




https://github.com/walsvid/Awesome-MVS
https://github.com/XYZ-qiyh/Awesome-Learning-MVS (基于深度学习的MVS)
现在发觉深度估计可以分为单目深度估计,双目深度估计(立体匹配),多目立体匹配(MVS)。而MVSNET属于多目深度估计,似乎不是双目深度估计,双目深度估计似乎也有一些专门的深度学习方法。现在感觉可以感受到一点,就是不管是单目深度估计还是双目深度估计还是多目立体匹配 都基本全面转向深度学习了。
我看到对MVS概括得最多而且简单的一句话是:寻找空间中具有图像一致性的点。 很多地方都看到了这句话,我个人感觉意义没那么大,说了似乎根没说一样。
多目立体匹配的前世今生 https://mp.weixin.qq.com/s/cfnzxaFffNAX1Hcmzn5slQ 这篇文章可以好好看看,我觉得对基于深度学习的MVS总结得很全面。
这个视频感觉也讲得系统全面,配合3D视觉工坊的视觉三维重建一起看会很有感觉,都是对传统MVS系统的概述。
【多视图像三维重建技术概述-哔哩哔哩】 https://b23.tv/HrMpyD8
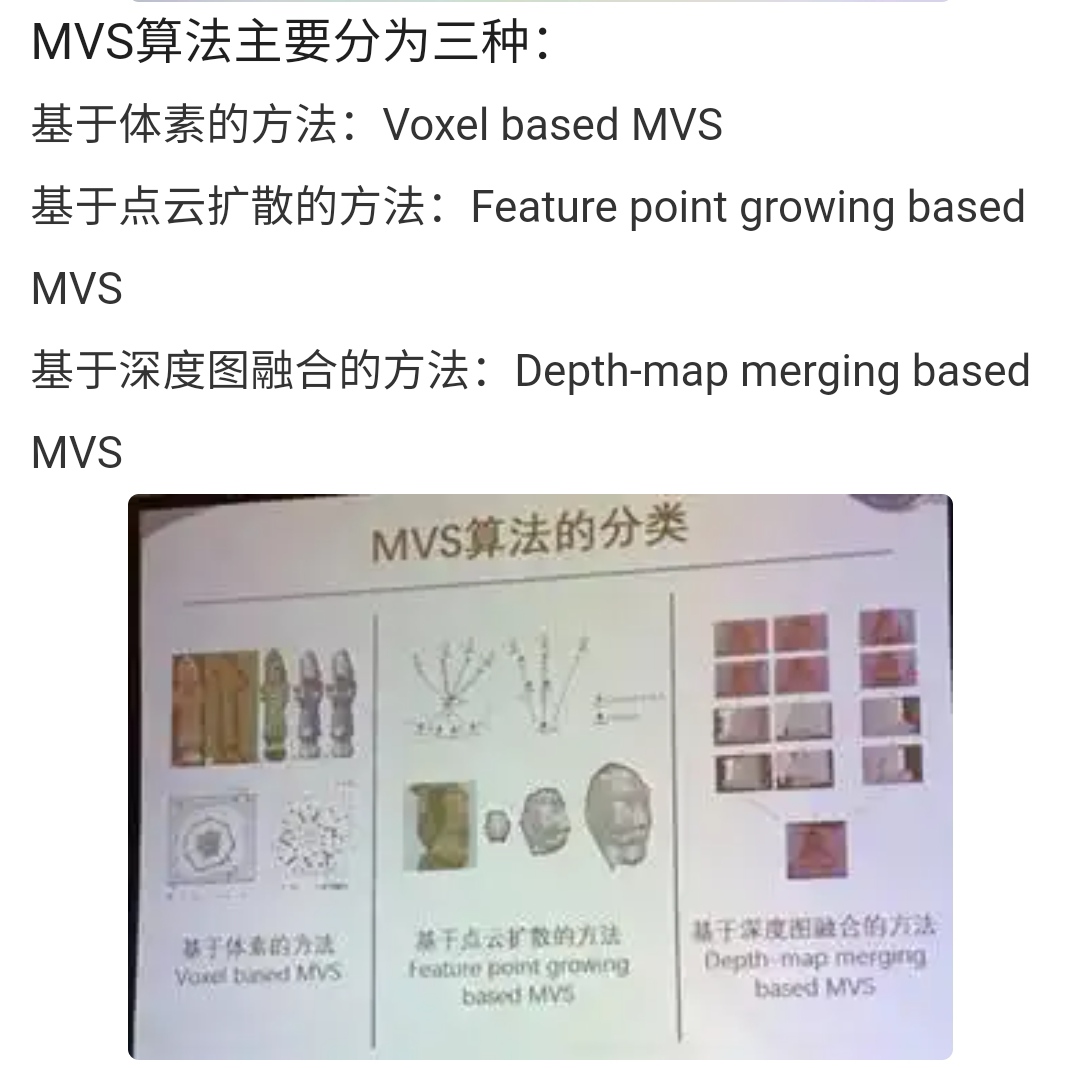
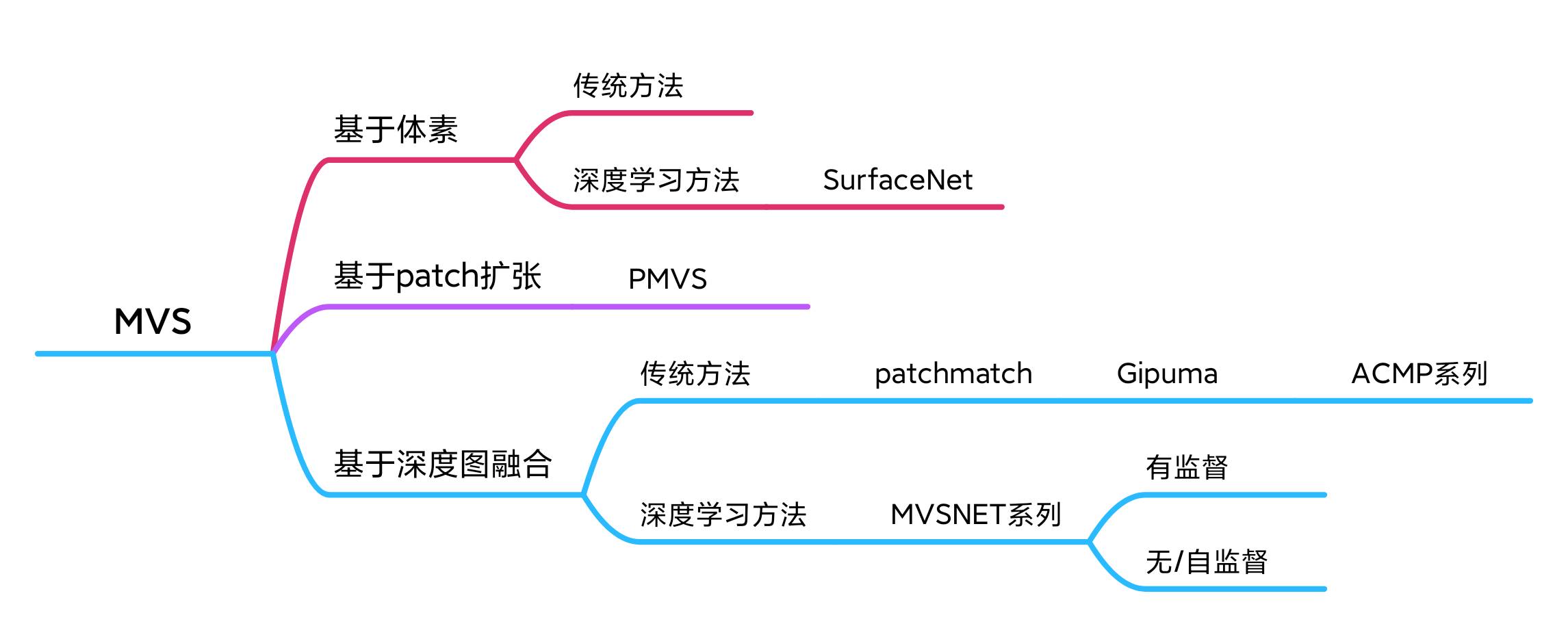
关于MVS方法分类
深蓝学院的基于图像的三维重建课程里给了三种,基于体素,基于patch扩张(这个方法也叫PMVS,是09年的一个工作,现在也有开源的代码),基于深度图融合

