







系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
TODO:写完再整理
文章目录
- 系列文章目录
- 前言
- 一、C/C++的介绍
- 二、C++自带的的数据结构(stl数据接结构进阶的基础)
- 0.NULL和nullptr数据类型
- 1.布尔型bool
- 2.整型int(int_16、int_32、uint_16、uint_32...)
- 3.浮点型float/double
- 4.字符型char
- 5.字符串型string
- 6.数组array
- 7.向量vector【stl库常用】
- 9.结构体struct
- 10.类class和对象
- 11.联合union
- 12.枚举eunm
- 14.类
- 三、指针pointer--操作内存的神器!
- 四、函数的使用--方法的实现
- 五、C++的模块结构
- 1.C/C++关键字
- (1)关键字extern的作用
- (2)关键字static的作用
- (3)关键字define的作用
- (4)关键字const的作用--运行时常量性
- (5)关键字constexpr的作用--运行时常量性+编译时常量性
- (5)关键字register的作用
- (6)关键字volatile的作用
- (7)关键字typedef的作用--取数据类型别名
- (8)关键字using的作用
- (9)关键字decltype的作用【C++】--推导出一个表达式的类型
- (10)final 关键字【C++ 11】
- (11)override关键字【C++ 11】
- (11)explicit关键字--显式地进行类型转换
- (12)auto关键字--自动推断数据类型
- (13)default 和 delete关键字
- (16)assert关键字
- 2.C/C++常用操作符
- 3.C++预处理指令#--头文件包含、宏定义、条件编译、输出编译警告与错误
- 4.强制类型转换
- 5.重载机制及多态性
- 6.虚函数和纯虚函数virsual
- (1)虚方法(virsual method)
- (2)C++虚函数和虚类
- (3)override关键字的作用
- (4)纯虚函数、虚函数的作用
- 7.命名空间namespace
- 8.模块化编程(工厂设计的方法基础)
- 9. template模板语法【泛型编程,函数、类与运算符重载的升级版】
- 10.C++11列表初始化
- 11、lambda表达式
- 12、内存字节对齐
- 13、动态内存申请与释放
- 六、C++内置库支持【库->API】
- 七、C/C++语法避坑
- 八、、防御式编程
- 参考资料
- 待整理
前言
认知有限,望大家多多包涵,有什么问题也希望能够与大家多交流,共同成长!本文先对C/C++语言语法做个简单的介绍,具体内容后续再更【防盗标记–盒子君hzj】,其他模块可以参考去我其他文章
提示:以下是本篇文章正文内容
编程基础及进阶
1、c和c++需要语法(b站和那本书)
2、数据结构与算法
3、计算机网络
4、操作系统
5、设计模式
C++语言与数据结构、算法的关系
数据结构与算法是不依赖任何一种语言的,对于C++ 语言,它有自己的语法和调用系统的机制
所以说,C++和数据结构与算法是两个方面的内容
参考书籍:
(1)csapp深入理解计算机系统
(2)代码大全
一、C/C++的介绍
1、从面向过程,到面向对象
C语言已经有模块化和结构化的优势,但是还是一个面向过程的语言,C面向过程的编程一般程序比较长,因为要对每个对象进项详细的描述,这样的好处是主函数特别精简,但可读性非常差。C++语言增加了面对对象的机制,同时支持面向过程。
面向对象的思想
把一个复杂的对象,不断细分成一个子对象,逐一突破,每个对象由属性和行为两个要素
面对对象的思维转变:程序员不在面对一个个函数和变量,而是要放眼大局,**面对一个个对象看待问题**
.
面向过程和面向对象的两种思维比喻
面向过程类似于企业老总什么都要自己亲力亲为,累得要死
面向对象类似于企业老总吧公司分成几个板块,任命经理对象,由经理对象处理好各自板块的问题,我仅仅需要管理好经理即可。
.
使用面向对象的编程技术开发程序的基本步骤
1、定义一个有属性(变量)和方法(函数)的类(模板)
2、实现方法的过程(构造函数)
3、调用方法实现对象的功能
.
面向对象的优点
1、面向过程编程偏向于关注对数据的处理过程,面向对象的编程是偏向于对数据进行怎行的处理,两者有很多相通的地方。
2、面向对象的编程方法的一个重要特征是用一个对象把数据和处理数据的函数封装到一起。越高级的语言封装的越多,每个函数只处理调用它的那个对象,所包含的数据,所有的数据偶属于同一个对象,类仅仅是一个描述对象的模板
3、面向对象是一个国家分成每个家庭进行管理,一出错仅仅某个家庭受害;面向过程是一个国家一起管理,一出错大家一起受伤害
(4)高级的面向对象编程方法
静态成员,静态对象、静态方法、虚方法、抽象方法、多态
.
2、C++的我特性–面向对象思想的的特点
(1)封装机制–类
封装定义:将数据和函数等集合在一个单元中(即类)。被封装的类通常称为抽象数据类型。封装的意义在于保护或者防止代码(数据)被我们无意中破坏。
封装的比喻(类似于分公司):把对象的属性和方法结合成一个独立的系统单位,并尽可能的隐藏对象的内部细节(包括复杂的函数实现和变量定义),这样能把程序变得更加“仔细”,更加“模块化”
抽象的比喻(类似于一个总公司):相当于总公司要对分公司下达的一些指令和指标。如同一个协议吧
.
(2)继承机制–类
继承定义:继承主要实现重用代码,节省开发时间。它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
继承的比喻:类似于儿子继承了老爸(基类,父类)的所有属性,并在这个基础上儿子(子类)有所扩展(属性和方法)
C++的继承性体现【公有继承、受保护继承、私有继承的区别】
(1)公有继承时,派生类对象可以访问基类中的公有成员,派生类的成员函数可以访问基类中的公有和受保护成员;
(2)私有继承时,基类的成员只能被直接派生类的成员访问,无法再往下继承;
(3)受保护继承时,基类的成员也只被直接派生类的成员访问,无法再往下继承。
.
(3)多态–重载与虚函数
多态定义:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。在运行时,可以通过指向派生类的基类指针,来调用实现派生类中的方法。有编译时多态和运行时多态。
多态的比喻:和继承相关,就是儿子对爸爸有所扩展的部分,同时能继承多个基类
C++的多态性体现
多态性可以简单地概括为一个接口,多种方法,程序在运行时才决定调用的函数 。C++多态性主要是通过虚函数实现的,虚函数允许子类重写override(注意和overload的区别,overload是重载,是允许同名函数的表现,这些函数参数列表/类型不同)
在绝大多数情况下,程序的功能是在编译的时候就确定下来的,我们称之为静态特性。反之,如果程序的功能是在运行时刻才能确定下来的,则称之为动态特性。C++中,虚函数,抽象基类,动态绑定和多态构成了出色的动态特性。
1)类class、虚函数virtual、类模板、重载等等
2)运行时多态性:通过虚函数实现,虚函数:虚函数允许子类重写override,用于定义同一功能,类似实现的一个父类函数
3)编译时多态性:通过重载函数实
现、
在团队开发中,这些特点更有利于分工合作~
3、C++对C语言的语法扩充
(0).NULL和nullptr数据类型,解决二义性
(1)C++变量的定义可以在程序中的任意一行(这样在大型程序中,变量灵活定义能大大提高可读性,但是C语言用声明也能解决这个问题)
(2)提供了标准的输入输出对象,cin\cout
(3)用const代替了define做宏定义,define只能修饰常量,而const可以修饰常量、变量和函数,更加灵活
(4)提供函数重载、函数模板、带默认值的函数
【防盗标记--盒子君hzj】
(5)引用类型,把指针的使用更加浅显化
(6)单目作用域运算符
(7)string类型字符串
(8)使用了new和delete代替了malloc和free函数
(9)从C语言的面向过程的编程方式,过度到面向对象的的编程方式。这样更有效的管理复杂,庞大的代码
(10)C++能开发,编译器、操作系统、应用软件、游戏等等。
.
4、C++的开发工具
1、记事本(notepad++)+命令行(上手慢,大牛级别)
2、visual C++6.0(太古老,和现在流行的系统会有冲突)
3、VS2015(功能强大,安装包和一样强大)
【防盗标记--盒子君hzj】
4、vscode::block(比较好的C++开发工具,适合专业人员)
5、集成IDE:DEV C++(太老了)、CLion(非常好,收费)、CFree(国产),XCode(适合苹果系统)等等
我当然使用的是廉价的vscode啦~
.
5、C++11中基于迭代器的for循环与基于范围的for循环
(1)C++中的迭代器怎么理解?
迭代器的本质就是一个计数器,如for循环的条件参数就是一个迭代器
(1)狭意是一个整型变量的自增与与自减,控制子程序的迭代次数(迭代变量是显式的,控制子程序是隐式的)
(2)广义是指定一个迭代函数运行多少次(迭代变量是显式的,控制子程序是隐式的)
.
(2)基于迭代器的for循环写法

vector可以理解为动态数组,其特点和基本操作方式与array相似,但vector可以动态调整大小。
vector中的元素是连续存储的,这意味着我们不仅可以通过迭代器std::vector<T>::iterator,还可以像array一样使用下标来访问任意位置的元素
(3)基于迭代器的for循环

在上面的基于范围的 for 循环中,n 表示 arr 中的一个元素,auto 则是让编译器自动推导出n的类型。在这里,n的类型将被自动推导为 vector 中的元素类型 int
在 n 的定义之后,紧跟一个冒号(:)之后直接写上需要遍历的表达式,for 循环将自动以表达式返回的容器为范围进行迭代。
在上面的例子中,我们使用 auto 自动推导了 的类型。当然在使用时也可以直接写上我们需要的类型:
std;:vector<int> arr;
for(int n : arr) ;
基于范围的 for 循环,对于冒号前面的局部变量声明(for-range-declaration)只要求能够持容器类型的隐式转换。因此,在使用时需要注意,像下面这样写也是可以通过编译的:
std::vector<int> arr;
for(char n :arr);//int 会被隐式转换为 char
在上面的例子中,我们都是在使用只读方式遍历容器。如果需要在遍历时修改容器中的值,则需要使用引用,代码如下:
for(auto6 n : arr)
{
std::cout << n++ << std::endl;
}
在完成上面的遍历后,arr 中的每个元素都会被自加 1。当然,若只是希望遍历,而不希望修改,可以使用 const auto& 来定义n 的类型。这样对于复制负担比较大的容器元素 (比如一个 std:vectorstd::string数组)也可以无损耗地进行遍历。
.
C++迭代器实现循环–实现元素的操作
for (auto iter = global_plan_.begin(); iter != global_plan_.end(); ++iter) {
Trajectory local_global_traj(0.3, 0, 0, 0.02, 0);
local_global_traj.addPoint(iter->point_.x(), iter->point_.y(),
iter->yaw_);
}
6、C++ 11新增的遍历容器算法
C++11 新增加了一些便利的算法,这些算法使代码编写起来更简洁、方便。这里仅列举一些常用的新增算法,更多的新增算法读者可以参考
http://en.cppreference.com/w/cpp.algorithmo
(1)用于判断的算法 all_of、any_of和 none_of
template< class InputIt,class UnaryPredicate >
bool all_of( InputIt first,InputIt last,UnaryPredicate p );
all of 检查区间[first, last) 中是否所有的元素都满足一元判断式p,所有的元素都满足条件返回 true,否则返回 false。
.
template< class InputIt,class UnaryPredicate >
bool any_of( InputIt first,InputIt last,UnaryPredicate p );
any_of 检查区间[first, last)中是否至少有一个元素都满足一元判断式p,只要有一个元素满足条件就返回 true,否则返回 true。
.
template< class InputIt,class UnaryPredicate >
bool none_of( InputIt first,InputIt last,UnaryPredicate p );
none_of 检查区间[first, last) 中是否所有的元素都不满足一元判断式 p,所有的元素都不满足条件返回 true,否则返回 false。
.
示例
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v={1,3,5,7,9 1;
auto isEven = {}(int i)(return i % 2 != 0};
bool isallOdd = std::all_of(v.begin(),v.end(), isEven);
if (isallOdd)
cout << "all is odd" << endl;
bool isNoneEven = std;:none_of(v,begin(), v.end(), isEven);
if (isNoneEven)
cout << "none is even" << endl;
vector<int> vl=[ 1,3,5,7,8,9 };
bool anyof = std::any_of(vl.begin(), vl.end(),isEven);
if (anyof)
cout << "at least one is even" << endl;
}
输出结果
all is odd
none is odd
at least one is even
.
(2)否定的判断式find_if_not
它的含义和 find if 是相反的,即查找不符合某个条件的元素,find if 也可以实现 find if not 的功能,只需要将判断式改为否定的判断式即可,现在新增了 find if not 之后,就不需要再写否定的判断式了,可读性也变得更好。
基本用法
#inelude <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v=[ 1,3,5,7,9,4 };
auto isEven = [](int i)(return i %2 == 0;};
auto firstEven = std::find_if(v.begin(), v,end(), isEven);
if (firstEven!=v.end())
cout << "the first even is " <<* firstEven << endl;
// 用 find_if 来查找奇数则需要重新写一个否定含义的判断式
auto isNotEven = [](int i)(return i %2 !=0;};
auto firstOdd = std::find if(v,begin(),v.end(),isNotEven);
if (firstOdd!=v.end())
cout << "the first odd is " <<* firstOdd << endl;
// 用 find_if_not 来查数则无须新定义判断式
auto odd = std::find_if_not(v,begin(), v.end(),isEven);
if (odd!=v.end())
cout << #the first odd is w <<* odd << endl;
}
输出结果
the first even is 4
the first odd is 1
the first odd is 1
(3)根据条件对容器的内容进行复制copy_if
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v=( 1,3,5,7,9,4 1;
std::vector<int> vl(v.size());
// 根据条件复制
auto it = std::copy_if(v,begin(), v.end(), vl.begin(),[](inti)(return i%2!=0;});
// 缩减 vector 到合适大小
vl.resize(std::distance(vl.begin(),it));
for(int i : vl)
{
cout<<i<<"";
}
cout<<endl;
}
(4)生成有序序列iota
算法库新增了 iota 算法,用来方便地生成有序序列。比如,需要一个定长数组,这个数组中的元素都是在某一个数值的基础之上递增的,用 iota 就可以很方便地生成这个数组了。
基本用法
#include <numeric>
#include <array>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector<int> v(4) ;
// 循环遍历赋值来初始化数组
// for(int i=l; i<=4; i++)
//{
// v.push back(i);
//}
// 直接通过 iota初始化数组,更简洁
std::iota(v.begin(), v.end(),1);
for(auto n: v)
{
cout << n <<;
}
cout << endl;
std::array<int, 4> array;
std::iota(array.begin(), array.end(), 1);
for(auto n: array) {
cout << n <<:
}
std::cout << end1;
}
输出结果如下:
1234
1234
可以看到使用 iota 比遍历赋值来初始化数组更简洁。需要注意的是,iota 初始化的序列需要指定大小,如果上述代码中的“vector v(4);”没有指定初始化大小为 4,则输出为空。
.
(5)获取最大值和最小值的算法 minmax_element
算法库还新增了一个同时获取最大值和最小值的算法 minmax element,这样在想获取最大值和最小值的时候就不用分别调用 max element 和 max element 算法了,用起来会更方便,minmax element会将最小值和最大值的迭代器放到一个pair 中返回。
minmax_elemen的基本用法
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
// your code goes here
vector<int> v=(12,5,7,9,4 ];
auto result = minmax element(v.begin(), v.end());
cout<<*result.first<<" "<<*result.second<<endl;
return 0;
}
输出结果
1 9
(6)排序及判断算法is_sort 、is_sort_until
算法库新增了 issorted 和 is sorted until 算法
1、is_sort 用来判断某个序列是否是排好序的
2、is_sort_until 则用来返回序列中前面已经排好序的部分序列。
基本用法
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v={1,2,5,7,9,4 };
auto pos = is_sorted_until(v.begin(),v.end());
for(auto it=vbegin(); it!=pos; ++it)
{
cout<<*it<< “ ”;
}
cout<<end1;
bool is sort = is_sorted(v.begin(),v.end());
cout<< is sort<<endl;
return 0;
}
输出结果
1 2 5 7 9
0
7、总结
c++优势是其他语言无法比拟的,几乎完美的代码体系,超高的运行效率,其他语言在这些方面就和c++差远了。
c++一方面希望引入面向对象所带来的软件架构方面的种种好处,另一方面又不愿放弃C对于硬件层面的深入控制.
因此,C++既可以是一个底层语言,也可以是一个上层语言,但是兼容下来后编码坑就很多
.
二、C++自带的的数据结构(stl数据接结构进阶的基础)
0.NULL和nullptr数据类型
在C++中,NULL和nullptr不过也是0罢了,但是在使用的时候,建议你用nullptr而不是NULL,其实nullptr是C++11版本中新加入的,它的出现是为了解决NULL表示空指针在C++中具有二义性的问题
https://blog.csdn.net/qq_18108083/article/details/84346655
.
C++11 之前都是用 0 来表示空指针,但由于 0 可以被隐式类型转换为整型,这就会存在一些问题。关键字 nullptr 是 std::nullptr_t 类型的值,用来指代空指针常量。nullptr 和任何指针类型以及类成员指针类型的空值之间可以发生隐式类型转换,同样也可以隐式转换为 bool 型(取值为false),但是不存在到整型的隐式转换。
int* p1 = NULL;
// 或
int* p2 = nullptr;
在使用 nullptr_t 与 nullptr 时,注意以下几点:
1、可以使用 nullptr_t 定义空指针,但所有定义为 nullptr_t 类型的对象行为上是完全一致的。
2、nullptr_t 类型对象可以隐式转换为任意一个指针类型。
3、nullptr_t 类型对象不能转换为非指针类型,即使使用reinterpret_cast进行强制类型转换也不行。
4、nullptr_t 类型对象不能用于算术运算表达式。
5、nullptr_t 类型对象可以用于关系运算表达式,但仅能与 nullptr_t 类型或指针类型对象进行比较,当且仅当关系运算符为==、>=、<=时,如果相等则返回 true。
一般来说,用nullptr取代所有的空指针检查及指针初始化
1.布尔型bool
布尔型bool不是true就是false
.
2.整型int(int_16、int_32、uint_16、uint_32…)
定义变量
1、用数据结构定义变量,如int a\float a \double a\char a
2、用类定义变量,如,类名 a;[app a;]
【防盗标记--盒子君hzj】
<hr style=" border:solid; width:100px; height:1px;" color=#000000 size=1">
3.浮点型float/double
4.字符型char
5.字符串型string
原始的字面量R
作用
原始字面量可以直接表示字符串的实际含义,因为有些字符串带有一些特殊字符。
.
用法
R“xxx(raw string)xxx”
注意:
1、中原始字符串必须用括号 ( )括起来。
2、括号的前后可以加其他字符串,所加的字符串是会被忽略的,而且加的字符串必须在括号两边同时出现。
#include <string>
#include <iostream>
using namespace std;
int main()
{
//error test 没有出现在反括号后面
string str = R"test(D; AlB test .text)";
// error,反括号后面的字符和括号前面的字符串不匹配
string strl= R"test(D: A B test.text)testaa";
//将输出 D:\A\B\test.text,括号前后的字符串被忽略
string str2 = R"test(D: A B test.text)test";
cout<<str2<<endl;
return 0;
}
.
例子
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str = "D:\A\B\test.text";
cout<<str<<endl;
string str1 = "D:\\A\\B\\test.text";
cout<<str1<<end1;
string str2 = R"(D:\A\B\test.text)";
cout<<str2<<endl;return 0;
}
输出结果如下:
D:AB test .text
D:\A\B\test.text
D:\A\B\test.text
可以看到通过原始字符串字面量 R可以直接得到其原始意义的字符串.
6.数组array
1、功能:可以把许多同类型的值存储在同一变量名下
数据类型声明:数组仍然要被声明为某一特定的类型:int \float\double\char等等
2、定义方法:type name[x]
3、注意:不同类型的值不能放在同一数组上
4、字符串储存类型:在C语言中,字符串其实是储存在一个字符数组里的;在C++语言中,不必这么做了,C++提供了std::string这个类
getline(std::cin>>str),直接输入一行字符串存储在str中
【防盗标记–盒子君hzj】
5、实质:计算机是把数组以一组连续的内存块保存的,如:int array[3]={1,2,3};
这说明数组是拥有很多个地址的,而且每个地址都对应这一个元素,同一数组拥有一样的变量名(都是array)
.
7.向量vector【stl库常用】
vector是c++的向量数据类型,是数组的拓展,元素几乎什么都行
补全的时候,vector的数据类型都回出来的,怎么用看自己理解了或者百度
(0)初始化赋值
eigen::vector3d a (0,0,0)
(1)赋值元素操作
vector数据类型的的赋值不能用等号,要用pull back,vector数据类型的相互赋值要用assign()
(2)增加元素操作
push_back()与emplace_back()函数,作用都是在容器后面加一个元素,实现不一样
(3)删除元素操作
(4)取元素操作
.at()
......
9.结构体struct
结构体structure(本质是面向对象,对象的基础)
。
1、背景
C和C++的程序完全可以根据具体情况自定义一些新的数据类型,
并创建新的数据类型变量,这个为对象的创建打下了基础
.
