种查询上的优势和劣势。论文提出了几种参数化胜出预测模型的方法。
(2)成本阈值,它将胜出概率转换为在M_strong和M_weak之间的路由决策。给定一个查询q,路由决策表述为:
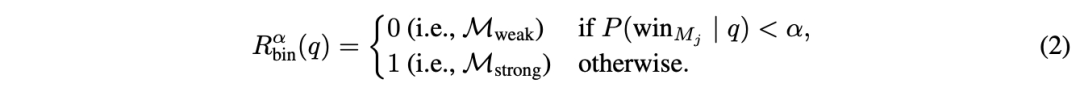
阈值 控制质量与成本的权衡:较高的阈值施加更严格的成本约束,减少开支但可能牺牲质量。
最后,论文将路由器的响应表示为 M_R,它代表根据路由器决策由弱模型或强模型生成的响应。
2.2.2 评估指标
论文定义了捕获LLM路由问题中成本与质量之间权衡的评估指标。论文首先独立评估给定R的质量和成本效率的指标,然后引入两个复合指标,这些指标将用于论文的实验评估。
对于成本效率,论文计算调用强模型的百分比:
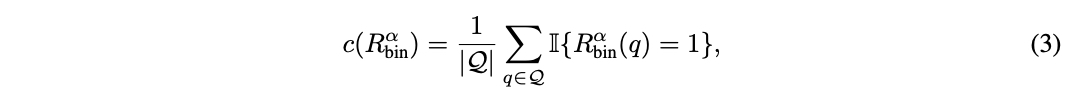
因为强模型的成本显著高于弱模型。
对于质量,论文在评估集 Q 上测量平均响应质量:
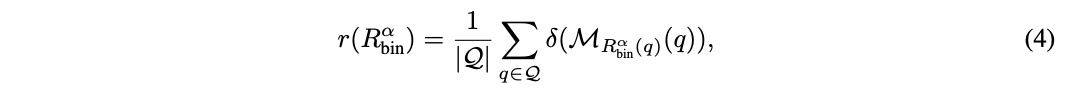
该评分可以是预定义指标在黄金标注数据集(例如 MMLU)中测量响应正确性的结果,或者是数值标签(例如 1-5 或 1-10),其中较高值表示质量更好。
鉴于 R的性能介于弱模型和强模型之间,论文通过量化路由器相对于两者模型性能差距的表现来定义总体性能增益(PGR):
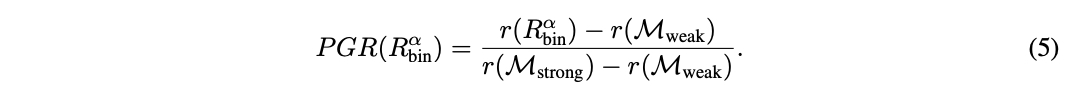
这两个指标单独都不充分,因为它们没有捕捉到路由中的质量-成本权衡。例如,一个将每个查询都发送到强模型的简单路由器可以实现完美的 PGR = 1,而没有任何成本降低。因此,论文通过改变阈值计算路由器 R的调用-性能图。论文定义平均性能差距恢复(APGR)作为在不同成本约束下路由器恢复性能差距的总体度量:
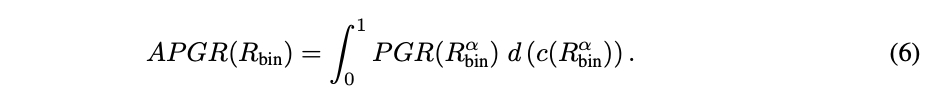
在图 1-(右) 中,APGR 由路由器性能曲线与弱模型性能之间的区域表示。实际上,论文将调用百分比区间 [0%, 100%] 离散化为 { c_i }_i∈[1,10]。对于每个 c_i,论文确定满足成本约束的截止阈值。论文使用以下公式近似 APGR:
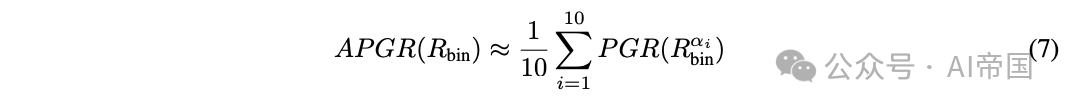