3D视觉工坊的MVSNET课程里面给了三种,同时课程讲师说:
现在主要是第三种,深度图融合主导。
方法二(体素)相当于某种程度上对方法一(点云)的改进 第三种想从根上把前两种方法的问题解决掉。方法三更易用,也应用更广。占用内存没有那么多。当然没有哪种方法是绝对的最好。
这里也看到说深度图融合是主要的方法 https://blog.csdn.net/weixin_41109672/article/details/108179922

https://www.360doc.cn/article/41357686_710307158.html
再进一步看发现它说的基于点云的扩张其实就是深蓝学院基于图像的三维重建课里面说的基于patch的扩散,好像也就是3D视觉工坊MVSNET课程里面说的基于点云的方法,底下解释不也是说扩散了么,看来可能都是一个意思,只是有点叫patch,有的叫点云,有的叫特征点,但都是扩散。
这里说的基于特征点扩散的MVS就是指PMVS算法,PMVS算法也就是对应着基于patch扩张的方法,这两个说的一个东西,PMVS里面也确实是要通过Harris和DoG算子提取出特征点,PMVS的算法细节可以见https://zhuanlan.zhihu.com/p/438232198?utm_id=0

这篇PlaneMVS论文(https://blog.csdn.net/qq_44930684/article/details/129228354 )里有写:传统的MVS方法大致可以分为基于体素的方法[27,41]、基于点云的方法[10,28]和基于深度映射的方法[3,11,50]。
patchmatchNet的论文里面有写:传统MVS方法可划分为四种:基于体素的,基于曲面估计的,基于patch的,基于深度图的。基于深度图的方法更简洁灵活。https://blog.csdn.net/chetttt/article/details/113781291
下面摘自论文 DP-MVS:一种针对大场景的保细节高精度三维重建方法 https://zhuanlan.zhihu.com/p/493723841?utm_id=0 看来很多论文里面就有对相关工作的总结整理。
目前多视图重建根据技术路线的不同,可以分为四类:基于体素融合的三维重建、基于表面演化的三维重建、基于区域增长的多视图重建和基于深度融合的多视图重建。
1)基于体素融合的三维重建
此类方法首先构建一个代价立方体,每个体素的代价通过图像块的光度一致性进行评价[1],往往还会加入局部平滑正则项,通过graphcut求解[2]。方法[3]通过光度一致性代价对体素进行自适应划分,一定程度缓解了体素分辨率不高的问题。但整体上,该类方法只能用于小物体的重建,无法适用大场景。由于需要构造代价立方体,对计算和内存资源的需求也较大。
2)基于表面演化的三维重建
基于表面演化的方法,从一个初始的表面开始,通过最小化面片的光度一致性,得到最优的物体表面。方法[4]提出一个形变模型框架,融合纹理和轮廓线索,优化物体的表面;方法[5]通过图割算法从稠密点云估计初始的物体表面,然后通过变分法优化物体的几何细节;方法[6]通过自适应分辨率控制的策略区分表面的显著区域,对非显著区域(比如平面)进行简化,从而加速模型优化的过程;方法[7]将多视图重建问题归纳为一个凸优化问题,从而不依赖初始化过程,但需要物体的轮廓作为约束。并且该方法用体素表达物体空间,不适于大场景重建。
3)基于区域增长的多视图重建
此类方法首先重建出纹理丰富区域的若干三维特征点,以这些三维点为种子点逐步扩展到弱纹理区域。代表性的方法是PMVS[8] ,其首先重建一些产生匹配关联的特征点对,然后迭代的对这些特征区域进行膨胀,同时过滤掉不满足可见性约束的匹配对。更早的方法[9]结合全局视图选择和局部逐像素视点选择估计深度,然后扩展到邻域图像。
4)基于深度融合的多视图重建
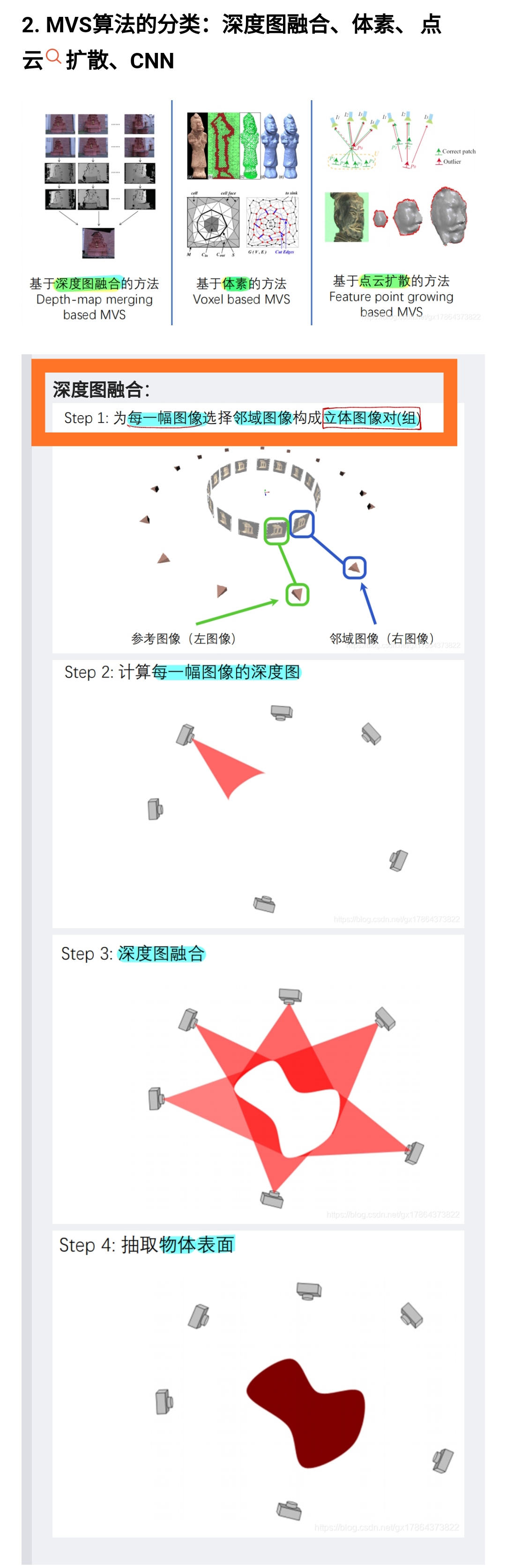
此类方法首先估计每张图像的深度,然后融合所有视角的深度,获取完整的点云和模型。这类方法以基于块匹配的方法最为普遍,由于不需要构建代价立方体,因此能够处理高分辨的图像,同时借助GPU的高并行能力,深度估计也可以做的较为高效。因此,此类方法最常用于大场景的多视图重建任务。该类方法主要包含三个模块:随机初始化、深度传播和局部优化。基于块匹配的方法根据其并行能力的不同,又可以分为基于序列式传播的块匹配方法和基于棋盘格式传播的块匹配方法。比较典型的基于序列式的块匹配方法如方法[10]和[11],后者是对前者方法的改进,除了深度图之外,其同时估计法线图和点的可见性;基于棋盘格的块匹配方法如[12],该类方法把图像像素分为红黑两类,每次迭代同时更新红色或黑色的像素,突破了序列式传播的局限,能够更充分的发挥GPU的高并行能力。这类方案最近几年得到迅速发展,如ACMM[13]采用由粗到精的策略,改善弱纹理的重建效果。ACMP[14]借助平面先验,TAPA-MVS[15]借助超像素分割改善弱纹理的重建效果,每个超像素块考虑为一个平面区域。以上这些方法,尽管取得了不错的效果,但细节结构的重建,仍然是一个充满挑战的问题。另外一些基于深度学习的方案,如[16-22],尽管在一些基准测试集上取得了不错的成绩,但其泛化性和大场景下的可扩展性,仍然存在问题,并且由于这类方法往往需要集成局部平滑的先验,细节的保持甚至还不如传统方法。
传统MVS的方法可以分成两种:区域增长(region growing)和深度融合(depth-fusion)。https://zhuanlan.zhihu.com/p/112103579?utm_id=0
这是西安交大19年的一个课件PPT里
https://gr.xjtu.edu.cn/c/document_library/get_file?folderId=2670378&name=DLFE-125650.pdf

