







 OpenCL是一种通用并行计算接口,支持多种设备,而CUDA专为NVIDIA GPU设计,提供更丰富的工具和库。CUDA在开发者友好度和市场占有率上占优,但OpenCL在跨平台性和通用性上更强。随着硬件发展,未来并行计算市场充满不确定性。
OpenCL是一种通用并行计算接口,支持多种设备,而CUDA专为NVIDIA GPU设计,提供更丰富的工具和库。CUDA在开发者友好度和市场占有率上占优,但OpenCL在跨平台性和通用性上更强。随着硬件发展,未来并行计算市场充满不确定性。
OpenCL与Cuda技术
CUDA只针对NVIDIA的GPGPU,OpenCL是并行运算的通用接口。想用CUDA就必须有NVIDIA的显卡或者计算卡。OpenCL对应的设备更广泛,CPU、显卡、FPGA、DSP等等都可能可以用OpenCL开发。
但是在显卡领域OpenCL表现并不好。显卡厂商并没在OpenCL上进行很大的投入,导致在基于显卡的高性能运算领域OpenCL并不好用。
CUDA和OpenCL的芯片结构类似,都是按等级划分的,并逐渐提高等级。然而OpenCL更具通用性并使用更加一般的技术,如OpenCL通过使用Processing Element代替CUDA的Processor,同时CUDA的模型只能在NVIDIA架构的GPU上运行。
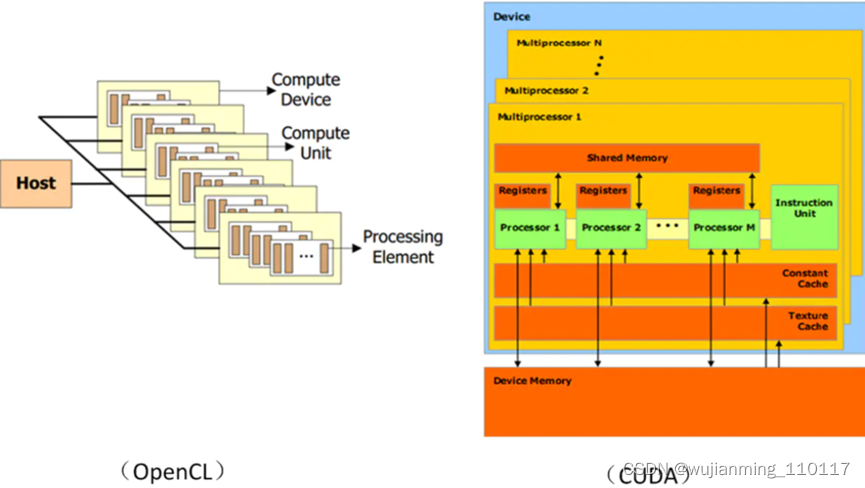
OpenCL与CUDA芯片结构
从很多方面来看,CUDA和OpenCL的关系都和DirectX与OpenGL的关系很相像。如同DirectX和OpenGL一样,CUDA和OpenCL中,前者是配备完整工具包、针对单一供应商(NVIDIA)的成熟的开发平台,后者是一个开放的标准。
虽然两者抱着相同的目标:通用并行计算。但是CUDA仅仅能够在NVIDIA的GPU硬件上运行,而OpenCL的目标是面向任何一种Massively Parallel Processor,期望能够对不同种类的硬件给出一个相同的编程模型。由于这一根本区别,二者在很多方面都存在不同:
1)开发者友好程度。CUDA在这方面显然受更多开发者青睐。原因在于其统一的开发套件(CUDA Toolkit, NVIDIA GPU Computing SDK以及NSight等等)、非常丰富的库(cuFFT, cuBLAS, cu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