2、结构体使用
结构体是一种有程序员定义的,由多种变量类型组合而成的数据类型【组合】
(1)定义语法:
//方法一:
struct name
{
type1 varname1;
type2 varname2;
.....
};
//方法二:
typedef struct event_producer {
uint8_t a;
uint8_t b;
uint8_t c;
} event_producer_t;
(2)调用赋值语法:
(1)调用赋值语法方法一:用“.”对结构成员进行赋值及调用
name hzj; //创建一个name结构类型的hzj
hzj.varname1=1; //成员进行赋值
hzj.varname2=2;
【防盗标记--盒子君hzj】
(2)赋值语法方法二:
name hzj={1,2};
注意:定义是单独的,赋值如果是顺序的话可以和在一起写,不然就要分开写
(3)结构体嵌套定义的区别
1、结构体嵌套但是分开定义,每个结构体都可以被外部调用
struct Point {
float x;
float y;
};
struct Obstacle {
int label;
int num;
Point points[1000];
};
struct Obstacles {
bool is_heart_beat;
int num;
Obstacle obstacles[100];
};
2、结构体嵌套但是不分开定义,子结构体只可以被父结构体调用,作用范围不一样
struct Obstacles
{
bool is_heart_beat;
int num;
struct Obstacle
{
uchar label;
int num;
struct Point
{
float x;
float y;
};
Point points[1000];
};
Obstacle obstacles[100];
};
10.类class和对象
类是一个模板,用于定义对象的,方法别称(函数|动词),属性别称(变量|名词)
0、使用类的一个原则
在设计、定义、使用一个类的时候,应该让每个组成部分简单到不嫩挂在简单是最好的,越简单越灵活
1、类和结构体的关系
(1)使用上:类似于结构体和定义的关系,先定义结构体再进行结构体的使用,
类似的,先定义一个类,再对类进行使用
(2)功能上:结构体只能进行变量数据类型(属性)的组合,
但是类不但可以进行变量数据类型的组合,还可以对功能相关的函数(方法)进行组合
【防盗标记–盒子君hzj】
(3)实际上,类是结构体慢慢进化而来的,更具有灵活性,再类中通常把变量成为属性,
把函数称为方法。
2、类和对象的关系
类仅仅是对象的一个雏形模板(必须内容干干净净的),经过过个类的组合完成对对象的描述,
类决定将一个对象打造成拥有什么功能,属性
11.联合union
1、联合定义
联合与结构体有很多相似的地方,也可以容纳多个不同类型的值,
但是联合每次只能储存这些值的某一个,即存放一个值会把上一个值覆盖掉,
用于密码设置等(结构体可以定义多个密码,但是联合只能定义一个)
【防盗标记--盒子君hzj】
C++中结构体和联合体的区别
结构体和联合体都是由多个不同的数据类型成员组成,但在任何同一时刻, 联合体中只存放了一个被选中的成员(所有成员共用一块地址空间), 结构体的所有成员都存在(不同成员的存放地址不同)
2、联合定义语法
union mima
{
int birthday;
char user;
int &c;
};
3、创建联合类型变量语法一般要
mima mima_1;
4、联合类型赋值语法
mima_1.birthday=19961220;【把19961220存入birthday变量中】
mima_1.user="hzj" 【这时候把hzj存入user的时候会把原来的birthday变量覆盖,做到一改全改】
12.枚举eunm
1、枚举存在的意义
枚举类型用于创建一个可取值的列表,取值也只能在这个列表里面,
否则会出错,编译器会把枚举的元素按照0~N进行顺序排列,
枚举其实是方便给人看的,实质内容也是0~N(功能比数组少一点,但是安全性也会高一点)
.
字符串都应以枚举或常量的形式定义。
在工程代码当中,只要和数据打交道,基本上就离不开枚举类型——这是因为单纯的字符串类型在一份合格的工程代码中是不应该出现的,所有的字符串都应以枚举或常量的形式定义。当输入不用枚举直接使用字符串就要考虑一些编程规范了
// Image.h
// 定义
class Image{
private:
String imgType;
int resolution;
public:
Image();
Image(String imgType, int resolution);
/**
* 其他成员已省略...
**/
};
// Process.cpp
Image tmpImage = new Image("jpg", 1920 * 1080);
上边调用是危险的,准确的来说问题出现在Image类的定义处,没有对两个成员的初始化作强限制。例如第一个参数调用者可能将参数传为"JPG",就意思表达来说是准确的,但是会给代码带来极大的不确定性;后者也可被传入诸如1080 * 1920之类的不符合要求的值,即使在备注上加上说明,也不能保证这是一个良好的设计。
以上所有的传参都应被常量或者枚举所替换,如对于图片的类型,我们可以设计一个枚举,从而存放可能需要的类型,而在类中成员,我们将其定义为枚举类型。
enum ImageType{
JPG = 100,
PNG = 200,
TIFF = 300,
SVG = 400
};
enum ImageResolution{
HIGH = 1920 * 1080,
HIGH_2K = 2560 * 1440,
HIGH_4K = 4096 * 2160
};
class Image{
private:
ImageType imgType;
ImageResolution resolution;
public:
Image();
Image(String imgType, ImageResolution resolution);
/**
* 其他成员已省略...
**/
};
.
2、枚举的用法
(1)创建枚举类型
enum weekdays
{
monday,
tuesday,
wednesday,
thursday,
friday
};
enum BumperTriggerType {
kBumperNone = 0,
kVirtualBumperMiddle,
kVirtualBumperFrontRight,
kVirtualBumperFrontLeft,
kBumperSideLeft,
kBumperFrontLeft,
kBumperMiddle,
kBumperFrontRight,
kBumperSideRight
};
typedef enum { kCoverJumpPoint = 0, kVisionNav } GoOnLifeType;
(2)创建枚举变量
weekdays today
【防盗标记--盒子君hzj】
(3)枚举变量赋值
today monday
.
3、C++ 98弱枚举的不足
C++ 98的枚举类型很弱
1、在C++98枚举(弱枚举)中,枚举类型是不限定作用域的(unscoped enumeration),枚举中的成员可不加命名空间限定符随意使用,但是不限定作用域的做法总是充满危险的,因为在全局中有可能存在命名相同的枚举。若真的存在,很可能在不知觉中被调用者混淆——更让人难过的是,调用者可能并没有料到如此。
弱枚举的写法允许你这样写
Image tmpImage = new Image(ImageType::JPG, ImageResolution::HIGH_2K);
Image tmpImage = new Image(JPG, HIGH_K);
我们无法保证在当前命名空间是否不存在与ImageResolution相对应的CameraResolution枚举类型,其同样包含有成员HIGH, HIGH_2K, HIGH_4K中的一个或多个,若真的包含,很可能在不知觉中被调用者混淆——更让人难过的是,调用者可能并没有料到如此。
.
.
2、弱枚举总是默认可以被隐式地转化为int类型,可以进行对整形和浮点型的隐式转换,这很容易造成滥用,在不知不觉中就进行了跨作用域的类型转换。
说到隐式转换,这就不得不让人提到另一个让人心塞的问题。对于int类型所能表达的最大范围是2147483647,如果我们在显示得给枚举成员赋值时超出这个值呢?如:
enum annoyType{
BIG_INTEGER = 2147483648; // 这里会发生什么,会报错吗?
}
很遗憾,不会报错,而且什么事都不会发生。
.
.
3、弱枚举类型必须定义在头文件中——编译依赖由此产生。
C++是强类型语言,规定在使用任何类型之前,需要看到这个类型的声明,并且可以根据此声明推断出该类型所占内存的大小。否则无法通过编译。由于C++98枚举类型的大小必须在看到它的定义后才能知道,因此无法实现前置声明。
因此,弱枚举类型必须定义在头文件中——编译依赖由此产生。
假设有两个文件都包含了business.h一个是business.cpp用来实现接口,另一个client.cpp用来使用接口。如果修改了LogLevel的定义,如增加一个成员等级为Info,就需要将business.cpp和client.cpp都重新编译,如果能实现前置声明,就可以将LogLevel的定义放在business.cpp中,当LogLevel的定义改变时,只需重新编译business.cpp即可,提高编译效率。
.
.
4、C++ 11强枚举的特性
强枚举是如何在弱枚举上进行改进?定义强枚举需要在enum关键字后面加上class或者struct关键字。
1、使用限定了作用域,避免歧义
enum color {red, yellow, green}; //不限定作用域的枚举类型
enum stoplight {red, yellow, green};//错误:重复定义了枚举成员
enum class pepers {red, yellow, green}; //正确:枚举成员被隐藏了
color eyes = green; //正确
peppers p = green; //错误:pepeers的枚举成员不在有效作用域中,
//green对应的是color::green,但显然类型错误。
peppers p2 = peppers::red; //正确使用peppers的red
.
.
2、不支持隐式转换为其他类型,如果要转换类型,必须显示地使用强制类型转换static_cast。
int i = color::red; //正确,不限定作用域的枚举类型的枚举成员隐式地转换成int
int j = peppers::red; //错误,限定作用域枚举类型不会进行隐式转换。
int x = static_cast<int>(peppers::red); //正确
C++是不鼓励做类型转换的,太危险,如果需要进行枚举成员之间的某种逻辑上的大小比较,可以直接规定清楚每个枚举成员的值,再进行直接比较。
enum class LogLevel{
Fatal = 500,
Error = 400,
Warning = 300,
Debug = 200,
Info = 100
};
// This is OK
LogLevel logLevel1 = LogLevel::Fatal;
LogLevel logLevel2 = LogLevel::Info;
if(loglevel1 > logLevel2){
// Do something...
}
.
.
3、限定基类型
enum intValues : unsigned long long {
charTyp = 255, shortTyp = 65535, intType = 2147483647,
longTyp = 4294967295UL,
long_longTyp = 18446744073709551615ULL
};
如果我们没指定枚举的潜在类型,在强枚举中成员类型默认为int,而对弱枚举而言,枚举成员不存在默认类型,只知道成员的潜在类型足够大,肯定能够容纳枚举值。
但是:一旦定义了某个枚举成员的基类型(包括强枚举的隐式限定),一旦某个枚举成员的值超出了该类型所能容纳的范围,则会引发程序错误。
.
.
4、允许枚举前置声明
//前置声明,并隐式声明基类型为int
enum class LogLevel;
class Logger{
// Some members
private:
void logging(LogLevel level, String message);
};
// business.cpp
#include "business.h"
//枚举的实现
enum class LogLevel{
// Implementation
};
// client.cpp
#include "business.h"
//调用
void someFunc(LogLevel level){
// Invokation
}
5、注意
用constexpr取代所有的宏变量及const变量,const仅用于函数参数修饰。
.
14.类
(1)封装机制–使用类构造自己的数据类型和相关方法
“class”这个关键字还用于定义模板参数,就像“typename”。但关键字“struct”不用于定义模板参数。
实现一个新的数据类型我常用结构体这种方式,组合已有的数据类型
为什么要对类和结构体进行初始化
定义结构体和类的对象必须进行初始化。因为定义结构体和类的对象很有可能取它的地址传入函数中,指针传址导致崩溃。
.
类与结构体进行初始化的区别
在定义类的时候就用构造函数进行了全部成员的初始化了,初始化类的对象是构造函数干的活
结构体不支持整体赋值,要一个一个成员进行赋值,结构体嵌套的复杂的结构体的方式比较难进行初始化赋值,这时候最好把结构体换成类来实现初始化
能用类实现的不要用结构体–结构体赋值麻烦
.
(2)继承机制
类里面定义结构体,但是类里面不能定义类,只能通过继承等方式
.
(3) 权限机制
类最本质的一个区别就是默认的访问控制: struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的。
.
(4)C++空类默认有哪些成员函数及其使用
记忆方法:
对象不存在,且没用别的对象来初始化,就是调用了默认构造函数;
对象不存在,且用别的对象来初始化,就是拷贝构造函数。
对象存在,用别的对象来给它赋值,就是赋值构造函数。
概念介绍
https://www.runoob.com/cplusplus/cpp-copy-constructor.html
https://blog.csdn.net/c243311364/article/details/81216212
0)理解深拷贝、浅拷贝的区别
A、浅拷贝,深拷贝、移动拷贝本质的区别
(1)浅拷贝只拷贝指针,不新开辟内存。使用指针和引用可以实现
(2)深拷贝会另外开辟一块内存,内容和拷贝的对象一样。使用赋值实现
(3)移动拷贝是另开一块内存转存资源,并把原来的资源释放掉
深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据,从而也就解决了指针悬挂的问题
.
B、浅拷贝,深拷贝的优劣势
浅拷贝和深拷贝都是通过拷贝对象的成员变量来创建新的对象。
(1)浅拷贝会直接复制对象的指针或引用等成员变量的值,不会开辟新的内存,但会导致多个对象共享同一份资源,容易出现资源释放重复等问题
(2)深拷贝会复制对象指针或引用等成员变量所指向的内存空间,从而避免了多个对象共享同一份资源的问题。但是,深拷贝的成本较高,需要分配新的内存空间并复制数据,可能会影响程序的性能。
.
C、浅拷贝,深拷贝的示例
1、一般的赋值操作是深度拷贝
//深度拷贝
int a = 5;
int b = a;
2、简单的指针、引用是浅拷贝
//浅拷贝
int a = 8;
int *p;
p = &a;
char* str1 = "HelloWorld";
char* str2 = str1;
注意:函数传指针、函数传引用都是浅拷贝!函数对于非指针变量是深拷贝!
.
3、把浅拷贝改为深度拷贝
//深度拷贝
int a = 8;
int *p = new int;
*p = a;
char* str1 = "HelloWorld";
int len = strlen(str1);
char *str2 = new char[len];
memcpy(str2, str1, len);
.
1)无参构造函数TestCls()【不用拷贝】
当类中没有定义任何构造函数时,编译器会默认提供一个无参构造函数且其函数体为空;
class TestCls{
public:
int a;
int *p;
public:
TestCls() //无参构造函数
{
std::cout<<"TestCls()"<<std::endl;
p = new int;
}
~TestCls() //析构函数
{
delete p;
std::cout<<"~TestCls()"<<std::endl;
}
};
int main(void)
{
TestCls c1;
//...
return 0;
}
类的构造函数–初始化操作
在构造函数用初始化列表进行变量的初始化,不要在函数体内进行变量的赋值操作
一般来说,类的构造函数一般的传入形参为空,甚至是函数体也为空(虚类)。但是有一些情况下类的构造函数是有传入形参的,这时候在实例化或者继承一个类的时候必须也要同时传入参数,可以使用函数列表的形式。也可以使用函数模板和类模板的方法。
类的构造函数带有形参,但是初始化的时候没有传入形参,原来是有用类模板自动匹配的
C++类的构造函数后面加“:”是初始化列表赋值
https://blog.csdn.net/zhanghenan123/article/details/86468317
构造函数
1、没有特殊情况一般设置构造函数的形参为空
2、若父类的构造函数还有形参,子类的构造函数要对父类的构造函数传入形参,可以使用初始化列表的方法
CExample() : a(0), b(8.8)
{}
CExample()
{
a = 0;
b = 8.8;
}
//这种方法很好,在定义函数的时候就引用了ControlFSMData结构体、实例化了FSM_State类的构造函数,:之后是操作
FSM_State_Leave_Dock<T>::FSM_State_Leave_Dock(ControlFSMData<T> *_controlFSMData)
: FSM_State<T>(_controlFSMData, FSM_StateName::PASSIVE, "PASSIVE")
https://blog.csdn.net/sinat_31608641/article/details/110692677
最终解决各种数据结构和形参的问题可以统一使用函数模板和类模板
C++显式的定义复制构造函数
https://blog.csdn.net/wz469167/article/details/79100298
https://blog.csdn.net/xikangsoon/article/details/103873337
.
2)默认拷贝构造函数cls(const cls& c)【浅拷贝】
拷贝构造函数的作用:使用之前创建的对象来初始化新创建的对象,当类的数据成员中没有指针时,浅拷贝是可行的。
举例:若a, b对象的成员是指针
以类 String 的两个对象 a, b 为例,假设 a.m_data 的内容为“hello”,b.m_data 的内容为“world”。现将 a 赋给b,缺省赋值函数的“位拷贝”意味着执行 b.m_data = a.m_data。这将造成三个错误:一是 b.m_data 原有的内存没被释放,造成内存泄露;二是 b.m_data 和 a.m_data 指向同一块内存,a 或 b 任何一方变动都会影响另一方;三是在对象被析构时,m_data 被释放了两次。
CControlBase::CControlBase()//无参构造函数
: motion_rotate_(new CMotionRotate),
// motion_followwall_right_(new CMotionFollowWallRight),
// motion_followwall_left_(new CMotionFollowWallLeft),
motion_detour_(new CMotionDetour),
motion_mp2p_(new CMotionMP2P),
motion_p2p_(new CMotionP2P),
motion_dock_ir_(new CMotionDockIR),
motion_forward_(new CMotionForward),
motion_test_(new CMotionTest),
motion_blade_stop(new CMotionBladeStop),
control_state_(CControlBase::IDLE) {
current_motion_ = NULL;
}
CControlBase(const CControlBase &){}; //默认拷贝构造函数
CControlBase &operator=(const CControlBase &){}; //默认拷贝构造函数
当类中没有定义拷贝构造函数时,编译器会默认提供一个拷贝构造函数,进行成员变量之间的拷贝
class cls
{
pubic:
//...
}
int main(void)
{
cls c1;
cls c2 = c1; //初始化类,还可以 cls c2(c1);
cls c3;
c3 = c1; //赋值类
//...
return 0;
}
如上的初始化类需要调用到cls类的默认实现的拷贝构造函数,为类赋值需要调用的是cls类的默认实现的赋值操作符重载函数,它们都是浅度拷贝的。前者其原型为:
cls(const cls& c)
.
例一:拷贝构造函数
#include <iostream>
using namespace std;
class A{
private:
int num;
public:
A(){
cout<<"这是默认构造函数"<<endl;
}
A(const A &a){
cout<<"这是拷贝构造函数"<<endl;
}
A& operator=(const A &a){
cout<<"这是赋值重载"<<endl;
return *this;
}
};
void main(){
A a; // 调用默认构造函数
A b(a); // 调用拷贝构造函数
A c=b; // 调用拷贝构造函数
c=a; // 调用重载的赋值运算符
}
3)自定义(带有指针成员)拷贝构造函数【深拷贝】
当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址,当对象快结束时,会调用两次析构函数,而导致指针悬挂现象。所以,这时,必须采用深拷贝。
为了解决浅拷贝带来造成重复释放,程序运行崩溃的问题,我们可以自定义拷贝构造函数,自己实现深拷贝。
自定义拷贝构造主要就是把别的对象的成员变量的值赋值给自己的成员变量。或者说,直接新开辟一段内存,然后把传入的对象的成员变量的值赋值给自己。
class TestCls{
public:
TestCls()//无参构造函数
{
std::cout<<"TestCls()"<<std::endl;
p = new int;
}
TestCls(const TestCls& testCls)
{
std::cout<<"TestCls(const TestCls& testCls)"<<std::endl;
a = testCls.a;
//p = testCls.p;
p = new int;
*p = *(testCls.p); //为拷贝类的p指针分配空间,实现深度拷贝
}
~TestCls()
{
delete p;
std::cout<<"~TestCls()"<<std::endl;
}
private:
int a;
int *p;
};
int main(void)
{
TestCls t1;
TestCls t2 = t1;
return 0;
}
class A{
public:
//默认拷贝构造函数为
A(const A& a){
tmp1=a.tmp1;//深拷贝,不同对象tmp1的地址不一样
ptr=a.ptr;//浅拷贝,因为ptr为指针变量
}
A(const A& a){
tmp1=a.tmp1;//深拷贝,不同对象tmp1的地址不一样
ptr= new int;
*ptr=*(a.ptr);//深拷贝,因为他们的ptr的地址不一样了。
}
private:
int tmp1;
int *ptr;
};
例二:带有指针的深拷贝
#include <iostream>
#include <cstring>
using namespace std;
class CExample
{
private:
int _num;
char * _str;
public:
//普通构造函数
CExample(int b,char *str):_num(b){
_str=new char[b];
strcpy(_str,str);
}
//拷贝构造函数
CExample(const CExample & C){
_num=C._num;
_str=new char[_num];
if(_str!=0){
strcpy(_str,C._str);
}
}
~CExample(){
delete _str;
}
void Show(){
cout<<_num<<" "<<_str<<endl;
}
};
int main()
{
CExample A(10, "hello");
CExample B=A;
A.Show();
//A.Show();
B.Show();
return 0;
}
.