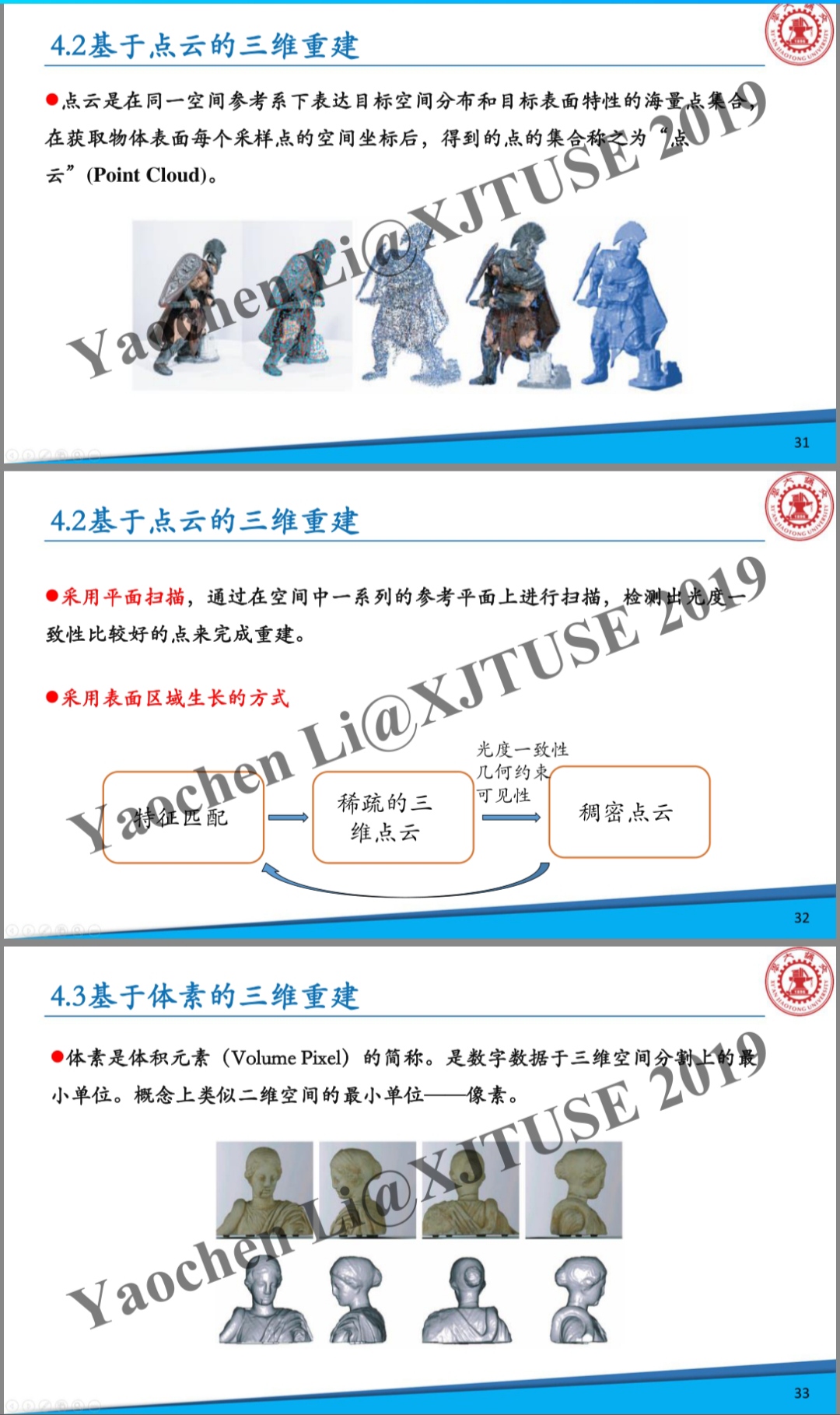
鲁鹏的《三维重建基础》这本书里面,多视图立体视觉那一章里面的分类是,可以看到也是这三种。

