









从图像到万象,InternVL 2.0 书生·万象多模态大模型发布!

目录
收起
代码开源/模型使用方法:
76B大模型,司南评测优于GPT-4O
8B端侧小模型,消费级单卡可部署
试用Demo:
正文开始!
1.多模态大模型的开始,AGI的黎明
三年演进,多模态先行者的实至名归之路
2.更少资源、更高性能,世界领先不止于数值
数值表:关键评测优于国际顶尖商业模型
2. 通专融合,万象理解万物
首创渐进式对齐训练,实现首个与大模型对齐的视觉基础模型
3.真实世界感知实例展示
图文问答样例展示(点击播放视频)
检测样例展示
开源链接
代码开源/模型下载链接:
试用Demo:
4B版本端侧小模型下载链接(以1/10的参数量实现80%的能力):
OmniCorpus开源/数据下载链接(目前规模最大的图文交错数据集):
MM-NIAH开源/数据下载链接(首个针对多模态长文档理解能力的评测基准):
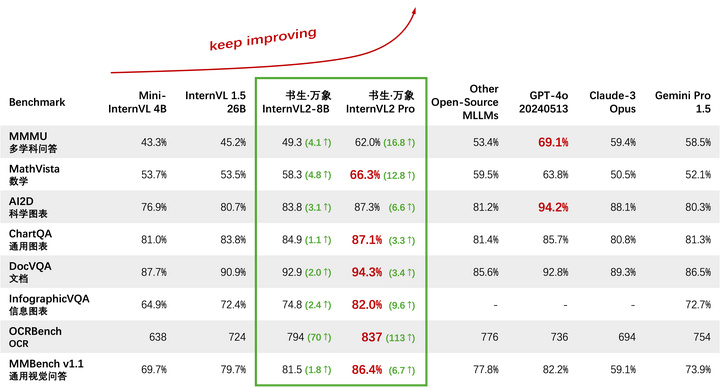
7月4日下午,世界人工智能大会科学前沿论坛, 老师 代表InternVL研究团队发布了2.0版本,中文正式名称为" 书生·万象”。它是目前已知性能 最强的开源 多模态大模型(见数值对比表),也是国内 首个在MMMU(多学科问答)上突破60的模型。数学基准 MathVista的测试中、书生·万象的得分为66.3%, 显著高于其他闭源商业模型和开源模型。在通用图表基准ChartQA、文档类基准DocVQA、信息图表类基准InfographicVQA中以及通用视觉问答基准MMBench (v1.1)中,书生万象也取得了 最先进(SOTA)的表现。科学图表基准AI2D的测试中,书生万象大幅领先其他优秀的开源模型,并 与商业闭源模型不相上下。
OpenCompass司南 - 评测榜单rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME
代码开源/模型使用方法:
https://github.com/OpenGVLab/InternVL
76B大模型,司南评测优于GPT-4O
https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B
8B端侧小模型,消费级单卡可部署
https://huggingface.co/OpenGVLab/InternVL2-8B
试用Demo:
https://internvl.opengvlab.com/
正文开始!
1.多模态大模型的开始,AGI的黎明
2022年,OpenAI的ChatGPT引爆大语言模型(LLM)热潮,人工智能大模型行业风起云涌,国外顶尖机构相继跟进,LLaMa、Cluade、Mixtral、Qwen、ChatGLM、Kimi、浦语等优秀的大语言模型竞争日渐胶着,能力不分高下。然而,人工智能的能力不能止于文字,面对万象缤纷的真实世界,LLM似乎难以领会。
图灵奖得主Yann LeCun曾在一次采访[1]中指出,为什么猫狗没有语言,但对世界的理解却比任何 LLM 都要好?这个问题17 世纪的 Sensim 学派哲学家可以回答:因为没有感知就没有认知。生物在5亿年进化出视觉 ,1万年前才有智人语言/现代人语言,视觉的信息带宽(约20MB/s)远高于语言信息带宽(约12bytes/s) [2]。LeCun 认为,没有视觉就无法建立对世界有深刻理解的模型,纽约大学助理教授谢赛宁则直言“现有的单纯的语言模型是一个盲人摸象般被遮蔽了双眼的博学的系统”[3]。