4)复制构造函数【传递】
移动构造函数通过将资源“移动”而不是复制,用于将对象的资源从一个对象“移动”到另一个对象中,复用对象中的资源(堆内存),延长其他临时对象的生命周期。可以避免浅拷贝和深拷贝可能出现的问题,并提高程序的性能。特别是当对象拥有大量数据或资源时。
移动构造函数的实现方式通常是将源对象的指针指向的资源转移到目标对象中,并将源对象的指针置为 nullptr,以避免资源的重复释放。
移动构造函数通常使用右值引用参数(&&)来接受源对象
class MyClass {
public:
// 移动构造函数
MyClass(MyClass&& other) {
// 将源对象的资源转移给目标对象
m_data = other.m_data;
m_size = other.m_size;
// 将源对象的指针置为 nullptr
other.m_data = nullptr;
other.m_size = 0;
}
private:
int* m_data; // 数据指针
int m_size; // 数据大小
};
例子二:
调用移动构造函数,会先把a对象的指针变量ptr先赋值给自己的指针变量ptr,然后把a.ptr指向空指针,这样a在析构的时候就不会把a.ptr本来指向的内容给释放了。这样自己的ptr指针还是指向那块内存。注意,指针指向的那块内存的值是通过*p=?的方式来修改的,所以修改指针指向并不是修改指针指向的内存的值,不要混淆。
A(A&& a):ptr(a.ptr){
a.ptr=nullptr;
}
另外,关于拷贝构造函数和移动构造函数,他们传入的形参都一样,怎么知道调用哪个呢?程序会判断这个形参是不是临时对象,如果是临时对象,就会调用移动构造函数。
.
5)析构函数【释放资源】
析构函数的作用–避免内存泄露
内存泄漏是指向系统申请分配内存进行使用(new),但是用完后不归还(delete),导致占用有效内存。
析构函数是用来释放delete所定义的对象中使用的指针、内存空间,打开了文件等等系统功能的,这样构造函数与对应的析构函数就可以避免内存泄露
如果是自己写析构函数的话,如果你的类里面分配了系统资源,如new了内存空间,打开了文件等,那么在你的析构函数中就必须释放相应的内存空间和关闭相关的文件;这样系统就会自动调用你的析构函数释放资源,避免内存泄漏
如果你的类里面只用到的基本类型,如int char double等,系统的默认析构函数其实什么都没有做,因为基本类型使用的是栈空间而不是堆空间
但如果你使用了其他的类如vector,string等,系统的默认析构函数就会调用这些类对象的析构函数
默认的析构函数不用显式调用,自建的析构函数要在程序末尾调用
.
(5)一个类中,类内的函数和变量可以相互调用
.
(6)一个类中,在.h类内进行声明不用加上类名
一个类中,在.h类内进行声明不用加上类名,但是函数在外面实现是记得加上类的名字,
函数格式一般是【函数类型+命名空间+类名称+函数名+参数】
引用任何的结构体和函数定义前前都要加上命名空间
.
(7)同一个类实例化不同的对象,对象是独立的
【若函数2要调用函数1,如果函数2也在类内声明了,函数2调用函数1的时候不需要用对象;
如果函数2没有在类内进行声明,函数2调用函数1的时候需要用对象;】
【函数1和函数2不在同一个类内才需要用对象去实例化】
.
(8)类的单例Instance()
instance是实例的意思,在C++上的作用是把class实例化
Instance()函数是C++用来实例化一个类的,实例化的过程中就会运行类内的构造函数、init()函数、process()函数
.
.
(9)在C++编程中,采用结构体还是类的考量原则
1、仅有变量的读取,且不需要对该变量进行保护的优采先用结构体
2、有对变量的保护,或有相关变量的方法函数实现的,优先采先用结构体。
.
三、指针pointer–操作内存的神器!
(0)指针的定义与功能
指针是专用来存放地址的特殊类型的变量,指针能完成很多其他工具没有完成的任务,如对内存的调用。
.
.
(1)指针的定义与释放
1、指针的定义
我们不能定义一个空指针!!
Node* NewCostNode = new Node();
定义指针要用上面的这种方式,定义的时候进行了内存的分配。若直接按下面来定义则是一个空指针
Node* NewCostNode;
直接定义一个指针,不给指针确定初始指向的地址就直接使用,或者传递给函数使用,会导致崩溃【取指针变量的成员会崩溃,对指针进行赋值operator也会出错,运行的时候会出错,最好装一个cppcheck软件尽早发现错误】
.
.
指针变量声明(定义)的方法
原则:C++定义指针的时候必须分配地址
1、要么取某一变量的地址(这样可以根据变量动态分配地址)
2、要么直接给定一个固定的地址
--type*pointername;【*代表指针变量】,如
方法一:
--int *p;【定义一个指针】
--int pp=123;【定义一个整形变量pp】
--p=&pp【把整形变量pp的地址赋给指针变量p里】
方法二:
--int pp=123;
--int*p=&pp;【一步到位】
方法三:
可以用malloc、new和freetros中的pvPortMalloc等,原理都是一样的
void* newPtr(uint64_t xWantedSize) {
if (xWantedSize == 0) {
return NULL;
}
void* data_ptr = pvPortMalloc(xWantedSize);
if (!data_ptr) {
MCU_LOG("Malloc %lld bytes of memory failed", xWantedSize);
return NULL;
}
memset(data_ptr, 0, xWantedSize);
return data_ptr;
}
定义传递地址给指针的异同的分析
//CurNode1是对象,这种方式当CurNode1被析构,CurNode就为空,若对象不在作用范围就很容易被自动析构
Node* CurNode =&CurNode1
//TailNode是指针,这种方式CurNode 和TailNode是等价的,操作谁另一个都会一起被操作
Node* CurNode = TailNode;
总的来说,第二种方式使用比较保险!
.
2、指针的释放
方法
p=null;
.
注意
释放指针的时候确保该指针不会在被使用,一般是在类的构造函数中定义指针并malloc一段内存给该指针,在类的析构函数中释放指针,并释放该指针指向的内存。
避免通过函数传指针的方式,在子函数中把父函数的指针释放了,导致父函数使用该指针是发生系统崩溃!
//下面这个是标准的指针完全释放模板(如果该指针的地址是手动申请的话)
if (pointer) {
vPortFree(pointer);
pointer = NULL;
}
.
.
3、注意的点
(1)使用指针进行函数传值时,记得原有的指针不能被释放,除非是新开一个空间存放新的处理数据,不然的数据都会随着最初的指针释放而释放掉!
(2)int *p1 p2 p3【这样定义仅有p1是指针变量,p2 p3都是整形变量,这样写的程序是具有极大迷惑力的,一般不同类型的变量分开写】
.
.
(2)指针和引用的区别
C++操作对象用成员符“.”,操作指针用指针操作符->
C++的引用"&“、取地址符”&"和与操作“&&”的区别
作用区别:
引用&是一般用来给函数输入参数的,取地址符&一般用来给函数输出参数的。
用法区别:
(1)引用定义:int &rf; // 声明一个int型的引用rf.
记忆:
1、和类型在一起的是引用(包括在函数的参数定义的时候,是引用,因为定义的时候带有类型),和变量在一起的是取址(一般是赋值操作)
2、引用在赋值=的左边,而取地址在赋值的右边,比如
int a=3;
int &b=a; //引用,b与a是等价的
int *p=&a; //取地址
指针和引用操作同一地址
(既可以用在函数传址,又可用在函数中作为变量)
https://zhuanlan.zhihu.com/p/139543762
.
引用&和指针变量*ptr注意的点
1、“引用&”不产生副本,而是给原变量起别名。
2、对引用&操作就是对原变量操作
3、指针变量*ptr是对同一段内存地址取出来的不同命名,不是对原地址操作
【指针是变量】指针只是一个变量,只不过这个变量存储的是一个地址;
【引用是别名】引用跟原来的变量实质上是同一个东西,只不过是原变量的一个别名而已,不占用内存空间。
引用&和取地址符&很像
指针可以为空,但引用不能为空
.
.
(3)指针操作变量
指针比引用更加灵活,但是引用更加符合理解
1、*p是指针
2、p是指针变量【“->”指针操作的对象,先定义一个指针*p,再使用指针变量进行操作p->xxx】
3、&p是变量地址【被赋值的对象】
使用指针时会频繁进行以下几个操作:定义一个指针变量、把变量地址赋值给指针、访问指针变量中可用地址的值。这些是通过使用一元运算符 * 来返回位于操作数所指定地址的变量的值。下面的实例涉及到了这些操作:
#include <iostream>
using namespace std;
int main ()
{
int var = 20; // 实际变量的声明
int *ip; // 指针变量的声明
ip = &var; // 在指针变量中存储 var 的地址
cout << "Value of var variable: ";
cout << var << endl;
// 输出在指针变量中存储的地址
cout << "Address stored in ip variable: ";
cout << ip << endl;
// 访问指针中地址的值
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}
变量寻址方法
对于一个变量,我们有两种方法对它进行寻址
方法一:通过变量名
方法二:通过地址,需要“取址”操作符--“&”,它的作用是获得变量的地址
“&”d的使用方法:
--int var=123;
--std::cout<<"var的地址:"<<&var
利用指针改变值的方法
(1)原理:指针变量可以让我们知道变量的地址,这样我们就可以通过指针访问该地址的数据(走后门)
(2)方法:解引用处理:即在指针变量前加上*【可以这么理解加*往上层走,加&往下层走】
方法一:
--int a=100;
--int*aa=&a;
--std::cout<<*aa;【输出的是100】
方法二:
--int a=100;
--std::cout<<a;【输出的也是100】
方法三:
--int a=100;
--int*aa=&a;
--*aa=1000;
--std::cout<<a;【输出的是1000】
说明a和*aa是同一个值,本质是一样的,其中a和*aa的值同时改变,aa是a的地址,C++是允许不同的指针变量同时指向一个地址的(一夫多妻制)
--int*a1=&a;
--int*a2=&a;
区别星号的用途
(1)--int*aa=&a;【这种形式是指针的定义,定义是带数据结构的】
(2)--*aa=1000;【这种形式是指针的解引用,引用不带数据结构的】
.
.
(4)指针操作数组
数组指针和指针数组的区别
https://blog.csdn.net/men_wen/article/details/52694069
数组和指针的关系
数组的数组名和下标操作符[]可以对应为指针的基地址指针和对应的指针运算++
int a[20];
int *x=a;
指针变量x指向a的首地址即a[0]的地址,a[0]和*x都代表数组的第一个元素 ,根据数组和下标操作和指针的指针运算,a[1]等价于*(x+1)......a(20)等价于*(x+20)
背景:计算机是把数组以一组连续的内存块保存的,如:int array[3]={1,2,3};
这说明数组是拥有很多个地址的,而且每个地址都对应这一个元素,同一数组拥有一样的变量名(都是array)
【防盗标记--盒子君hzj】
实际上,数组的名字就是一个指针(变量的名字也是指针),指向数组的基地址(第一个元素),故下面两句本质是一样的
--int*ptr1=&array[0];
--int*ptr2=&array;
用指针访问同一数组的不同元素方法
(1)方法:ptr++;
(2)注意:这里的指针++不是地址位置简单的++,而是以数据结构对应的地址数目++,因为不同的数据结构的地址数目是不一样的
(3)一般用法:
--int array[10]={1,2,3,4,5,6,7,8,9,10}; 【定义一个数组】
--int *array=&array 【定义一个指针,指向该数组的首地址】
--std::cout<<*array; 【输出数组的第一个元素】
--*array++;
--std::cout<<*array; 【输出数组的第二个元素】
.........
注意*array+1和*(array+1)的区别:优先级问题
.
.
(5)指针操作结构体
指针和结构体的关系
背景:指针也可以指向结构体,方法和指向其他任何变量一样(类似于数组)
步骤:
第一步:定义结构体:
struct name
{
type1 varname1;
type2 varname2;
.....
};
第二步:赋值语法
name hzj={1,2};
【防盗标记--盒子君hzj】
第三步:创建指向该结构变量的指针
name *pzhj=&hzj;
注意:指针的类型必须和结构体变量的类型是一样的,都是name
第四步:结构体变量指针的调用
方法一:返回层次操作:通过"."解引用符
(*pzhj).varname1=100; 【这里改变了hzj这个结构体内的varname1成员的值】
*pzhj本质上和hzj一样,都是结构体变量;pzhj是hzj的的基地址,因为hzj结构体变量的成员数据结构不一样,不可以使用像数组变量"++"的形式
方法二:指针层面操作:通过"->"解引用符
phzj->varname1=100; 【这里是直接操作phzj指针】
.
.
(6)指针操作函数
指针和函数参数调用的关系
--int a=100;
--int b=1000;
//子函数
void add(int *one,int *two)
{
int sum;
sum=*one+*two;
std::cout<<sum;
}
//调用子函数
add(a,b);
//分析:这时候*one和a的本质是一样的,都是变量,one是a的地址,而且调用这个函数的时候只能传变量,不能传值
指针函数
1、功能:动态内存可以让函数返回一个地址,以前函数一般都是仅能返回一个标量值(整型浮点型指针等等)
基本思路:
2、使用方法:函数返回一个地址(该函数是指针函数,如,int *funtion(int a);)
在函数里调用new语句为某个对象或者某个基本数据类型分配一块内存,
再把该块内存的地址返回给主程序的代码,主程序的代码使用完这个地址后使用delete对该块内存进行释放
3、注意:任何一个指针函数都不应该把函数内部的指针(局部变量的指针)作为返回值,
因为当函数执行完毕后,局部变量自动被清空,返回的地址是一个乱码。
返回的地址应该是用new动态分配的内存基地址
【防盗标记--盒子君hzj】
注意
若函数的返回的是指针,则不能被const(要么一const就要const到底,不然会数据类型不匹配)–这种情况要保证被const的对象不能被赋值(包括传入函数被赋值的情况)
.
(7)指针操作对象
操作类的对象
.
(8)this指针
this指针的介绍
this指针是当前对象指针地址的意思,一般用在类内成员中
this指针是类的自动生成、自动隐藏的 私有成员,存在于类的非静态成员函数中,指向被调用函数对象的所在地址
.
使用this指针的原则
如果代码不存在二义性隐患,就不必使用this指针
.
C++中的this指针应用场景–子类调用父类的成员(这种场景存在二义性)
//this一般用于在子类调用父类的成员
template <typename T>
FSM_State_Leave_Dock<T>::FSM_State_Leave_Dock(ControlFSMData<T> *_controlFSMData)
: FSM_State<T>(_controlFSMData, FSM_StateName::PASSIVE, "PASSIVE")
{
//这个this指针就是FSM_State实例化对象的指针
this->checkSafeOrientation = false; //关闭设置预控制安全检查
this->checkPDesFoot = false; //关闭控制后安全检查
this->checkForceFeedForward = false;
}
//this指针可以用于本类对象的任意一个成员
#include <iostream>
using namespace std;
class person {
public:
person(const std::string name = "", int age = 0) :
name_(name), age_(age) {
std::cout << "Init a person!" << std::endl;
}
~person() {
std::cout << "Destory a person!" << std::endl;
}
const std::string& getname() const {
return this->name_;
}
int getage() const {
return this->age_;
}
private:
const std::string name_;
int age_;
};
int main() {
person p;
return 0;
}
https://www.runoob.com/cplusplus/cpp-this-pointer.html
.
.
(9)二维指针–指向指针变量数据的指针
指针的指针
**p
理解复杂,能不用不要用,可读性较差
https://blog.csdn.net/weixin_43283397/article/details/103915135
.
.
(10)智能指针
当类中有指针成员时,一般有两种方式来管理指针成员:一是采用值型的方式管理,每个类对象都保留一份指针指向的对象的拷贝;另一种更优雅的方式是使用智能指针,从而实现指针指向的对象的共享。
智能指针其实就是解决指针和内存的关系–更加智能的管理好指针创建释放内存,解决C++内存泄漏的问题,最有效的方法就是使用智能指针。share_ptr、unique_ptr、weak_ptr都叫智能指针。
1、创建与释放内存【基础特性】
2、共享
3、独占
4、没有所有权限
共享和独占是两种极端的特性
(0)auto_ptr自动指针
从c++11开始, auto_ptr已经被标记为弃用, 常见的替代品为shared_ptr。shared_ptr的不同之处在于引用计数, 在复制(或赋值)时不会像auto_ptr那样直接转移所有权。 两者都是模板类,却可以像指针一样去使用。只是在指针上面的一层封装。
.
1)auto_ptr介绍
auto_ptr实际也是一种类, 拥有自己的析构函数, 生命周期结束时能自动释放资源,正因为能自动释放资源, 特别适合在单个函数内代替new/delete的调用, 不用自己调用delete,也不用担心意外退出造成内存的泄漏。
2)atuo_ptr的缺陷
1、auto_ptr不能共享所有权,即不要让两个auto_ptr指向同一个对象(因为它采用的是转移语义的拷贝,原指针会变为NULL)。没有共享属性
2、auto_ptr不能管理对象数组(因为它内部的析构函数调用的是delete而不是delete[])
3、auto_ptr不能作为容器对象,STL容器中的元素经常要支持拷贝,赋值等操作,在这过程中
4、auto_ptr会传递所有权。
.
.
(1)unique_ptr独占指针
(1)unique_ptr独占指针为啥叫做独占:因为它不允许其他的智能指针共享器内部的指针,同时,不允许通过赋值的方式将一个unique_ptr赋值给另外的unique_ptr。不可以复制指针但是可以通过函数返回的方式给到其他unique_ptr
1)unique_ptr独占指针特性
1、unique_ptr指针对资源的独占特性:不允许其他的智能指针共享器内部的指针。同时,不允许通过赋值的方式将一个unique_ptr赋值给另外的unique_ptr。
这样一些全局的指针都可以用unique_ptr代替
unique ptr<T> myPtr(new T);
unique ptr<T> myOtherPtr = myPtr;// 错误,不能复制
2、unique_ptr指针可以移动不影响其独占特性:可以通过函数返回的方式给到其他unique_ptr,可以通过std::move 来转移到其他的 unique_ptr
unique ptr<T> myPtr(new T); // Okay
unique ptr<T> myotherptr = std::move (myPtr); // Okay
unique ptr<T> ptr = myPtr; // 错误,只能移动,不可复制
3、unique_ptr指针可以指向一个数组的任意元素
std::unique ptr<int []> ptr(new int[10]);
ptr[9] = 9; //设置最后一个元素值为 9
4、当指针超出作用域,内存自动释放
.
2)unique_ptr的创建
//直接创建
unique ptr<T> myPtr(new T);
封装创建make_unique
C++11没有提供 make_unique 方法,在 C++14 中会提供和 make_shared 类似的 make_unique 来创建unique_ptr。其实要实现一个 make_unique 方法是比较简单的
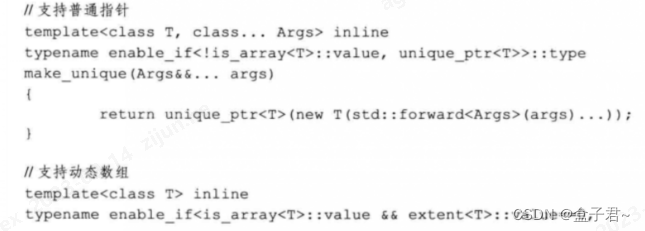

实现思路很简单,如果不是数组,则直接创建 unique_ptr。如果是数组,先判断是否为定长数组,若为定长数组则编译不通过(因为不能这样调用 make unique<T[10]>(10),而应该这样 make_unique(10));若为非定长数组,则获取数组中的元素类型,再根据入参 size创建动态数组的 unique ptr。
.
2)unique_ptr的使用场景
希望只有-个智能指针管理资源或者管理数组就用 unique_ptr。因此在做函数传参或返回值的时候一定要注意其所有权
(1)当作为值进入函数传参时(Passing by value),需要用std::move来转移所有权,C++14中如果传参直接为std::make_unique语句,自动转换为move操作
void do_with_cat_pass_value(std::unique_ptr<Cat> c)
{
c->cat_info();
}
int main(int argc, char *argv[])
{
std::unique_ptr<Cat> c1 = make_unique<Cat>("ff")
do_with_cat_pass_value(std::move(c1));
c1->cat_info();//这样会导致崩溃
return 0;
}
move走了之后再通过原指针调用其指向类的成员函数时会崩溃,原因是所有权已经转让给了函数,并且在退出这个函数的时候已经自动析构了
(2)当作为引用进入函数传参时(Passing by reference),如果设置参数为const则不能改变指向,reset()方法为智能指针清空方法
//不设置const
void do_with_cat_pass_ref(std::unique_ptr<Cat> &c)
{
c->set_cat_name("oo");c->cat_info();
c.reset();
}
std::unique_ptr<Cat> c2 = make unique<Cat>("f2");
do_with_cat_pass_ref(c2);
其中,reset()方法为智能指针清空方法,此时c2为空,后续再调用其指向类的成员函数会崩溃。因此一般作为引用进入函数传参的时候要加const,不允许修改指向,像reset方法在函数内是不可用了
void do with cat pass ref(const std::unique_ptr<Cat> &c)
{
c->set_cat_name("oo");
c->cat_info();
// c.reset();
}
do_with_cat_pass_ref(c2);
std::unique_ptr<Cat> c2 = make unique<Cat>("f2");
(推荐使用)当作为引用进入函数传参时,如果设置参数为const,不可以改变指向。这时智能指针只有在其生成地方所在的作用域退出后才会析构。还要注意的是这个const的作用不是禁止函数修改指针指向类的成员变量,只是禁止指针指向改变
(3)当作为函数返回时(return by value),他指向一个局部对象(local object),可以用作链式函数
std::unique_ptr<Cat> get unique_ptr()
{
std::unique_ptr<Cat> p_dog = std::make_unique<Cat>("Local cat");
return p_dog;
}
get_unique_ptr()->cat info();
.
