







 本文介绍了一种在CPU上自动生成优化的低精度卷积算子的方法,用于深度学习模型的低功耗部署。通过位打包和位平面计算,实现了低精度卷积,利用AutoTVM进行参数搜索和优化,实现在Raspberry Pi和x86平台上的性能提升。
本文介绍了一种在CPU上自动生成优化的低精度卷积算子的方法,用于深度学习模型的低功耗部署。通过位打包和位平面计算,实现了低精度卷积,利用AutoTVM进行参数搜索和优化,实现在Raspberry Pi和x86平台上的性能提升。
自动生成低精度深度学习算子
深度学习模型变得越来越大,越来越复杂,由于其有限的计算和能源预算,部署在低功耗电话和IoT设备上变得充满挑战。深度学习的最新趋势是使用高度量化的模型,该模型可对输入和几位权重进行操作,诸如XNOR-Net,DoReFa-Net和HWGQ-Net之类的网络正在稳步发展,提高了准确性。
下面是一个低精度图形片段的示例。低精度卷积将量化的数据和位包放入适当的数据布局中,实现有效的比特卷积。输出具有更高的精度,在对其进行重新量化,另一个低精度算子发送之前,将传统的深度学习层(如批处理归一化和ReLu)应用于该输出。
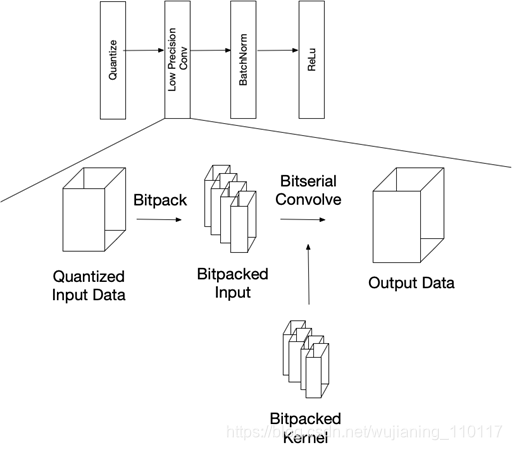
低精度卷积管线。
理论上讲,低精度算子比浮点算子使用更少的运算,可以实现巨大的加速。深度学习框架难以置信的良好优化的低级BLAS和LAPACK库,利用了数十年的工程工作,CPU包含用于加速这些任务的内在指令。开发与8位量化甚至浮点算子的卷积之类的低级算子并不简单。本文介绍了为CPU自动生成优化的低精度卷积的方法。声明低精度算子,根据有效存储的低精度输入进行计算,描述用于描述实现参数搜索空间的调度。依靠AutoTVM来快速搜索空间,找到针对特定卷积,精度和后端的优化参数。
二进制计算背景
低精度模型的核心是biterial点积,使得仅使用按位运算和popcount即可计算卷积和密集算子。点积是两个向量的元素逐次相乘,将所有元素相加来计算的,就像下面的简单示例一样。如果所有数据都是二进制数据,可以将输入向量打包为单个整数,按位与打包的输入,使用popcount对结果中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