InternVL对摄影作品的构图分析(回答详情见3.真实世界感知实例展示)
就这样,多模态来到人工智能的浪潮之巅。国际顶尖机构相继入局,谷歌推出Gemini Pro1.5,OpenAI推出GPT-4O等商业闭源模型。书生从视觉生根,稳扎稳打一路走来,如今进化为书生·万象多模态大模型。万象,代表我们对多模态大模型的愿景,即理解真实世界一切事物和景象,实现全模态全任务的通用智能。它涵盖图像,视频,文字,语音、三维点云等5种模态,首创渐进式对齐训练,实现了首个与大语言模型对齐的视觉基础模型,通过模型”从小到大”、数据”从粗到精"的渐进式的训练策略,以1/5成本完成了大模型的训练。它在有限资源下展现出卓越的性能表现,横扫国内外开源大模型,媲美国际顶尖商业模型,同时也是国内首个在MMMU(多学科问答)上突破60的模型。它在数学、图表分析、OCR等任务中表现优异,具备处理复杂多模态任务、真实世界感知方面的强大能力,是当之无愧的最强多模态开源大模型。
三年演进,多模态先行者的实至名归之路

2021年,上海人工智能实验室推出推出国内首个广泛覆盖多种视觉任务的大模型书生,在四大任务26个场景性能显著提升,仅用10%的数据便可超越OpenAI的CLIP模型。 2022年,发布通用视觉大模型InternImage[4](点击了解),实现一个模型在COCO 物体检测,ImageNet图像分类等视觉标杆任务上同时达到世界最佳性能,12大类50余种权威评测性能领先,其核心论文入选CVPR 2023 PaperDigest十大最具影响力论文榜单。 2023年底,研发了图文大模型InternVL[5](点击了解),以1/3参数量超谷歌视觉模型ViT-22B,减小80%训练成本。2023年5月发布的InternVL-1.5版本智源评测、司南评测等权威榜单认证,性能比超国际上的一系列闭源模型,如Open AI公司的GPT-4V、谷歌Gemini Pro等。在国际最大的人工智能开源社区HuggingFace 开源后,即登顶模型下载量增长趋势榜单,位居首位达到一个月之久,并迅速跻身视觉语言基础模型总下载量榜单上排列前10,与脸书的DINO、谷歌ViT等知名模型位于同一榜单,同时实验室也是该榜单上的唯一中国机构。
今天我们隆重推出书生·万象多模态大模型(InternVL 2.0)。关键评测指标比肩国际顶尖商用闭源模型,支持图像、视频、文本、语音、三维、医疗多种模态支持百种下游任务,性能媲美任务专用模型。
2.更少资源、更高性能,世界领先不止于数值
数值表:关键评测优于国际顶尖商业模型
书生·万象在处理复杂多模态数据方面具有强大能力,尤其是在数学、科学图表、通用图表、文档、信息图表和OCR等任务中表现优异。书生·万象在多个基准测试中表现出色,书生·万象多模态大模型是国内首个在MMMU(多学科问答)上突破60的模型,在视觉基准MathVista的测试中、书生·万象的得分为66.9%,显著高于其他闭源商业模型和开源模型。在通用图表基准ChartQA、文档类基准DocVQA、信息图表类基准InfographicVQA中以及通用视觉问答基准MMBench (v1.1)中,书生万象也取得了最先进的表现。在科学图表基准AI2D的测试中,书生万象大幅领先其他优秀的开源模型,并与商业闭源模型不相上下。
准确版本的数值对比表(比WAIC发布现场又更新啦!)