2)unique_ptr的使用注意点
1)不建议原始指针和智能指针混用,导致unique_ptr失去独占特性
Cat *c_p2 = new Cat("yz");
std::unique_ptr<Cat> u_c_p2(c_p2};
c_p2->cat_info();
u_c_p2->cat_info();
c_p2->set_cat_name("ok");
u_c_p2->cat_info();
return 0;
输出
cat info name : yz
cat info name : yz
cat info name :ok
智能指针指向原始指针时,可见当原始指针变更指向内容,智能指针内容随之变化,这已经不符合独占unique的定义了
.
(2)share_ptr共享指针
1)share_ptr的特性
1、资源共享特性:每一个share_ptr拷贝都是指向同一个内存地址,因此,同一个指针资源,可以被多个 shared_ptr 对象所拥有,该类型指针可以copy操作
2、自动创建与释放内存管理特性:shared_ptr 使用引用计数的方式来实现对指针资源的管理,初始化一次就计数加一,超过作用域就计数减一,当计数值未0时自动释放指针指向的内存。
这样一些临时的指针都可以用share_ptr代替
共享指针的计数实现(内部实现了,我问理解和尽管用就行)
构造函数中计数初始化为1;
拷贝构造函数中计数值加1;
赋值运算符中,左边的对象引用计数减一,右边的对象引用计数加一;
析构函数中引用计数减一;
在赋值运算符和析构函数中,如果减一后为0,则调用delete释放对象
3、可以通过api获取计数器上当前的数字use_count()
2)share_ptr的创建
1)方法一:通过构造函数进行创建
std::shared ptr<int> p(new int (1));
if (ptr) {
cout << "ptr is not null";
}
注意
std::shared ptr<int> p = new int(1);//编译报错,不允许直接赋值
智能指针的用法和普通指针的用法类似,只不过不需要自己管理分配的内存shared ptr 不能通过直接将原始指针赋值来初始化,需要通过构造函数和辅助方法来初始化。
2)方法二:通过复制指针进行创建
std::shared ptr<int> p(new int (1));
std::shared ptr<int> p2 = p;
if (ptr) {
cout << "ptr is not null";
}
注意:
(1)当通过其中任意一个指针改变其所指向的值,通过其他指针获取到的值都将随之改变;当对copy后的新指针赋为空指针时,不影响原有指针或其他指针的count;当对copy后的原有指针赋为空指针时,也不影响新指针或其他指针的count.
(2)不管copy了多少次,当离开作用域的时候,最终都只会析构一次。因为析构是按照内存来的,内存里的数据永远只有一套,不管有多少个指针指向它。并且析构是在所有指针count都为0的时候才执行析构,当没有shared_ptr指向它的时候便会销毁。
(3)shared_ptr可以进行copy操作,因此不必进行move操作可以直接传值.
3)方法三:通过reset函数进行创建
std::shared ptr<int> ptr;
ptr.reset(new int(1))
if (ptr) {
cout << "ptr is not null";
}
4)方法四:【推荐】通过make_share封装进行创建
std::shared_ptr<int> i_p_1 = make shared<int>(10);
// std::shared ptr<int> i_p_1 = make shared<int>{new int(10)};
cout <<"value :<<*i_p_1 << endl;
cout << "use count :<<i p 1.use count() << endl;
.
3)share_ptr的原始指针获取
当需要获取原始指针时,可以通过 get 方法来返回原始指针
std::shared ptr<int> ptr(new int(1));
int* p = ptr.get();
.
4)share_ptr的释放
智能指针初始化,可以指定该指针释放(前提是该智能指针的计数器为0),代码如下:
void DeleteIntPtr(int* p)
{
delete p;
}
std::shared ptr<int> p(newint, DeleteIntPtr);
当p的引用计数为0时,自动调用删除器 DletelntPtr 来释放对象的内存.一般来说,都智能指针了就不必手动释放该指针了
.
5)share_ptr的使用场景
希望多个智能指针管理同一个资源就用 shared_ptr
.
6)share_ptr的使用注意的问题
1) 不要用一个原始指针初始化多个 shared ptr【???】
int* ptr = new int;
shared ptr<int> pl(ptr);
shared ptr<int> p2(ptr); // logic error
.
2)不要在函数实参中创建 shared ptr
function (shared ptr<int>(new int), g( ) ); // 有缺陷
因为 C++ 的函数参数的计算顺序在不同的编译器不同的调用约定下可能是不一样的,一般是从右到左,但也有可能是从左到右,所以,可能的过程是先 new int,然后调 g(),如果恰好 g()发生异常,而 shared ptr 还没有创建,则int 内存泄露了,正确的写法应该是先创建智能指针,代码如下:
shared ptr<int> p(new int());
f(P,g());
3) 通过 shared from this( 返回 this 指针。不要将 this 指针作为 shared ptr 返回出来因为 this 指针本质上是一个裸指针,因此,这样可能会导致重复析构
struct A
{
shared ptr<A>GetSelf()
{
return shared ptr<S>(this);// don't do this!
}
};
int main()
{
shared ptr<A> spl(new A);
shared ptr<A> sp2 = sp1->GetSelf();
return0;
}
在这个例子中,由于用同一个指针 (this)构造了两个智能指针 sl 和 sp2而它们之间是没有任何关系的,在离开作用域之后 this 将会被构造的两个智能指针各自析构,导致重复析构的错误。
4)要避免循环引用。循环引用会导致内存泄露
下例是一个典型的循环引用的场景。
struct A;
struct B;
struct A
{
std::shared ptr<B> bptr;//A中创建了B
~A() { cout <<"A is deleted!" << endl; }
};
struct B
{
std::shared ptr<A> aptr;//B中创建了A
~B() { cout <<"B is deleted!” << endl;}
};
void TestPtr(){
std::shared ptr<A> ap(new A);
std::shared ptr<B> bp(new B);
ap->bptr=bp;
bp->aptr=ap;// Objects should be destroyed.
}
测试结果是两个指针 A 和 B 都不会被删除,存在内存泄露。循环引用导致 ap 和 bp 的引用计数为 2,在离开作用域之后,ap 和 bp 的引用计数减为 1,并不会减为 0,导致两个指针都不会被析构,产生了内存泄露。解决办法是把 A 和B 任何一个成员变量改为 weak ptr。
.
7)share_ptr管理第三方库的接口,避免内存泄漏
第三方库分配的内存一般需要通过第三方库提供的释放接口才能释放,由于第三方库返回的指针一般都是原始指针,在用完之后如果没有调用第三方库的释放接口,就很容易造成内存泄露。
void* p = GetHandle()->Create();
//do something...
GetHandle()->Release(p);
这段代码实际上是不安全的,在使用第三方库分配的内存的过程中,可能忘记调用Release 接口,还有可能中间不小心返回了,还有可能中间发生了异常,导致无法调用Release 接口。
智能指针来管理第三方库的内存就很合适了,只要离开作用域内存就会自动释放,不用显式去调用释放接口了,不用担心中途返回或者发生异常导致无法调用释放接口的问题。
void* p = GetHandle()->Create();
std::shared ptr<void> sp(p,[this] (void*p) (GetHandle ()->Release (p);));
上面这段代码就可以保证任何时候都能正确释放第三方库分配的内存
.
(3)weak_ptr弱指针
1)weak_ptr的特性
1、weak_ptr弱指针不能对资源进行操作(weak ptr 没有重载操作符* 和->,因为它不共享指针),只能作为一个旁观者监控share_ptr的生命周期(不会使引用计数加1减1),即仅仅监控共享指针管理的资源是否存在。
2、用于share_ptr共享指针的this返回实现,解决share_ptr循环引用。
.
2)Weak_ptr的创建
Weak_ptr不能单独存在,需要依靠已有的shared_ptr创建
;
std::shared_ptr<Cat> s_p_c1 = std::make_shared<Cat>("C1");
std::weak ptr<Cat> w_p_c1(s_p_c1);
3) 通过 use_count0 ,获取share_ptr的引用计数
Weak_ptr同样可以调用use_count(),但计数器不+1
shared ptr<int> sp(new int (10));
weak ptr<int> wp(sp);
cout<<wp.use count()<<endl;//结果将输出1
4)通过 expired0 ,判断所share_ptr是否已经被释放
shared ptr<int> sp(new int(10));
weak ptr<int> wp(sp);
if(wp.expired())
std::cout <<"weak ptr 无效,所监视的智能指针已被释放\n”;
else
std::cout << "weak ptr 有效\n";//结果将输出 :weak ptr 有效
5)通过 lock(),获取所监视的 shared ptr数据
Weak_ptr可以通过lock()函数来提升为shared_ptr(类型装换)
std::weak_ptr<int> gw;
void f()
{
if (gw.expired()) // 所监视的 shared ptr 是否释放
{
std::cout << "gw is expired\n";
}
else
{
auto spt = gw.lock()
std::cout << *spt << #\n";
}
}
int main()
{
{
auto sp = std::make_shared<int>(42);
gw=sp;
f();
}
f();
}
输出如下:
42
gw is expired
6)weak_ptr的this返回实现,解决share_ptr循环引用
回到share_ptr循环引用问题,解决方式可以使用弱指针,只要将A或B的任意一个成员变量改为 weak ptr 即可。
struct A;
struct B;
struct A
{
std::shared ptr<B> bptr;//A中创建了B
~A() { cout <<"A is deleted!" << endl; }
};
struct B
{
std::weak_ptr<A> aptr;//改为weak_ptr
~B() { cout <<"B is deleted!” << endl;}
};
void TestPtr(){
std::shared ptr<A> ap(new A);
std::shared ptr<B> bp(new B);
ap->bptr=bp;
bp->aptr=ap;// Objects should be destroyed.
}
这样在对 B 的成员赋值时,即执行 bp->aptr-ap;时,由于 aptr 是 weak_ptr,它并不会增加引用计数,所以 ap 的引用计数仍然会是 1,在离开作用域之后,ap 的引用计数会减为0.A 指针会被析构,析构后其内部的 bptr 的引用计数会减为 1,然后在离开作用域后 bp 引用计数又从1减为0,B 对象也将被析构,不会发生内存泄露。
(4)智能指针总结
(1)C++指针包括两种:原始指针(raw pointer),智能指针(smart pointer),智能指针是unique_ptr、shared_ptr、weak_ptr的统称
(2)关于shared_ptr和unique_ptr的使用场景要根据实际应用需求来选择
如果希望只有一个智能指针管理资源或者管理数组就用unique_ptr
如果希望多个智能指针管理同一个资源就用 shared_ptr。
如果希望监控智能指针资源,而没有权限进行资源操作,就用 weak_ptr。
(3)智能指针只解决了独占特性、共享所有权指针的释放和传递问题,没有从根本上解决C++内存安全问题
.
.
.
(11)指针常量和常量指针
常指针
(1)const 修饰指针指向的内容
const int *p = 8;
等价于
int const *p = 8;
const 修饰指针指向的内容,则内容为不可变量
.
.
(2)const 修饰指针
int a = 8;
int* const p = &a;
*p = 9; // 正确
int b = 7;
p = &b; // 错误
const 修饰指针,则指针为不可变量。
.
.
(3)const 修饰指针和指针指向的内容
int a = 8;
const int * const p = &a;
const 修饰指针和指针指向的内容,则指针和指针指向的内容都为不可变量。(实际上是上面两种情况的合并)
https://www.zhihu.com/question/19829354
https://blog.csdn.net/xingjiarong/article/details/47282563
.
(12)指针实现多态
使用指针多态的实现步骤–用于实现抽象重复事情的函数
1、定义一个公用的多态指针对象,定义具体指针对象
2、通过把具体的指针对象赋值给多态指针对象,实现用多态指针对象操作具体指针对象
(参考control\motion\action的多态设计方式)
基类要越简单越好,是各个子类的公共部分
.
(13)new申请内存并初始化
参考链接https://blog.csdn.net/u012494876/article/details/76222682
无法将分配的所有元素同时初始化为非0值,以下代码是不合法的:
int* buffer = new int[512](0); // 语法错误!!!
int* buffer = new int[512](5); // 语法错误!!!
方法一:在默认情况下,new是不会对分配的int进行初始化的。要想使分配的int初始化为0,需要显式地调用其初始化函数
int* buffer = new int(); // 分配的一个int初始化为0
int* buffer = new int(5); // 分配的一个int初始化为5
int* buffer = new int[512](); // 分配的512个int都初始化为0
方法二:C++11中,增加了初始化列表功能,所以也可以使用以下的方式进行初始化:
int* buffer = new int{}; // 初始化为0
int* buffer = new int{0}; // 初始化为0
int* buffer = new int[512]{}; // 512个int都初始化为0
int* buffer = new int{5}; // 初始化为5
上面不同的是,如下写法是合法的:
int* buffer = new int[512]{5}; // 第一个int初始化为5,其余初始化为0
int* buffer = new int[512]{1, 2, 3, 4}; // 前4个int分别初始化为1、2、3、4,其余int初始化为0
(14)指针的使用note
1、非单一函数体内的对象,能用指针的尽量用指针,只要管理得好,指针的灵活性可以简化很多代码
2、指针的定义(&、malloc、new)、操作operator、使用->(使用的地址被提前释放了)、**内存泄漏(free、delete)**导致系统崩溃,C与C++的灵活性很高,写得好是厉害烂代码一大堆!
3、指针理论上永远不能为空,指针只有被释放之前可以设置为null
4、两个指针指向一个内存地址的使用也要注意,避免出现野指针的问题
参考资料
https://blog.csdn.net/sunshinewave/article/details/51020421
https://blog.csdn.net/zcl1804742527/article/details/52400914
https://blog.csdn.net/sunshinewave/article/details/51020421
.
.
四、函数的使用–方法的实现
(0)参数列表
一般用在类中的构造函数中,构造函数对类内的变量进行初始化时,用参数列表的方式进行类内变量的初始化的效率是比较高的,如
注意:
参数列表初始化变量的顺序要与类中的变量定义顺序一致
例子:
class CControlHome : public CControlBase {
public:
CControlHome();
virtual ~CControlHome() {}
void setParamsAndEnter();
private:
virtual void reset();
virtual void execute();
state state_, last_state_;
LawnBMap *lawn_map_;
BJpsPlan *jps_planner_;
ParameterData *param_data_;
int dock_tried_count_;
uint32_t out_boundary_counter_;
};
CControlHome::CControlHome()
: state_(REACH_CHARGE),
last_state_(REACH_CHARGE),
task_info_(NULL),
lawn_map_(NULL),
jps_planner_(NULL),
param_data_(NULL),
dock_tried_count_(0),
out_boundary_counter_(0) {}
.
.
(1)默认参数
1、注意默认参数的先后顺序:默认实参必须是排在函数参数表中最右边的参数
2、默认参数的数据类型要一致,避免重载。
3、默认参数的赋值要在头文件声明时进行。在源文件不要赋值。若两个文件的默认参数都进行赋值会报声明错误!
源文件定义方法
void CControlMP2P::setParams(Pose &tarQue,bool lookAhead) {
头文件定义方法
void setParams(Pose> &tarQue, bool lookAhead = false);
4、谷歌规范中,函数尽量不要使用默认参数,避免调用的时候过于自动化导致赋值的疏忽,进而程序跑飞。
【函数尽量不要使用默认参数,API调用起来坑很多!!】
.
.
(2)传值–小数据
用途:
一般用于设置标志位,设置小参数(保证拷贝数据的时候不会发生错误)
.
参数传值的原理:
1、C/C++默认情况下,被传递到函数的只是变量的值,永远不可能是变量本身,这就意味着参数传值会新开一个变量的内存空间,同时把形参的值拷贝过来
2、传入函数的只是参数的值,无论是怎么操作,外部原参数不会改变。
.
用例:
1、函数定义上
int changeage(int age)
2、函数调用上
int changeage(age) //传入的参数为整型数据age
double function(int a,int b);//传值函数声明
int x,y;
double result=function(x,y);
.
note:
1、形参和实参的不同,形参是被调函数的形式参数,实参是运行函数中实际参数
2、传值调用并不会改变原来的变量的值,但是传址调回用会改变原来的值,因为本质是改地址底层的东西
3、值传递是安全的,址传递是危险的
.
.
(3)传地址–大数据
1、函数传地C++中rvalue和lvalue详悉
lvalue:变量在内存中的位置。通过它能够找到内存中存放的变量(location value);
rvalue:存放在lvalue对应的内存中的东西(register value);
https://blog.csdn.net/piaoxuezhong/article/details/60574596
.
想要绕开"传值"的问题,最好的办法是拿到变量的地址,把传值问题变成传址问题,想要获得某个变量的地址很简单,只需要在变量前加上"&"取地址符,或者直接传入对象的地址即可。
2、使用指针传址*a的方式(一般用于函数输出)
针传址*a的方式一般用于函数输出,是因为在函数外部可以查看输出是否为null【前提的函数体内计算不到结果,要把输出置为null】
1、函数定义上
int changeage(int *age) //这里说明实参输入是地址
2、函数调用上
int changeage(&age) //若age为对象
int changeage(age) //若age为指针
3、变量的操作
*age //像变量一样进行操作【若是变量常用此操作】
age->XXX //像对象一样进行操作【若是对象常用此操作】
4、变量赋值和指针赋值的差异
函数若定义如下
ErrorCode GetNode(PriorityQueue queue,Point target_point,Node* target_node)
1、若使用引用,则直接像普通变量这样赋值使用
2、若使用指针
指针错误赋值方法如下
target_node=queue->nodes[index];
指针正确赋值方法如下
target_node=&queue->nodes[index];
.
变量用例:
double function(int *a,int *b)//*说明是指针变量
{
double c;
c = *a + *b;
return c;
};//传指针函数声明
int x, y;
double result=function(&x, &y);//此时的&是地址运算符
.
对象用例:
在函数内传指针,变量用*a,对象与结构体用a->
void:getFirstPointFromPath(
uint32_t ¤t_tasks_num, AgileX::CrossRegionPath<int> &paths_,
AgileX::Pose *goal) {
goal->point_.x() = paths_.paths.at(current_tasks_num).at(0).x();
goal->point_.y() = paths_.paths.at(current_tasks_num).at(0).y();
goal->yaw_ = paths_.paths.at(current_tasks_num)
.at(0)
.direction(paths_.paths.at(current_tasks_num).at(1));
}
.
.
3、使用引用传址&a的方式(一般用于函数输入)
传引用的原理
操作的是对象而不是对象的指针,地址还是那个地址,对象还是那个对象,引用不过是给参数起多了个别名。无论是改了拿一个别名,其他别名的值也会改变。
变量用例
int a=10;
int &b=a; //此时b是a的别名,是同一个参数,修改b就是修改a
对象用例
double function(int &a,int &b);//传引用函数声明
int x,y;
double result=function(x,y);//使用函数时看不出来是引用,只能从函数声明和定义中看出来是传引用
1、函数定义上
int changeage(int &age)//age是对象
2、函数调用上
int changeage(age) //age是对象
.
4、指针变量的引用*&a的方式(一般用于函数的输出)
使用指针变量的引用&a的方式场景,函数输出的对象也是指针*。若仅仅使用的是指针传递就会存在二义性,并不是浅拷贝对象的首地址而是开辟了新空间的复制操作,没有实现传地址的效果
void func(int *&x){
++x;}
参考链接
https://zhuanlan.zhihu.com/p/139543762
.
(4)函数return返回值
1)尽量不要写void类型的函数
1、如果函数返回的数据类型不是void都要写return ,不然容易导致线程挂掉
2、尽量不要写void类型的函数,要写一个bool或者int类型的函数,至少函数出现问题可以用if(return)的方式查看,
或许函数或者线程挂了,逻辑根本排除不出来的
.
2)函数的return区别
(1)return;
这种形式是返回void,注意void有时候并不是0,根据系统而定。
(2)return 0;和return false;
这种形式是返回0
(3)return null;
这种形式是返回空指针
可以返回指针和引用,还可以对返回值加上const保护
.
3)函数返回值
bool fun(int a,int b);
.
4)函数返回地址–一般使用指针返回对象
例子:有a个学生,每个学生有b门成绩。要求在用户输入学生的学号后,能输出该学生的全部成绩。用指针函数实现。
# include<stdio.h>
int main()
{
float *search(float (*pointer)[4], int m);
float score[][4]={{60,70,80,90},{56,89,67,88},{34,78,90,66}};
float * p;
int i,k;
printf("Enter the number of student:");
scanf("%d",&k);
printf("The score of No.%d are:\n",k);
p=search(score,k);
for(i=0;i<4;i++)
printf("%5.2f\t", *(p+i));
printf("\n");
return 0;
}
float *search(float (*pointer)[4], int m)
{
float *pt;
pt = *(pointer+m);
return pt;
}
(5)const保护
const的用法
1、const加在函数前修饰函数返回值
2、const加在形参上修饰输入参数
3、const加在函数后,修饰成员函数(若函数是const对象的成员函数,该成员函数也要加上const)
其他看const关键字,常变量,常函数等等
.
(6)函数重载
在同一个作用域内,可以声明几个功能类似的同名函数,但是这些同名函数的形式参数**(指参数的个数、类型或者顺序)必须不同**。您不能仅通过返回类型的不同来重载函数。
.
