










进阶篇 ->
代码篇 -> ICLR 2024-GraphCare图谱论文 逐行代码解释-CSDN博客ICLR 2024-GraphCare图谱论文 逐行代码解释
GraphCare:通过个性化知识图增强医疗保健预测
*伊利诺伊大学厄巴纳-香槟分校 †通用电气医疗集团 ‡OSF 医疗保健
{pj20, jimeng}@illinois.edu , danicaxiao@gmail.com
adam.r.cross@osfhealthcare.org
抽象的
临床预测模型通常依赖于患者的电子健康记录 (EHR),但整合医学知识来增强预测和决策具有挑战性。 这是因为个性化预测需要个性化知识图 (KG),而很难从患者 EHR 数据生成这些知识图。 为了解决这个问题,我们提出了GraphCare,一个使用外部 KG 来改进基于 EHR 的预测的框架。 我们的方法从大语言模型(LLM)和外部生物医学知识图谱中提取知识来构建特定于患者的知识图谱,然后将其用于训练我们提出的双注意力增强(BAT)图神经网络(GNN)以进行医疗保健预测。 在 MIMIC-III 和 MIMIC-IV 这两个公共数据集上,GraphCare在四项重要的医疗预测任务上超越了基线:死亡率、再入院、住院时间 (LOS) 和药物推荐。 在 MIMIC-III 上,它使死亡率和再入院的 AUROC 提高了 17.6% 和 6.6%,将 LOS 和药物推荐的 F1 分数分别提高了 7.9% 和 10.8%。 值得注意的是,GraphCare在数据有限的场景中表现出了巨大的优势。我们的研究结果强调了在医疗保健预测任务中使用外部知识图谱的潜力,并证明了 GraphCare在生成个性化知识图谱以促进个性化医疗方面的前景。
1介绍
医疗保健系统的数字化导致了大量电子健康记录 (EHR) 数据的积累,这些数据编码了有关患者、治疗等的宝贵信息。基于这些数据开发了机器学习模型,并展示了增强患者护理和治疗的巨大潜力。通过预测任务进行资源分配,包括死亡率预测(Blom et al., 2019;Courtright et al., 2019)、住院时间(LOS)估计(Cai et al., 2015;Levin et al., 2021)、再入院预测(Ashfaq 等人,2019;Xiao 等人,2018)和药物建议(Bhoi 等人,2021;Shang 等人,2019b)。
为了提高预测性能并将专家知识与数据见解相结合,采用临床知识图(KG)来补充 EHR 建模(Chen 等人,2019;Choi 等人,2020;Rotmensch 等人,2017)。 这些知识图谱代表医学概念(例如,诊断、程序、药物)及其关系,从而能够有效学习模式和依赖性。 然而,现有方法主要关注简单的层次关系 (Choi et al., 2017; 2018; 2020),而不是利用生物医学实体之间的全面关系,尽管整合了来自已建立的生物医学知识库的有价值的上下文信息(例如,UMLS (Bodenreider, 2004))可以增强预测。此外, 在网络规模生物医学文献上进行预训练的大型语言模型(LLM),例如 GPT (Brown 等人,2020;Chowdhery 等人,2022;Luo 等人,2022;OpenAI,2023)可以作为替代方案鉴于他们对开放世界数据的卓越推理能力,他们拥有提取临床知识的资源。 大量现有研究证明了它们作为知识库的潜在用途(Lv 等人,2022 年;Petroni 等人,2019 年;AlKhamassi 等人,2022 年)。
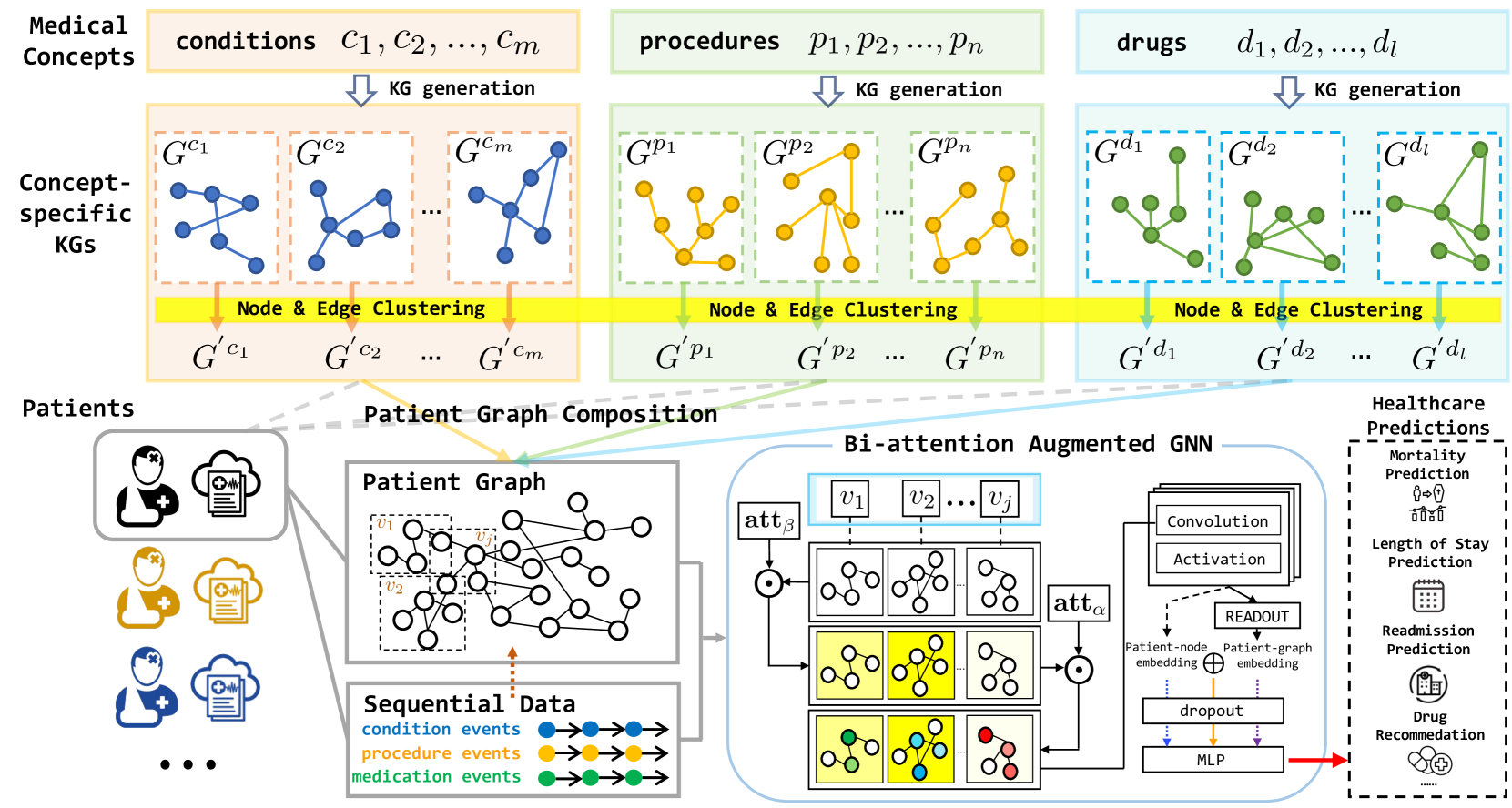
图1:GraphCare概述。 上图:给定由病情、程序和药物组成的患者记录,我们通过法学硕士的知识探索和现有知识图谱的子图采样,为每个医学概念生成一个特定于概念的知识图谱;我们在所有图之间执行节点和边聚类(第3.1节)。 下图:对于每位患者,我们通过组合与患者相关的特定概念 KG 来构建特定于患者的图表,并使图表具有患者就诊期间的顺序数据(第3.2节)。 为了利用患者图进行预测,我们采用了双注意力增强图神经网络(GNN)模型,该模型突出显示了具有注意力权重的基本访问和节点(第3.3节)。 通过三种类型的患者表示(患者节点、患者图和关节嵌入),GraphCare能够处理各种医疗保健预测(第3.4节)。
为了填补个性化医疗知识图谱的空白,我们建议利用法学硕士卓越的推理能力从开放世界数据中提取和集成个性化知识图谱。 我们提出的方法GraphCare(基于个性化图的医疗保健预测)是一个框架,旨在通过有效利用丰富的临床知识来生成特定于患者的 KG。 如图1所示,我们的患者知识图谱生成模块首先将医学概念作为输入,并通过提示 LLM 或从现有图中检索子图来生成特定于概念的知识图谱。 然后,它对节点和边进行聚类,为每个医学概念创建更聚合的知识图谱。 接下来,它通过合并相关的特定概念 KG 并合并来自顺序访问数据的时间信息,为每个患者构建个性化 KG。 然后,这些特定于患者的图被输入到我们的Bi -attention Augmen Ted (BAT) 图神经网络 (GNN)中,以执行各种下游预测任务。
我们使用两个广泛使用的 EHR 数据集 MIMIC-III (Johnson 等人,2016)和 MIMIC-IV (Johnson 等人,2020)评估了GraphCare的有效性。 通过广泛的实验,我们发现GraphCare优于多个基线,而 BAT在四种常见医疗保健方面优于最先进的 GNN 模型(Veličković et al., 2017; Hu et al., 2019; Rampášek et al., 2022)预测任务:死亡率预测、再入院预测、LOS预测、药物推荐。 我们的实验结果表明,配备 BAT 的GraphCare与 MIMIC-III 和 MIMIC 的所有基线相比,平均 AUROC 提高了 17.6%、6.6%、4.1%、2.1% 和 7.9%、3.8%、3.5%、1.8%。分别为四。 此外,我们的方法需要显着减少的患者记录才能获得可比较的结果,为将开放世界知识整合到医疗保健预测中的好处提供了令人信服的证据。
2相关作品