在许多实际应用中,量化达到某个性能水平所需的成本是很重要的。因此,论文定义了第二个指标,称为调用-性能阈值(CPT)。给定所需的路由器性能(以x%的PGR衡量),CPT(x%)指的是获得所需PGR所需的对强模型调用的最小百分比。
在图1-(右)中,虚线绿线表示CPT(50%),即达到50% PGR的期望性能所需的对GPT-4的调用百分比;在这里,CPT(50%) ≈ 37%。
2.3 方法论
2.3.1 偏好数据
论文首先描述如何获取用于训练路由函数的偏好数据。论文主要使用来自在线Chatbot Arena平台[10]的80k对战数据。在该平台上,用户通过聊天机器人界面提交自选提示。提交后,他们会收到两个匿名模型的响应,并投票选出获胜模型或平局。由此产生的数据集,记为D_arena = {(q, M_i, M_j, l_i,j) | q ∈ Q, M_i, M_j ∈ A, l_{i,j} ∈ C},包含用户查询、两个模型的回答M_i、M_j以及基于人类判断的成对比较标签。
使用原始Chatbot Arena数据的一个主要问题是标签稀疏性。例如,任意两个模型之间的比较标签平均占比不到0.1%。因此,论文按如下方式推导用于训练路由器的偏好数据:首先,论文通过将D_arena中的模型聚类成10个不同等级(见附录A)来减少标签稀疏性,使用每个模型在Chatbot Arena排行榜上的Elo评分,并通过动态规划尽量减少每个等级内的变异。论文选择第一和第二等级的模型来代表强模型M_strong,第三等级的模型代表弱模型M_weak。虽然论文主要在跨这些等级对战上进行训练,但也利用涉及其他模型等级的对战来规范论文的学习方法。关键的是,论文省略了D_arena中的实际模型响应,仅保留模型身份。比较标签l_i,j仍然提供了关于LLM M_i和M_j在不同类型和复杂度查询q上的相对能力的洞察。
2.3.1.1数据增强
即使在将模型分类到等级后,不同模型类别间的用户偏好信号仍可能相当稀疏。正如论文在第4.1节中讨论的,这可能阻碍泛化,尤其是对于参数庞大的模型。因此,论文探索了两种数据增强方法:
黄金标注数据集:论文通过形式为D_gold的数据集来增强训练数据。此类数据集的一个例子是MMLU基准。论文通过简单比较M_i的响应来计算l_g,用于增强。