(7)内联函数–运行优化
内联函数的实现原理:
内联函数要做参数类型检查, 内联函数则是在编译的时候进行代码插入,编译器会在每处调用内联函数的地方直接把内联函数的内容展开,这样可以省去函数的调用的压栈出栈的开销,提高效率。
内联函数是指嵌入代码,就是在调用函数的地方不是跳转,而是把代码直接写到那里去。对于短小简单的代码来说,内联函数可以带来一定的效率提升,而且和C时代的宏函数相比,内联函数 更安全可靠。可是这个是以增加空间消耗为代价的
.
内联函数优势:
内联函数目的是为了提高函数的执行效率。因为调用函数都要做很多工作(调用前要先保存寄存器,并在返回时恢复,复制实参,程序还必须转向一个新位置执行),而内联函数可以省去函数调用的工作,相当于把函数的内容直接执行。
C++内联函数编译展开,运行更快,但是实现的逻辑和业务效果是一致的
.
用例
(1)用关键字 inline 放在函数定义的前面即可将函数指定为内联函数。声明也是这样
(2)Tip: 只有当函数只有 10 行甚至更少时才将其定义为内联函数.
inline int max(int a, int b)
{
return a > b ? a : b;
}
则调用: cout<<max(a, b)<<endl;
在编译时展开为: cout<<(a > b ? a : b)<<endl;从而消除了把 max写成函数的额外执行开销
内联函数会用就行,不必要纠结它是怎么实现的
.
总结
优点:
当函数体比较小的时候, 内联该函数可以令目标代码更加高效. 对于存取函数以及其它函数体比较短, 性能关键的函数, 鼓励使用内联.
缺点:
滥用内联将导致程序变慢. 内联可能使目标代码量或增或减, 这取决于内联函数的大小. 内联非常短小的存取函数通常会减少代码大小, 但内联一个相当大的函数将戏剧性的增加代码大小. 现代处理器由于更好的利用了指令缓存, 小巧的代码往往执行更快。
结论: 一个较为合理的经验准则是, 不要内联超过 10 行的函数. 谨慎对待析构函数, 析构函数往往比其表面看起来要更长, 因为有隐含的成员和基类析构函数被调用!
参考资料
https://blog.csdn.net/u011327981/article/details/50601800
(8)递归函数
使用递归函数涉及代码设计模式,使用递归函数要规范。不然很容易导致死循环出不来!
.
(9)C++函数使用注意事项
1、函数中的避免使用全局变量,把全局变量写在函数参数,用引用进行传入
2、函数参数中一般不允许被改变的变量要加入const进行修饰,引用的参数一般要用const进行修饰
3、大多时候输入形参往往是 const T&. 输出形参往往是const T 。*
若用 const T* 做输出形参则说明输入另有处理. 所以若要使用 const T*, 则应给出相应的理由, 否则会使得读者感到迷惑.
输出使用const T*是因为,其他程序调用是可以先判断该函数输出是否为null,导致程序崩溃
.
五、C++的模块结构
每种语言(C/C++、python)都有它对应的语法、数据结构操作API和应用功能API函数,还有各种功能的库(功能包)。
一些API的实现是用库支持的,而第一个库的实现也会用到第二种或者第三种库支持,这样就会出现各种依赖的问题。
API函数的使用不在于记,因为API会随着版本更新而变化【防盗标记–盒子君hzj】,API的使用关键是在于找途径去查Google。
.
1.C/C++关键字
(1)关键字extern的作用
extern置于变量或函数前,用于标示变量或函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义【定义的时候用过后,声明就不要在重复了】
.
(2)关键字static的作用
static修饰变量或者函数时,使得被修饰的变量成为静态变量,不可被改变,在作用域的生命周期完了的时候内存自动会被释放
Static静态变量的使和作用
开的内存是固定的,不同动态内存这样发生内存泄露
Static静态对象的实现原理
在计算机的静态空间中定义对象,所以动态的程序怎么变,Static静态对象都不会变!
全局/静态区: 保存自动全局变量和static变量(包括static全局和局部变量)。静态区的内容在整个程序的生命周期内都存在,有编译器在编译的时候分配(数据段(存储全局数据和静态数据)和代码段(可执行的代码/只读常量))。
常量存储区: 常量 (const) 存于此处 , 此存储区不可修改 .
全局变量和静态方法static
1、适用场景
当多个对象同时需要某个变量的数据,而该变量数据又不属于某个类class
解决方法一:可以通过吧这个数据定义成全局变量,这样可以解决这个问题,
但是这样存在一个不安全性,因为虽然满足了每个对象的访问级别问题,
但是若果每个对象都能修改这个变量,万一出错就找不到源头,
所以我们不建议在非必要的时候声明使用全局变量
解决方法二:
C++允许我们把一个或者多个变量过着函数声明属于某个类,而不仅仅是该类特有的变量或者函数--静态变量
2、静态方法的使用
在它的声明前面加上static保留字就可以了,声明可以在类中的任何位置,包括:public\protected\private中
3、静态方法的调用语法
(1)可以使用普通函数的调用语法进行调用,但是不建议,如:objectName.methodName();
(2)坚持使用静态类的调用语法:ClassName::methodName();
4、静态方法的注意
(1)static既可以用于变量,和可以用于函数【这就是比全局变量好的地方,static静态变量可以认为是一个全局变量的功能,只是更强大了】
(2)记得要在类声明的外部对静态 属性(变量)做出声明,意思是静态变量要做两次声明【就像声明全局变量一样】,这么做是为了给静态变量分配内存
(3)静态成员是所有对象都可以共享的,所以不能在静态方法里访问非静态的元素【静态方法优先级是比较低的】
(4)非静态方法可以访问类的静态成员,也可以访问类的非静态成员
5、优点
1、程序员可以在没有创建任何对象的情况下调用这个变量和函数【访问级别层面】
2、可以让有关的数据在所有的对象中进行共享 【数据层面】
【防盗标记--盒子君hzj】
.
.
(3)关键字define的作用
#define记得用小括号,避免在#define中数字运算逻辑发生混乱
.
(4)关键字const的作用–运行时常量性
(1)const与#define的区别:
C++的const可以认为是C的define的升级版,const比define更高级就行,define仅仅能修饰常量,const可以修饰常量、变量、函数返回值、函数形参、函数的成员。
宏在预处理阶段替换,const在编译阶段替换;宏没有类型,不做安全检查,const有类型,在编译阶段进行安全检查
(1) 编译器处理方式不同。define宏是在预处理阶段展开,生命周期止于编译期。
只是一个常数、一个命令中的参数,没有实际的存在。#define常量存在于程序的代码段。const常量是编译运行阶段使用,const常量存在于程序的数据段.
(2)类型和安全检查不同。define宏没有类型,不做任何类型检查,仅仅是展开。
const常量有具体的类型,在编译阶段会执行类型检查。
(3) 存储方式不同。define宏仅仅是展开,有多少地方使用,就展开多少次,不会分配内存。
const常量会在内存中分配(可以是堆中也可以是栈中)
.
.
(2)const的用法
const不修饰数据类型,const是修饰离const右边最近的对象。
如果对const常量型变量进行赋值,会左值数据类型报错。
.
.
const修饰变量、函数返回值、函数形参、函数的成员
在定义变量的时候加上了const,该变量就不能被改变,认为该变量是一个常量,const可以出现在函数形参上(传实参但是不能被改变的场景),也可以用在全局定义变量上
const int a=0; //修饰变量,注意:定义的时候就要被赋值!
const int& fun(int& a); //修饰返回值--为了避免返回值被修改的情况。
int& fun(const int& a); //修饰形参--为了避免形参被修改的情况,同时把传值的问题变成传址问题(避免对象或者数据拷贝错误)。
int& fun(int& a) const{} //const成员函数
1)常变量–const修饰整型变量
我们知道,const是一个关键词,在编译的时候起效果。它所修饰的常变量是C语言常量中的一种。
首先通过例子来了解const的用法。
int main()
{
const int num = 10;//int与const的位置可换
num = 20;
printf("%d\n", num);
return 0;
}
这个时候,程序马上会报错,会提示:num必须是可修改的左值。因为在这段代码里,const修饰的是num,那就意味着num的值不能被修改。
那const修饰的常变量,都不能被修改吗?
我们来看这段代码:
int main()
{
const int a = 10;
int * p = &a;
*p = 100;
printf("%d", a);
return 0;
}
我经过运行,得出这个运行结果为100,那也就是说,a虽然是被const修饰,但a的值却被改变了,很明显我们可以看出是通过指针p改变的。因此,我们可以得出一个结论:const修饰的常变量,不能被直接改变,但可以被间接改变。
.
.
2)常指针
1)const 修饰指针指向的内容
const int *p = 8;
等价于
int const *p = 8;
const 修饰指针指向的内容,则内容为不可变量
int main(void)
{
int i = 20;
const int *j = &i; //指针,指向int型常量
//也可以写成int const *j = &i;
j++; //指针指向的内存地址可变
(*j)++; //错误,不能改变内存内容
}
.
.
2)const 修饰指针指向的地址
int a = 8;
int* const p = &a;
*p = 9; // 正确
int b = 7;
p = &b; // 错误
int main(void)
{
int i = 10;
int *const j = &i; //常指针, 指向int型变量
(*j)++; //可以改变变量的内容
j++; //错误,不能改变常指针指向的内存地址
}
const 修饰指针地址,则指针地址为不可变量。
.
.
3)const 修饰指针和指针指向的内容
int a = 8;
const int * const p = &a;
const 修饰指针和指针指向的内容,则指针和指针指向的内容都为不可变量。(实际上是上面两种情况的合并)
.
.
3)常函数
1、const加在函数前修饰函数返回值
2、const加在形参上修饰输入参数
3、const加在函数后,修饰成员函数(若函数是const对象的成员函数,该成员函数也要加上const)
与常指针的用法相似,具体用法在函数章节提及
https://zhuanlan.zhihu.com/p/256423512
.
.
4)const注意实现
若是用const修饰一个引用则容易出现问题,函数输入的形参要加conts就要一const到底,函数内的形参也不能被改变!不然就会报错
参考资料及引用链接
https://blog.csdn.net/qq_42913794/article/details/89390890
https://zhuanlan.zhihu.com/p/134654903
https://zhuanlan.zhihu.com/p/110159656
https://zhuanlan.zhihu.com/p/256423512
.
.
(5)关键字constexpr的作用–运行时常量性+编译时常量性
1、简介
constexpr 在 C++11 中用于申明常量表达式 (const expression),可作用于函数返回值、函数参数、数据申明以及类的构造函数等。常量表达式指值不会改变并且在编译时期就得到计算结果的表达式
const int i=3; //i是一个常变量
const int j=i+1; //j是一个常变量,i+1是一个常量表达式
int k=23; //k的值可以改变,从而不是一个常变量
const int m=f(); //m不是常变量,m的值只有在运行时才会获取
2、constexpr 与 const 的区别
const可以修饰函数参数、函数返回值、函数本身、类等,在不同的使用场景下,const具有不同的意义,不过大多数情况下,const描述的是“运行时常量性”,即在运行时数据具有不可更改性。
constexpr可以修饰函数参数、函数返回值、变量、类的构造函数、函数模板等,是一种比const更加严格的约束,它修饰的表达式除了具有**“运行时常量性”,也具有“编译时常量性”**,即constexpr修饰的表达式的值在编译期间可知。
const int getConst(){ return 1; }
enum{ e1=getConst(),e2}; //编译出错
//换成constexpr即可在编译期确定函数返回值用于初始化enum常量
constexpr int getConst(){ return 1; }
enum{ e1=getConst(),e2}; //编译OK
在constexpr出现之前,可以在编译期初始化的const表达式都是隐含的常量表达式(implicit constexpr),直到C++ 11,constexpr才从const中细分出来成为一个关键字,而 const从1983年C++刚改名的时候就存在了。面对constexpr,我们应当尽可能地、合理地使用constexpr来帮助编译器优化代码。
.
3、constexpr 的应用
1)常量表达式函数
如果函数返回值在编译时期可以确定,那么可以使用constexpr修饰函数返回值,使函数成为常量表达式函数。
constexpr int f(){return 1;}
注意,constexpr修饰函数返回值需要满足如下条件:
(a)函数必须有返回值;
(b)函数体只有单一的return语句;
(c)return语句中的表达式也必须是一个常量表达式;
(d)函数在使用前必须已有定义。
2)常量表达式值
一般来说,如果认定变量是一个常量表达式,那就把它声明为constexpr类型。
constexpr int i=3; //i是一个常变量
constexpr int j=i+1; //i+1是一个常变量
constexpr int k=f(); //只有f()是一个constexpr函数时,k才是一个常量表达式
必须明确一点,在constexpr声明中,如果定义了一个指针,constexpr仅对指针有效,与指针所指对象无关。
const int *p=nullptr; //p是一个指向整型常量的指针(pointer to const)
constexpr int *p1=nullptr; //p1是一个常量指针(const pointer)
如果自定义类型对象为常量表达式,那么在定义自定义类型时,需要将constexpr作用于自定义类型的构造函数。
struct MyType {
int i;
constexpr MyType(int x):i(x){}
};
constexpr MyType myType(1);
constexpr作用于自定义类型的构造函数需要满足如下条件:
(a)构造函数体必须为空;
(b)初始化列表只能使用常量表达式。
4、注意
用constexpr取代所有的宏变量及const变量,const仅用于函数参数修饰。
.
(5)关键字register的作用
作用:提高效率
请求CPU尽可能让变量的值保存在CPU内部的寄存器中,减去CPU从内存中抓取数据的时间,提高程序运行效率。
.
.
(6)关键字volatile的作用
用来修饰变量的,表明某个变量的值可能会随时被外部改变,因此这些变量的存取不能被缓存到寄存器,每次使用需要重新读取。
.
(7)关键字typedef的作用–取数据类型别名
功能:
作用是为一个数据类型取一个别名;类似于引用,但是引用时针对对象的
typedef用于给数据类型定义一个新名字,但typedef无法重定义一个模板
typedef unsigned int uint_t;
typedef oldName newName;
oldName 是类型原来的名字
newName 是类型新的名字。例如:
例子
typedef int INTEGER;
INTEGER a, b;
a = 1;
b = 2;
INTEGER a, b;等效于int a, b;
--typedef int* intpointer; 【把int*取别名intpointer】
--intpointer a 【从此可以直接用intpointer定义一个指针变量a】
.
(8)关键字using的作用
1、用于名字空间、类型、函数与对象的引入,实际上是去除作用域的限制。
using 在 C++11 之前主要用于名字空间、类型、函数与对象的引入,实际上是去除作用域的限制。通常与namespace联合使用
//引入名字空间
using namespace std;
//引入类型
using std::iostream;
//引入函数
using std::to_string;
//引入对象
using std::cout;
其中通过 using 引入函数可以解除函数隐藏。
class Base {
public:
void func() {
cout << "in Base::func()" << endl;
}
void func(int n) {
cout << "in Base::func(int)" << endl;
}
};
class Sub: public Base {
public:
using Base::func; // 引入父类所有同名函数func,解除函数隐藏
void func() {
cout<<"in Sub::func()"<<endl;
}
};
int main() {
Sub s;
s.func();
s.func(1); // Success!
}
.
.
2、使用 using 代替 typedef,给类型命名【C++ 11】
从 C++11 开始,using 的别名语法覆盖了 typedef 的全部功能.
对普通类型的重定义示例
将这两种语法对比一下:
// 重定义 unsigned int
typedef unsigned int uint t;
using uint t = unsigned int;
// 重定义 std::map
typedef std::map<std::string, int> map int t;
using map int t std::map<std::string, int>;
可以看到,在重定义普通类型上,两种使用方法的效果是等价的,唯一不同的是定义语法。
typedef void (*func t)(int,int);
using func t = void (*) (int, int);
// 等价于 typedef unsigned char uint8;
using uint8=unsigned char;
// 等价于 typedef void (*FunctionPtr)();
using FunctionPtr = void (*)();
// 定义模板别名,注意typedef无法定义模板别名,因为typedef只能作用于具体类型而非模板
template<typename T> using MapString = std::map<T, char*>;
.
对模板的重定义示例
/* C++98/03*/
template <typename T>
struct func_t
{
typedef void (*type) (T,T);
};
//使用 func_t 模板
func_t<int>::type xx_1;
/* C++11*/
template <typename T>
using func t=void (*)(T,T);
//使用 func_t 模板
func_t<int> xx 2;
.
(9)关键字decltype的作用【C++】–推导出一个表达式的类型
C++11 新增了 decltype 关键字,用来在编译时推导出一个表达式的类型。
decltype 与auto 关键字类似,用于编译时类型推导,不过它与 auto 还是有一些区别的。decltype 的类型推导并不像 auto 从变量声明的初始化表达式获得变量的类型,而总是以一个普通表达式作为参数,返回该表达式的类型,而且 decltype 并不会对表达式进行求值.
语法格式
decItype(exp)
其中,exp 表示一个表达式(expression)。
注意:decltype 的推导过程是在编译期完成的,并且不会真正计算表达式的值。
.
decltype 的推导规则
(1)推导规则 1,exp 是标识符、类访问表达式,decltype(exp)和 exp 的类型一致。
(2)推导规则 2,exp 函数调用,decltype(exp)和返回值的类型一致。
(3)推导规则3,其他情况,若 exp 是一个左值,则 decltype(exp) 是 exp 类型的左值引用,否则和 exp 类型一致。
举例
(1)推导出表达式类型。

struct A { double x; };
const A* a = new A{0};
//第一种情况
decltype(a->x) y; // type of y is double
decltype((a->x)) z = y; // type of z is const double&,因为a一个常量对象指针
//第二种情况
int* aa=new int;
decltype(*aa) y=*aa; //type of y is int&,解引用操作
//第三种情况
decltype(5) y; //type of y is int
decltype((5)) y; //type of y is int
const int&& RvalRef() { return 1; }
decltype ((RvalRef())) var = 1; //type of var is const int&&
(2)与using/typedef合用,用于定义类型
using size_t = decltype(sizeof(0));//sizeof(a)的返回值为size_t类型
using ptrdiff_t = decltype((int*)0 - (int*)0);
using nullptr_t = decltype(nullptr);
vector<int>vec;
typedef decltype(vec.begin()) vectype;
for (vectype i = vec.begin; i != vec.end(); i++)
{
//...
}
显而易见,与auto一样,也提高了代码的可读性。
.
使用场景
若想要通过某个表达式得到类型,但不希望新变量和这个表达式具有同样的值
泛型编程中结合 auto,用于追踪函数的返回值类型,这是 decltype的最大用途。decltype 帮助 C++ 模板更加泛化,程序员在编写代码时无需关心任何时段的类型选择,编译器会合理地进行推导。
template <typename _Tx, typename _Ty> auto multiply(_Tx x, _Ty y)->decltype(x*y) {
return x*y;
}
.
(10)final 关键字【C++ 11】
作用
C++11 中增加了 final 关键字来限制某个类不能被继承,或者某个虚函数不能被重写。如果修饰函数,final 只能修饰虚函数,并且要放到类或者函数的后面。
final 的用法
struct A
{
//A::foois final,限定该虚函数不能被重写
virtual void foo() final;
//Error:non-virtual function cannot be final,只能修饰虚函数
void bar() final;
};
struct B final :A // struct B is final
{
//Error: foo cannot be overridden as it's final in A
void foo();
};
struct C : B //Error: B is final
{};
.
(11)override关键字【C++ 11】
作用
override 关键字确保在派生类中声明的重写函数与基类的虚函数有相同的签名,同时也明确表明将会重写基类的虚函数,还可以防止因疏忽把本来想重写基类的虚函数声明成重载。这样,既可以保证重写虚函数的正确性,又可以提高代码的可读性。
用法
区别是 override 关键字和 final关键字一样,需要放到方法后面
struct A
{
virtual void func()[]
};
struct D:A
{
// 显式重写
void func() override
{
}
};
.
(11)explicit关键字–显式地进行类型转换
作用
1、指定构造函数或转换函数 (C++11起)为显式, 即它不能用于隐式转换和复制初始化。
C++中的explicit关键字通常用来将构造函数标记为显式类型转换,即在创建对象的时候不能进行隐式类型转换。
2、可以与常量表达式一同使用. 当该常量表达式为 true 才为显式转换(C++20起)。
参考链接
https://zhuanlan.zhihu.com/p/498803683
.
(12)auto关键字–自动推断数据类型
1、变量类型推断
在变量定义时根据初始化表达式自动推断变量类型。
auto 是旧关键字,在 C++11 之前,auto 用来声明自动变量,表明变量存储在栈,很少使用。在 C++11 中被赋予了新的含义和作用,用于类型推断。
auto关键字的功能:
auto的自动数据类型能够根据数据定义生成不同的数据结构。会根据右边赋值的量的数据类型来定义变量的数据类型
.
auto关键字的实现原理:
auto 并不能代表一个实际的类型声明,只是一个类型声明的“占位符”,使用 auto 声明的变量必须马上初始化,以让编译器推断出他的实际类型,并在编译时将auto 占位符替换为真正的类型。
不同于python等动态类型语言的运行时变量类型推导,隐式类型定义的类型推导发生在编译期。它的作用是让编译器自动推断出这个变量的类型,而不需要显式指定类型。
.
auto 的推导规则
auto可以同指针、引用结合起来使用,还可以带上 cv 限定符(cv-qualifier,const 和 volatile 限定符的统称)。
int x=0;
auto * a= &x; //a -> int*,auto被推导为int.
auto b = &x; //b -> int*,auto被推导为 int*
auto &c= x; //c-> int&,auto 被推导为int,注意:这是引用,不是取地址
auto d=c; //d->int ,auto被推导为int
const auto e = x; //e -> const int
auto f =e; //f -> int
const auto& g = x; //g -> const int&&
auto& h = g; //h -> const int6
通过上面的一系列示例,可以得到下面这两条规则:
- 当不声明为指针或引用时,auto 的推导结果和初始化表达式抛弃引用和 cv 限定符后类型一致。
2)当声明为指针或引用时,auto 的推导结果将保持初始化表达式的 cv 属性
.