临床预测模型。 EHR 数据越来越被认为是医疗领域的宝贵资源,许多预测任务都利用了这些数据(Ashfaq 等人,2019 年;Bhoi 等人,2021 年;Blom 等人,2019 年;Cai 等人,2015 年) )。 人们设计了多种深度学习模型来满足这种特定类型的数据,利用其丰富的结构化性质来实现增强的性能(Shickel 等人,2017;Miotto 等人,2016;Choi 等人,2016c; a;b;Shang等人,2019b;Yang等人,2021a;Choi等人,2020;Zhang等人,2020;Ma等人,2020b;a;Gao等人,2020;Yang等人等人,2023b)。 在这些模型中,一些模型采用图结构来提高预测准确性,有效捕获医疗实体之间的潜在关系(Choi et al., 2020; Su et al., 2020; Zhu & Razavian, 2021; Li et al., 2020; Xie等人,2019;Lu 等人,2021a;Yang 等人,2023b;Shang 等人,2019b)。 然而,这些现有工作的局限性在于它们没有将本地图链接到外部知识库,而外部知识库包含大量有价值的关系信息(Lau-Min et al., 2021;Pan & Cimino, 2014)。 我们建议通过探索 LLM 或 KG 的相关知识,在开放世界的环境中为每个医学概念创建一个定制的知识图谱,从而增强其对医疗保健的预测能力。
个性化知识图。 个性化 KG 已成为改善医疗预测的有前景的工具(Ping 等人,2017 年;Gyrard 等人,2018 年;Shirai 等人,2021 年;Rastogi 和 Zaki,2020 年;Li 等人,2022 年)。 先前的方法,例如 GRAM (Choi 等人,2017)及其后继者(Ma 等人,2018;Shang 等人,2019a;Yin 等人,2019;Panigutti 等人,2020;Lu 等人, 2021b)合并层次图以改进基于深度学习的模型的预测;然而,他们主要关注简单的亲子关系,忽视了大型知识库中丰富的复杂性。 MedML (Gao et al., 2022)利用图形数据进行 COVID-19 相关预测。 然而,这项工作中的知识图谱范围有限,并且严重依赖于策划的功能。 为了弥补这些差距,我们引入了两种使用开源创建详细、个性化知识图谱的方法。 第一个解决方案是促使(Liu et al., 2023)llm生成适合医学概念的知识图谱。 这种方法受到之前研究的启发(Yao et al., 2019; Wang et al., 2020a; Chen et al., 2022; Lovelace & Rose, 2022; Chen et al., 2023; Jiang et al., 2023),表明预先训练的语言模型可以充当综合知识库。 第二种方法涉及从已建立的知识图谱中进行子图采样(Bodenreider,2004),增强知识库的多样性。
注意力增强 GNN。 注意力机制(Bahdanau et al., 2014)已在 GNN 中得到广泛应用,以从各种任务的图结构中捕获最相关的信息(Veličković et al., 2017;Lee et al., 2018;Zhang et al., 2018) ;Wang 等人,2020b;Zhang 等人,2021a;Knyazev 等人,2019)。 GNN 中注意力机制的结合可以增强图表示学习,这在 EHR 数据分析背景下特别有用(Choi 等人,2020;Lu 等人,2021b)。 在GraphCare中,我们引入了一种新的 GNN BAT,它利用访问级和节点级注意力、边权重和注意力初始化来进行基于 EHR 的个性化 KG 预测。
3基于图的个性化医疗保健预测
在本节中,我们将介绍GraphCare,这是一个综合框架,旨在生成个性化 KG 并将其用于医疗保健预测。 它通过三个一般步骤进行操作:
步骤 1: 使用 LLM 提示并通过对现有 KG 进行二次采样,为每个医学概念生成特定于概念的 KG。 对这些 KG 上的节点和边执行聚类。
步骤2: 对于每个患者,合并相关的特定概念KG以形成个性化KG。
步骤 3: 采用新颖的双注意力增强 (BAT) 图神经网络 (GNN) 基于个性化 KG 进行预测。
3.1步骤 1:特定概念的知识图生成。
将医学概念表示为这是![]() eε{𝐜,𝐩,𝐝}, 在哪里
eε{𝐜,𝐩,𝐝}, 在哪里![]() , 和
, 和![]() 对应于条件、程序和药物的医学概念集,其大小为|𝐜|,|𝐩|, 和|𝐝|, 分别。 这一步的目标是生成一个KG
对应于条件、程序和药物的医学概念集,其大小为|𝐜|,|𝐩|, 和|𝐝|, 分别。 这一步的目标是生成一个KG![]() )对于每个医学概念这是, 在哪里𝒱这是代表节点,并且ℰ这是表示图中的边。
)对于每个医学概念这是, 在哪里𝒱这是代表节点,并且ℰ这是表示图中的边。
我们的方法包括两种策略: (1)通过提示进行基于 LLM 的 KG 提取: 利用带有说明、示例和提示的模板。 例如,使用指令“给定提示,推断出尽可能多的关系并提供更新列表”,例如“提示:系统性红斑狼疮。” 更新:[系统性红斑狼疮正在用类固醇治疗]…… ”并提示“提示:结核病。 更新: ”,LLM 将回复一个 KG 三元组列表,例如“ [结核病,可以用抗生素治疗],[结核病,影响,肺]... ”,其中每个三元组包含一个头实体,一个关系和一个尾部实体。 附录D.1详细介绍了我们精心策划的提示。 运行后�次,我们聚合1 并解析输出以形成每个医学概念的 KG,�法学硕士(�)这是=(𝒱法学硕士(�)这是,ℰ法学硕士(�)这是)。 (2)从现有知识图谱中进行子图采样: 利用预先存在的生物医学知识图谱(Belleau et al., 2008; Bodenreider, 2004; Donnelly et al., 2006),我们通过子图采样提取概念的特定图。 这涉及从主 KG 中选择相关节点和边。 对于该方法,我们首先查明生物医学知识图谱中与该概念对应的实体这是。然后我们采样一个k-hop 子图源自实体,![]() 这是)。我们在附录 D.2中详细介绍了抽样过程。 因此,对于每个医学概念,KG 表示为
这是)。我们在附录 D.2中详细介绍了抽样过程。 因此,对于每个医学概念,KG 表示为![]() 。
。