第8章多视图立体视觉129
8.1基于体素的方法129
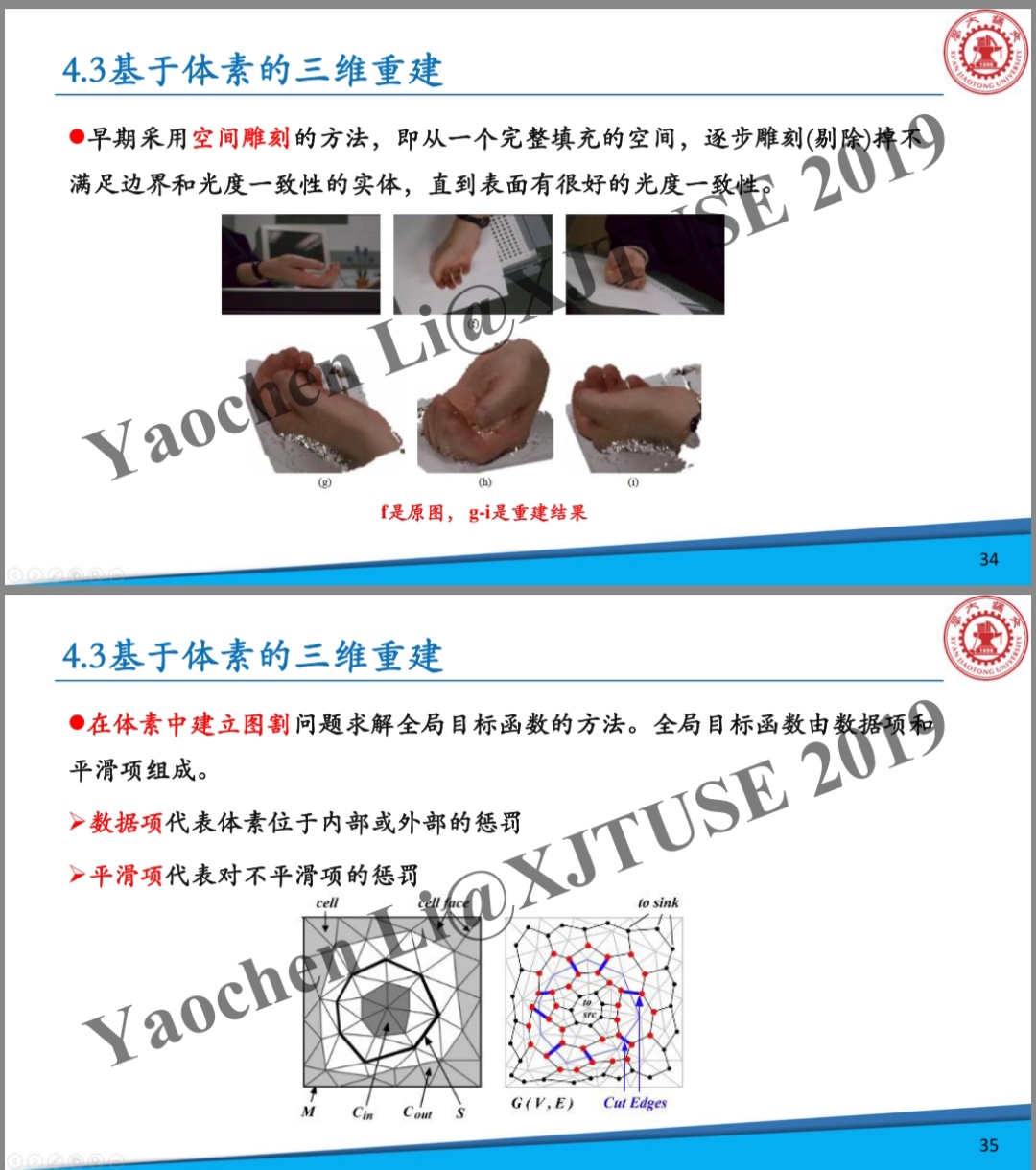
8.1.1空间雕刻法130
8.1.2阴影雕刻法136
8.1.3体素着色法139
8.1.4马尔可夫离散优化法141
8.2基于面片的多视图重建143
8.2.1基础知识144
8.2.2面片重建146
8.2.3总结150
8.3基于深度图的多视图重建150
8.3.1预处理151
8.3.2深度图生成153
8.3.3总结155
基于深度学习的MVS里面我有见到基于体素的也就是surfaceNet和基于深度图融合的也就是MVSNET,surfaceNet比MVSNET要早 但是大家比较喜欢MVSNET的框架所以基本都基于它进行的改进。
现在有点清楚深蓝学院基于图像的三维重建课里面说基于深度图融合的方法也是区域生长的意思了,只不过基于patch扩散的方法是在三维上扩散,深度图融合的方法是在二维图像上扩散,听了3D世界工坊的MVSNET老师doubleZ讲了Cas-ACMP后清楚的,基于深度图融合的方法核心还是在于深度估计,深度估计的时候也就是先估计出一个点再往周围扩散,是2D的扩散,现在也清楚了Cas-ACMP也属于基于深度图融合的方法,但是里面也有区域生长扩散的策略,现在可以理解了
这是目前(2014.1.21)听了真么多MVS的课,自己简略画的一个MVS的图。我也做些解释说明。
PMVS方法属于基于patch扩张的这类MVS方法里面,而且他们(深蓝学院的基于图像的三维重建课程)讲基于patch扩张的MVS方法时其实就是讲的PMVS算法,这个方法应该是一个经典的方法,ACMP的论文里面对比精度时对比对象之一也有PMVS。也注意PMVS和PM以及PMS不是一个东西PM是patchmatch,PMS是patchmatchstereo。
基于深度图融合这一类方法里面,传统方法里,我看讲得很多(doubleZ以及华科陶文兵的一个报告以及网上搜到的一些,提及ACMP的不少,3D视觉工坊的视觉三维重建课程讲colmap的patchmatch时就说到了ACMP)的就是基于patchmatch一路发展下来的系列算法,包括gipuma,再进一步改进的ACMP系列,华科的作品。COLMAP自己用的是patchmatch,所以可以看出和COLMAP对比某种意义上也是和patchmatch对比,怪不得ACMP论文结果对比里面没有写patchmatch,而且注意patchmatch也是双目立体匹配的基础方法。
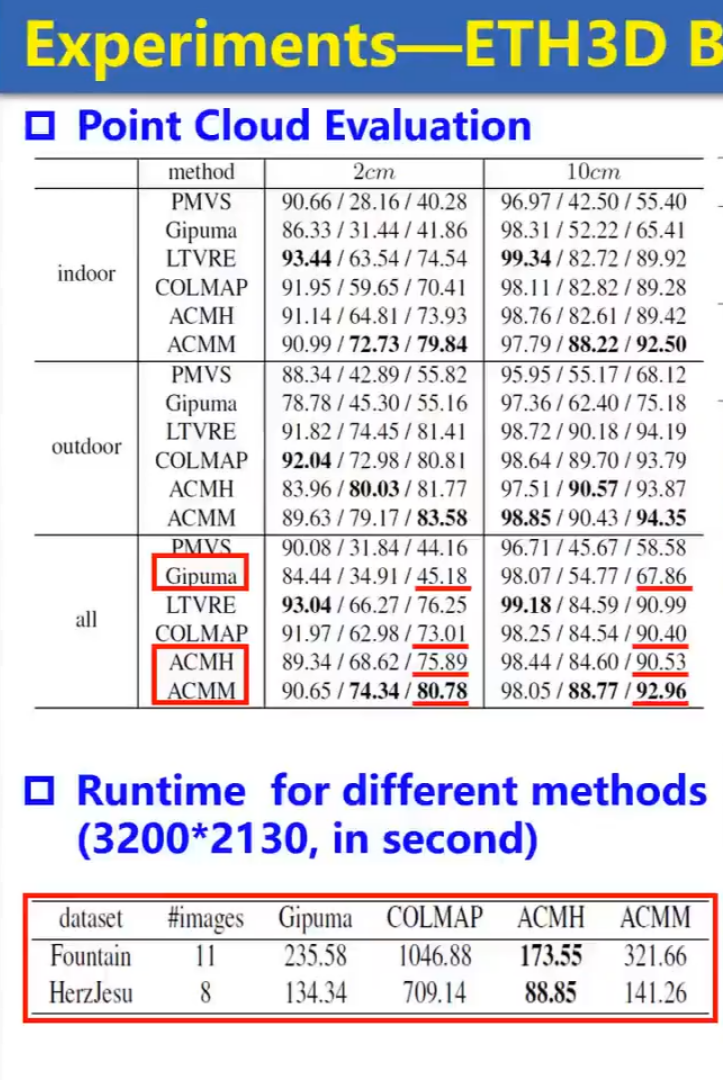
下图可以看到ACMM ACMH的对比对象,进而可以看出哪些是传统的基于深度图融合的MVS方法。
关于基于深度图方法中的传播策略
https://baijiahao.baidu.com/s?id=1696888954560877785&wfr=spider&for=pc&searchword=gipuma
改进的传播方式可以利用GPU并行加速,但是GPU的利用率不高,所以后面有出个ACMP,用红黑棋盘格的方式传播,这种传播方式对GPU利用率就比较高。 (我后来看到一篇文章有这方面的介绍 https://baijiahao.baidu.com/s?id=1696888954560877785&wfr=spider&for=pc&searchword=gipuma PatchMatchStereo在整个视差空间内进行搜索,既保证全局搜索的准确性,又提升了算法的效率。但其本身的传播策略无法极尽GPU效能,以至于PMS的立体像对视差估计速度比较慢。直到Gipuma等方法提出新的传播策略后,才使得GPU加速和PatchMatch算法在多视图立体中应用成为可能 )
下面PPT来自3D视觉工坊的视觉三维重建课程

