






【LLM数据工程】LLMs-开源数据-预训练数据集总结v1.0
原创 zzichen Theseyouwant 2024年07月31日 23:33 江苏
【导读】:本文是LLM数据工程第一篇,介绍37个开源的预训练数据集。
【@】预训练数据集目录
| :
分享 |
开源数据集-预训练数据集
【001】Skywork/SkyPile-150B
数据集名称:Skywork/SkyPile-150B
数据集标签:【预训练数据】【中文】【web领域】【202310】
数据集介绍:Skypile-150B 是一个大型的中文语言模型预训练数据集,它取自于公开可用的中文互联网网页数据,并经过严格的过滤和广泛的重复数据删除,同时还采用了FastText和Bert等模型对低质量数据进行过滤。Skypile-150B包含大约166M个单独网页,平均每篇文章中文字符超过1,000。数据集总共约150B token,硬盘大小为592GB。
数据集下载:https://huggingface.co/datasets/Skywork/SkyPile-150B
数据集来源:https://huggingface.co/datasets/Skywork/SkyPile-150B
https://github.com/SkyworkAI/Skywork
Skywork论文:https://arxiv.org/pdf/2310.19341
数据集条数:1.76M =176w| 150B tokens| 592GB
数据集格式:
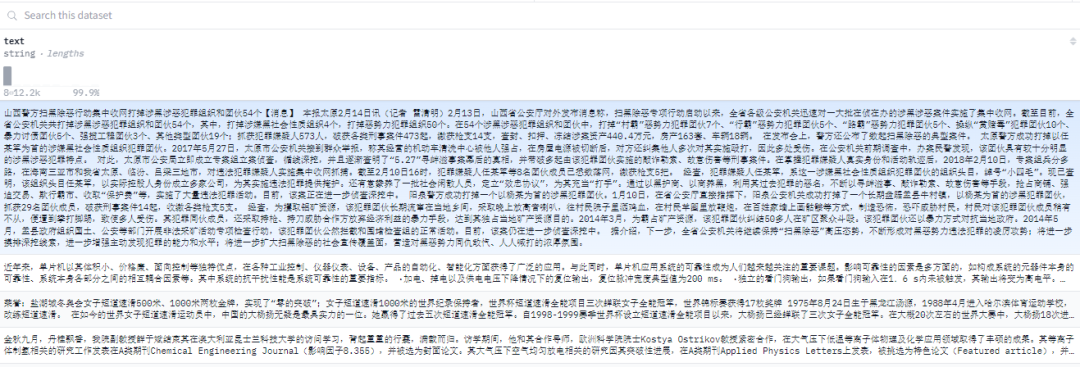
【002】togethercomputer/RedPajama-Data-1T
数据集名称:togethercomputer/RedPajama-Data-1T
数据集标签:【预训练数据】【多语种】【web领域】
数据集介绍:RedPajama 是 LLaMa 数据集的一个完全开源的独立实现版本。Total(1.2 Trillion):Commoncrawl(878 Billion),C4(175 Billion),GitHub(59 Billion),ArXiv(28 Billion),Wikipedia(24 Billion),StackExchange(20 Billion)。
数据集下载:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
数据集来源:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T-Sample
https://github.com/togethercomputer/RedPajama-Data
数据集条数:
数据集格式:
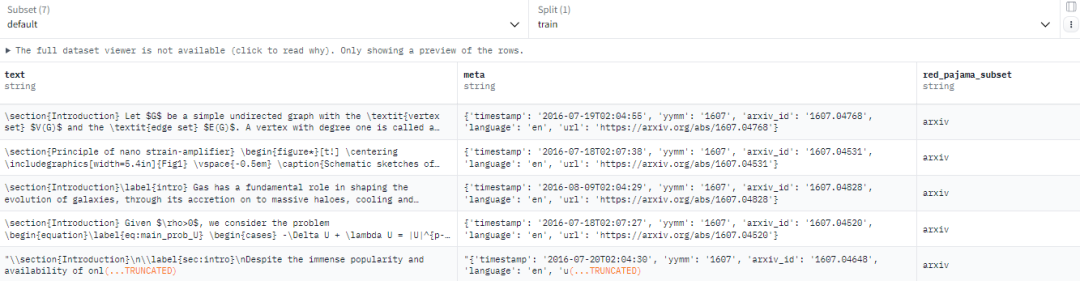

【003】togethercomputer/RedPajama-V2
数据集名称:togethercomputer/RedPajama-V2
数据集标签:【预训练数据】【多语种】【web领域】