举例:
auto i = 42; //i is an int
auto l = 42LL; //l is an long long
auto p = new foo(); //p is a foo*
对于值x=1;既可以声明: int x=1 或 long x=1,也可以直接声明 auto x=1
auto f = 3.14; //double
auto s("hello"); //const char*
auto z = new auto(9); //int *,new 申请内存,创建的是指针
auto x1 = 5, x2 = 5.0, x3 = 'r'; //错误,必须是初始化为同一类型
但是这不常用于基本的数据类型,代码追求尽可能高的确定性,自动生成就太依赖系统平台了,我们一般事先就会想好int\double\char等数据类型)
auto关键字适用于自动生成类型冗长的数据类型,使得代码更加简洁,同时可以避免类型声明时的麻烦而且避免类型声明时的错误。
比如:
#include <string>
#include <vector>
void loopover(std::vector<std::string>&vs)
{
std::vector<std::string>::iterator i=vs.begin();
for(;i<vs.end();i++)
{
}
}
变为:
#include <string>
#include <vector>
void loopover(std::vector<std::string>&vs)
{
for( auto i=vs.begin();;i<vs.end();i++)
{
}
}
.
2、函数返回值的占位符
在声明或定义函数时作为函数返回值的占位符,此时需要与关键字 decltype 连用。auto 不能用来声明函数的返回值。但如果函数有一个尾随的返回类型时,auto 是可以出现在函数声明中返回值位置。这种情况下,auto 并不是告诉编译器去推断返回类型,而是指引编译器去函数的末端寻找返回值类型。在下面这个例子中,函数返回值类型是 operator+ 操作符作用在 T、U 类型变量上的返回值类型。
template<class T, class U> auto add(T t, U u) -> decltype(t + u) {
return t + u;
}
auto 的限制
1、 auto 是不能用于函数参数的
void func(auto a = 1) {} // error: auto 不能用于函数参数
2、auto不能用于非静态成员变量
struct Foo
{
auto var1 = 0; //error: auto不能用于非静态成员变量
static const auto var2 = 0; //ok:var2 -> static const int
};
https://blog.csdn.net/xiaoquantouer/article/details/51647865
.
(13)default 和 delete关键字
1、default
C++98 和 C++03 编译器在类中会隐式地产生四个函数:默认构造函数、拷贝构造函数、析构函数和赋值运算符函数,它们被称为特殊成员函数。在 C++11 中,被称为 “特殊成员函数” 的还有两个:移动构造函数和移动赋值运算符函数。如果用户申明了上面六种函数,编译器则不会隐式产生。
C++11 引入的 default 关键字,可显示地、强制地要求编译器生成默认版本。
class DataOnly {
public:
DataOnly()=default; //default constructor
~DataOnly()=default; //destructor
DataOnly(const DataOnly& rhs)=default; //copy constructor
DataOnly& operator=(const DataOnly & rhs)=default; //copy assignment operator
DataOnly(const DataOnly && rhs)=default; //C++11,move constructor
DataOnly& operator=(DataOnly && rhs)=default; //C++11,move assignment operator
};
上面的代码,就可以让编译器生成上面六个函数的默认版本。
1、delete
1)delete关键在C++11之前是对象释放运算符
用于释放new对象时所申请的内存。
.
2)禁止default时编译器生成上面六种函数的默认版本。
在C++11中,被赋予了新的功能。
class DataOnly {
public:
DataOnly()=delete; //default constructor
~DataOnly()=delete; //destructor
DataOnly(const DataOnly& rhs)=delete; //copy constructor
DataOnly& operator=(const DataOnly & rhs)=delete; //copy assignment operator
DataOnly(const DataOnly && rhs)=delete; //C++11,move constructor
DataOnly& operator=(DataOnly && rhs)=delete; //C++11,move assignment operator
};
C++11 中,delete 关键字可用于任何函数,不仅仅局限于类成员函数。在函数重载中,可用delete来滤掉一些函数的形参类型,如下:
bool isLucky(int number); // original function
bool isLucky(char) = delete; // reject chars
bool isLucky(bool) = delete; // reject bools
bool isLucky(double) = delete; // reject doubles and floats
这样在调用 isLucky 函数时,如果参数类型不对,则会出现错误提示
if (isLucky('a'))... // error! call to deleted function
if (isLucky(true))... // error!
if (isLucky(3.5))... // error!
(16)assert关键字
1、assert动态断言关键字
作用
断言就是对一个表达式的判断,当表达式为假时就输出诊断消息并调用abort()函数中止程序。
使用格式
断言的头文件为 assert.h
assert(bool_constexpr );
断言的用法
#include <assert.h>
void test (char *a){
assert(a!=NULL);
printf("%s",a);
}
int main()
{
char * p=NULL;
char * p1="this test !";
test(p);
test(p1);
return 0;
}
当传入参数为空值时,程序中断并输入如下诊断信息
C:\Users\23171\Desktop\test_cmake\bin>"C:\Users\23171\Desktop\test_cmake\bin\main.exe"
Assertion failed: a!=NULL, file C:\Users\23171\Desktop\test_cmake\src\main.c, line 9
如何禁用断言
因为频繁调用断言会影响程序性能,因此有时需要禁用断言。只需要在头文件里添加NDEBUG的宏定义。
#include<iostream>
#include<cassert>
#define NDEBUG
……
使用注意
1.在函数开始时,监测参数是否合法。
2.每个断言只能检测一个条件。因为条件过多,当出现错误时,无法判断是哪个条件出错。
3.不能在断言中放入改变源程序数值的语句,例如assert(++i==3);
4.assert();语句只有在Debug版本中才能使用,而在Release版本中被无视。为了使在Debug版本和Release版本下不产生任何差别,assert()不是一个函数而是一个宏。
5.使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的
2、static_assert静态断言关键字
作用
static_assert是C++11引入的静态断言,与assert(运行时断言宏)相反,用于检测和诊断编译期错误。
基本语法
static_assert(断言表达式,提示字符串);
断言表达式必须是在编译器可以计算的表达式,即必须是常量表达式。如果断言表达式的值为 false ,那么编译器会出现一个包含指定字符串的错误,同时编译失败。如果为 true 那么没有任何影响。
static_assert(sizeof(void*) == 8,"not supported");
3、Boost C++ assert的用法简析【升级版】
https://blog.csdn.net/weixin_39956356/article/details/111482530
https://blog.csdn.net/lijie0073237/article/details/56489728
.
2.C/C++常用操作符
(1)取地址运算符“&”–用于取变量的地址
成员访问运算符“*” --用于把指针变量的地址转化成变量,进行运算
【可以这么理解加*往上层走,加&往下层走】
.
(2)成员运算符“.”
使用方法:对象.函数(行为),如:cin.peek();意思是cin这个流对象调用了peek()这个函数【区别于C语言中的主函数调用子函数】
"->"解引用符 --针对地址
【指针用"->",对象用"."】
A.B【.是成员调用操作符】
A为对象或者结构体,B为A中的成员变量或者成员函数
.
(3)“<<”“>>”位移操作符或流操作符
1、在C语言中“<<”是左移操作符
2、在C++语言中“<<”是一个流操作符
【防盗标记--盒子君hzj】
3、这两个流操作符调用了输入输出对象,已经做好了重载,能自动识别整形、浮点型、字符型等等数据结构
4、C语言和C++语言的“<<”含义是不一样的,C++语言对这个"<<"进行了重载,运行C文件是左移操作符,运行C++文件是流操作符
.
(4)作用域运算符"::"
作用:告诉编译器这个函数是存在在哪里的,或者是属于哪个类的,如
std::cout<< <<
A::B【::是作用域运算符】
A可以是名字空间、类、结构,A::B表示作用域A(命名空间A)中的名称B
.
(5)条件运算符"?:"
(0)条件语句的高级写法
(条件)?(行动一):(行动二)
(1)result=a>b?"x":"y";
判断a是否大于b,如果a大于b 则把x的值赋给result,如果a小于b 则把y的值赋给result
(2)result=a>b?"x":(a>c?"y":"z");
判断a是否大于b,如果a大于b 则把x的值赋给result,如果a小于b 那么在a大于b 的前提下进行判断a是否大于c,如果a大于c 那么把y的值赋给result,如果a小于c那么把z的值赋给result
(6)尺寸运算符"sizeof"
sizeof计算的是在栈中分配的内存大小。常用于计算数组的长度
.
(7)A->B【->是成员提取操作符】
A只能是指向类、结构、联合的指针,A->B是提取A中的成员B【防盗标记--盒子君hzj】
.
(8)A:B【:是继承运算符】
A可以是类,A:B表示B类继承A类
.
(9)i++和++i【++自增运算符】
(1)单独使用两者没有区别!
(2)在赋值操作的时候两者有区别,运算符服从左边的优先级较高的原则,i++是先赋值,然后再自增;++i是先自增,后赋值
https://zhuanlan.zhihu.com/p/391942337
https://blog.csdn.net/David8631/article/details/2707914
.
3.C++预处理指令#–头文件包含、宏定义、条件编译、输出编译警告与错误
Makefile文件的作用
makefile关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。
.
1、预编译指令#用途总览
指令 用途
# 空指令,无任何效果
#include 包含一个源代码文件
#define 定义宏
#undef 取消已定义的宏
#if 如果给定条件为真,则编译下面代码
#ifdef 如果宏已经定义,则编译下面代码
#ifndef 如果宏没有定义,则编译下面代码
#elif 如果前面的#if给定条件不为真,当前条件为真,则编译下面代码
#endif 结束一个#if……#else条件编译块
#error 停止编译并显示错误信息
预处理指令以#号开头,并且#号必须是该行除了任何空白字符外的第一个字符。
#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。
单纯一个#号表示空指令,没有任何作用
.
.
2、#define宏定义与#undef取消宏定义
#define指令定义了一个标识符及一个串,标识符称为宏名,源程序中宏名的每次出现都会用其定义的串进行替换,称为宏替换。
#undef指令取消一个已定义的宏。
因为宏替换并不会进行类型匹配之类的安全性检查。同时用宏定义了一个MAX函数,其好处是没有函数调用的额外开销,运行速度较快,但容易出错,而且大量的宏替换会增加代码的长度。
#define PI 3.14
.
.
3、#if、#else、#elif、#endif条件编译块
这几个指令称为条件编译指令,可对程序源代码的各部分有选择地进行编译。
跟一般的if、else if、else语句类似,如果一个条件上的值为真,则编译它对应的代码,否则提过这些代码,测试下一个条件上的值是否为真。注意,作为条件的表达式是在编译时求值的,它必须仅含常量及已定义过的标识符,不可使用变量,也不可以含有操作符sizeof(sizeof也是编译时求值)。
命令#endif标识一个#if块的结束。
void test3()
{
#define OPTION 2
#if OPTION == 1
cout << "Option: 1" << endl;
#elif OPTION == 2
cout << "Option: 2" << endl; //选择这句
#else
cout << "Option: Illegal" << endl;
#endif
.
.
4、#include、#ifdef、#ifndef、#endif头文件包含关系
#include预处理指令的作用是在指令处展开被包含的文件。展开被包含的文件之后,在代码就可以正常地调用该文件中所声明的变量和函数。#include指令有两种使用方法
#include <xxx.h>
#include "xxx.h"
第一种方法#include <xxx.h>将待包含的头文件使用尖括号括起来,预处理程序会在系统默认目录或者括号内的路径查找,通常用于包含系统中自带的公共头文件。
第二种方法#include <xxx.h>将待包含的头文件使用双引号引起来,预处理程序会在程序源文件所在目录查找,如果未找到则去系统默认目录查找,通常用于包含程序作者编写的私有头文件。
文件包含可以是多重的,也就是说一个被包含的文件中还可以包含其他文件。在大型的程序中可能会产生重复包含的问题,如
#include "a.h"
#include "b.h"
一个程序包含了a.h和b.h两个头文件,但a.h和b.h可能同时又都包含了c.h,于是该程序就包含了两次c.h,这在一些场合下会导致程序的错误,可以通过**#ifdef、#ifndef、#endif**的条件编译进行解决。
#ifdef、#ifndef、#endif指令这几个也是条件编译指令,其检查后面指定的宏是否已经定义,然后根据检查结果选择是否要编译后面语句。其中#ifdef表示”如果有定义“,#ifndef表示”如果没有定义“。
这个通常可以用于防止重复包含头文件的问题
#ifndef MYHEAD_H
#define MYHEAD_H
#include "myHead.h"
#endif
5、#error指令、#pragma warning指令
#error指令在编译时输出编译错误信息,可以方便程序员检查出现的错误。
void test5()
{
#define OPTION 3
#if OPTION == 1
cout << "Option: 1" << endl;
#elif OPTION == 2
cout << "Option: 2" << endl;
#else
#error ILLEGAL OPTION! //fatal error C1189: #error : ILLEGAL OPTION!
#endif
}
#pragma warning指令能够控制编译器发出警告的方式,其用法举例如:#pragma warning(disable : 4507 34; once : 4385; error : 164)
这个指令有三部分组成,其中disable部分表示忽略编号为4507和34的警告信息,once部分表示编号为4385的警告信息只显示一次,error部分表示把编号为164的警告信息当做错误。
另外,其还有两个用法
#pragma warning(push [, n]):保存所有警告信息的现有的警告状态,后面n是可选的,表示把全局警告等级设为n。
#pragma warning(pop):弹出最后一个警告信息,取消在入栈和出栈之间所作的一切改动
void test6()
{
#pragma warning(push) //保存编译器警告状态
#pragma warning(disable:4305) //取消4305的警告
bool a = 5; //无警告信息
#pragma warning(pop) //恢复之前的警告转改
bool b = 5; //warning C4305: 'initializing' : truncation from 'int' to 'bool'
}
4.强制类型转换
1、方法
在静态变量前加入小括号--(变量数据类型)
2、功能
强制改变变量的的数据类型,来对得上程序的数据结构要求
3、例子
(int)、(float)、(double)、(class name*)、(char)等等
4、数据类型的运算和强制转换错误
9/5.0输出的是整数,9.0/5.0输出的是浮点数
【防盗标记--盒子君hzj】
5、强制转换要注意的点
(1)内存的对齐方式,对齐方式不同可能导致强制转换的时候崩溃
(2)嵌入式现在的传输时一个一个字节的传输的
不能大于uint64_t,uint64_t接收会导致崩是内存不对齐,内存不对齐不能进行强制转换,故只能用memcpy
uint64_t stamp = 0;
memcpy((uint8_t *)&stamp, (uint8_t *)data, 4);
MCU_LOG("stamp now: %lld", stamp);
visionObject->stamp = stamp;
offset += sizeof(uint64_t);
.
6、C++ 11强制转换的防止类型收窄
类型收窄指的是导致数据内容发生变化或者精度丢失的隐式类型转换。
类型收窄包括以下几种情况:
1)从一个浮点数隐式转换为一个整型数,如 int i2.2。
2)从高精度浮点数隐式转换为低精度浮点数,如从long double 隐式转换为 double 或float.
3) 从一个整型数隐式转换为一个浮点数,并且超出了浮点数的表示范围,如 floatx=(unsigned long long)-1。
4)从一个整型数隐式转换为一个长度较短的整型数,并且超出了长度较短的整型数的表示范围,如char x=65536。
在 C++98/03 中,像上面所示类型收窄的情况,编译器并不会报错或报一个警告
在C++11,可以通过列表初始化来检查及防止类型收窄。

在上面的各种隐式类型转换中,只要遇到了类型收窄的情况,初始化列表就不会允许这种转换发生。
.
7、数值类型和字符串类型的相转换
(1)数值类型转字符串类型
C++11 提供了 to string 方法,可以方便地将各种数值类型转换为字符串类型
API如下:

测试代码如下:
#include <iostream>
#include <string>
int main()
double f =1.53;
std::string f_str = std::to string(f);
std::cout << f_str << i\n';
double fl = 4.125;
std::wstring f_strl= std::to wstring(f1);
std::wcout << f_strl;
}
输出结果如下(注意这是字符串)
1.53
4.125
.
(2)字符串类型转数值类型
C++11 还提供了字符串转换为整型和浮点型的方法口atoi:将字符串转换为 int 类型。
atoi:将字符串转换为 long 类型。
atoii:将字符串转换为 long long 类型。
atof:将字符串转换为浮点型。
字符串转换为整型的测试代码如下:
finclude <iostream>
#include <cstdlib>
int main()
{
const char*strl =“10";
const char*str2 ="3.14159";
const char*str3 =“31337 with words";
const char*str4 = "words and 2";
int numl = std::atoi(str1);
int num2 = std::atoi(str2);
int num3 = std;:atoi(str3);
int num4 = std::atoi(str4);
std::cout<<"std::atoi(\""<< str1<<"\")is"<<num1<<\n';
std::cout<<"std::atoi(\""<< str2<<"\")is"<<num2<<\n';
std::cout<<"std::atoi(\""<< str3<<"\")is"<<num3<<\n';
std::cout<<"std::atoi(\""<< str4<<"\")is"<<num4<<\n';
return 0;
}
输出结果如下:
std::atoi("10") is 10
std::atoi("3.14159") is 3
std::atof("31337 with words") is 31337
std::atoi("words and 2") is 0
如果需要转换的字符串前面部分不是数字,会返回 0,上面的 str4 转换后返回0;如果字符串的前面部分有空格和含数字,转换时会忽略空格并获得前面部分的数字。
.
5.重载机制及多态性
(1)重载定义
实质就是用同样的名字再定义一个有着不同参数但有着同样功能用途的函数(如同一个人,能完成不同的事情一样)
重载可以重载不同数目的参数,也可以重载不同的数据类型
(2)重载好处
简化工作的编程工作,提高了程序的可读性,所以重载不是面向对象的特征
(3)(函数)重载机制
不同的数据类型重载函数实现方法
改变函数传入的形参数据结构,同时对同一名字而不同数据结构的函数进行声明,系统会自动识别
不同的参数个数的重载函数实现方法
改变函数传入的形参的数目,同时对同一名字而不同数据结构的函数进行声明,系统会自动识别
(4)(类)重载机制
重载机制可以允许定义同名的多个函数(方法),只是这些函数的输入参数必须不同(可以参数的数据类型不同,也可以参数的数量不同),
编译器会自定识别,因为编译器是根据不同的参数输入区分不同的函数(方法)的
注意:重载只能在类本身新定义的函数中进行重载,不能子类中先集成基类的函数再对该继承的函数进行重载,这样会出错的,重载机制只适合用于新定义的函数
【防盗标记--盒子君hzj】
注意区分重载机制和覆盖机制,及其两个机制的作用
(5)(运算符)重载机制
1、重载的定义
重新赋予新的含义,函数重载就是对函数重新赋予新的含义,运算符重载就是对运算符重新赋予新的含义
2、运算符重载的方法:
先定义一个重载运算符函数,在执行被重载的运算符时,系统会自动调用该函数,实现相应的运算
3、运算符重载和函数重载的关系:
运算符重载是通过定义函数实现的,所以运算符重载实质上是函数的重载
4、重载运算符 函数格式一般如下:
函数类型 operator 运算符名称(形参列表)
{
对重载运算符的实现过程
}
例子:把加法运算符重载成减法运算符
【防盗标记--盒子君hzj】
int operator +(int a,int b)
{
return(a-b);
}
5、优点:
用重载运算符代替了函数调用的过程,可视化程度更高,仅仅关注运算符的功能就行,不用关心运算符功能的实现
6、注意:
1、C++不允许用户及定义新的运算符,只能对已有的运算符进行重载
2、以下蜈蚣丸运算符是不允许重载的。
--"." 成员运算符
--"*" 成员访问运算符
--"::" 作用域运算符
--"?:" 条件运算符
--"sizeof" 尺寸运算符
3、重载不能改变运算符对象(操作数)个数
4、重载不能改变运算符的优先级别
5、重载不能改变运算符的结合性
6、重载运算符函数不能有默认的参数
7、重载运算符必须和用户定义的自定义类型的对象一起使用,其参数必须有一个类的对象或者引用。(这个约定是为了防止程序员该标准类型结构的运算符性质)
8、只有在经常使用,很有必要的时候才重载运算符,因为别人读程序,重载运算符不好理解
9、重载运算符尽量不要改变他原有的意义,最好是在原有的意义上增加功能
(6)重载"<<"操作符
通过重载"<<"操作符来实现print打印输出的功能
(7)多态性
1、多态性的解释:
用同一个名字定义函数,当调用同一个名字的函数的时候,却执行不同的操作,从而实现了一个接口,多钟方法(函数),理解上可以康丽洁为重载函数的升级版
2、多态性是如何实现的
【防盗标记--盒子君hzj】
--编译时的多态性:重载函数
--运行时的多态性:虚函数
.