在有RGBD的情况下如何直接进行MVS呢
对于基于深度图融合的MVS,我的理解就是得到每张RGB图对应的深度图,然后做融合,假设现在已经有RGBD相机或者深度相机,直接就可以拿到深度图了,这个时候如何进行一个实时的融合呢?对于D435i,我是不是只要找到一个实时的深度图融合方法,就可以进行实时的稠密重建了。这是否和RGBD SLAM有些交叉。
一种真正端到端的深度学习MVS
发现一种新的基于深度学习的三维重建,就是输入是图像或者是视频,输出直接是重建结果,比如是TSDF或者occupancy,真正的端到端,,把深度图融合也包含进去了,之前doubleZ也说了MVSNET不是真正的端到端。
下面这句话摘自simplerecon的论文 https://zhuanlan.zhihu.com/p/578361551?utm_id=0
传统上,基于posed图像的3D室内场景重建分为两个阶段:每幅图像的深度估计,然后是深度合并和表面重建。最近,出现了一系列直接在最终3D体积特征空间中执行重建的方法。
https://zhuanlan.zhihu.com/p/564442411?utm_id=0 TransformerFusion和特斯拉的occupancy network非常像
TransformerFusion是在NeuralRecon的基础上改进的。
TransformerFusion尝试使用transformer进行室内三维重建。作者使用视频+对应的姿态作为输入,对应的每一帧视频会被编码到代表场景的特征网格内,并解码为对应的三维场景表示。这一算法的关键在于,引入了transformer以更好的学习最重要的视频帧。同时特征学习遵循了由粗到细(course-to-fine)的过程,只存储精细特征,以节约所需的gpu内存。最后,区别于Atlas与NeuralRecon,使用了基于occupancy预测的方式(而非tsdf预测)来进行建模。
NeuralRecon-神经网络直接预测TSDF进行三维重建,直接重建局部窗帧的TSDF而不是估计每一帧的深度图再融合。https://zhuanlan.zhihu.com/p/446080211?utm_id=0
VoRTX使用一系列无顺序视频帧以及与之对应的姿态作为输入,同时学习对应的全局TSDF网格重建结果。
CVRecon
这些很多喜欢叫recon,recon就是reconstruction的简写,因为它们是真正的端到端的重建。
现在再看特斯拉的occupancy network就清晰了一些,但是我不知道能不能归属于这一类端到端MVS里面。
占据网络 Occupancy Network,一种新的基于学习的三维重建方法。占据网络隐式地将三维曲面表示为深度神经网络分类器的连续决策边界。
Atlas
这个看到很多次了,https://zhuanlan.zhihu.com/p/547411687?utm_id=0 https://zhuanlan.zhihu.com/p/564442411?utm_id=0 ,这里面就有看到。 【ATLAS:端对端网络重建三维场景-哔哩哔哩】 https://b23.tv/hP61nn6
MVS和SFM的区别与关系
SFM(structure from motion 从运动恢复结构)和MVS(multi-view stereo 多视图立体视觉)
参考自:https://blog.csdn.net/Vpn_zc/article/details/124602747
1、主要目的:
SFM是可以重建稀疏点云的和相机参数(内外), 主要目的是:estimating the geometry of the scene and camera poses from a set of images. 使用场景最多还是标定相机内外参。
MVS重建的是稠密点云。多视图立体匹配的定义是从两个或多个相机中恢复深度信息。
输入的数据:SFM是没有标定的图像,而MVS输入的是标定的图像(具有相机参数),
PS:相机参数可以通过SFM标定,所以如果从一组图像中重建三维模型,我们可以首先采用SFM标定相机内外参,然后根据标定结果进行稠密点云重建。 2、为什么SFM无法重建出稠密的点云,但是MVS可以?
SFM中我们用来做重建的点是由特征匹配提供的!这些匹配点天生不密集!MVS则几乎对照片中的每个像素点都进行匹配,几乎重建每一个像素点的三维坐标,这样得到的点的密集程度可以较接近图像为我们展示出的清晰度。 SFM和MVS关系
SFM给MVS算好了输入视角的位姿,内参,稀疏点云以及它们的共视关系,MVS再利用这些信息以及彩色图来估计深度图以及做最后的Fusion,还有点云过滤等等的。SFM是camera tracking, 而MVS是depth map estimation和depth fusion。在实际使用中,一般是SFM进行相机标定,然后采用MVS重建稠密点云。
MVS和SFM的关系还可以参考下面这个,似乎SFM可以算作MVS的子集?
https://mp.weixin.qq.com/s/Cuj24lsLKvYMXvaDuZc0jA?poc_token=HAv2Z2WjwNkA8sOZe1OkATF50LzvpD-lV2fERXlg

这里也是说SFM是MVS的前序步骤
https://mp.weixin.qq.com/s/oJixvzkdkqLDE8atFEzWUA

这里也可以看出SFM和MVS的关系
https://app0s6nfqrg6303.h5.xiaoeknow.com/v1/goods/goods_detail/p_609161a1e4b071a81eb781a8?type=3

稠密重建或者MVS里面做极线搜索的前提肯定是得已知两张图片之间的相对位姿了,所以MVS需要用到SFM的结果。
这个分类可以参考下

MVS和双目立体匹配的区别与联系
双目立体匹配是已知了相机内外参,特别是相机外参是固定的,MVS每两张图之间的外参都得专门估计,一般是SFM进行提供。
然后我个人感觉MVS更侧重于三维重建,毕竟有那么多张图片了,立体匹配侧重于单纯的深度估计也就是输出深度图。
MVS和立体匹配的关系还可以这么看,MVS不一定要估计出深度图,深度图融合只是MVS的方法之一,当MVS用深度图融合的时候,此时估计深度图可以和立体匹配对应上,但凡要估计深度图,核心原理基本都一样,基本都离不开极线搜索和块匹配,这样说是不是好理解一些了。立体匹配到目的就是得到视差图或者深度图,而MVS的目的,用看到的比较多点一句话来说是,寻找空间中具有图像一致性的点。 https://blog.csdn.net/gx17864373822/article/details/117826862
https://blog.csdn.net/weixin_40957452/article/details/120382758

MVS是计算的参考图像对应的深度图,多张图只有一个是参考图像,其他都叫源图像,也就是source。但是立体匹配里面好像没有参考图像源图像这个概念,它就是单纯计算两幅图像的视差,得到视差图,所以得到的深度图并不是跟某幅图像完全对应的?
不过你回看那些深度假设,极线搜索的图,他们都是有相对于一张图做深度假设的,也就是两个图里面还是有一个图作为参考图的。只要找到了匹配的像素点,得到该空间点相对于哪个图的深度理论上都是可以算出来的。所以不管是MVS还是双目立体匹配,得到的深度图是会和其中一张图对应上的!但是还是感觉什么地方不对劲,一个空间点,和光心的连线,不一定垂直于相机平面啊,这个深度指到投影平面的垂直距离还是到光心的距离,我感觉应该是到光心的距离吧。但是得到了到广西点距离,已经角度关系,也应该是可以酸楚到相机平面的垂直距离的吧,进而得到真正意义的深度图。
这么来看,不管是多目立体匹配还是双目立体匹配,应该都是有一张参考图像的,输出的深度图和参考图像对应。后来发现双目立体匹配不用选出什么参考图像,因为两个相机是平行的,空间点对于两个相机的深度值是一样的!