LLM-judge-labeled 数据集:论文探索在开放式目的聊天领域使用 LLM 判断[30]获取偏好标签,因为它已证明与人类判断高度相关。给定一组用户查询,论文首先从 M_strong 中的强模型和 Mweak 中的弱模型生成响应,然后使用 GPT-4 作为判断生成成对比较标签。这种方法的主要挑战是大量收集 GPT-4 响应和成对比较的高成本。幸运的是,Nectar 数据集[31]提供了多种查询及其对应的模型响应。论文通过选择带有 GPT-4 响应(作为 M_strong 的代表)的查询,并在此基础上生成 Mlixtral-8x7B(作为 M_weak 的代表)的响应,显著降低了成本。最后,论文获得了成对比较标签。
2.3.2 路由方法
论文现在详细介绍从偏好数据 D_pref 学习胜预测模型 P的方法。
相似性加权(SW)排名 论文采用类似于[10]的 Bradley-Terry(BT)模型。给定用户查询 q,论文为训练集中的每个查询计算权重,基于其相似性。
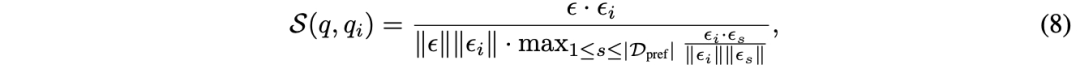
论文通过以下方式学习 BT 系数 (代表 10 个模型类别):
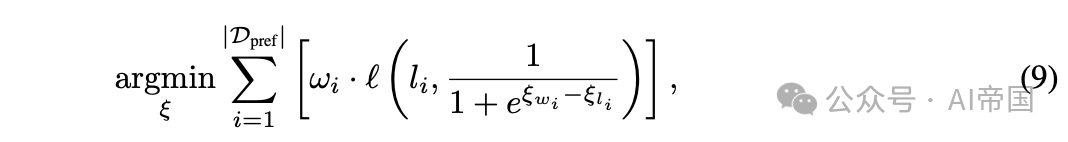
其中 l是二元交叉熵损失。对于此路由模式,不需要训练,求解在推理时进行。
矩阵分解 受推荐系统中矩阵分解模型[18, 25]的启发,这些模型用于捕捉用户-物品交互的低秩结构,论文利用这种方法对偏好数据进行训练。关键在于揭示一个隐藏的评分函数 。评分 ( s(M_w, q) ) 应当表示模型 ( M_w ) 对查询 ( q ) 的回答质量,即如果模型 ( M_w ) 在查询 ( q ) 上优于模型 ( M_l ),则 ( s(M_w, q) > s(M_l, q) )。论文通过使用BT关系建模获胜概率来强化这种关系:
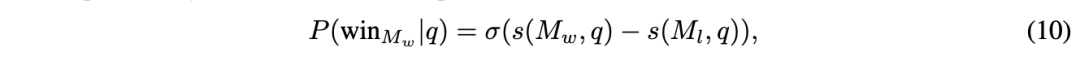
论文在偏好数据上优化这一关系。论文将评分函数 ( s ) 建模为模型和查询的双线性函数,并将模型身份 ( M ) 嵌入到一个 ( d_m ) 维向量 ( v_m ) 中,将查询嵌入到一个 ( d_q ) 维向量 ( v_q ) 中;
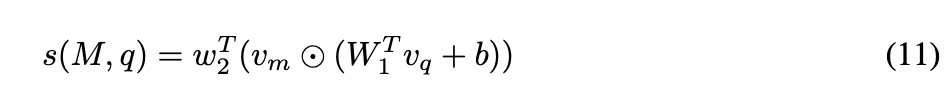