(8)重载与重写的区别
重载:是指允许存在多个同名函数,而这些函数的参数表不同
重写:是指子类重新定义父类虚函数的方法
.
.
6.虚函数和纯虚函数virsual
(1)虚方法(virsual method)
1、功能
纯虚函数【最抽象的函数,什么都不做就是什么都做了】
为了是编译器有选择的调用覆盖的内容的方法(函数 )【相当于调用的优先级提高】
2、使用场景
假如cat和dog是pet的子类,基类中有一个函数play(),
子类cat和dog也有对应的play()并对基类的play()进行了覆盖,
如果在主程序中定义pet *pointer=new cat,并执行cat->play();
结果是输出了pet.play()的 内容。这是不对的
3、注意
虚方法是继承的,如果在基类里把某个函数或者变量声明为虚方法(函数)
,在子类中就不可以在一次声明是虚方法(函数)了,
因为本来已经继承了,已经是虚函数了
4、虚方法的用法
在变量或者函数定义前加上virtual保留字
5、优点
程序员无需顾虑一个虚函数会咋子其某个子类中编辑一个非虚函数
6、经验
(1)如果某个函数拿不准要不要声明为虚方法,那么就把这个函数声明为虚方法
(2)虚方法可能会使程序运行的慢一点,但是安全性高,天使过程不会出现奇怪的现象
在设计一个多层次 类继承关系时常常用到
【防盗标记--盒子君hzj】
功能:告诉编译器不要浪费时间在这个类中寻找实现函数了,只有在继承的时候才会有实现过程
语法:在声明一个虚方法的基础上,在原型的末尾加上“=0”
virtual void eat()=0;
.
(2)C++虚函数和虚类
C++ 只能定义虚函数和虚类,不能定义虚变量,虚函数和虚类本质是一种方法的抽象
.
(3)override关键字的作用
(1)纯虚类的继承必须override
(2)override的语法,当你写了override注解时
第一的作用:程序会判断你是否正确的重写了父类的对应方法。
第二的作用:只要子类定义了和父类一样的方法名,不管是直接重载还是override重写,那么父类中所有同名方法都会被子类屏蔽
(3)基类的虚函数一般不会写实现,在子类继承这个基类的时候必须对基类的虚函数进行重写
.
(4)纯虚函数、虚函数的作用
纯虚函数的理解
纯虚函数是为你的程序制定一种标准,纯虚函数只是一个接口,是个函数的声明而已,它要留到子类里去实现, 带纯虚函数的类抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。
虚函数可以让成员函数操作一般化,用基类的指针指向不同的派生类的对象时,基类指针调用其虚成员函数,则会调用其真正指向对象的成员函数,而不是基类中定义的成员函数(只要派生类改写了该成员函数)。若不是虚函数,则不管基类指针指向的哪个派生类对象,调用时都会调用基类中定义的那个函数。虚函数是C++多态的一种表现,可以进行灵活的动态绑定。
class A{
protected:
void foo();//普通类函数
virtual void foo1();//虚函数
virtual void foo2() = 0;//纯虚函数
}
带纯虚函数的类抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。
虚函数是为了继承接口和默认行为
纯虚函数只是继承接口,行为必须重新定义
.
.
7.命名空间namespace
1、使用背景
编写的程序越多越复杂,就需要用到命名空间,命名空间其实是由用户自己制定义的范围,
同一个命名空间内的东西只要独一无二就可以的,如果某个程序有许多不同的头文件或者已经编译的文件,
而它们有各种声明了许多东西,这时候命名空间可以提供保护,以防变量及函数冲突,
这样不同命名空间里面就可以拥有相同的变量名和函数名了
【防盗标记--盒子君hzj】
2、功能
这是一个命名空间的概念,作用是把C++标准库中所有的标志符(类函数、对象)都定义在同一个特殊的命名空间下,
这样可以避免全局变量、局部变量等的冲突
3、方法
先写出关键字namespace,在写出空间名字,最后用一堆花括号把命名空间里面的东西括起来
namespace name
{
.......
}
4、using与namespace的配合使用
注意using和namespace的配合使用
namespace的用法可以使得程序更加清晰,模块之间的引用不会乱
using的用法可以类似于宏定义,using可以配合namaspace做第三方库的命名空间宏
定命名空间是C++ using namespace中最常被用到的地方
【using namespace std;】
一般都是using ClassBase::a;这样的形式出现
(它引用了基类ClassBase中的成员a)
一般都是using a = b;这样的形式出现
(即a 是b的一个别名, a和b是同样的效果)【防盗标记--盒子君hzj】
.
5、注意
(1)在最后面不用加分号
(2)如果在程序开头没有写using namespace std;这个指令,还有一个补救的方法:std::cout语法来调用特定的输出流,std::在大型程序中是很有必要的
.
.
8.模块化编程(工厂设计的方法基础)
1、使用背景
把实现的效果划分为多个部分(模块),每个模块写在一个文件里面,
这样把多个模块搞到多个文件中,用编译器把文件重新组合一起实现功能。
2、头文件:后缀名为.h文件
系统头文件功能:声明C++标准库文件 如:#include<stdio.h>
3、自定义头文件功能
提供必要的函数声明,变量声明、类声明,使用第三方库声明,
但是千万不要在头文件里面写程序的实现,程序的实现写在C/C++文件里面,如:#include“fish.h”
4、注意
(1)自定义头文件一般都放在一个头文件里进行声明,再调用这个头文件就行了,这样避免重复包含和漏包含的情况,而且会专门创建一个目录(文件夹)分开存放这些头文件,易于查找
【防盗标记--盒子君hzj】
(2)头文件里面尽可能多的注释,因为头文件会被很多文件引用,声明的东西应该描述的更清晰
.
.
9. template模板语法【泛型编程,函数、类与运算符重载的升级版】
(1)模板的定义
模板是用户为类或者函数声明一种一般模式,同样的函数和类的框架,但是允许输入输出类型不一样
(类似于的重载函数,但是模板不需要事先知道类型,模板和auto语法一样,传入实参的时候自动推断类型,便于记忆,模板的特性=重载的特性+auto的特性)【防盗标记–盒子君hzj】
泛型编程技术支持程序员创建函数和类的模板(template),而不是具体的函数和类
适用范围:
当程序员需要用到这些函数中的某一个时,编译器将根据模板生成一个能够对特定数据类型进行处理的代码版本,这样允许程序员使用一个解决方案解决多个问题。
引入原因:编写单一的模板,它能适应大众化,使每种类型都具有相同的功能,但对于某种特定类型,如果要实现其特有的功能,单一模板就无法做到,这时就需要模板特例化。
定义:是对单一模板提供的一个特殊实例,它将一个或多个模板参数绑定到特定的类型或值上。
.
.
(2)模板的作用
使得函数中或类中的某些数据成员或者成员函数的参数、返回值可以取任意类型,让程序员编写与类型无关的代码
例子
比如编写了一个交换两个整型int 类型的swap函数,
这个函数就只能实现int 型,对double,字符这些类型无法实现,要实现这些类型的交换就要重新编写另一个swap函数。
使用模板的目的就是要让这程序的实现与类型无关,比如一个swap模板函数,即可以实现int 型,又可以实现double型的交换
(3)模板的形式
(1)函数模板(函数模板针对仅参数类型不同的函数)
(2)类模板(类模板针对仅数据成员和成员函数类型不同的类)
(4)函数模板
1)函数模板的格式
template <class 形参名,class 形参名,......>
返回类型 函数名(参数列表)
{
函数体
}
其中
(1)template和class是关键字,class可以用typename 关键字代替,在这里typename 和class没区别
(2)<>括号中的参数叫模板形参,模板形参不能为空
(3)<>括号后的是模板函数,模板函数的参数列表必须用模板形参定义
2)函数模板的示例
template <class T>
void swap(T& a, T& b)
{}
当调用这样的模板函数时类型T就会被被调用时的类型所代替,
比如swap(a,b)其中a和b是int 型,这时模板函数swap中的形参T就会被int 所代替,
模板函数就变为swap(int &a, int &b)。而当swap(c,d)其中c和d是double类型时,
模板函数会被替换为swap(double &a, double &b),这样就实现了函数的实现与类型无关的代码
.
函数模板特例化的方法
必须为原函数模板的每个模板参数都提供实参,且使用关键字template后跟一个空尖括号对<>,表明将原模板的所有模板参数提供实参。
声明函数模板
template <typename T>
void fun(T a)
{
cout << "The main template fun(): " << a << endl;
}
定义和使用函数模板
template <> // 对int型特例化
void fun(int a)
{
cout << "Specialized template for int type: " << a << endl;
}
int main()
{
fun<char>('a');
fun<int>(10);
fun<float>(9.15);
return 0;
}
对于除int型外的其他数据类型,都会调用通用版本的函数模板fun(T a);对于int型,则会调用特例化版本的fun(int a)。注意,一个特例化版本的本质是一个实例,而非函数的重载。因此,特例化不影响函数匹配
.
.
(5)类模板
1)类模板的格式
template<class 形参名,class 形参名,…>
class 类名
{ ... };
其中
(1)template和class是关键字,class可以用typename 关键字代替,在这里typename 和class没区别
(2)模板形参不能为空,一但声明了类模板就可以用类模板的形参名声明类中的成员变量和成员函数,
即可以在类中使用内置类型的地方都可以使用模板形参名来声明
2)类模板的示例
template<class T>
class A
{
public: T a; T b;
T hy(T c, T &d);
};
在类A中声明了两个类型为T的成员变量a和b,还声明了一个返回类型为T带两个参数类型为T的函数hy
.
.
3)类模板创建对象方法
比如使用一个模板类A创建一个对象m,则使用类模板创建对象的方法为
A<int> m;
在类A后面跟上一个<>尖括号并在里面填上相应的类型。
这样的话,类A中凡是用到模板形参的地方都会被int 所代替。
当类模板有两个模板形参时创建对象的方法为A<int, double> m;类型之间用逗号隔开【防盗标记--盒子君hzj】
.
.
4)在类模板外部定义成员函数的方法
template<模板形参列表>
函数返回类型 类名<模板形参名>::函数名(参数列表){函数体}
如:
template<class T1,class T2>
void A<T1,T2>::h(){}
.
.
类模板的特例化的方法
声明类模板
template <typename T>
class Test{
public:
void print(){
cout << "General template object" << endl;
}
};
定义和使用函数模板
template<> // 对int型特例化
class Test<int>{
public:
void print(){
cout << "Specialized template object" << endl;
}
};
另外,与函数模板不同,类模板的特例化不必为所有模板参数提供实参。我们可以只指定一部分而非所有模板参数,这种叫做类模板的偏特化 或部分特例化(partial specialization)
.
注意
模板的声明或定义只能在全局,命名空间或类范围内进行。即不能在局部范围,函数内进行【防盗标记–盒子君hzj】
.
10.C++11列表初始化
在 C++98/03 中的对象初始化方法有很多种
(1)普通数组的初始化
int i arr[3] = {1,2,3}// 普通数组
(2)POD结构体的初始化
struct A
{
int X;
struct B
{
int i;
int j;
}b;
}a=[ 1,{ 2,3 ) };//POD 类型
(3)使用拷贝构造函数初始化类
class Foo
{
public:
Foo(int) []
}foo 123; 需要拷贝构造函数
(4)列表初始化{}
变量、数组、结构体、类这些不同的初始化方法,都有各自的适用范围和作用。最关键的是,这些种类繁多的初始化方法,没有一种可以通用所有情况。
为了统一初始化方式,并且让初始化行为具有确定的效果,C++11 中提出了列表初始化(List-initialization)的概念
(1)改进变量及数组的初始化


(2)改进结构体的初始化

(3)改进类的初始化

(4)参数列表还可以用在函数返回值上

(5)初始化任意长度的初始化列表

.
.
11、lambda表达式
(1)lambda 表达式优点
**1、声明式编程风格:**就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,好的可读性和可维护性。
2、简洁:不需要额外再写一个函数或者函数对象,避免了代码膨胀和功能分散,让开发者更加集中精力在手边的问题,同时也获取了更高的生产率。
3、在需要的时间和地点实现功能闭包,使程序更灵活。
.
(2)lambda 表达式的语法
[ capture ] ( params ) opt -> ret { body; };
其中:
capture 是捕获列表;
params 是参数表;
opt是函数选项;r
et 是返回值类型;
body 是函数体。
因此,一个完整的lambda 表达式看起来像这样
auto f = [](int a) -> int ( return a + 1; };
std::cout << f(1) << std::endl;//输出:2
lambda 表达式可以通过捕获列表捕获一定范围内的变量:
[ ] 不捕获任何变量。
[&] 捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)
[=] 捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。
[=,&foo] 按值捕获外部作用域中所有变量,并按引用捕获 foo 变量。
[bar] 按值捕获 bar 变量,同时不捕获其他变量。
[this] 捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限。如果已经使用了 & 或者 =,就默认添加此选项。捕获 this 的目的是可以在lamda 中使用当前类的成员函数和成员变量。
.
12、内存字节对齐
(1)内存字节对齐定义
内存对齐,或者说字节对齐,是一个数据类型所能存放的内存地址的属性。这个属性是一个无符号整数,并且这个整数必须是2的 N次方(1、2、4、8、…、1024、…)。当我们说一个数据类型的内存对齐为 时,就是指这个数据类型所定义出来的所有变量的内存地址都是 8的倍数。
自然对齐的定义
当一个基本数据类型(Fundamental Types)的对齐属性和这个数据类型的大小相等时,这种对齐方式称为自然对齐(Naturally Aligned)。比如,一个4字节大小的 int 型数据,在默认情况下它的字节对齐也是 4。
.
(2)内存对齐的作用
1、提高系统读取性能
因为并不是每一个硬件平台都能够随便访问任意位置的内存的。不少平台的 CPU,比如 Alpha IA-64、MIPS 还有 SuperH 架构,若读取的数据是未对齐的(比如一个4字节的 imt 在一个奇数内存地址上),将拒绝访问或抛出硬件异常。
.
2、避免不同系统的内存对齐方式不同,导致交互兼容性问题而发生错误
考虑到CPU处理内存的方式(32位的X86 CPU,一个时钟周期可以读取4个连续的内存单元,即4字节)使用字节对齐将会提高系统的性能(也就是 CPU 读取内存数据的效率)。比如将一个 it 放在奇数内存位置上,想把这4个字节读出来,32位 CPU 就需要两次。但按 4字节对齐之后一次就可以读出来了)。
.
(3)POD类型的内存大小
char a; // 1 byte
short b;// 2 bytes
int c;// 4 bytes
uint8_t d;// 4 bytes
uint16_t e;// 8 bytes
uint32_t f;// 16 bytes
uint64_t g;// 32 bytes
long long h;//bytes8
.
(4)内存对齐原则
对齐原则
(1)原则1: 数据成员对齐规则:结构(struct或联合union) 的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员obj存储的起始位置要从该成员obj大小的整数倍开始(比如int在32位机为 4字节,则要从4的整教倍地址开始存储,shot是2字节,就要从2的整数倍开始存储)
(2)原则2:结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整教倍地址开始存储。(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储。)
(3)原则3:收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的整教倍,不足的要补齐,如果是结构体B包含了结构体A对象a,判断最大成员时并不是a,而是a结构体的最大成员。
因为有了内存对齐,所以数据在内存中的存放就不是紧挨着的,而是会出现一些空隙(Data Structure Padding,也就是用于填充的空白内容)。
struct MyStruct{
char a; // 1 byte
int b; // 4 bytes
short c; // 2 bytes
long long d;// 8 bytes
char e; //1 byte
}
MyStruct 中有 5 个成员,如果直接相加大小应该是 16,但在32位 MSVC 中它的 sizeof结果是 32。结果之所以出现偏差,是因为为了保证这个结构体中的每个成员都应该在它对齐了的内存位置上,而在某些位置插人了 Padding。
为了保证成员各自的对齐属性,在 char 和 int 之间及 short 和 longlong 之间分别插人了一些 Padding
struet Mystruet
{
char a; //1 byte
char pad 0[3]; // Padding 3
int b; // 4 bytes
short c; // 2 bytes
char pad 1[6]; // Padding 6
long long d; // 8 bytes
char e; //1 byte
char pad 2[7]; // Padding 7
}
注意,上述加了 Padding 的结构体,e 的后面还跟了7字节的填充。这是因为结构体的整体大小必须能被对齐值整除,所以“char e”的后面会被继续填充 7 个字节,好让结构体的整体大小是 8 的倍数 32。我们可以在 gcc+32 位 Linux 中尝试计算 sizeof(MyStruct),得到的结果是 24。这是因为 gcc 中的对齐规则和 MSVC 不一样,不同的平台下会使用不同的默认对齐值。在 gcc+32 位 Linux 中,大小超过4字节的基本类型仍然按4字节对齐。
.
(5)堆内存的内存对齐_aligned_malloc/memalign
在 MSVC 下应当使用 _aligned_malloc,而在 gcc 下一般使用 memalign 等函数
实现一个简易的aligned_malloc

.
(6)利用alignas 指定内存对齐大小
有时我们希望不按照默认的内存对齐方式来对齐,这时,可以用 alignas 来指定内存对齐的大小。
下面是 alignas 的基本用法
alignas(32] long long a = 0;
#define XX 1
struct alignas(XX) MyStruct_1 {}; // OK
template <size t YY = 1>
struct alignas(YY] MyStruct_2 {}; // OK
static const unsigned ZZ = 1;
struct alignas(Zz) MyStruct 3 {}; // OK
alignas(int) char c; // OK
注意,对 MyStruct 3 的编译是没问题的。在 C++11 中,只要是一个编译期数值 (包括static const)都支持 alignas。
另外,需要注意的是 alinas 只能改大不能改小”。如果需要改小,比如设置对齐数为1.仍然需要使用 #pragma pack。或者,可以使用 C++11 中与 #pragma 等价的物 Pragma (微软暂不支持)
(6)利用pragma指定内存对齐大小
#pragma pack作用
使结构体按x字节方式对齐
#pragma pack用法
#pragma pack (1)
...
#pragma pack ()
举例
//c语言
#pragma pack(1)
struct sample
{
char a;
double b;
};
#pragma pack()
若不用#pragma pack(1)和#pragma pack()括起来,则sample按编译器默认方式对齐(成员中size最大的那个)。即按8字节(double)对齐,则sizeof(sample)==16.成员char a占了8个字节(其中7个是空字节);若用#pragma pack(1),则sample按1字节方式对齐sizeof(sample)==9.(无空字节),比较节省空间,有些场和还可使结构体更易于控制。
//C++11
_Pragma("pack(1)")
struct MyStruct
{
char a; //1 byte
int b; // 4 bytes
short c; // 2 bytes
long long d;// 8 bytes
char e: //1 bytes
}
_Pragma("pack()")
(7)利用alignof和std::alignment_of 获取内存对齐大小
作用
std::alignment of 的功能是获取编译器计算类型的内存对齐大小 。alignof 用来获取变长放入内存对齐大小
alignof 的基本用法
MyStruct xx;
std::cout << alignof(xx) << std::endl;
std::cout << alignof (MyStruct) << std::endl;
举例
struct MyStruct
{
char a;
int b;
double c;
}
int main()
{
int alignsize m std::alignment of<MyStruct>::value; //8
int sz = alignof(MyStruct); //8
return 0;
}
(8)内存对齐使用场景
1、不同运行设备的的通讯,数据包对齐解包,保证发包和解包的内存大小一致
2、eigen的数据类型接口使用,eigen的数据类型默认都是16字节对齐的
.
(9)总结
C++11 为我们提供了不少有用的工具,可以让我们方便地操作内存对齐,但是在堆内存方面,我们很可能还是需要自已想办法。不过在平时的应用中,因为很少会手动指定内存对齐数到大于系统默认的对齐数,所以也不必每次 new/delete 的时候都提心吊胆。
13、动态内存申请与释放
堆空间是存放临时用的数据,如局部变量。一般来说,一些大数据或大的全局对象会申请栈空间,并使用指针进行操作。
注意 # include<stdlib.h> 指令把 stdlib.h 头文件包含到程序中。
(1)C使用malloc与free操作栈空间
用malloc函数开辟动态存储区
其函数原型为
void *malloc(unsigned int size);
在内存的动态存储区分配一个长度为size的连续空间,形参size的类型为无符号整形
malloc(100); // 开辟100字节的临时分配域,函数值为其第一个字节的地址
用calloc函数开辟动态存储区
其函数原型为
void *calloc(unsigned n,unsigned int size);
在内存中分配n个长度为size的连续空间
p=calloc(50,4); // 开辟50x4个字节的临时分配域,把起始地址赋给指针变量p
用realloc函数重新分配动态存储区
其函数原型为
void *realloc(void *p,unsigned int size);
如果已经通过 malloc 或 calloc 函数获得了动态空间,想改变大小,可以用 recalloc 函数重新分配。
recalloc(p, 50); // 将p所指向的已分配的动态空间改为50字节
用free函数释放动态存储区
其函数原型为
void free(void *p);
其作用是释放指针变量 p 所指向的动态空间,使这部分空间能重新被其他变量使用。p 应是最后一次调用 calloc或 malloc 函数时得到的函数返回值。如:
free(p); // 释放指针变量 p 所指向的已分配的动态空间
free 函数无返回值。
(2)C++使用new和delete操作栈空间
.