对于双目立体匹配而言,是不用选出一个参考图像的,因为深度值对于两个相机而言是一样的!因为两个相机是平行的!

这个把双目立体匹配做到SOTA之后把成功就拓展到MVS。
CVPR 2023 | IGEV-Stereo & IGEV-MVS:双目立体匹配网络新SOTA!
https://mp.weixin.qq.com/s/fd11pBzRDDfSzSQ2Oy1xcg
patchmatch我发现是一个贯穿双目立体匹配和MVS的一个方法,两边都用到了而且都是很重要的基础方法。patchmatch在MVS这边衍生出了gipuma,ACMP系列这些优秀方法。
3D视觉工坊的视觉三维重建课程里面讲colmap时就讲了patchmatch,看来确实是传统MVS在用的

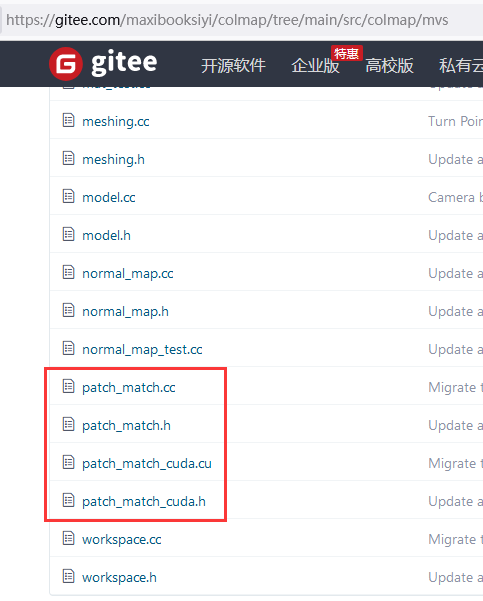
而且看colmap的源码,在colmap代码的MVS文件夹下就有patch_match的代码,再一次印证了,colmap就用的patchmatch做深度估计。 马熙/colmap - Gitee.com
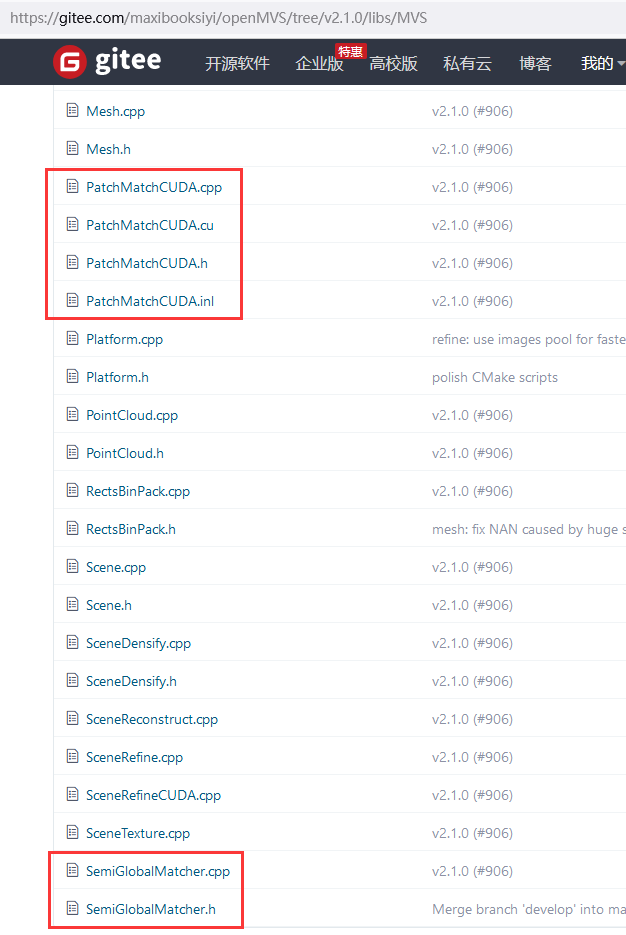
openMVS里面也有patchmatch的代码,也有SGM的代码。 马熙/openMVS - Gitee.com
还有一点我很好奇,是不是双目立体匹配和MVS刷榜的数据集都是不一样的,评价指标也是不一样的,相当于两个赛道?但是双目立体匹配的成果可以被MVS使用。
是的,可以看到不一样,双目立体匹配的论文里用的数据集和MVS的不一样。所以双目立体匹配和多目立体匹配从某个层面上说不完全在一个赛道上,不好同等比较,所以MVSNET的课里面压根没有提基于深度学习的双目立体匹配的成国庆。而且就算是比深度,多目立体匹配用到的图像多,理论上估计的深度也应该比双目好啊,所以这么比不公平。所以我发我的论文你发你的论文,不完全在一个体系下。
双目立体匹配用到的数据集有比如SceneFlow数据集,KITTI数据集。
SceneFlow数据集是目前规模最大的双目立体视觉公开数据集,所有场景都是利用3D模型人工合成的虚拟数据,包括三个子数据集:FlyingThings3D、Monkaa和Driving。 https://mp.weixin.qq.com/s/fd11pBzRDDfSzSQ2Oy1xcg
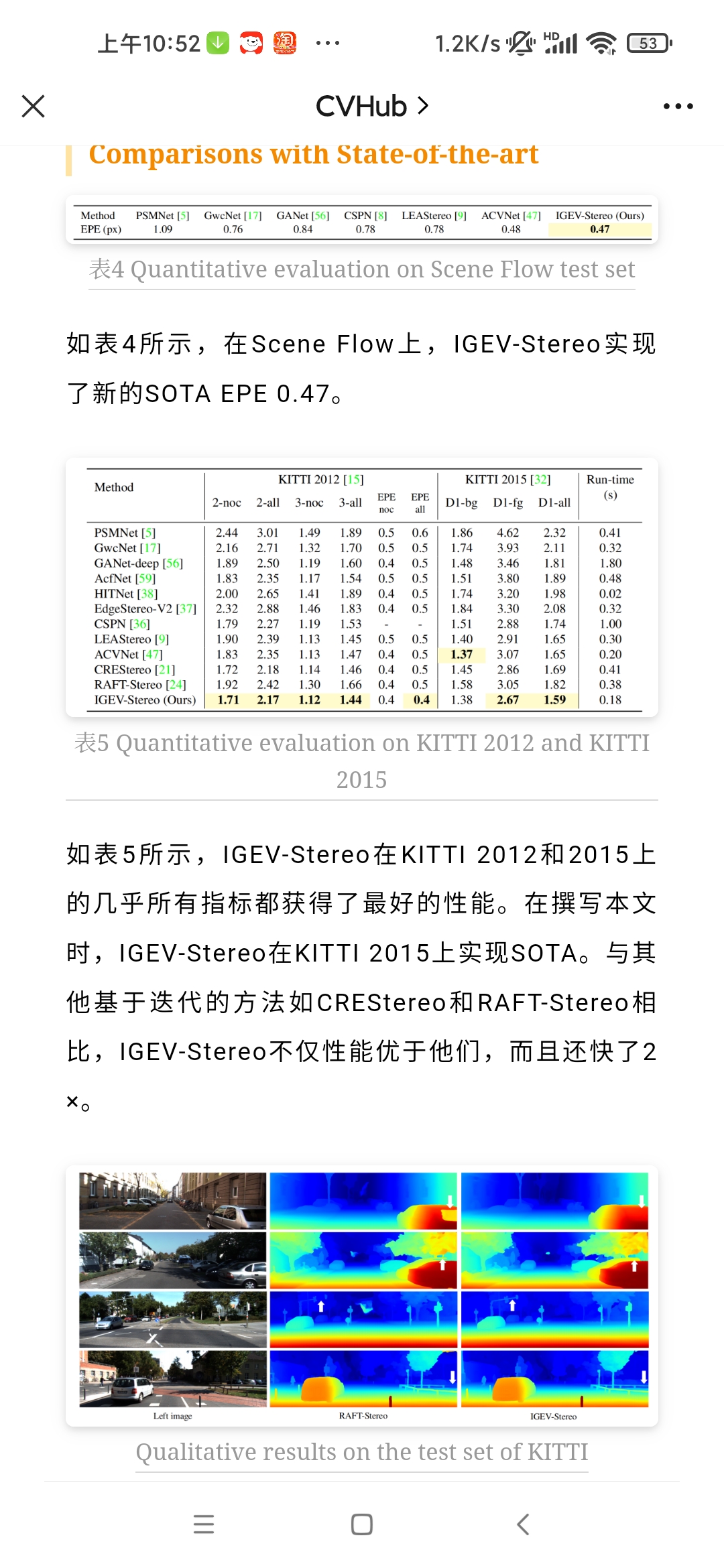
https://blog.csdn.net/Twilight737/article/details/127709054