节点和边缘聚类。 接下来,我们根据节点和边的相似性对节点和边进行聚类,以细化特定于概念的知识图谱。 使用词嵌入之间的余弦相似度来计算相似度。 我们将agglomerative clustering algorithm凝聚聚类算法(Müllner,2011)应用于具有距离阈值的余弦相似度�,将全局图中相似的节点和边分组�=(�这是1,�这是2,……,�这是(|𝐜|+|𝐩|+|𝐝|))所有概念。 经过聚类处理后,我们得到𝒞𝒱:𝒱→𝒱′和𝒞ℰ:ℰ→ℰ′映射节点𝒱和边缘ℰ在原始图表中�到新节点𝒱′和边缘ℰ′, 分别。 通过这两个映射,我们得到一个新的全局图�′=(𝒱′,ℰ′),我们创建一个新图�这是′=(𝒱这是′,ℰ这是′)⊂�′对于每个概念。 节点嵌入𝐇𝒱εℝ|𝒱′|×![]() 在和边缘嵌入
在和边缘嵌入![]() 在由每个簇中的平均词嵌入来初始化,其中在表示词嵌入的维度。
在由每个簇中的平均词嵌入来初始化,其中在表示词嵌入的维度。
3.2第二步:个性化知识图谱构成
对于每个患者,我们通过合并他们的医学概念的聚类知识图谱来组成他们的个性化知识图谱。 我们创建一个患者节点(𝒫)并将其连接到图中的直接 EHR 节点。 患者的个性化 KG 可以表示为�相同=(𝒱相同,ℰ相同), 在哪里𝒱相同=𝒫∪{𝒱这是1′,𝒱这是2′,……,𝒱这是哦′}和ℰ相同=�∪{ℰ这是1′,ℰ这是2′,……,ℰ这是哦′}, 和{这是1,这是2,……,这是哦}是与患者直接相关的医学概念,哦是概念的数量,并且�是连接的边缘𝒫和{这是1,这是2,……,这是哦}。 此外,由于患者被表示为一系列�访问次数(Choi et al., 2016a),患者的访问子图我可以表示为{�我,1,�我,2,……,�我,�}={(𝒱我,1,ℰ我,1),(𝒱我,2,ℰ我,2),……,(𝒱我,�,ℰ我,�)}参观{�1,�2,……,��}在哪里𝒱我,�⊆𝒱相同(我)和ℰ我,�⊆ℰ相同(我)为了1≤�≤�。 我们介绍ℰ国际米兰对于这些访问子图之间的互连性,定义为: ℰ国际米兰={(在我,�,�↔在我,�′,�′)|在我,�,�ε𝒱我,�,在我,�′,�′ε𝒱我,�′,�≠�′,和(在我,�,�↔在我,�′,�′)εℰ′}。 该组包括边缘(在我,�,�↔在我,�′,�′)连接节点的在我,�,�和在我,�′,�′来自不同的访问子图�我,�和�我,�′分别,假设存在一条边(在我,�,�↔在我,�′,�′)在全局图中�′。 患者个性化KG的最终表示,�相同(我),整合特定于访问的数据和更广泛的访问间连接,给出如下: �相同(我)=(𝒫∪⋃�=1�𝒱我,�′,�∪(⋃�=1�ℰ我,�′)∪ℰ国际米兰)。
3.3步骤 3:双注意力增强图神经网络
鉴于每个患者的数据包含多个访问子图,因此必须设计一个能够管理此时间图数据的专用模型。 图神经网络(GNN)以其在该领域的熟练程度而闻名,可以概括为:

| 𝐡�(我+1)=�(𝐖(我)总计的(我)(𝐡�′(我)|�′ε𝒩(�))+𝐛(我)), | (1) |
在哪里![]() 表示节点更新后的节点表示�在(l+1)GNN 的第 层。 功能总计的(我)聚合所有邻居的节点表示𝒩(�)节点的�在我第-层。
表示节点更新后的节点表示�在(l+1)GNN 的第 层。 功能总计的(我)聚合所有邻居的节点表示𝒩(�)节点的�在我第-层。 ![]() 是可学习的权重矩阵和偏置向量我分别为第-层。 �表示激活函数。 尽管如此,传统的 GNN 方法忽略了患者特定图的时间特征,并且错过了个性化医疗保健的复杂性。 为了解决这个问题,我们提出了一种双注意力增强 (BAT) GNN,它可以更好地适应时间图数据并提供更细致的预测医疗保健见解。
是可学习的权重矩阵和偏置向量我分别为第-层。 �表示激活函数。 尽管如此,传统的 GNN 方法忽略了患者特定图的时间特征,并且错过了个性化医疗保健的复杂性。 为了解决这个问题,我们提出了一种双注意力增强 (BAT) GNN,它可以更好地适应时间图数据并提供更细致的预测医疗保健见解。
我们的模型。 在GraphCare中,我们结合了注意力机制来有效地从个性化 KG 中捕获相关信息。 我们首先从词嵌入到隐藏嵌入减少节点和边嵌入的大小,以提高模型的效率。 降维隐藏嵌入计算如下:
| 𝐡我,�,�=𝐖在𝐡(我,�,�)𝒱+𝐛在𝐡(我,�,�)↔(我,�′,�′)=𝐖�𝐡(我,�,�)↔(我,�′,�′)ℛ+𝐛� | (2) |
在哪里𝐖在,𝐖�εℝ在×�,𝐛在,𝐛�εℝ�是可学习的向量,𝐡(我,�,�)𝒱,𝐡(我,�,�)↔(我,�′,�′)ℛεℝ在是输入嵌入,𝐡我,�,�,𝐡(我,�,�)↔(我,�′,�′)εℝ�是隐藏嵌入的�第 - 个节点�患者的第次访问子图,以及节点之间边的隐藏嵌入在我,�,�和在我,�′�′, 分别。 �是隐藏嵌入的大小。
随后,我们计算两组注意力权重:一组对应于与每次访问相关的子图,另一组对应于每个子图中的节点。 节点级注意力权重�第 - 个节点�患者的第次就诊子图我,表示为�我,�,�,以及访问级别的注意力权重�患者第次就诊我,表示为乙我,�,如下所示:
| �我,�,1,……,�我,�,中号=软最大(𝐖�𝐠我,�+𝐛�), | ||||
| 乙我,1,……,乙我,氮=𝝀⊤腥(𝐰乙⊤𝐆我+𝐛乙),在哪里𝝀=[我1,……,我氮], | (3) |
在哪里𝐠我,�εℝ中号是访问子图的多热向量表示�我,�,表示出现的节点�患者第次就诊我在哪里中号=|𝒱′|是全局图中的节点数�′。 𝐆我εℝ氮×中号表示患者的多热矩阵我的图�我在哪里氮是所有患者的最大就诊次数。 𝐖�εℝ中号×中号,𝐰乙εℝ中号,𝐛�εℝ中号和𝐛乙εℝ氮是可学习的参数。 𝝀εℝ氮是衰减系数向量,�是患者就诊的次数我,我�ε𝝀在哪里我�=经验值(-�(�-�))什么时候�≤�和0否则,是访问系数�,具有衰减率�,为最近的访问初始化更高的权重。
注意初始化。 为了进一步整合法学硕士的先验知识并帮助模型收敛,我们初始化𝐖�基于节点嵌入和词嵌入之间的余弦相似度的节点级注意力𝐰tf预测任务特征对的特定术语(例如,死亡状况的“最终状况”。我们在附录 C中提供了更多详细信息)。 形式上,我们首先计算全局图中节点的权重�′经过在米=(𝐡米⋅𝐰tf)/(‖𝐡米‖2⋅‖𝐰tf‖2)在哪里𝐡米ε𝐇𝒱是输入嵌入米第 - 个节点�′, 和在米是计算出的权重。 我们将权重标准化 0≤在米≤1,∀1≤米≤中号。 我们初始化𝐖�=诊断(在1,……,在中号)作为对角矩阵。
接下来,我们通过聚合所有访问子图中的相邻节点来更新节点嵌入,其中包含在等式(3.3)中计算的访问和节点的注意力权重以及边的权重。 基于式(1),我们设计卷积层BAT如下:
| 𝐡我,�,�(我+1)=�(𝐖(我)Σ�′ε�,�′ε𝒩(�)∪{�}(�我,�′,�′(我)乙我,�′(我)𝐡我,�′,�′(我)⏟节点聚合术语+在ℛ〈�,�′〉(我)𝐡(我,�,�)↔(我,�′,�′)⏟边聚合术语)+𝐛(我)), | (4) |
在哪里�是ReLU函数,𝐖(我)εℝ�×�,𝐛(我)εℝ�是可学习的参数,𝐰ℛ(我)εℝ|ℰ′|是该层的边缘权重向量我, 和在ℛ〈�,�′〉(我)ε𝐰ℛ(我)是边缘嵌入的标量权重𝐡(我,�,�)↔(我,�′,�′)ℛ。 在等式(4)中,节点聚合项捕获了注意力加权节点的贡献,而边聚合项表示连接节点的边的影响。 该卷积层集成了节点和边缘特征,使模型能够学习患者 EHR 数据的丰富表示。 经过几层卷积后,我们得到了节点嵌入𝐡我,�,�(�)最后一层(�),用于预测:
| 𝐡我�相同=意思是(Σ�=1�Σ�=1��𝐡我,�,�(�)),𝐡我𝒫=意思是(Σ�=1�Σ�=1��𝟙我,�,�D𝐡我,�,�(�)), | ||||
| 𝐳我图形=多层线性规划(𝐡我�相同),𝐳我节点=多层线性规划(𝐡我𝒫),𝐳我联合的=多层线性规划(𝐡我�相同⊕𝐡我𝒫), | (5) |
在哪里�是患者就诊的次数我,��是访问的节点数�,𝐡我�相同表示通过对访问子图中所有节点的嵌入以及患者每个子图中的各个节点的嵌入进行平均而获得的患者图嵌入我。𝐡我𝒫表示通过平均链接到患者节点的直接医学概念的节点嵌入来计算的患者节点嵌入。 𝟙我,�,�Dε{0,1}是一个二进制标签,指示节点是否在我,�,�对应于患者直接的医疗概念我。 最后,我们将多层感知(MLP)应用于𝐡我�相同,𝐡我𝒫,或串联嵌入(𝐡我�相同⊕𝐡我𝒫)获得logits𝐳我图形,𝐳我节点或者𝐳我联合的分别。我们在附录 E中讨论患者表征学习的更多细节。
3.4训练和预测
该模型可以适用于各种医疗保健预测任务。 考虑一组样本{(�1),(�1,�2),……,(�1,�2,……,��)}对于每个患者�访问,其中每个元组表示由一系列连续访问组成的样本。
死亡率 (MT.) 预测预测每个样本后续访问的死亡率标签,并丢弃最后一个样本。 正式地,�:(�1,�2,……,��-1)→和[��]在哪里和[��]ε{0,1}是一个二进制标签,表示访视时记录的患者生存状态��。
再入院 (RA.) 预测可预测患者是否会在以下时间内重新入院�天。 正式地,�:(�1,�2,……,��-1)→和[�(��)-�(��-1)],和ε{0,1}在哪里�(��)表示访问的相遇时间��。 和[�(��)-�(��-1)]等于 1 如果�(��)-�(��-1)≤�,否则为 0。 在我们的研究中,我们设定�=15天。
住院时间 (LOS) 预测 (Harutyunyan 等人,2019)可预测每次就诊的 ICU 住院时间。 正式地,�:(�1,�2,……,��)→和[��]在哪里和[��]εℝ1×�是一个独热向量,指示其类别�类。 我们设置了10个班级[𝟎,𝟏,……,𝟕,𝟖,𝟗],表示长度<1天(𝟎),一星期内(𝟏,……,𝟕),一到两周(𝟖), 和≤两周(𝟗)。
药物推荐可预测每次就诊的药物标签。 正式地,�:(�1,�2,……,��)→和[��]在哪里和[��]εℝ1×|𝐝|是一个多热向量,其中|𝐝|表示所有药物种类的数量。
我们使用带有 sigmoid 函数的二元交叉熵(BCE)损失来训练二元(MT. 和 RA.) 和多标签分类(Drug.) 分类任务,而我们使用带有 softmax 函数的交叉熵(CE)损失来训练多类(LOS)分类任务。
4实验
4.1实验设置
数据。 对于 EHR 数据,我们使用公开的 MIMIC-III (Johnson et al., 2016)和 MIMIC-IV (Johnson et al., 2020)数据集。 表1列出了处理后的数据集的统计数据。 为了构建特定于概念的知识图谱(第3.1节),我们利用 GPT-4 (OpenAI,2023)作为知识图谱生成的 LLM,并利用 UMLS-KG (Bodenreider,2004)作为现有的生物医学知识图谱进行子图采样,其具有 300K实体和 1M 关系。 �=3和�=1被设置为参数。 我们采用 GPT-3 嵌入模型来检索实体和关系的词嵌入。
表格1:预处理 EHR 数据集的统计数据。 ”#”:“数量”,“/病人”:“每个病人”。
| #患者 | #访问 | #就诊次数/患者 | #病情/患者 | #程序/患者 | #药物/患者 | |
|---|---|---|---|---|---|---|
| 模拟-III | 35,707 | 44,399 | 1.24 | 12.89 | 4.54 | 33.71 |
| 模拟-IV | 123,488 | 232,263 | 1.88 | 21.74 | 4.70 | 43.89 |
表2:MIMIC-III/MIMIC-IV 上四个预测任务的性能比较。 我们报告平均表现(%)以及 MIMIC-III 运行超过 100 次和 MIMIC-IV 运行超过 25 次的每个模型的标准差(括号内)。 两个数据集的最佳结果均突出显示。
| 任务 1:死亡率预测 | 任务 2:再入院预测 | ||||||||
| 模型 | 模拟-III | 模拟-IV | 模拟-III | 模拟-IV | |||||
| 澳大利亚UPRC | 奥罗克 | 澳大利亚UPRC | 奥罗克 | 澳大利亚UPRC | 奥罗克 | 澳大利亚UPRC | 奥罗克 | ||
| 格鲁乌 | 11.8(0.5) | 61.3(0.9) | 4.2(0.1) | 69.0(0.8) | 68.2(0.4) | 65.4(0.8) | 66.1(0.1) | 66.2(0.1) | |
| 变压器 | 10.1(0.9) | 57.2(1.3) | 3.4(0.4) | 65.1(1.2) | 67.3(0.7) | 63.9(1.1) | 65.7(0.3) | 65.3(0.4) | |
| 保持 | 9.6(0.6) | 59.4(1.5) | 3.8(0.4) | 64.8(1.6) | 65.1(1.0) | 64.1(0.7) | 66.2(0.3) | 66.3(0.2) | |
| 公克 | 11.4(0.7) | 60.4(0.9) | 4.4(0.3) | 66.7(0.7) | 67.2(0.8) | 64.3(0.4) | 66.1(0.2) | 66.3(0.3) | |
| 迪普 | 13.2(1.1) | 60.8(0.4) | 4.2(0.2) | 68.9(0.9) | 68.8(0.9) | 66.5(0.4) | 65.6(0.1) | 65.4(0.2) | |