数据集介绍:RedPajama-V2是一个用于训练大型语言模型的开放数据集。该数据集包括超过100B的文本文档,这些文档来自84个CommonCrawl快照,并使用CCNet管道进行处理。其中,语料库中有30B个文档额外附带了质量信号。此外,还提供了重复文档的id,可用于创建一个包含20B重复数据消除文档的数据集。
数据集下载:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2
数据集来源:https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2
https://github.com/togethercomputer/RedPajama-Data
数据集条数:>2.25M =225w | 100B
数据集格式:
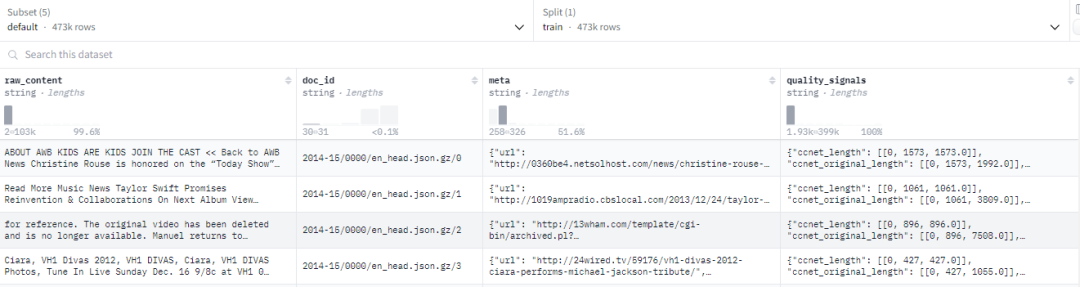
【004】tiiuae/falcon-refinedweb
数据集名称:tiiuae/falcon-refinedweb
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:Falcon RefinedWeb数据集 是由阿布扎比技术创新研究院(TII )在Common Crawl语料库基础上进行严格过滤和大规模去重构建,并发布的大型英文网络数据集;RefinedWeb的数据来源网络内容(仅包含网络数据),但是在此基础上所训练模型的性能达到或优于所谓精选数据集。Falcon RefinedWeb大语言模型Falcon训练的主要数据集。RefinedWeb 同时也具备多模特性,在处理样本中包含alt文本内容和图片链接。RefinedWeb 的公开摘录包含大约 1 Billon 个实例(968Million 个单独网页),总共 2.8TB 的纯文本数据。压缩后约为500GB。
数据集下载:https://huggingface.co/datasets/tiiuae/falcon-refinedweb
数据集来源:https://huggingface.co/datasets/tiiuae/falcon-refinedweb
Falcon RefinedWeb论文:https://arxiv.org/pdf/2306.01116
数据集条数:968M | 500GB
数据集格式:
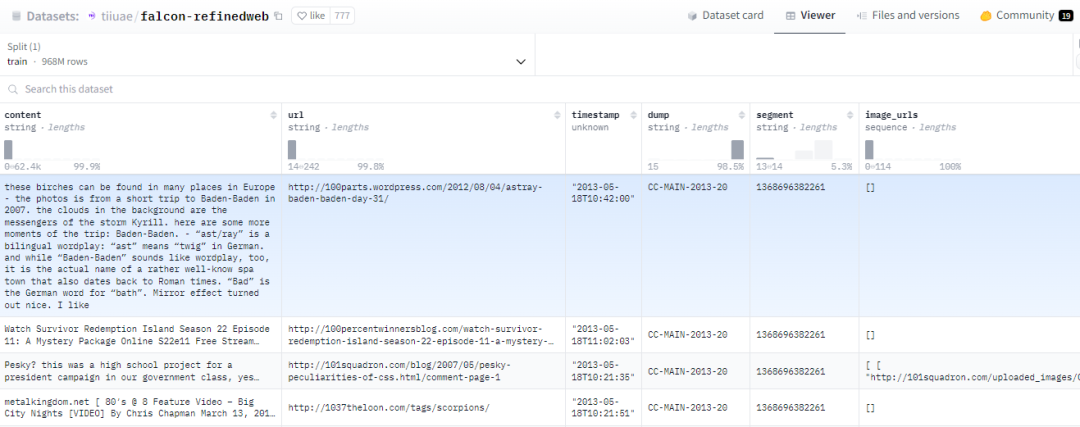
【005】WanJuan2.0(WanJuan-CC)
数据集名称:WanJuan2.0(WanJuan-CC)
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:WanJuan2.0(WanJuan-CC) 是从CommonCrawl获取的一个 1T Tokens 的高质量英文网络文本数据集。结果显示,与各类开源英文CC语料在 Perspective API 不同维度的评估上,WanJuan2.0 都表现出更高的安全性。此外,通过在4个验证集上的困惑度(PPL)和6下游任务的准确率,也展示了WanJuan2.0 的实用性。WanJuan2.0 在各种验证集上的PPL表现出竞争力,特别是在要求更高语言流畅性的tiny-storys等集上。通过与同类型数据集进行1B模型训练对比,使用验证数据集的困惑度(perplexity)和下游任务的准确率作为评估指标,实验证明,WanJuan2.0 显著提升了英文文本补全和通用英文能力任务的性能。