关于基于几何的MVS和基于深度学习的MVS对比
目前深度学习MVS在准确性上是抵不过基于传统方法的MVS的,完整性上可能比传统MVSNET好点。
基于深度学习MVS目前主要还是用于科研和demo展示。

https://zhuanlan.zhihu.com/p/558191511?utm_id=0
未来基于深度学习的多视图重建方法是否能够在实际应用中大放异彩,还是仍然停留在数据评测刷榜的阶段?而传统的几何方法是否又能找到好的突破口重新焕发活力?这一切都需要时间来检验。
至少在目前看来,与其它的很多计算机视觉任务如目标检测等不同,在多视图重建中,深度学习方法的性能还远未达到碾压传统几何方法的地步,在一些代表性的数据集上二者评测性能仍在伯仲之间。而就多视图重建整个大的范畴而言,深度图估计和稠密点云生成,仍然还有很多需要完善的地方。
尽管不少商业软件宣称能够如何如何,恨不得智慧城市、数字地球、数字孪生、元宇宙等等下一刻就会降临人间,但是这一领域研究的客观局限性仍在那里,弱纹理甚至无纹理物体或区域,遍布城市的玻璃结构,草丛树木的精细表达,以及其他外在因素如低照度、光照不均衡、反射及天气状况等引起的成像问题,这些特殊情况的重建仍是需要克服的障碍,如果不能有所突破,终究只是沦为口号而已。任重而道远,与诸君共勉!
一些开源MVS软件
OpenMVS
https://github.com/electech6/openMVS_comments.git
OpenMVS是三维重建的一个成熟开源框架,综合重建效果和性能,该算法是目前MVS(Multi-View Stereo)相关的所有开源库中最好的一个。
我看李迎松博客里面给开源三维重建软件链接时,也是先给的openMVS,再给的colmap。
COLMAP
Colmap是一款功能强大的开源视觉三位重建软件,用于倾斜摄影测量和视觉SFM任务,COLMAP 是一种通用的运动结构 (SfM) 和多视图立体 (MVS) 管道,具有图形和命令行界面。 https://github.com/colmap/colmap
https://colmap.github.io/
linux上源码编译安装colmap https://colmap.github.io/install.html#installation
Build from Source
COLMAP builds on all major platforms (Linux, Mac, Windows) with little effort. First, checkout the latest source code:
git clone https://github.com/colmap/colmap
On Linux and Mac it is generally recommended to follow the installation instructions below, which use the system package managers to install the required dependencies. Alternatively, there is a Python build script that builds COLMAP and its dependencies locally. This script is useful under Windows and on a (cluster) system if you do not have root access under Linux or Mac.
Linux
Recommended dependencies: CUDA (at least version 7.X)
Dependencies from the default Ubuntu repositories:
sudo apt-get install \
git \
cmake \
ninja-build \
build-essential \
libboost-program-options-dev \
libboost-filesystem-dev \
libboost-graph-dev \
libboost-system-dev \
libeigen3-dev \
libflann-dev \
libfreeimage-dev \
libmetis-dev \
libgoogle-glog-dev \
libgtest-dev \
libsqlite3-dev \
libglew-dev \
qtbase5-dev \
libqt5opengl5-dev \
libcgal-dev \
libceres-dev
Configure and compile COLMAP:
git clone https://github.com/colmap/colmap.git
cd colmap
git checkout dev
mkdir build
cd build
cmake .. -GNinja
ninja
sudo ninja install
Run COLMAP:
colmap -h
colmap gui
To compile with CUDA support, also install Ubuntu’s default CUDA package:
sudo apt-get install -y \
nvidia-cuda-toolkit \
nvidia-cuda-toolkit-gcc
Or, manually install latest CUDA from NVIDIA’s homepage. During CMake configuration specify CMAKE_CUDA_ARCHITECTURES as “native”, if you want to run COLMAP on your current machine only, “all”/”all-major” to be able to distribute to other machines, or a specific CUDA architecture like “75”, etc.
Under Ubuntu 16.04/18.04, the CMake configuration scripts of CGAL are broken and you must also install the CGAL Qt5 package:
sudo apt-get install libcgal-qt5-dev
Under Ubuntu 22.04, there is a problem when compiling with Ubuntu’s default CUDA package and GCC, and you must compile against GCC 10:
sudo apt-get install gcc-10 g++-10
export CC=/usr/bin/gcc-10
export CXX=/usr/bin/g++-10
export CUDAHOSTCXX=/usr/bin/g++-10
# ... and then run CMake against COLMAP's sources.
3D视觉工坊里面有一门三维重建的课程,里面就是专门讲colmap
https://app0s6nfqrg6303.h5.xiaoeknow.com/v1/goods/goods_detail/p_609161a1e4b071a81eb781a8?type=3
利用Colmap实现基于图像的大规模户外场景重建 https://mp.weixin.qq.com/s/IwyTvs2b0B-8roVighUlIA
还有我发现colmap是可以配合MVSNET使用的( https://mp.weixin.qq.com/s/ifxkL7zpNn4paU_F4xidOA ),它们不是一个互斥的关系,像上面课程就有colmap+MVSNET。
COLMAP可以给图像数据集标定一套相机外参及视图选择。如果想用COLMAP导出的结果输入MVSNet测试,需要把数据集(图片、相机参数等)转化为MVSNet的输入格式。MVSNet的作者yaoyao在Github上提供了colmap2mvsnet.py代码,可以实现以上格式转化的需求。(摘自 https://blog.csdn.net/qq_43307074/article/details/128062508 )