.
六、C++内置库支持【库->API】
1.内置库和API函数的关系
.
2.std、STL库及其API函数
(1)【数据结构类】
(1)std::vector
1、std::vector的介绍
vector可以理解为动态数组,其特点和基本操作方式与array相似,但vector可以动态调整大小。
vector中的元素是连续存储的,这意味着我们不仅可以通过迭代器std::vector::iterator,还可以像array一样使用下标来访问任意位置的元素
2、vector支持的基本操作
1.vector的初始化及赋值
2.vector中插入元素
3. vector删除元素
4. vector查看容量与大小:size()函数是检查动态数组有多少个成员的数量的【防盗标记--盒子君hzj】
5. 自定义类的排序
参考
https://blog.csdn.net/qq_37653144/article/details/79242242
https://www.cnblogs.com/yxnchinahlj/archive/2011/03/06/1972435.html
https://blog.csdn.net/tpriwwq/article/details/80609371
(2)isnan()函数
snan() 判断是不是NAN值(not a number非法数字)
标准库中定义了一个宏:NAN来表示非法数字。比如负数开方、负数求对数、0.0/0.0、0.0* INFINITY(无穷大)、
INFINITY/INFINITY、INFINITY-INFINITY。注意:如果是整数0/0会产生操作异常
(3)isinf()函数
sinf()测试某个浮点数是否是无限大,其中INF表示无穷大
.
.
.
(2)【数据结构处理类】
(1).push_back()向列表等数据结构后面添加元素
(2)std_msgs::Float32是ROS中数据特有的,一般的C++就是用flaot代替
(3)用std的API ,cout,at,size等等
(3)【输入输出类】
(1)C语言:scan()/printf()
(2)C++语言:cint << XXX <<endl /cout << XXX <<endl
使用C++的cout和cin要包含iostream的头文件,#include<iostream.h>
在cout或者cin出现错误的时候,可能是C++标准导致的,改成std::cout << XXX <<std::endl
【防盗标记–盒子君hzj】
C++的输入流cin与输出流cout
#include 这个和cin \ cout有关,输入流与输出流
. ## 2.调试及显示的输入输出流 **(1)流的概念** 1、流有数据流、输入\输出流、视频流,程序流,流程图等等 2、输入流类比:程序指令输入,从键鼠到程序内部,这就是一个输入流,cin<<.....<< 3、输出流类比:屏幕显示输出,从程序内部到屏幕,这就是一个输出流cont<<......<<
(2)print和cout输出流(scan/cin输入流)的区别
print是面向过程的输出,本质是一个函数
cout是面向对象的输出,本质是一个类(输出流对象)
【防盗标记–盒子君hzj】
(3)输出流对象常用的功能函数
cin.ignore(7) 忽略输入的前7个字符
cin.getline(buf,10) 只取输入的10个字符,存放在buf的数组(缓冲区)里
cin.gcout() 检测输入了多少数目的字符
cin.read(buf,10) 只取输入的10个字符,存放在buf的数组(缓冲区)里
cout.write(buf,10) 从缓冲区输出了10个数目的字符
(4)输出流对象常用的用法
cout<<buf<<endl;其中endl是回车加上清空的作用
cout<<buf<<“\n";其中\n是分行符
cout<<“直接输出一段文本”
cout.weith(10);按10个字符分隔输出
cout.persion(10);按10个小数点进行输出
.
.
(4)【算数运算类】
1)fabs()
求绝对值的方法
2)sqrt()
求平方运算
3)Hypot(x,y,z)
欧式两点距离计算【防盗标记–盒子君hzj】
4)norm()
norm()函数是C ++ STL中的内置函数,在头文件中定义。 norm()函数用于获取复数的范数。复数的范数是数字的平方大小
norm()函数是计算两点间的距离的平方,即向量的模平方
例子
【计算原点(0,0)到点(3,4)的距离】
K>> norm([3 4])
ans =25
5)std::floor()和std:ceil()
std::floor 和 std::ceil都是对变量进行四舍五入,只不过四舍五入的方向不同
std::floor -->向下取整数【std::floor(5.88) = 5;】
std::ceil -->向上取整数【std::ceil(5.88) = 6;】
6)dot()函数
向量或者是矩阵的点乘
设A(2 * 3), B(3 * 4), 那么dot(A, B)就表示两个矩阵相乘
.
.
(5)【文件读取类】
C++文件读取需要包含相关的std库
1)Std::ifstream()
读取文件的整个内容
.
2)Std::Isstringstream()
读取文件的第XXX行
.
3)Std::getline()
读取文件某一行的所有元素【防盗标记–盒子君hzj】
.
3.文本读写权限操作及库解释
1)标准库
#include<iostream>这个库是输入输出流的库
#include<stream>这个库是字符串的库,调用如:std::stream str
这些标准库的**内建功能**非常多,百度一下,绝大部分的功能都能实现的如
--提取字符串
--比较字符串
--添加字符串
【防盗标记--盒子君hzj】
--搜索字符串
2)传入参数argc\argv[]
argc:整形变量,含义是传入程序的参数数量,包含本身
argv[]:字符指针数组,含义是对应指针指向的文件
3)文本操作
ifstream in(char*filename,int open_mode)
--ios::in 其中ios是命名空间,只可读取文件
--ios::out 只可写入
--ios::binary 以二进制文件打开(如exe文件,还有一种形式文本形式)
--ios::app 在文件末尾追加一个写入的所有数据
--ios::trunk 删除所有文本的所有文件
--“|”用这个分隔符,同时实现多种打开方式,因为in\out这些指令是枚举变量,事先已经由默认值了
(::前面是一个命名空间,后面是他对应的函数)
.
4.C++ 11 实现实现多进程、多线程
转战一下我这篇文章
https://blog.csdn.net/qq_35635374/article/details/132029314
.
5.C++ 11实现处理日期和时间的chrono库
chrono 库主要包含 3 种类型: 时间间隔 duration、时钟 clocks 和时间点 time point。我们可以根据 chrono 库提供的 duration、clocks 和 time point 来实现一个 timer,方便计算时间差。
(1)时间间隔 duration
1、功能
duration 表示一段时间间隔,用来记录时间长度,可以表示几秒、几分钟或者几个小时的时间间隔
2、duration 的原型实现
template<
std::intmax t Num,
std::intmax t Denom = 1
> class ratio;
template<
class Rep,
class Period = std::ratio<1,1>
> class duration;
第一个模板参数 Rep 是一个数值类型,表示时钟数的类型;第二个模板参数是一个默认模板参数std::ratio,表示时钟周期。ratio第一个模板参数Num代表分子,Denom 代表分母分母默认为 1,因此,ratio 代表的是一个分子除以分母的分数值。
为了方使使用,标准库定义了些常用的时间间隔,如时、分、秒、毫秒、微秒和纳秒,在 chrono 命名空间下,它们的定义如下
typedef duration <Rep,ratio<3600,1>> hours;
typedef duration <Rep,ratio<60.1>> minutes;
typedef duration <Rep,ratio<1,1>> seconds;
typedef duration <Rep,ratio<1,1000>> milliseconds;
typedef duration <Rep,ratio<1,1000000>> microseconds;
typedef duration <Rep,ratio<1,1000000000>> nanoseconds;
3、应用场景
1)线程的休眠
std::this thread;:sleep for(std::chrono::seconds (3)); // 休眠3秒
std::this thread;isleep for(std::chrono:: milliseconds (100));//休眠100 毫秒
2)计算两端时间间隔的差值
std::chrono::minutes t1( 10 );
std::chrono::seconds t2( 60 );
std::chrono::seconds t3 = t1 - t2;
std::cout << t3.count() << " second" << std::endl;
其中,t1 代表 10 分钟、t2 代表 60 秒,t3 则是 1 减去2,也就是 600-60=540 秒。
值得注意的是,duration 的加减运算有一定的规则,当两个 duration 时钟周期不相同的时候,会先统一成一种时钟,然后再作加减运算。
.
.
(2)时间点 time point
1、作用
time point 表示一个时间点。time point 必须用clock 来计时。
2、应用场景
1)计算从它的 clock 的纪元开始所经过的 duration
//计算当前时间距离 1970年1月1日有多少天的示例。
finclude <iostream>
finclude <ratio>
finclude <chrono>
int main ()
{
using namespace std::chrono;
typedef duration<int,std::ratio<60*60*24>> days type;
time_point<system clock,days type> today =time point cast<days type(system clock::now());
std::cout << today.time_since_epoch().count() << " days since epoch" <<std::endl;
return 0;
}
2)计算当前的时间
3)计算一些时间点的比较和算术运算
4)和ctime 库结合起来显示时间
//输出前一天和后一天的日期。
#include <iostream>
#include <iomanip>
#include <ctime>
#include <chrono>
int main()
{
using namespace std::chrono;
system clock::time point now = system clock::now();
std::time t last = system clock::to time t(now - hours(24));
std::time t next= system clock:;to time t(now - hours(24));
std::cout << "One day ago, the time was "<< std::put time(std::localtime(&last),"") <<'\n';std::cout << "Next day, the time is "<< std::put time(std::localtime(next)," T") <<i\n';
}
输出如下
One day ago,the time was 2014-3-2622:38:27
Next day,the time is 2014-3-2822:38:27
.
(3)时钟 clocks
1、作用
clocks 表示当前的系统时钟,内部有 time_point、duration、Rep、Period 等信息,主要用来获取当前时间,以及实现 time t和 time point 的相互转换。
.
2、时钟类型
system_clock:
代表真实世界的挂钟时间,具体时间值依赖于系统。system clock 保证提供的时间值是一个可读时间。
steady_clock:
不能被“调整”的时钟,并不一定代表真实世界的挂钟时间。保证先后调用 now0得到的时间值是
不会递减的。
high resolution clock:
高精度时钟,实际上是 system clock 或者 steady clock 的别名
.
3、使用场景
1)可以通过 now() 来获取当前时间点
#include <iostream>
#include <chrono>
int main()
{
std::chrono::system clock::time point t1 =std::chrono::system clock::now();
std::cout << "Hello World\n";
std::chrono::system clock::time point t2 =std::chrono::system clock::now();
std::cout << (t2-t1).count()<<"tick count"<<std::endl;
}
输出如下:
Hello World
97tick count
通过时钟获取两个时间点之间相差多少个时钟周期,我们可以通过 duration cast 将其转换为其他时钟周期的duration:
std::cout <
<std::chrono::duration cast<std::chrono:microseconds>(t2-t1).count) <<"tickcount"microseconds"<<std::endl;
输出结果
20 microseconds
.
(4)实现timer计时器
1、作用
可以利用 high resolution clock 来实现一个类似于 boost.timer 的计时器。
.
2、timer计时器的实现
#include<chrono>
using namespace std;
using namespace std::chrono;
class Timer
{
public:
Timer() : m_begin(high resolution clock::now()) {};
void reset() { m_begin = high resolution clock::now(); }
// 默认输出毫秒
template<typename Duration=milliseconds>
int64 t elapsed() const
{
return duration cast<Duration>(high resolution clock::now()-m begin).count();
}
// 微秒
int64 t elapsed micro() const
{
return elapsed<microseconds>();
}
//纳秒
int64_t elapsed nano() const
{
return elapsed<nanoseconds>();
}
// 秒
int64 telapsed seconds() const
{
return elapsed<seconds>();
}
// 分
int64 telapsed minutes () const
{
return elapsed<minutes>();
}
// 时
int64 t elapsed hours() const
{
return elapsed<hours>();
}
};
.
3、使用场景
1)测试函数的性能
void fun()
{
cout<<"hello word"<<endl;
}
int main()
{
Timer t; // 开始计时
fun ();
cout<<t.elapsed()<<end1;// 默认,打印 fun 函数耗时多少毫秒
cout<<t.elapsed micro.(<<endl;// 打印微秒
cout<<t.elapsed nano ()<<endl;// 打印纳秒
cout<<t.elapsed seconds ()<<endl;// 打印秒
cout<<t.elapsed minutes()<<endl;// 分钟
cout<<t.elapsed hours()<<endl;// 打印小时
}
auto current_tick = std::chrono::steady_clock::now();
std::chrono::duration<double, std::milli> elapsed{current_tick -
last_check_tick};
last_check_tick = current_tick;
MCU_LOG("Nav period is %f ms", elapsed.count());
(5)tick的局部计时
优势就是代码段暂停,计时自动暂停,对业务暂停恢复的功能很友好
.
(6)boost库可以实现相关的功能
(7)系统时间统计集成接口
inline uint64_t getSystemTickTime() {
//Linux中的system_clock时间会跳变甚至倒流,可能导致导航出现异常行为,要使用std::chrono::steady_clock
// return std::chrono::time_point_cast<std::chrono::milliseconds>(
// std::chrono::system_clock::now())
// .time_since_epoch()
// .count();
return std::chrono::time_point_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now())
.time_since_epoch()
.count();
}
inline uint64_t getSystemTickTimeDiffMs(uint64_t tick_from, uint64_t tick_to) {
if (tick_to >= tick_from) return tick_to - tick_from;
uint64_t next_loop_tick_to = tick_to + UINT64_MAX;
return next_loop_tick_to - tick_from;
}
(8)使用注意
1、steady_clock 是单调的时钟,相当于教练手中的秒表; 只会增长,适合用于记录程序耗时:
2、system_clock 是系统的时钟,因为系统的时钟可以修改,甚至可以网络对时,所以用系统时间计算时间差可能不准。
3、high _resolution_clock 是当前系统能够提供的最高精度的时钟,它也是不可以修改的。相当于 steady_clock 的高精度版本
.
.
七、C/C++语法避坑
(1)声明非类对象的成员函数和变量,若没有命名空间namespace限制,尽量不要在.h头文件中,在源文件即可,
目的:
(1)避免头文件相互包含且出现同一变量的时候容易发生冲突或者调用混乱
(2)避免增加变量命名空间所占用的内存
(3)限制变量和函数的使用范围,限制调用函数的对象
.
(2)尽量不要在if、while(for)语句中定义变量
在if、while(for)语句中定义变量,不会被编译的,但是可以在全局和函数局部中定义变量
解决办法:条件允许情况下,在离if/while最近的地方定义对象。占用不了太大的内存的~
.
(3)使用条件语句,有if就尽量配一个else,有switch就尽量配一个default
每个if尽量都要配一个else,同理用switch时尽量都要配一个default
不然逻辑出问题,debug就很难定位出问题,在重要且不频繁的调用的条件语句中,最好埋点打印一些log
.
(4)int类型在不同的计算机长度是不一样
int类型在不同的计算机长度是不一样的,一般要指定int_8、int_16、int_32、int_64等等
.
.
(5) 浮点数不能判断==相等
错误的用法示例
if ((startPose.point_.x() == tarPose.point_.x()) &&
(startPose.point_.y() == tarPose.point_.y())) {
return;
}
正确的用法是两个浮点数做差,差的绝对值小于小数点后三位或者四位就代表相等
(6)全局变量要慎用,全局标志位也要慎用管理好标志位各种情况的生命周期
.
(7)能用const和static的变量,不要用#define,就算用#define也要加上括号()进行修饰;
能用静态变量static,也不要用define
.
(8)switch case 的break使用
结论:case和break不绑定使用,当一个case满足条件,后面的case不需要判断,可以直接执行,注意这个设计会影响状态机的扭转
找到适合的case前不执行,找到对应case后都执行,直到遇到break或者switch语句结束!
首先看下正确的写法:
int main()
{
int i;
for(i=0;i<3;i++)
{
switch(i)
{ //switch语句一定加大括号
case 0: //注意格式 case 0: 这里不用加大括号
cout<<i;
break; //每个case后要break
case 2:
cout<<i;
break;
default:
cout<<i;
break;
}
}
system("pause");
return 0;
}
程序输出是:012
加break的意思是说,找到合适的case执行后,下面的case就不再执行,而是退出当前switch语句。
.
case和break不绑定使用示例
int main()
{
int i;
for(i=0;i<3;i++)
{
switch(i)
{
case 0:
cout<<i;
case 2:
cout<<i;
default:
cout<<i;
}
}
system("pause");
return 0;
}
程序输出是000122
int main()
{
int i;
for(i=0;i<3;i++)
{
switch(i)
{
case 0:
cout<<i;
case 2:
cout<<i;
break;
default:
cout<<i;
}
}
system("pause");
return 0;
}
程序输出是0012
.
八、、防御式编程
1、主函数都要有return
因为return是用来推出程序并返回错误信息的,其中return 0代表程序运行没有问题
.
2、合法性检查–检查的是数据类型及是否为null、变量取值范围(正负数、特定值)、参数个数等
要对数据的输入输出做合法性检查(特别是用户输入的数据),以免输入错误及系统崩溃,检查的是数据类型和取值范围(正负数、特定值)、参数个数等等
这样做事比较耗内存,但是大大增加了程序的健壮性(减少缓冲区溢出的问题)
解决办法:
1、使用switch语句检查特定值
2、用if语句做范围限幅
【防盗标记–盒子君hzj】
.
3、发布出去的程序都要做压力测试
–有时候内存不够大也会出错
–或者缓冲区不够大
–或者数据类型不对应【重载能够解决】
–狂按enter键,触发了后面的程序(小孩子)
–系统的应用软件崩溃检查
.
4、程序越简化越好–用封装来整理架构和控制风险
–面对过程的把实现过程封装起来
–面对对象的把对象封装起来
–面对模块的把组件和一个一个程序文件封装起来
封装程度越高,越高级的程序语言,运行效率越低,要求的硬件越高 (因为要考虑通用性,会预先定义很多东西)
.
6、要用的变量最好先初始化一遍,避免随机初始化
特别是类内变量,用参数列表进行初始化
.
7、强制转换时在该变量前加一个(数据类型),如(float)a
.
8、设计程序要考虑通用性(以后可以偷懒)、预错性
【程序看起来成熟很多 ,不能只考虑仅仅实现功能】
【防盗标记–盒子君hzj】
–常用的常量可以用宏定义定义起来,方法一:#define【在函数外】 方法二:const【在函数内】(一改全改)
–检测输入cin是正常的,如果cin为非正常值得时候是0,如:std::cin<<a
.
9、访问数组先进性数组的长度检查
10、申请内存和释放内存的操作,进行步骤绑定,避免漏了一些步骤
如定义指针必须指向地址,释放指针必须释放内存(除非是动态内存)
11、函数的指针和引用,能加const就加上const
参考资料
c/c++格式规范参考ROS规范
http://wiki.ros.org/CppStyleGuide
待整理
嵌入式可以调整编译优先级,提高运行效率
1、编译优化等级导致运行崩溃
2、强制类型转换导致崩溃
浅拷贝和深拷贝的定义及使用场景与方法(C++)
在C++文件加入C文件extern “C”
如果要对编译器提示使用C的方式来处理函数的话,那么就要使用extern "C"来说明
在C文件加入一下代码
//模板
#ifdef __cplusplus
extern "C" {
#endif
//一段代码
#ifdef __cplusplus
}
#endif
//示例
#ifndef _CORTEXM_BACKTRACE_H_
#define _CORTEXM_BACKTRACE_H_
#include "cmb_def.h"
#ifdef __cplusplus
extern "C" {
#endif
void cm_backtrace_init(const char *firmware_name);
void cm_backtrace_firmware_info(void);
size_t cm_backtrace_call_stack(uint32_t *buffer, size_t size, uint32_t sp);
void cm_backtrace_assert(uint32_t sp);
void cm_backtrace_fault(uint32_t fault_handler_lr, uint32_t fault_handler_sp);
uint8_t cmbackTraceFlashInfoUpdate(void);
#ifdef __cplusplus
}
#endif
#endif /* _CORTEXM_BACKTRACE_H_ */
c和C++混合编程方法
https://blog.csdn.net/lbzhao_28/article/details/3159598
https://blog.csdn.net/minyangchina/article/details/4760257
整理代码的方法
1、拼写错误。
2、代码格式。
3、参考谷歌编程规范要求。
.
auto关键字的使用
对于复杂的变量类型,我们可以用auto来代替简化,这是c11的特性
.
数值后带f应为float类型
const double boundary_threshold = 0.3f;//这样命名的就是有错
.
变量命名
const变量使用k+驼峰命名法
一般的变量全小写,下划线分开
全局变量后面加上下划线
信念–C/C++语言的语法问题一定都是可以解决的!
算法和逻辑问题才是不可解决的!
ROS C++编程规范
https://blog.csdn.net/Travis_X/article/details/87968746
编程习惯
1、可以抽象成一个小的子功能的代码段要封装成为一个函数
2、代码一般超过20行的要封装成一个函数
3、编程多用心,小细节修好了在给别人,按照编程规范来(没可能一口气编的很好的)【修改编程规范】
写代码的心态
1、写代码就好像写作文一样,有框架有细节!按着自己的思路一步一步往下写!不要急想清楚处理的方法(不懂就学,即学即用)
2、软件开发过程中要写todo记录进度和readme使用方法
3、自己写的代码的设计流程和要调节的参数,还是要背一背记住在心里面的熟悉形成条件反射的
4、代码除了算法本身外,更多的是业务逻辑和程序流程逻辑,都是可以通过放置标志位flag慢慢捋找出问题的
5、工程是实地测试,针对效果,一个一个问题进行优化的!















 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