| 爱达康 | 11.1(0.4) | 58.4(1.4) | 4.6(0.3) | 69.3(0.7) | 68.6(0.6) | 65.7(0.3) | 65.9(0.0) | 66.1(0.0) | |
| 抓牢 | 9.9(1.1) | 59.2(1.4) | 4.7(0.1) | 68.4(1.0) | 69.2(0.4) | 66.3(0.6) | 66.3(0.3) | 66.1(0.2) | |
| 舞台网 | 12.4(0.3) | 61.5(0.7) | 4.2(0.3) | 69.6(0.8) | 69.3(0.6) | 66.7(0.4) | 66.1(0.1) | 66.2(0.1) | |
| 图形护理 | 带盖特 | 14.3(0.8) | 67.8(1.1) | 5.1(0.1) | 71.8(1.0) | 71.5(0.7) | 68.1(0.6) | 67.4(0.4) | 67.3(0.4) |
| 带吉恩 | 14.4(0.4) | 67.3(1.3) | 5.7(0.1) | 72.0(1.1) | 71.3(0.8) | 68.0(0.4) | 68.3(0.3) | 67.5(0.4) | |
| 带EGT | 15.5(0.5) | 69.1(1.0) | 6.2(0.2) | 71.3(0.7) | 72.2(0.5) | 68.8(0.4) | 68.9(0.2) | 67.6(0.3) | |
| 带 GPS | 15.3(0.9) | 68.8(0.8) | 6.7(0.2) | 72.7(0.9) | 71.9(0.6) | 68.5(0.6) | 69.1(0.4) | 67.9(0.4) | |
| 带最佳可行技术 | 16.7(0.5) | 70.3(0.5) | 6.7(0.3) | 73.1(0.5) | 73.4(0.4) | 69.7(0.5) | 69.6(0.3) | 68.5(0.4) | |
| 任务 3:停留时间预测 | |||||||||
| 模型 | 模拟-III | 模拟-IV | |||||||
| 奥罗克 | 河童 | 准确性 | F1分数 | 奥罗克 | 河童 | 准确性 | F1分数 | ||
| 格鲁乌 | 78.3(0.1) | 26.2(0.2) | 40.3(0.3) | 34.9(0.5) | 78.7(0.1) | 26.0(0.1) | 35.2(0.1) | 31.6(0.2) | |
| 变压器 | 78.3(0.2) | 25.4(0.4) | 40.1(0.3) | 34.8(0.2) | 78.3(0.3) | 25.3(0.4) | 34.4(0.2) | 31.4(0.3) | |
| 保持 | 78.2(0.1) | 26.1(0.4) | 40.6(0.3) | 34.9(0.4) | 78.9(0.3) | 26.3(0.2) | 35.7(0.2) | 32.0(0.2) | |
| 公克 | 78.2(0.1) | 26.3(0.3) | 40.4(0.4) | 34.5(0.2) | 78.8(0.2) | 26.1(0.4) | 35.4(0.2) | 31.9(0.3) | |
| 迪普 | 77.9(0.1) | 25.3(0.4) | 40.1(0.6) | 35.0(0.4) | 79.5(0.3) | 26.4(0.2) | 35.8(0.3) | 32.3(0.1) | |
| 舞台网 | 78.3(0.2) | 24.8(0.2) | 39.9(0.2) | 34.4(0.4) | 79.2(0.3) | 26.0(0.2) | 35.0(0.2) | 31.3(0.3) | |
| 图形护理 | 带盖特 | 79.4(0.3) | 28.2(0.2) | 41.9(0.2) | 36.1(0.4) | 80.3(0.3) | 28.4(0.4) | 36.2(0.1) | 33.3(0.3) |
| 带吉恩 | 79.2(0.2) | 28.3(0.3) | 41.5(0.3) | 36.0(0.4) | 79.9(0.2) | 27.5(0.3) | 36.3(0.3) | 32.8(0.2) | |
| 带EGT | 80.3(0.3) | 28.8(0.2) | 42.8(0.4) | 36.3(0.5) | 80.5(0.2) | 28.7(0.3) | 36.7(0.2) | 33.5(0.1) | |
| 带 GPS | 80.9(0.3) | 28.8(0.4) | 43.0(0.3) | 36.8(0.4) | 80.7(0.3) | 28.8(0.4) | 36.7(0.3) | 33.9(0.3) | |
| 带最佳可行技术 | 81.4(0.3) | 29.5(0.4) | 43.2(0.4) | 37.5(0.2) | 81.7(0.2) | 29.8(0.3) | 37.3(0.3) | 34.2(0.3) | |
| 任务4:药物推荐 | |||||||||
| 模型 | 模拟-III | 模拟-IV | |||||||
| 澳大利亚UPRC | 奥罗克 | F1分数 | 杰卡德 | 澳大利亚UPRC | 奥罗克 | F1分数 | 杰卡德 | ||
| 格鲁乌 | 77.0(0.1) | 94.4(0.0) | 62.3(0.3) | 47.8(0.3) | 74.1(0.1) | 94.2(0.1) | 60.2(0.2) | 44.0(0.4) | |
| 变压器 | 76.1(0.1) | 94.2(0.0) | 62.1(0.4) | 47.1(0.4) | 71.3(0.1) | 93.4(0.1) | 55.9(0.2) | 40.4(0.1) | |
| 保持 | 77.1(0.1) | 94.4(0.0) | 63.7(0.2) | 48.8(0.2) | 74.2(0.1) | 94.3(0.0) | 60.3(0.1) | 45.0(0.1) | |
| 公克 | 76.7(0.1) | 94.2(0.1) | 62.9(0.3) | 47.9(0.3) | 74.3(0.2) | 94.2(0.1) | 60.1(0.2) | 45.3(0.3) | |