patchmatchNet用的时候我看也有先用colmap先算出一些基础的东西比如位姿(参看 https://blog.csdn.net/qq_41694024/article/details/129021069 )
B站看到一些别人简单使用colmap进行三维重建的使用视频
【【colmap】基于多视角图像的三维重建-哔哩哔哩】 https://b23.tv/dQQqbMN
【【三维重建】利用开源软件colmap实现基于图像的三维重建-哔哩哔哩】 https://b23.tv/E4RjdQf
一些MVS方法
SurfaceNet
SurfaceNet是一个通过将相机参数与图像以3D体素共同编码表示的方式构建的全3D卷积网络。https://m.sohu.com/a/258754817_715754
MVSNet
基于深度学习的图像三维重建算法性能较好的主要有:MVSNet、PatchMatchNet、NeuralRecon。(摘自 https://zhuanlan.zhihu.com/p/532213401?utm_id=0 )
虽然这两年已经有更多的框架在精度和完整度上面超过了MVSNet,但笔者发现,无论是基于监督学习的R-MVSNet 、Cascade – MVSNet等网络,还是基于自监督学习的M3VSNet,核心网型设计都是在借鉴MVSNet而完成的,而且MVSNet也是比较早期且较为完整的三维重建深度学习框架,了解该框架的原理、数据IO与实际操作能加深对2020年以来各种新方法的理解。(摘自https://mp.weixin.qq.com/s/ifxkL7zpNn4paU_F4xidOA )
PatchMatchNet
下面摘自 https://mp.weixin.qq.com/s/sNfYt30dxQn8da-jI6qXJQ
自MVSNet[1]提出以来,稠密重建(Multi-view Stereo, MVS)领域的learning-based方法基于正平扫(front-to-parallel)+可微单应性形变(differentiable homography)构建多视图对的cost volume,之后利用3D CNN进行正则的技术路线似乎已经根深蒂固。后续的R-MVSNet[2]对于cost volume在深度维度的正则方式进行创新,采用Conv-GRU逐层处理大幅减少了显存占用;CasMVSNet[3]首次提出coarse-to-fine的结构范式优化了显存占用和计算效率;Vis-MVSNet[4]和CVP-MVSNet[5]分别从多视图对cost volume的聚合方式以及coars-to-fine后续阶段的深度假设范围进行了深入思考。虽然在这个过程中,近景MVS数据集DTU和中近景MVS数据集Tanks & Temples也不断被新的learning-based方法霸榜,但是没有一篇文章能够跳出MVSNet构建的算法框架去思考learning-based方法未来可能的发展方向。
随着CVPR2021会议的召开,multi-view stereo领域的一篇oral文章《PatchmatchNet: Learned Multi-View Patchmatch Stereo》(论文链接:https://arxiv.org/abs/2012.01411)给出了一种新的可能性——基于patch match的思路去做learning-based稠密重建算法。
omniMVS
https://github.com/matsuren/omnimvs_pytorch
对应用它的有个omniSLAM
SD-MVS
https://mp.weixin.qq.com/s/iMpbM4t0Kk8kx65cHxrbtA
一种名为"Segmentation-Driven Deformation Multi-View Stereo (SD-MVS)"的方法,旨在有效解决在3D重建中纹理稀疏区域所面临的挑战。该方法创新性地融合了多个关键技术,包括自适应块变形、球面梯度细化以及基于期望最大化(EM)算法的超参数优化。
自监督MVS
https://zhuanlan.zhihu.com/p/439210991?utm_id=0
有监督的MVSNet系列已经有比较多工作,自监督/无监督的MVS目前工作主要有以下几篇:Unsup_MVS(CVPR 2019 Workshop)、MVS2(3DV 2019)、M3VSNet(ICIP 2021)、Self-supervised-CVP-MVSNet(CVPR 2021)、U-MVS(ICCV 2021)JDACS-MS(AAAI 2021)。
https://mp.weixin.qq.com/s/7dh1E4Y3Ru6aZGuskd356A
无监督/自监督学习的MVS方法回顾
Learning Unsupervised Multi-view Stereopsis via Robust Photometric Consistency (CVPRW2019)
以UnsupMVS方法为例,无监督的多视图立体匹配是指在没有ground-truth深度图的情况下,利用多视图的光度一致性进行监督的方法。
具体地,在网络训练过程中借助了图像重建损失:基于网络预测的深度图,将源图像投影至参考视图下,计算参考图像与投影变换后的源图像之间的光度差异,多视图图像之间的光度差异即为网络训练的监督信号。考虑到多视图之间可能存在遮挡,因此在计算光度损失的时候采用了TopK的策略,即计算M=6幅源图像之间的光度损失,但是只选取K=3幅最小的误差计算损失项。
BEVScope:自监督多目深度估计新方案
https://mp.weixin.qq.com/s/l1cUB6zf-T6NJvWgyZA_rw
真正端到端MVS
Atlas
这个看到很多次了,https://zhuanlan.zhihu.com/p/547411687?utm_id=0 https://zhuanlan.zhihu.com/p/564442411?utm_id=0 ,这里面就有看到。 【ATLAS:端对端网络重建三维场景-哔哩哔哩】 https://b23.tv/hP61nn6
NeuralRecon
我感觉这种就叫创新,有让人眼前一亮的感觉
项目主页:
https://zju3dv.github.io/neuralrecon/
该工作提出了一种从单目视频中实时重建三维场景的框架。不同于先前估计每个视角深度图并进行融合的思路,该方法使用神经网络将每个视频序列片段直接以稀疏TSDF的形式重建,从而得到光滑、稠密、精确、且一致的重建结果。
B站上看到一个专门详细讲它的视频教程
【浙大团队研发!首个基于单目视频的三维场景重建框架:NeuralRecon 计算机博士带读CVPR2021经典论文,解读算法+源码实战!-哔哩哔哩】 https://b23.tv/vUnBUv6
孙佳明是这个的一作,亲自讲解
【基于深度学习的三维重建与位姿估计系统设计 | 孙佳明-哔哩哔哩】 https://b23.tv/Zrfngnk
SimpleRecon 无3D卷积三维重建
ECCV2022
https://mp.weixin.qq.com/s/fKDHFfVsW3TZgtF3e22U9w
作者认为在三维重建中深度估计的好才是王道,目前已有的3D卷积过于“昂贵”,低功耗设备无法使用,于是作者精心设计使用2D卷积进行多视图深度估计,结果显示其算法在ScanNet 以及 7-Scenes 接近甚至超过目前最好的重建算法,且速度非常快,约70ms每帧。
主页:nianticlabs.github.io/simplerecon
论文:https://arxiv.org/abs/2208.14743
代码:https://github.com/nianticlabs/simplerecon
TransformerFusion
基于NeuralRecon做的改进
Occupancy Network
是的,就是特斯拉的occupancy network,就是BEV的occupancy network。


















 4677
4677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











