







 本文介绍了如何使用NVIDIA TensorRT在GPU上高效部署和优化深度学习推理。TensorRT通过自动优化训练好的神经网络,提高运行时性能,提供高达16倍的能效。文章详细阐述了TensorRT的工作流程,包括构建和部署阶段,以及如何通过TensorRT实现网络优化,提升推理的效率和性能。
本文介绍了如何使用NVIDIA TensorRT在GPU上高效部署和优化深度学习推理。TensorRT通过自动优化训练好的神经网络,提高运行时性能,提供高达16倍的能效。文章详细阐述了TensorRT的工作流程,包括构建和部署阶段,以及如何通过TensorRT实现网络优化,提升推理的效率和性能。
用NVIDIA-TensorRT构造深度神经网络
Deploying Deep Neural Networks with NVIDIA TensorRT
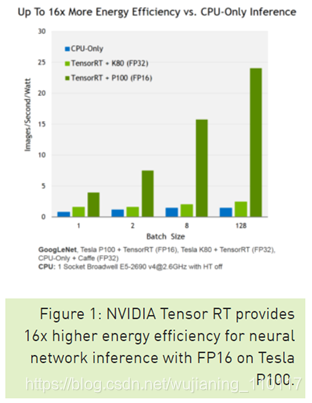
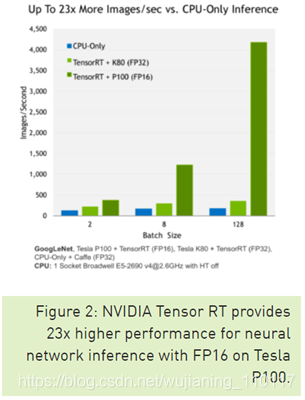
NVIDIA TensorRT是一个用于生产环境的高性能深度学习推理库。电源效率和响应速度是部署的深度学习应用程序的两个关键指标,因为直接影响用户体验和所提供服务的成本。Tensor RT为运行时性能自动优化训练的神经网络,在Tesla P100 GPU上提供高达16倍的能效(性能/瓦),而普通的CPU专用深度学习推理系统(见图1)。图2显示了NVIDIA Tesla P100和K80使用TensorRT和相对复杂的GoogLenet神经网络架构运行推理的性能。
在本文中,将向展示如何在基于GPU的部署平台上使用Tensor RT从经过训练的深层神经网络中获得最佳的效率和性能。
深度学习训练和部署
用深层神经网络求解有监督机器学习问题涉及两步过程。
第一步是利用gpu对海量标记数据进行深层神经网络训练。在这一步中,神经网络学习数以百万计的权值或参数,使其能够将输入数据示例映射到正确的响应。由于目标函数相对于网络权值最小,训练需要在网络中反复向前和向后传递。为了估计真实世界的性能,通常需要训练几个模型,并根据训练期间没有看到的数据验证模型的准确性。
下一步——推理——使用经过训练的模型根据新数据进行预测。在此步骤中,在生产环境(如数据中心、汽车或嵌入式平台)中运行的应用程序中使用经过最佳训练的模型。对于一些应用,如自动驾驶,推理是实时进行的,因此高吞吐量是至关重要的。
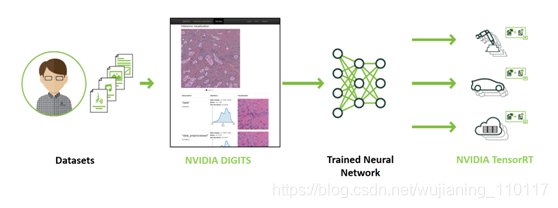
Figure 3: Deep learning training to eployment workflow with NVIDIA DIGITS and Tensor RT.
要了解更多关于训练和推理之间的区别,请参阅Michael Andersch关于GPUs推理的文章。
目标部署环境引入了训练环境中通常不存在的各种挑战。例如,如果目标是使用经过训练的神经网络感知其周围环境的嵌入式设备,则通过该模型的正向推理将直接影响设备的总体响应时间和功耗。优化的关键指标是功率效率:每瓦特的推理性能。
每瓦特性能也是最大化数据中心运营效率的关键指标。在这种情况下,需要最小化在地理上和时间上完全不同的大量请求上使用的延迟和能量,这限制了形成大批量的能力。
NVIDIA TensorRT
Tensor RT是一个高性能的推理引擎,旨在为常见
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