| 迪普 | 74.3(0.1) | 93.7(0.0) | 60.3(0.4) | 44.7(0.3) | 73.7(0.1) | 94.2(0.1) | 59.1(0.4) | 43.8(0.4) | |
| 舞台网 | 74.4(0.1) | 93.0(0.1) | 61.4(0.3) | 45.8(0.4) | 74.4(0.1) | 94.2(0.0) | 60.2(0.3) | 45.4(0.4) | |
| 安全药物 | 68.1(0.3) | 91.0(0.1) | 46.7(0.4) | 31.7(0.3) | 66.4(0.5) | 91.8(0.2) | 56.2(0.4) | 44.3(0.3) | |
| 微米 | 77.4(0.0) | 94.6(0.1) | 63.2(0.4) | 48.3(0.4) | 74.4(0.1) | 94.3(0.1) | 59.3(0.3) | 44.1(0.3) | |
| 游戏网 | 76.4(0.0) | 94.2(0.1) | 62.1(0.4) | 47.2(0.4) | 74.2(0.1) | 94.2(0.1) | 60.4(0.4) | 45.3(0.3) | |
| 鼹鼠记录 | 69.8(0.1) | 92.0(0.1) | 58.1(0.1) | 43.1(0.3) | 68.6(0.1) | 92.1(0.1) | 56.3(0.4) | 40.6(0.3) | |
| 图形护理 | 带盖特 | 78.5(0.2) | 94.8(0.1) | 64.4(0.3) | 49.2(0.4) | 74.7(0.5) | 94.4(0.3) | 60.4(0.3) | 45.7(0.4) |
| 带吉恩 | 78.2(0.1) | 94.7(0.1) | 63.6(0.4) | 47.9(0.3) | 74.8(0.3) | 94.6(0.1) | 60.6(0.4) | 46.1(0.4) | |
| 带EGT | 79.6(0.2) | 95.3(0.0) | 66.4(0.2) | 49.6(0.4) | 75.4(0.4) | 95.0(0.1) | 61.6(0.3) | 47.3(0.3) | |
| 带 GPS | 79.9(0.3) | 95.5(0.1) | 66.2(0.3) | 49.8(0.4) | 75.9(0.5) | 94.9(0.1) | 62.1(0.3) | 46.8(0.4) | |
| 带最佳可行技术 | 80.2(0.2) | 95.5(0.1) | 66.8(0.2) | 49.7(0.3) | 77.1(0.1) | 95.4(0.2) | 63.9(0.3) | 48.1(0.3) | |
基线。 我们的基线包括 GRU (Chung et al., 2014)、Transformer (Vaswani et al., 2017)、RETAIN (Choi et al., 2016c)、GRAM (Choi et al., 2017) 、Deepr (Nguyen et al., 2017)、Deepr (Nguyen et al., 2017) 2016)、StageNet (Gao 等人,2020)、AdaCare (Ma 等人,2020a)、GRASP (Zhang 等人,2021b)、SafeDrug (Yang 等人,2021b)、MICRON (Yang 等人,2021b) 2021a)、GAMENet (Shang 等人,2019b)和 MoleRec (Yang 等人,2023b)。 鉴于其计算需求,AdaCare 和 GRASP 仅在二进制预测任务上进行评估。 对于药物推荐,我们还考虑特定任务模型 SafeDrug、MICRON、GAMENet 和 MoleRec。 我们的GraphCare模型的性能在五种 GNN 和图转换器下进行了检查:GAT (Veličković 等人,2017)、GINE (Hu 等人,2019)、EGT (Hussain 等人,2022)、GPS (Rampášek 等人, 2022)和我们的 BAT。 我们不会与 GCT (Choi 等人,2020)和 CGL (Lu 等人,2021a)等模型进行比较,因为它们包含了实验室结果和临床记录,而本研究中未使用这些结果。 实施细节在附录C中讨论。
评估指标。 我们考虑以下指标:(a)准确性——正确预测的实例占总实例的比例; (b) F1——精确率和召回率的调和平均值; (c) Jaccard分数——预测标签和真实标签的交集与并集的比率; (d) AUPRC——精确率-召回率曲线下的面积,强调精确率和召回率之间的权衡; (e) AUROC - 接收者操作特征曲线下的面积,捕获真阳性率和假阳性率之间的权衡。 (f) Cohen 的 Kappa - 衡量分类项目的评估者间一致性,调整多类别分类中偶然的预期一致性水平。
4.2实验结果
如表2所示,GraphCare在 MIMIC-III 和 MIMIC-IV 数据集的所有预测任务中始终优于现有基线。 例如,当与 BAT 结合使用时,GraphCare在 MIMIC-III 死亡率预测的 AUROC 中超出了 StageNet 的最佳结果 +14.3%。 在我们的GraphCare框架中,我们提出的 BAT GNN 始终表现最好,强调了双向注意力机制的有效性。 下面,我们详细分析结合个性化 KG 和我们提出的 BAT 的效果。
4.2.1个性化知识图谱的作用
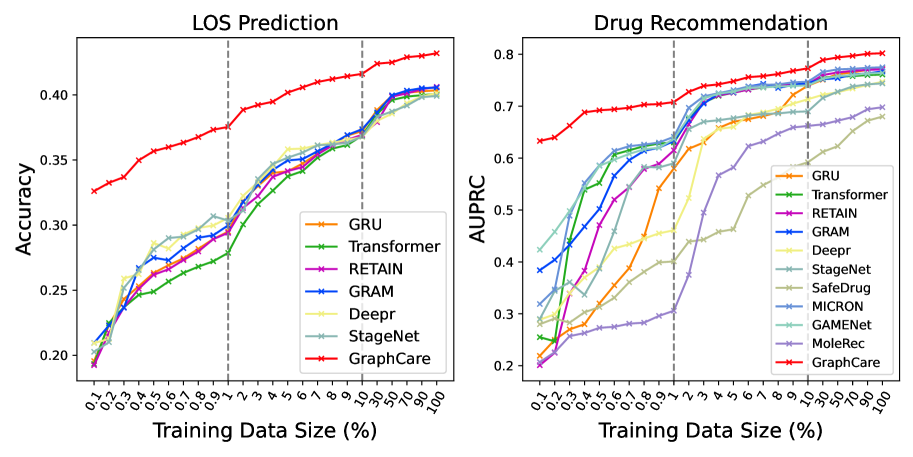
图2:EHR 训练数据大小的性能。 x 轴上的值表示%整个训练数据。 虚线分隔三个范围:[0.1, 1]、[1, 10] 和 [10, 100] (%)。
EHR 数据大小的影响。 为了检查训练数据量对模型性能的影响,我们进行了一项综合实验,其中训练数据的大小在原始训练集的 0.1% 到 100% 之间波动,而验证/测试数据保持不变。 性能指标是 10 次运行的平均值,每次运行都使用不同的随机种子。图 2所示的结果表明,当面对稀缺的训练数据时,GraphCare 比其他模型表现出相当大的优势。例如,GraphCare尽管仅使用 0.1% 的训练数据(36 个患者样本)进行训练,但其 LOS 预测精度与使用 2.0% 的训练数据(约 720 个患者样本)进行训练的最佳基线 StageNet 相当。 类似的模式也出现在药物推荐任务中。 值得注意的是,GAMENet 和 GRAM 还表现出了一定程度的针对数据限制的弹性,这可能是由于它们使用了内部 EHR 图表或外部本体。