数据集下载:https://opendatalab.com/OpenDataLab/WanJuanCC/tree/main
数据集来源:https://opendatalab.com/OpenDataLab/WanJuanCC/tree/main
WanJuan-CC数据集:为大型语言模型训练提供高质量Webtext资源
数据集条数:约 100B Tokens;
数据集格式:

【006】EleutherAI/the_pile_deduplicated
数据集名称:EleutherAI/the_pile_deduplicated
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:The Pile数据集由22个不同的高质量子集构建而成,其中许多来自学术或专业资源。主要包括作者新构建的ArXiv, GitHub等,还包括已有的Books3,English Wikipedia等数据集。Pile规模有825GB。GPT-NeoX模型使用的训练数据。
数据集下载:https://pile.eleuther.ai/
https://huggingface.co/datasets/EleutherAI/the_pile_deduplicated
数据集来源:https://pile.eleuther.ai/
https://huggingface.co/datasets/EleutherAI/the_pile_deduplicated
The Pile论文:https://arxiv.org/pdf/2101.00027
数据集条数:134M| 451GB
数据集格式:
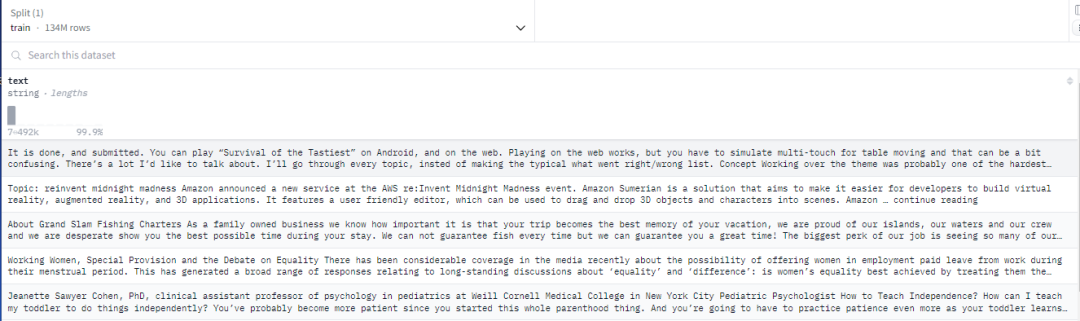
【007】ROOTS 数据集
数据集名称:bigscience-data/roots_zh-tw_wikipedia
数据集标签:【预训练数据】【多语种】【web领域】
数据集介绍:ROOTS 数据集由 huggingface datasets, dataset collections, pseudo-crawl dataset, Github Code, OSCAR 这几个数据构成的,它包含 46 个 natural 语言和 13 个编程语言 (总共 59 个语言),整个数据集的大小有 1.6TB。需要申请。
数据集下载:https://huggingface.co/bigscience-data?#datasets
数据集来源:https://huggingface.co/bigscience-data?#datasets
https://docs.google.com/forms/d/e/1FAIpQLSdq50O1x4dkdGI4dwsmchFuNI0KCWEDiKUYxvd0r0_sl6FfAQ/viewform?pli=1
数据集条数:1.6TB
数据集格式:
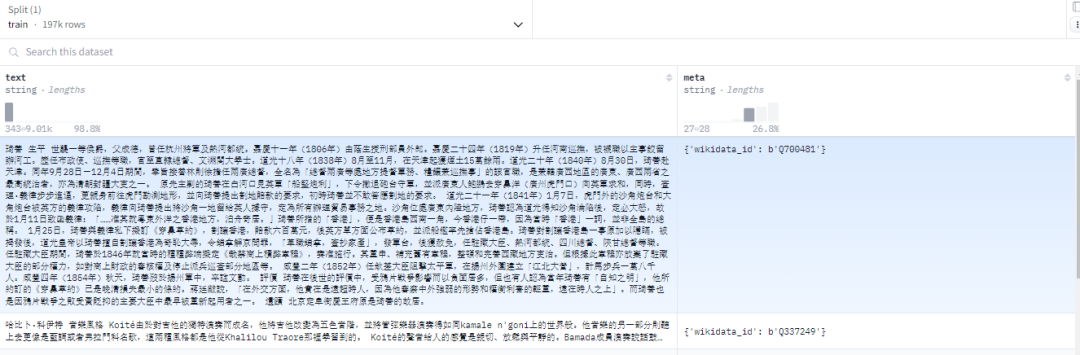