数值对比表

发布现场版本数值对比表
我们除了在评测基准上数值领先,作为“最强”多模态大模型,真金不怕火炼,直接拿这个信息量极大的表格,输入模型中看看它的分析能力。下图为真实输出截图。
InternVL 2.0 不但看懂了这是开源模型与闭源模型的对比,输出的数值、评测基准名称全部正确。
“这些数据表明,“书生·万象”在数学问题解决、图表理解、文档问答、信息图表问答和光学字符识别(OCR)等方面具有显著的优势。总的来说,这张表格展示了“书生·万象”模型在多模态任务中的强大性能,特别是在数学和图表理解方面表现尤为突出。” -- 来自书生·万象的自我评价(见下图)。

2. 通专融合,万象理解万物

书生万象具有千亿规模参数,支持图像,视频,文字,语音、三维点云等模态。为了使模型能够支持丰富的输出格式,书生万象首次使用了向量链接技术,链接各领域专用解码器,打通梯度传输链路,实现通专融合,支持检测、分割、图像生成、视觉问答等百种细分任务,性能媲美各领域的专家模型。为了训练书生万象模型,我们从各类来源构建了最大图文交错数据集OmniCorpus,包含约160亿图像,3万亿文本词元,相比现有开源图文数据集 ,图像数量扩大了三倍,文本数量扩大了十倍。
首创渐进式对齐训练,实现首个与大模型对齐的视觉基础模型

传统的预训练范式直接使用大模型+大数据进行一步到位训练,需要大量的算力资源。为了提高训练效率,研究团队首创了渐进式训练策略,先利用小模型在海量带噪数据上进行高效预训练,然后再使用大模型在较少高质量精选数据上进行高效对齐,模型"从小到大",数据"从粗到精",仅需20%的算力资源即可取得同等效果。 采用这种训练策略,我们实现了首个与大模型对齐的视觉基础模型,同时,我们的多模态大模型,展现出卓越的性能,在MathVista(数学)、AI2D(科学图表)、MMBench(通用视觉问答)、MM-NIAH(多模态长文档)等评测上可比肩GPT-4o、Gemini 1.5 Pro等闭源商用大模型。
3.真实世界感知实例展示
图文问答样例展示(点击播放视频)

01:14
检测样例展示
加大一些难度测试万象的视觉能力。输入一张车流密集的交通图,让它检测出所有车辆、行人和交通灯,它很快给出对应物体的坐标和检测框。亲爱的读者朋友仔细可以找找看,交通灯一共有几个?

行人和车辆的检测,对于InternVL 2.0来说是一般任务

交通灯有点难度,模型给出的检测结果是5个。远处的2个不容易看到,我们做了放大效果图,看来InternVL的视力很不错呢!

开源链接
目前多模态技术仍处于早期发展阶段,距离人类专家性能还相距甚远,发展空间潜力巨大。上海人工智能实验室致力于开源和开放的研究,旨在推动原创技术的发展,带来技术革新和行业进步。多模态大模型必将为AI发展带来比LLM更高的浪潮,希望各界同行与我们一起探索多模态大模型关键问题,共建多模态大模型生态!
代码开源/模型下载链接:
https://github.com/OpenGVLab/InternVL
试用Demo:
进入https://github.com/OpenGVLab/InternVL,点击“Chat Demo”,目前仅提供加固过滤版模型试用,输出效果可能与文中展示有误差:

4B版本端侧小模型下载链接(以1/10的参数量实现80%的能力):
https://modelscope.cn/models/OpenGVLab/Mini-InternVL-Chat-4B-V1-5
OmniCorpus开源/数据下载链接(目前规模最大的图文交错数据集):
https://github.com/OpenGVLab/OmniCorpus
MM-NIAH开源/数据下载链接(首个针对多模态长文档理解能力的评测基准):
https://github.com/OpenGVLab/MM-NIAH
参考
- ^https://zhuanlan.zhihu.com/p/687859297
- ^https://zhuanlan.zhihu.com/p/687859297
- ^智源独家丨谢赛宁:AI是否需要更强的视觉基础来实现理解和意义?
- ^https://zhuanlan.zhihu.com/p/610772005
- ^https://zhuanlan.zhihu.com/p/702946079
编辑于 2024-07-23 12:49・IP 属地上海
















 2901
2901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