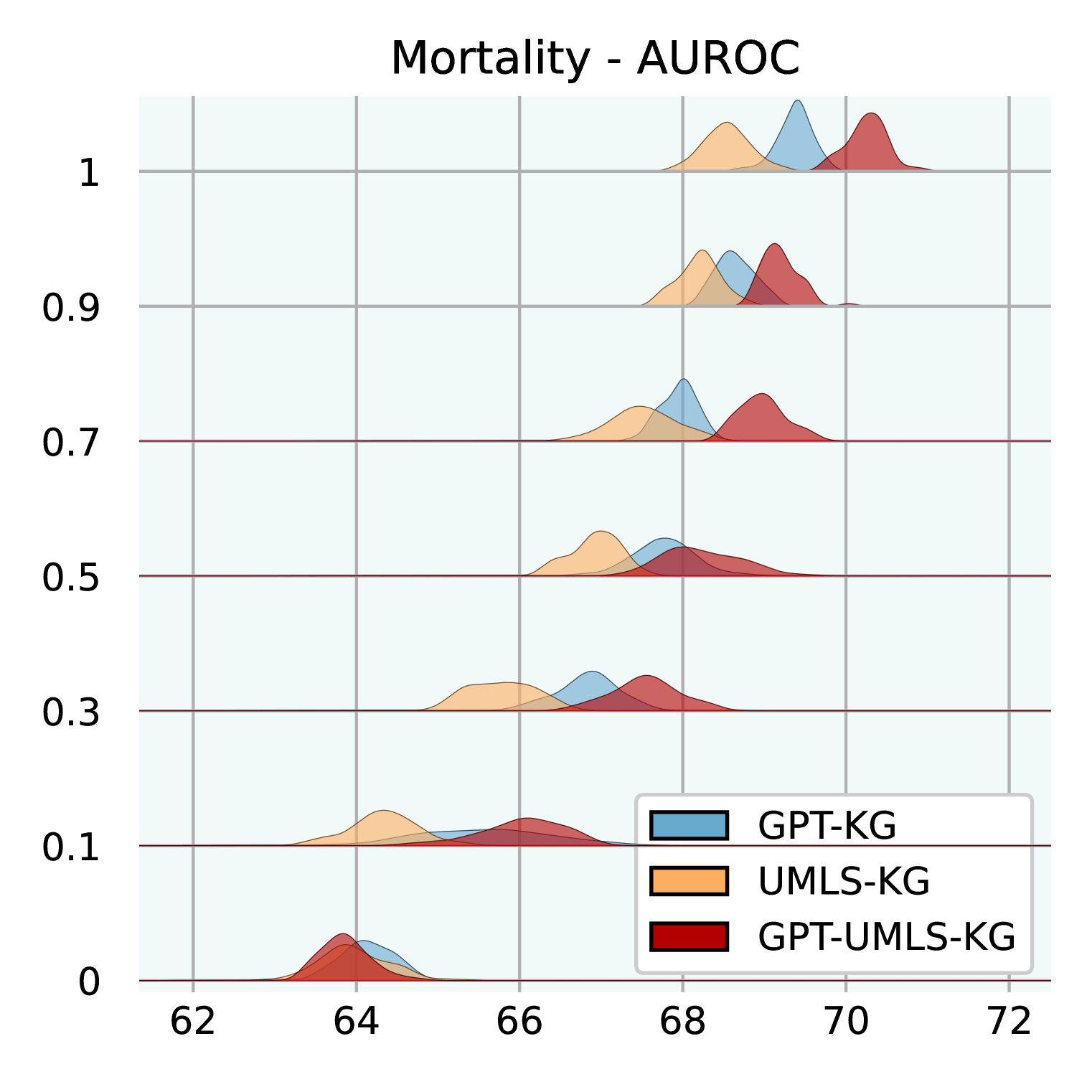
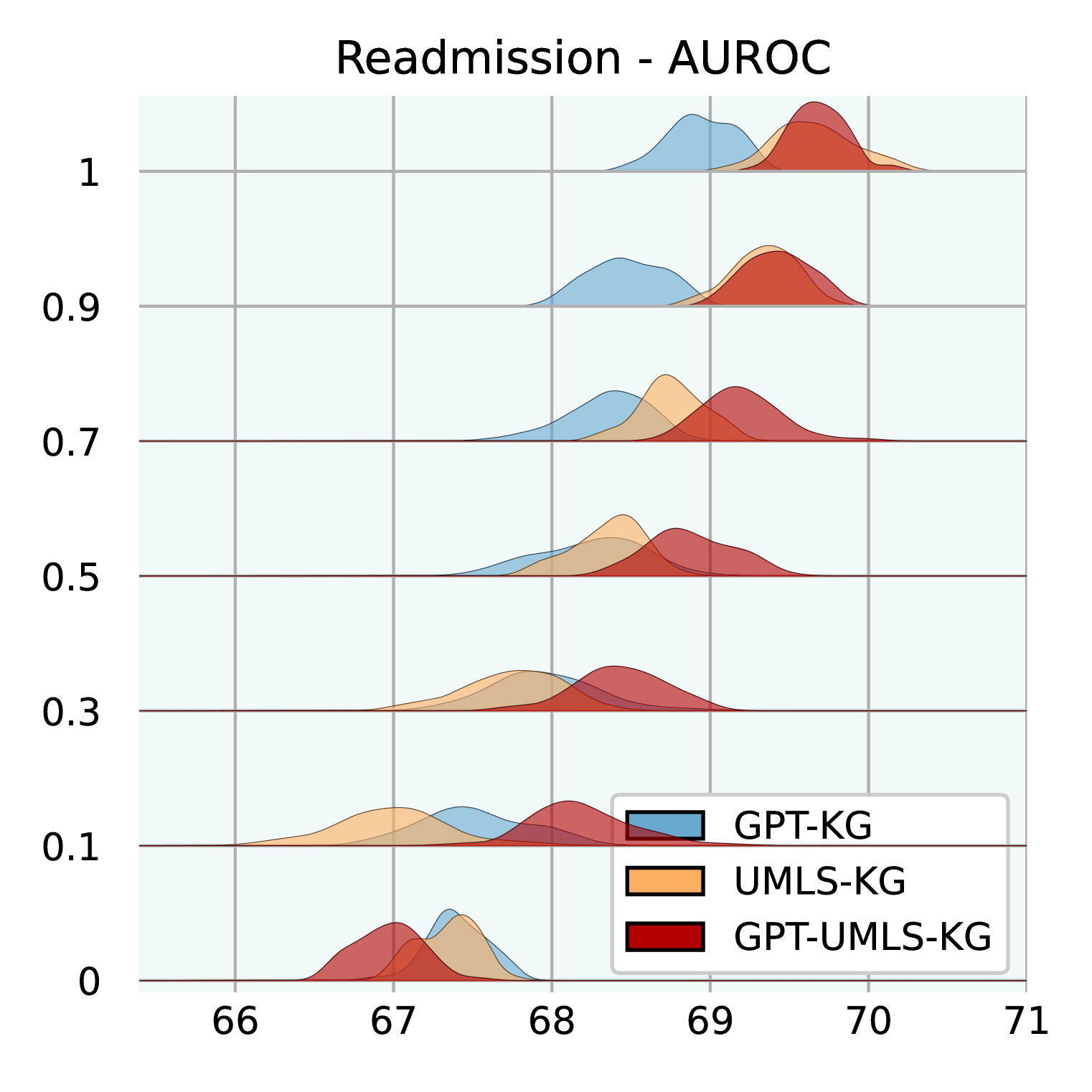
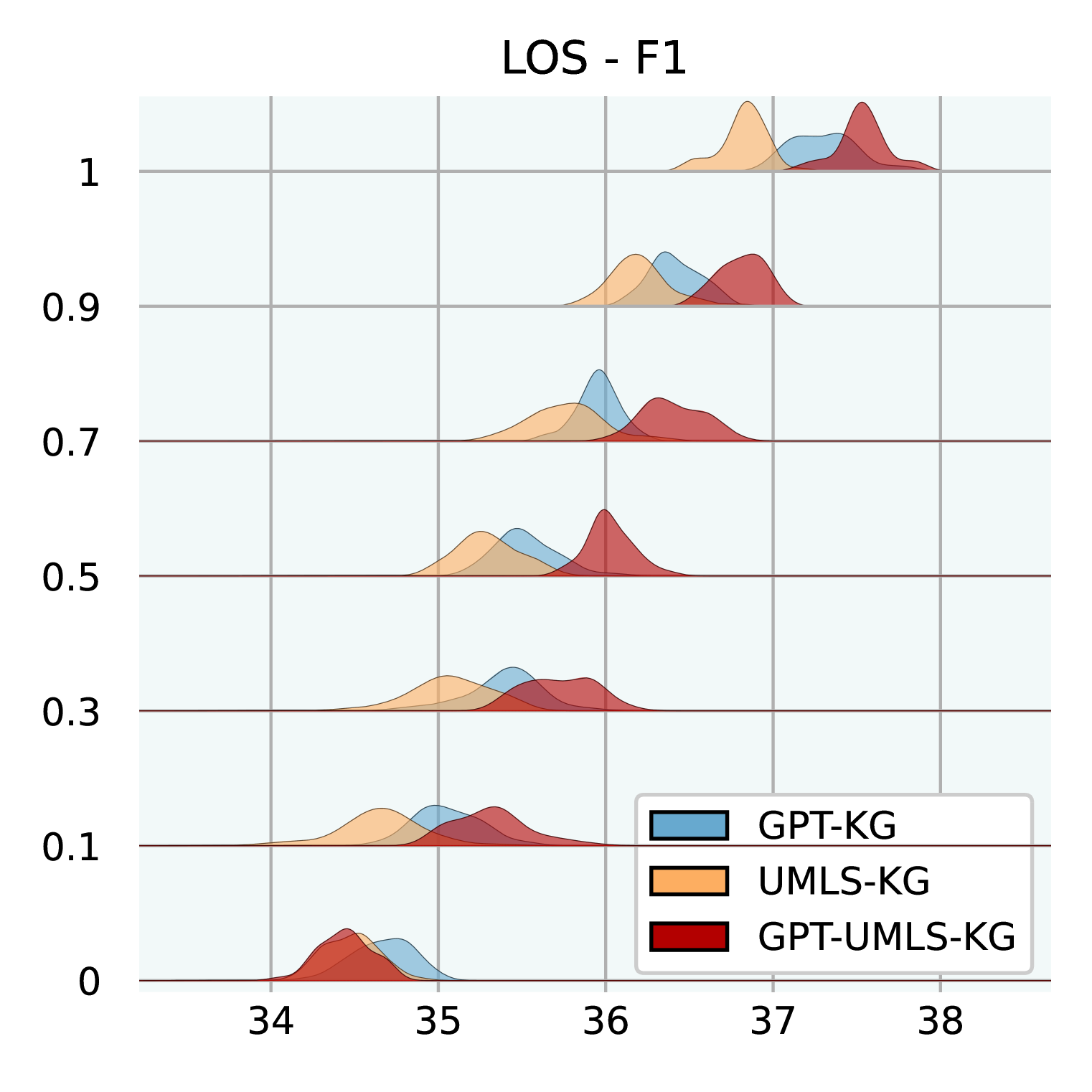
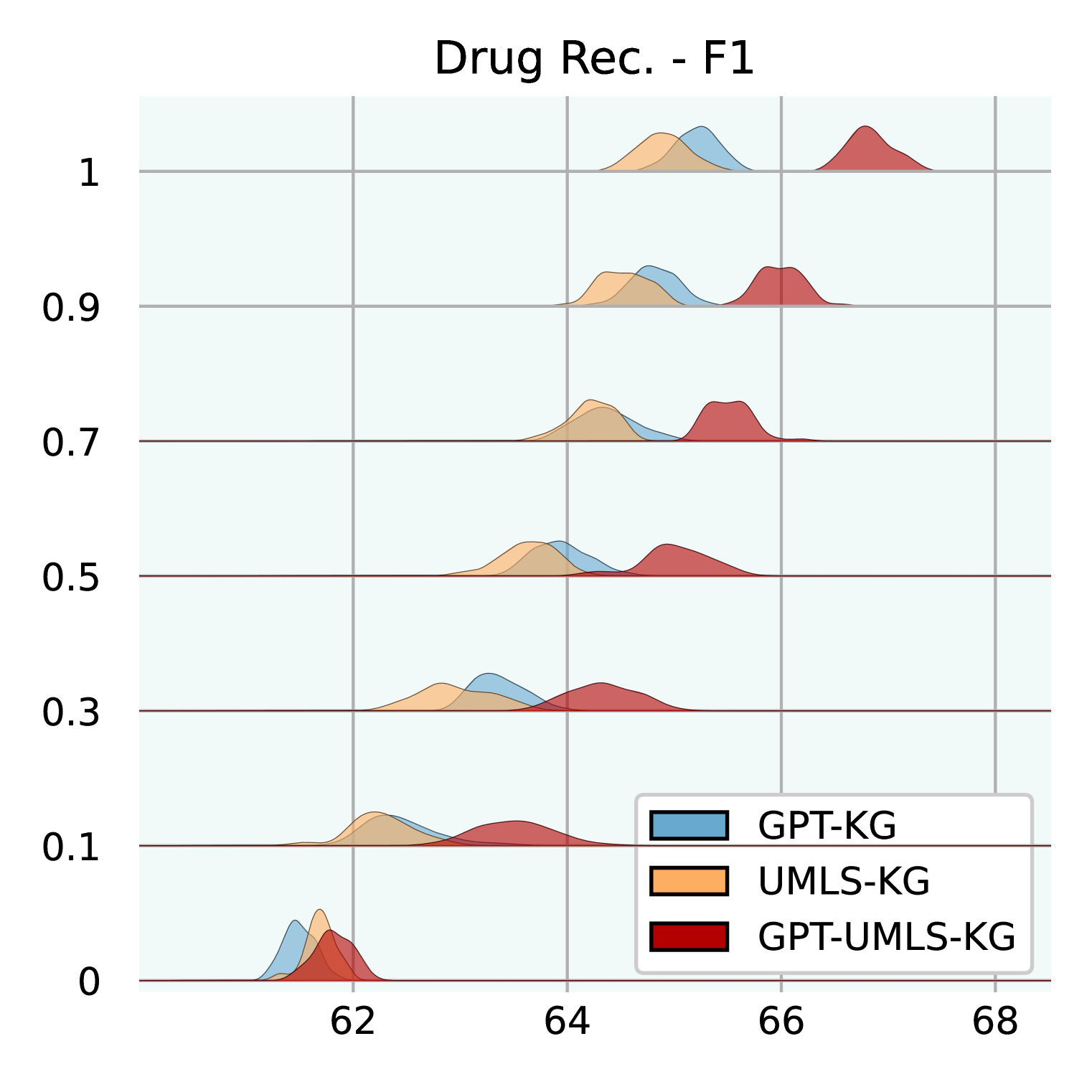
图3:不同公斤大小的性能。 我们在三个不同的 KG 上进行测试:GPT-KG、UMLS-KG 和 GPT-UMLS-KG。 对于每个子 KG,我们使用不同的比率进行采样:[0.0,0.1,0.3,0.5, 0.7,0.9,1.0]同时确保与 EHR 医学概念对应的节点在样本之间保持一致。 这些分布基于 MIMIC-III 上使用不同随机种子的 30 次运行。
知识图大小的影响。 图3说明了不同大小的 KG 如何影响GraphCare的功效。 我们测试 GPT-KG(由 GPT-4 生成)、UMLS-KG(从 UMLS 采样)和 GPT-UMLS-KG(组合)。 主要观察结果包括:(1)在所有 KG 中,随着 KG 大小比例的增加, GraphCare的性能也会相应提高。 (2)合并后的 GPT-UMLS-KG 始终优于其他两个 KG。 这强调了这样一个前提:更丰富的知识库可以实现更精确的临床预测。 此外,它表明 GPT-KG 和 UMLS-KG 可以通过看不见的知识相互丰富。 (3)KG 贡献的程度取决于手头的任务。 具体而言,与 UMLS-KG 相比,GPT-KG 对死亡率和 LOS 预测的影响更大。 相反,UMLS-KG 在再入院预测方面表现出色,而两个 KG 在药物推荐方面都表现出相当的能力。 (4)值得注意的是,较低的 KG 比率(从 0.1 到 0.5)与较大的标准差相关,这是由于稀疏采样的子 KG 中包含重要知识的可能性降低。
4.2.2双注意力增强图神经网络的效果
表3提供了对所提出的 GNN BAT 的深入消融研究,强调了不同组件对模型有效性的深远影响。
数据显示,排除节点级注意力(�)导致两个数据集的任务性能普遍下降。 对于药物推荐任务来说,这种下滑尤为明显。 关于访问级别的关注(乙),其缺失的影响在 MIMIC-IV 数据集中更明显。 这可能归因于 MIMIC-IV 每名患者的平均就诊次数较多,如表1所示。 鉴于这种差异,区分不同访问的能力对于所有任务都至关重要。 此外,在考虑任务时,很明显 RA. 任务特别容易受到访问级别注意力调整的影响(乙)和边权重(在ℛ)。 这强调了在 EHR 中捕获访问级别的细微差别和实体间关系以确保精确 RA 的重要性。 结果预测。 关于注意力初始化(AttnInit),它成为启动模型从一开始就更容易接受相关临床见解的关键因素。 忽略此初始化会导致性能明显下降,特别是对于药物推荐。 这表明,通过引导最初的注意力集中在个性化知识图谱中潜在有影响力的节点上,该模型可以更熟练地吸收重要模式并做出明智的预测。
表3:BAT 的变异分析。 我们测量 MT 的 AUROC。 和RA。 预测,以及用于 LOS 预测和药物推荐任务的 F1-score。 �,乙,在ℛ、AttnInit分别是节点级、访问级注意力、边权重和注意力初始化。 我们报告每个案例 10 次运行的平均性能。
| 模拟-III | 模拟-IV | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 案件 | 变体 | 公吨。 | DA。 | 这 | 药品。 | 公吨。 | DA。 | 这 | 药品。 |
| #0 | 墙 | 70.3 | 69.7 | 37.5 | 66.8 | 73.1 | 68.5 | 34.2 | 63.9 |
| #1 | 不带/不带� | 68.7↓0.6 | 68.5↓1.2 | 36.7↓0.8 | 64.6↓2.2 | 72.2↓0.9 | 67.8↓0.7 | 33.1↓1.1 | 61.6↓2.3 |
| #2 | 不带/不带乙 | 69.9↓0.4 | 68.7↓1.0 | 37.2↓0.3 | 66.5↓0.3 | 72.1↓1.0 | 67.0↓1.5 | 33.5↓0.7 | 63.2↓0.7 |
| #3 | 不带/不带在ℛ | 69.8↓0.5 | 68.4↓1.3 | 36.8↓0.7 | 66.3↓0.5 | 72.9↓0.2 | 67.9↓0.6 | 33.7↓0.5 | 63.1↓0.8 |
| #4 | 不带AttnInit | 69.5↓0.8 | 69.2↓0.5 | 37.2↓0.3 | 65.5↓1.3 | 72.5↓0.6 | 68.1↓0.4 | 34.1↓0.1 | 62.4↓1.5 |
| #5 | 不含 #(1,2,3,4) | 67.4↓2.9 | 68.1↓1.6 | 36.0↓1.5 | 64.0↓2.8 | 71.7↓1.4 | 67.5↓1.0 | 32.9↓1.3 | 60.5↓3.4 |
4.3GraphCare的可解释性。
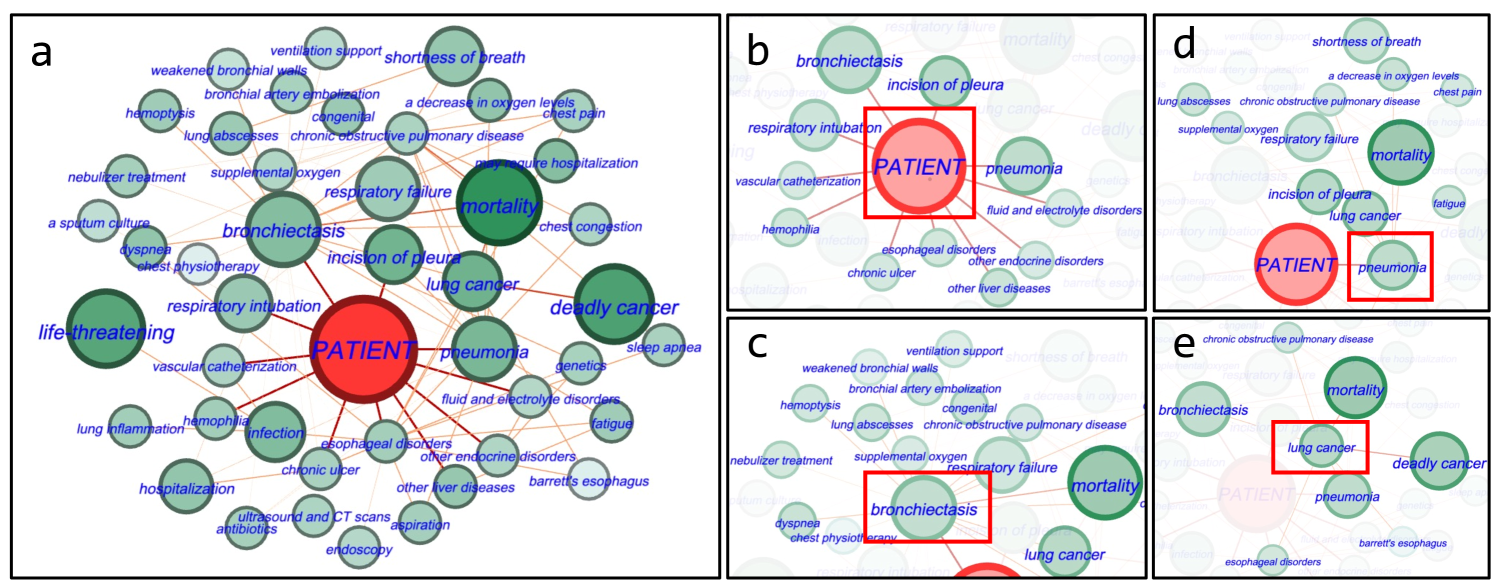
图4:显示患者个性化 KG 以及重要性评分(附录F)的示例。 为了更好的展示,我们隐藏了药物的节点。 红色节点代表患者节点。 分数越高的节点 越大。分数越高的边缘越厚。子图 (a) 显示了该个性化 KG 的中心区域概述,其他子图显示了更多详细信息,并突出显示了重点节点。darker darker
图4显示了与特定患者(预测死亡率 1)相关的用于死亡率预测的个性化 KG 示例,该患者仅通过我们的GraphCare方法进行了准确预测,而其他基线则错误地估计了结果。 在图4a中,对死亡率预测有贡献的重要节点和边(例如“致命癌症”)以较高的重要性分数进行了强调。 这证明了我们的 BAT 模型在识别相关节点和边方面的有效性。 此外,图4b显示了连接到患者节点的直接 EHR 节点,使用患者节点嵌入增强了预测的可解释性。 图4c和4d显示了与直接 EHR 节点“支气管扩张”和“肺炎”相关的 KG 三元组。这些节点与“ 死亡率”、“呼吸衰竭”、“肺癌”、“呼吸急促”等重要节点相连,表明它们的权重较高。 在图4e中,“肺癌”节点充当“支气管扩张”和“肺炎”的公共连接器。它与“ 死亡率”和“致命癌症”联系在一起,凸显了它的重要性。 删除该节点对模型的性能产生了显着影响,表明其在准确预测中的关键作用。 这强调了全面健康数据的价值,并考虑所有潜在的健康因素,无论它们看起来有多么间接的联系。