这种方法本质上是在集合上学习评分矩阵的矩阵分解。论文使用8GB GPU对模型进行10个周期的训练,批次大小为64,采用学习率为3 x 10^-4、权重衰减为1 x 10^-5的Adam优化器。
BERT分类器 在此,论文探索使用一种标准文本分类方法,该方法的参数数量较之前的方法更多。论文采用BERT-base架构,为用户的查询提供上下文嵌入,并定义胜率概率为:
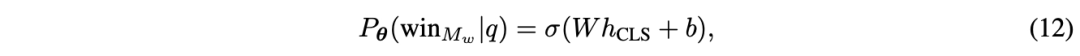
因果LLM分类器 论文最终通过使用Llama 3 8B参数化来扩展论文路由器的能力。论文采用指令遵循范式[28],即论文提供包含用户查询的指令提示作为输入,并以下一词预测方式输出获胜概率,而不是使用单独的分类头。值得注意的是,论文将比较标签作为额外词汇追加,并计算标签类别C上的softmax作为获胜概率。
2.4 实验
训练数据:论文主要使用80K聊天机器人竞技场来训练论文的模型,但保留了5k样本用于验证。论文剔除了所有少于16个字符的提示样本,从而得到了65k对来自64个不同模型的比较。这些对话涵盖了超过100种语言,其中大部分(81%)为英语,其次是中文(3.1%)和俄语(2.2%)。论文将模型分配到10个类别以减少比较标签的稀疏性。如第3.1.1节所讨论,论文进一步通过以下方式增强训练数据:
评估基准:论文在三个广泛使用的学术基准上评估论文的路由器:MMLU 包含57个学科的14,042个问题,MT Bench 使用LLM作为评判的160个开放式问题,以及GSM8K 超过1,000个小学数学问题。此外,论文还进行了评估与训练数据集之间的交叉污染检查,并报告了未受污染的结果。论文展示公共基准上的结果,以理解路由器的域外泛化能力。
路由器:对于矩阵分解路由器和相似性加权排序路由器,论文使用OpenAI的嵌入模型text-embedding-3-small来嵌入输入查询。论文对BERT和因果LLM进行全参数微调,并使用验证集进行模型选择。论文选择使用gpt-4-1106-preview [20]作为Mstrong中的代表模型,以及Mixtral 8x7B 作为Mweak中的代表模型,以具体评估路由器性能。论文还使用了一个在成本约束下随机路由查询的随机路由器作为基线。
2.4.1 结果
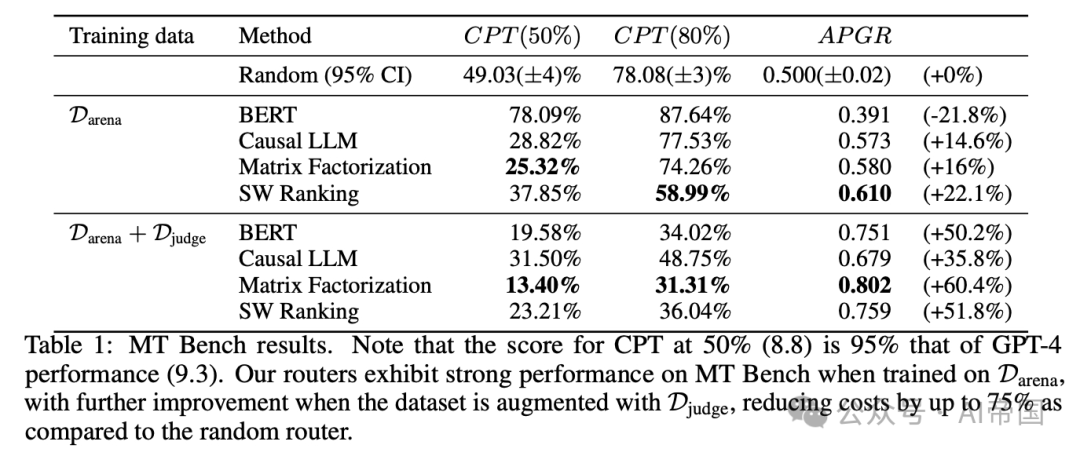
