






 超级会员免费看
超级会员免费看
 模型的知识获取始于预训练,通过无监督学习建立通用语料理解。接着,二次预训练引入垂直领域知识,然后有监督微调使模型能处理问答对和指令对。进一步,奖励模型利用排序数据集优化,最后通过与人类对齐的强化训练PPO进行精细调整,强调在指令微调中数据质量与丰富度优于数量。
模型的知识获取始于预训练,通过无监督学习建立通用语料理解。接着,二次预训练引入垂直领域知识,然后有监督微调使模型能处理问答对和指令对。进一步,奖励模型利用排序数据集优化,最后通过与人类对齐的强化训练PPO进行精细调整,强调在指令微调中数据质量与丰富度优于数量。
模型的知识来源于预训练阶段,指令微调目的是和人类指令进行对齐。在指令微调阶段,数据的质量与丰富度,远比数量更重要。这是最近一段时间,开源社区以及各个论文强调的一个结论。
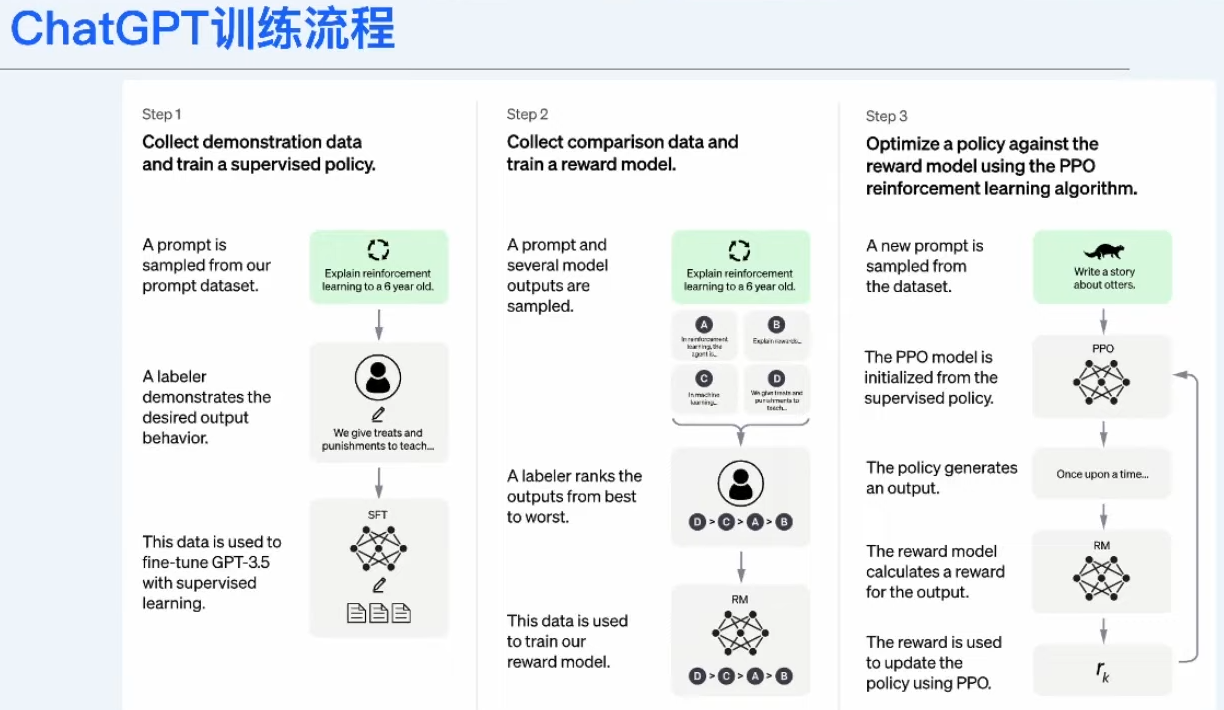
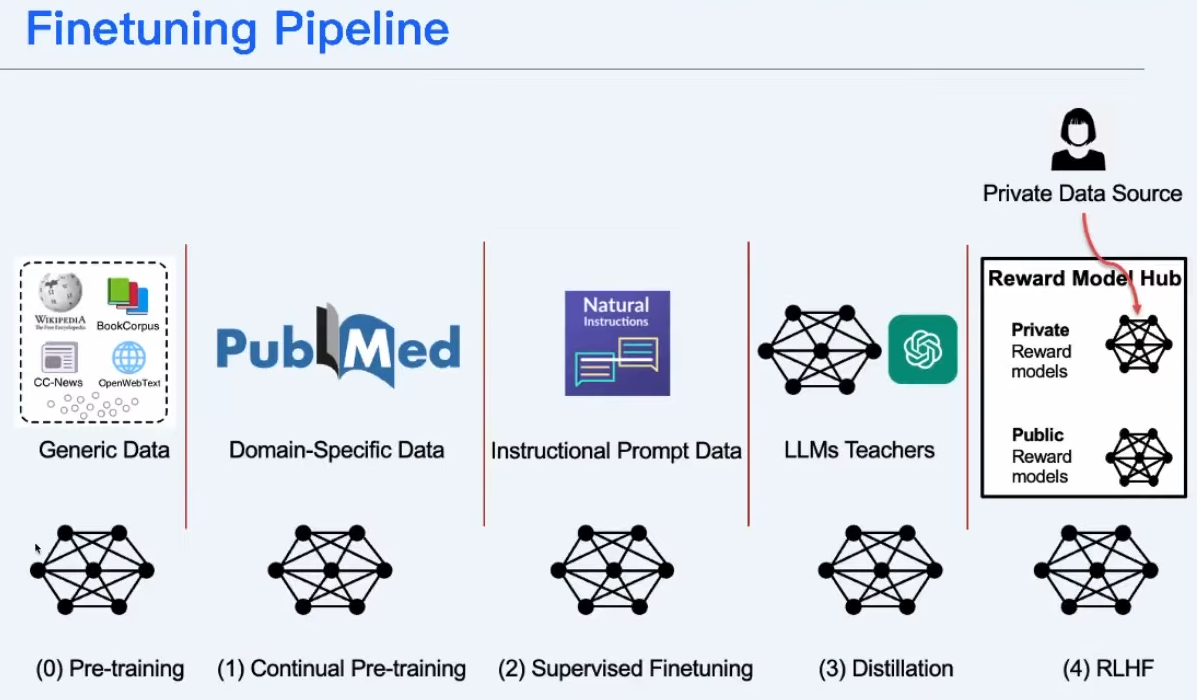


模型的知识来源于预训练阶段,指令微调目的是和人类指令进行对齐。在指令微调阶段,数据的质量与丰富度,远比数量更重要。这是最近一段时间,开源社区以及各个论文强调的一个结论。
 2661
1万+
2305
2661
1万+
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