5结论
我们提出了GraphCare,一个构建个性化知识图以增强医疗保健预测的框架。 实证研究表明,它在两个数据集上的各种任务中优于基线。 凭借其对有限数据的鲁棒性和 KG 大小的可扩展性,GraphCare在医疗保健领域有望发挥巨大潜力。 我们在附录A中讨论道德、限制和风险。
参考
- 阿尔卡米西等人。 (2022)Badr AlKhamissi、Millicent Li、Asli Celikylmaz、Mona Diab 和 Marjan Ghazvininejad。作为知识库的语言模型综述,2022 年。
- 阿什法克等人。 (2019)阿瓦伊斯·阿什法克、安妮塔·圣安娜、马库斯·林曼和斯瓦沃米尔·诺瓦奇克。使用电子健康记录深度学习进行再入院预测。生物医学信息学杂志,97:103256,2019。
- 巴达瑙等人。 (2014)德兹米特里·巴达瑙、Kyunghyun Cho 和 Yoshua Bengio。通过共同学习对齐和翻译来进行神经机器翻译。arXiv 预印本 arXiv:1409.0473,2014年。
- 巴斯蒂安等人。 (2009)马蒂厄·巴斯蒂安、塞巴斯蒂安·海曼和马蒂厄·雅科米。Gephi:一种用于探索和操作网络的开源软件。网络和社交媒体国际 AAAI 会议记录,第 3 卷,第 361-362 页,2009 年。
- 贝洛等人。 (2008)弗朗索瓦·贝洛、马克·亚历山大·诺林、妮可·图里尼、菲利普·里戈和让·莫里塞特。Bio2rdf:构建生物信息学知识系统的混搭。生物医学信息学杂志,41(5):706–716,2008。
- 博伊等人。 (2021)Suman Bhoi、Mong Li Lee、Wynne Hsu、Hao Sen、Andrew Fang 和 Ngiap Chuan Tan。使用基于图表的方法个性化药物推荐。ACM 信息系统汇刊 (TOIS),40(3):1–23,2021 年。
- 布洛姆等人。 (2019)马蒂亚斯·卡尔·布洛姆、阿瓦伊斯·阿什法克、安妮塔·圣安娜、菲利普·D·安德森和马库斯·林曼。训练机器学习模型来预测急诊科出院患者的 30 天死亡率:一项基于人群的回顾性登记研究。BMJ 公开,9(8):e028015,2019。
- 博登雷德 (2004)奥利维尔·博登雷德。统一医学语言系统(umls):整合生物医学术语。核酸研究,32(suppl_1):D267–D270,2004。
- 布朗等人。 (2020)汤姆·布朗、本杰明·曼、尼克·莱德、梅兰妮·苏比亚、贾里德·D·卡普兰、普拉富拉·达里瓦尔、阿文德·尼拉坎坦、普拉纳夫·希亚姆、吉里什·萨斯特里、阿曼达·阿斯克尔等。语言模型是小样本学习者。神经信息处理系统的进展,33:1877-1901,2020。
- 蔡等人。 (2015)蔡雄才、奥斯卡·佩雷斯-孔查、恩里科·科耶拉、费尔南多·马丁-桑切斯、理查德·戴、大卫·罗夫和布兰卡·加莱戈。使用电子健康记录数据实时预测死亡率、再入院和住院时间。美国医学信息学协会杂志,23(3):553–561,2015 年 9 月。ISSN 1067-5027。doi:10.1093/jamia/ocv110。网址Real-time prediction of mortality, readmission, and length of stay using electronic health record data | Journal of the American Medical Informatics Association | Oxford Academic。
- 陈等人。 (2022)Chen Chen, Yufei Wang, Bing Li, and Kwok-Yan Lam.知识是扁平的:用于各种知识图补全的 seq2seq 生成框架。arXiv 预印本 arXiv:2209.07299,2022年。
- 陈等人。 (2023)
摘要与引言
GRAPHCARE是一篇发表于ICLR 2024的会议论文,旨在通过个性化知识图谱(KGs)增强基于电子健康记录(EHR)的临床预测模型。作者提出了一种框架,该框架利用外部KGs来提高EHR数据的预测能力。GRAPHCARE通过从大型语言模型(LLMs)和外部生物医学KGs中提取知识,为每位患者构建特定的KG,并使用这些KG训练双注意力增强(Bi-attention AugmenTed, BAT)图神经网络(GNN),以执行多种健康预测任务。
方法论
GRAPHCARE的方法包括以下几个步骤:
患者知识图谱生成:首先从患者的医疗概念(疾病、程序、药物等)出发,通过向LLMs提问或从现有图谱中检索子图来生成特定医疗概念的KG。
节点和边缘聚类:在生成了特定概念的KG后,系统进一步对节点和边进行聚类,创建每个医疗概念的更综合的KG。
构建患者特定KG:将患者相关的概念特定KG融合,并结合患者访问数据中的时间序列信息,形成个性化KG。
应用BAT GNN:使用双注意力增强的GNN,这一模型将关注重要访问和节点,并通过注意力权重突出显示它们,以进行不同的下游预测任务。
实验证明
GRAPHCARE在MIMIC-III和MIMIC-IV两个公共EHR数据集上的效果得到了验证。与多个基线模型相比较,GRAPHCARE在死亡率预测、再入院预测、住院时长(LOS)预测和药物推荐这四个关键的医疗预测任务中表现更佳。在MIMIC-III上,平均AUROC提升了17.6%,6.6%,4.1%,2.1%,而在MIMIC-IV上,提升了7.9%,3.8%,3.5%,1.8%。此外,该方法在数据有限的情况下展示了明显的优势。
相关工作
在相关工作部分,作者讨论了EHR数据和预测模型、临床知识图谱、大型语言模型在医疗预测中的应用情况。指出了现有方法的局限性,包括对简单层次关系的依赖以及未充分利用外部生物医学知识库中的丰富上下文信息。
总结
GRAPHCARE通过结合LLMs和外部生物医学KGs,生成个性化的患者KG,然后使用这些KG来增强基于GNN的医疗预测能力。这种方法能够提供更准确的预测,并且在数据受限情况下特别有用,展现了将开放世界知识融入健康预测的潜力。















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