表1:MT Bench结果。注意,CPT在30%时的分数(8.8)是95%的GPT-4性能(9.3)。论文的路由器在Darena训练时在MT Bench上表现出强劲性能,当数据集增加Djudge时,性能进一步提高,与随机路由器相比,成本降低了高达75%
表1展示了论文的路由器在MT Bench上的性能。对于在Arena数据集上训练的路由器,论文观察到矩阵分解和相似性加权排序都有很强的性能,两者在所有指标上都显著优于随机路由器。值得注意的是,矩阵分解所需的GPT-4调用次数是随机路由器的一半,以达到50%的PGR。然而,论文的BERT和因果LLM分类器在Arena数据集上训练时表现接近随机,论文认为这是由于高容量方法在低数据体制下表现较差。
使用GPT-4法官增强偏好数据,导致所有路由器的性能显著提升。BERT和因果LLM路由器现在表现远超随机基线,BERT分类器的APGR比随机提升了超过50%。在这个增强数据集上训练时,矩阵分解是表现最好的路由器,其CPT(80%)几乎减半,所需的GPT-4调用次数比随机少50%。
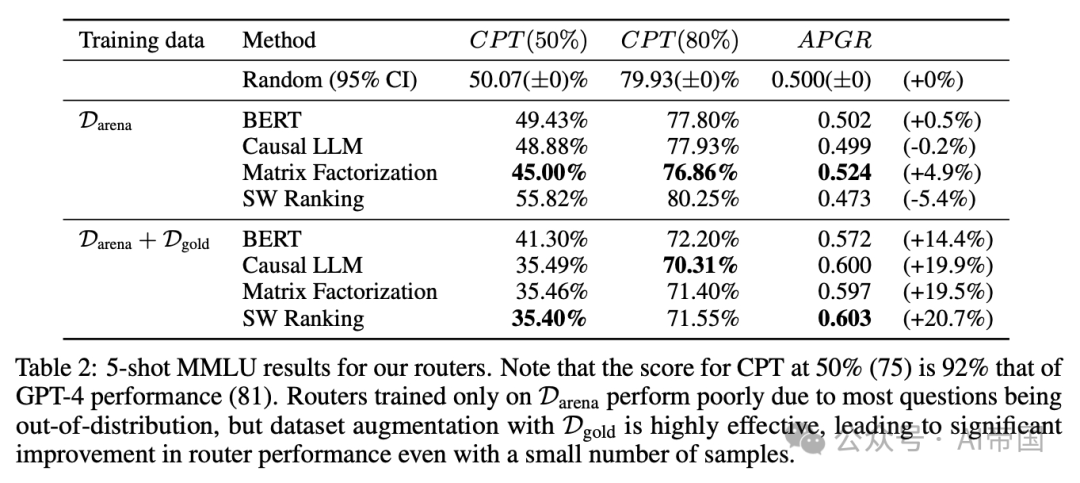
表2:论文的路由器在5-shot MMLU上的结果。请注意,CPT在50%(75)的得分是GPT-4性能(81)的92%。仅在Darena上训练的路由器表现不佳,因为大多数问题都是分布外的,但使用Dgold进行数据集增强非常有效,即使样本数量很少,也能显著提高路由器性能
在MMLU测试集(表2)上,所有路由器在仅使用Arena数据集进行训练时表现不佳,其水平相当于随机路由器,论文认为这主要是由于大多数MMLU问题超出了训练数据的分布范围。然而,通过在训练数据集中加入来自MMLU验证集的金标准数据,所有路由器在MMLU上的性能都得到了显著提升,所有路由器所需的GPT-4调用次数比随机路由器减少了约20%,以达到CPT(50%6)。重要的是,尽管额外加入的约1500个金标准样本仅占总体训练数据的不到2%,这一结果仍展示了数据集增强在小样本量情况下的有效性。
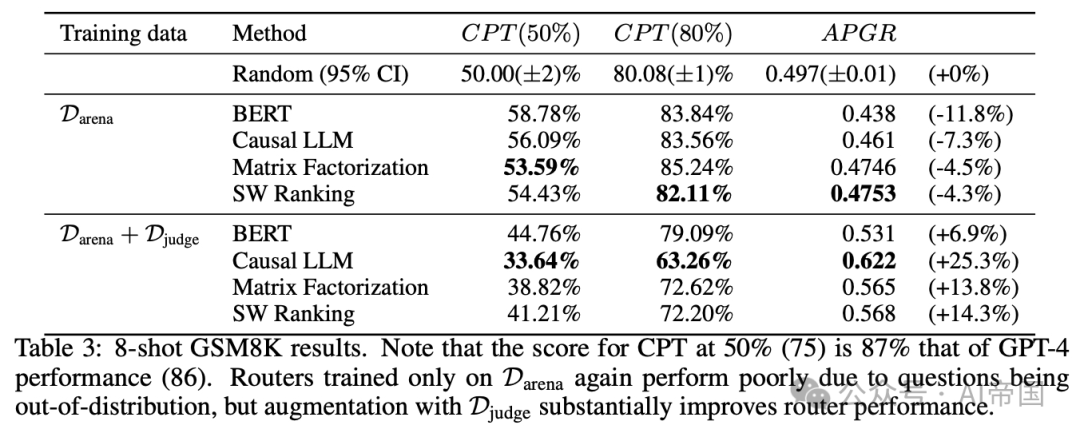
表3:8-shot GSM8K测试结果。注意,CPT在50%时的得分(75)是GPT-4性能(86)的87%。仅在PDarena上训练的路由器再次因问题超出训练数据分布而表现不佳,但通过Diudge数据集的增强,路由器性能得到了显著提升。
最终,在GSM8K上(表3),论文观察到与MMLU类似,仅在Arena数据集上训练的所有路由器的性能接近随机。然而,通过在由LLM法官生成的合成数据增强的数据集上训练论文的路由器,性能显著提升,所有路由器的APGR从低于随机变为高于随机。当在此增强数据集上训练时,因果LLM分类器在所有路由器中表现最佳,相比随机方法,实现CPT(50%)和CPT(80%)所需的GPT-4调用减少了17%。
2.4.2 量化数据集与基准的相似性
论文将同一数据集上训练的路由器在不同基准上性能差异归因于评估数据和训练数据分布的不同。对于每个基准-数据集对,论文在表4中计算了一个基准-数据集相似度分数,该分数指示评估数据在训练数据中的代表性程度。
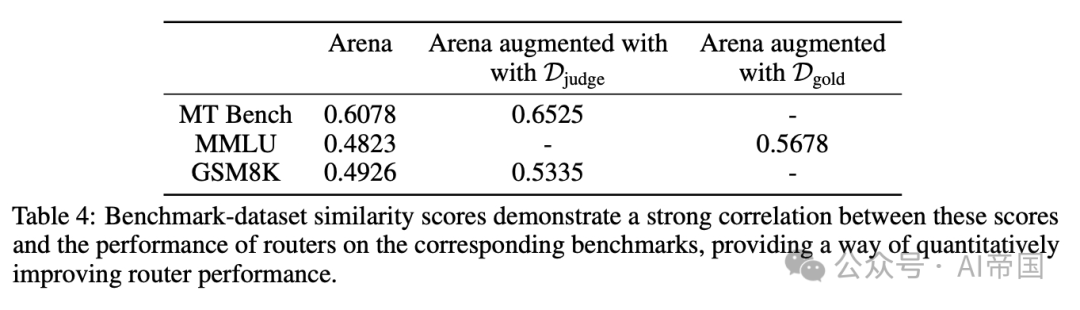
表4:基准-数据集相似度分数显示这些分数与路由器在相应基准上的性能之间存在强相关性,为定量提升路由器性能提供了一种方法
较高的基准数据集相似度分数与使用相应数据集训练的路由器在该基准上的更强性能相关,如第4.1节所示。数据集增强,无论是使用黄金标注数据集还是LLM法官标注数据集,都会使偏好数据的整体分布更符合基准,并提高基准数据集相似度分数,从而转化为性能提升。这种相似度分数对于理解路由器在不同基准上的相对性能也很有用:在Arena数据集上,MT Bench与所有数据集的相似度分数明显高于其他基准,论文认为这解释了与GSM8K和MMLU相比,路由器在MT Bench上的相对更强性能。鉴于对查询分布的了解,基准数据集相似度分数是系统性提升路由器在实际用例中性能的有前景方向。
2.4.3 推广到其他模型对
论文选择gpt-4-1106-preview 和Mixtral 8x7B作为上述实验的代表性强模型和弱模型。然而,为了证明论文的框架对不同模型对的通用性,本节报告了在MT Bench上,当路由器在Claude 3 Opus和Llama 3 8B之间路由时的性能。重要的是,论文使用相同的路由器而无需任何再训练,仅替换路由到的强模型和弱模型。这两个模型也不存在于论文的训练数据中。
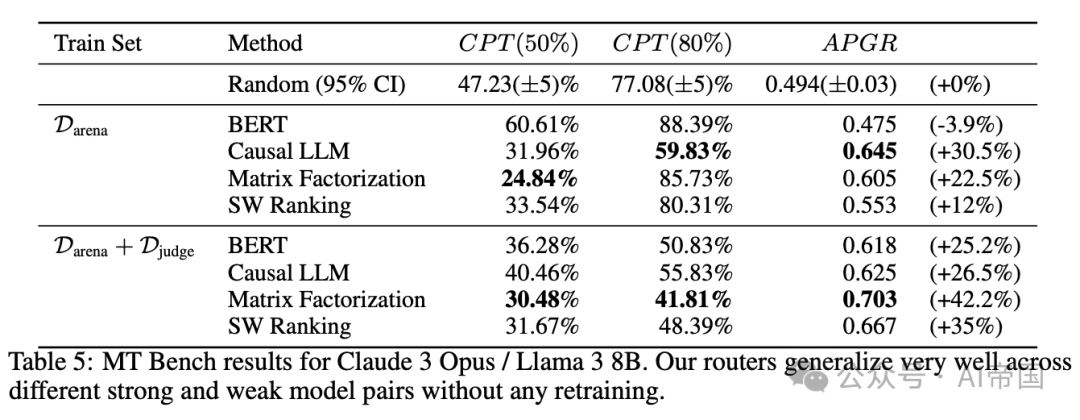
表5:Claude 3 Opus / Llama 3 8B在MT Bench上的结果。论文的路由器在不同强弱模型对之间具有很好的泛化能力,无需任何再训练
再次,论文观察到即使在更换模型对的情况下,所有现有路由器在MT Bench上的性能依然强劲。所有路由器的性能与原始模型对相当。新模型对和原始模型对的结果仍然明显强于随机,论文的路由器在达到CPT(80%)时所需的GPT-4调用次数最多可减少30%。这些结果表明,论文的路由器已经学习了一些能够区分强弱模型的常见问题特征,这些特征可以泛化到新的强弱模型对,而无需额外训练。
2.4.4 成本分析

表6:论文的最佳表现路由器相对于GPT-4的成本节约比率。论文的路由器能够在保持质量的同时实现显著的成本节约
论文估计使用GPT-4和Mixtral 8x7B的平均成本分别为每百万 tokens 24.7和0.24。在表6中,论文展示了量化论文方法所实现的成本节约的结果。论文计算了论文的顶级表现路由器相对于随机基线的GPT-4调用比例的倒数,因为GPT-4的成本是论文分析中的主要因素。论文的路由器实现了高达3.66倍的最优成本节约,表明路由可以在保持响应质量的同时显著降低成本。
2.4.5 路由开销

表7:不同路由器的成本和推理开销。与LLM生成成本相比,部署路由器的成本较小,同时也能支持实际工作负载
与使用单一模型相比,LLM路由的一个担忧是其路由开销。因此,论文在表7中测量并报告了论文的路由器的开销,以展示它们在实际应用中的可行性,使用了从Chatbot Arena随机抽样的对话。对于需要GPU的路由器,即矩阵分解和分类器方法,论文使用了包含单个NVIDIA L4 GPU的Google Cloud的g2-standard-4 VM。对于相似性加权排序,论文使用了Google Cloud的仅CPU的n2-standard-8 VM。论文基于GPU的路由器目前比基于CPU的路由器效率高得多,但论文注意到在优化路由器吞吐量方面仍有很大的改进空间。然而,即使是SW排序,论文最昂贵的路由器,与GPT-4生成相比,引入的额外成本也不超过0.4%。
















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