【008】MNBVC超大规模中文语料集
数据集名称:MNBVC/wanng/wikipedia-zh-mnbvc
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:MNBVC超大规模中文语料集。对标chatGPT训练的40T数据。MNBVC数据集不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。目前MNBVC数据集包含如下几类数据:通用文本。问答语料。代码语料。多轮对话。论坛语料。平行语料。
数据集下载:https://huggingface.co/datasets/botp/liwu-MNBVC
https://huggingface.co/datasets/wanng/wikipedia-zh-mnbvc
数据集来源:https://huggingface.co/datasets/botp/liwu-MNBVC
https://github.com/esbatmop/MNBVC
数据集条数:10M |3.39GB
数据集格式:
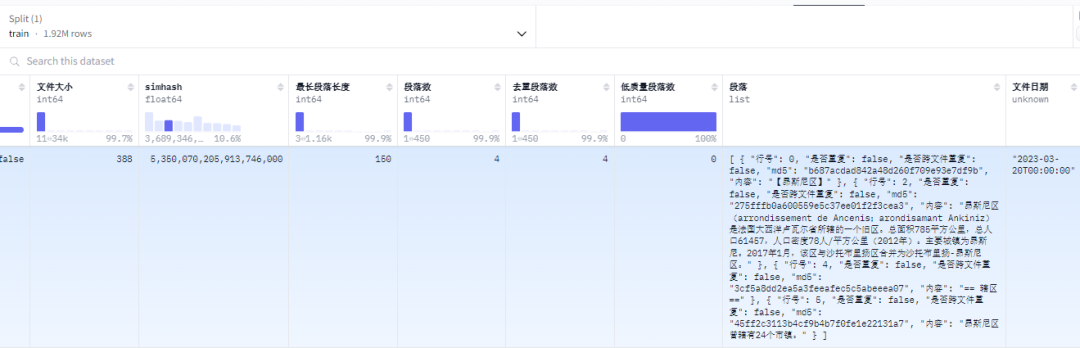
【009】WuDaoCorporaText
数据集名称:p208p2002/wudao
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。
数据集下载:https://data.baai.ac.cn/details/WuDaoCorporaText
数据集来源:https://data.baai.ac.cn/details/WuDaoCorporaText
https://huggingface.co/datasets/p208p2002/wudao
数据集条数:1.43M=143w|200GB
数据集格式:
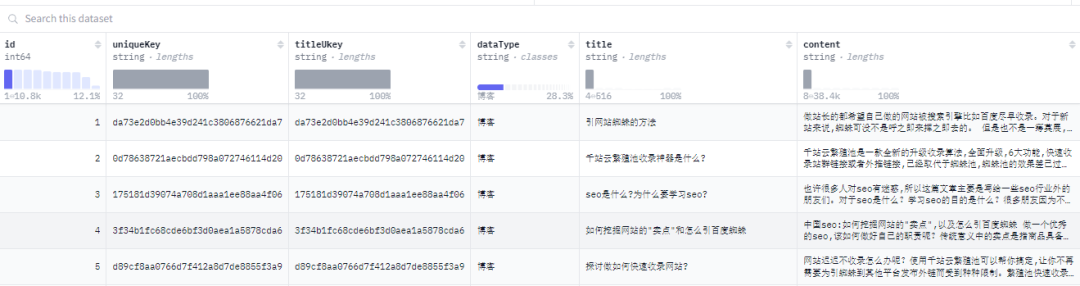
【010】CLUECorpus2020
数据集名称:CLUECorpus2020
数据集标签:【预训练数据】【中文】【web领域】【QA】
数据集介绍:通过对Common Crawl的中文部分进行语料清洗,最终得到100GB的高质量中文预训练语料,可直接用于预训练、语言模型或语言生成任务以及专用于简体中文NLP任务的小词表。
数据集下载:https://github.com/CLUEbenchmark/CLUECorpus2020
https://huggingface.co/datasets/austenjs/ClueCorpusSmallDataset
数据集来源:https://github.com/CLUEbenchmark/CLUECorpus2020
CLUECorpus2020论文:https://arxiv.org/pdf/2003.01355
数据集条数:6.02M| 3.56GB
数据集格式:
【011】wikimedia/wikipedia
数据集名称:wikimedia/wikipedia
数据集标签:【预训练数据】【多语种】【平行语料】【通用数据】
数据集介绍:wikipedia包含所有语言清理过的文章的维基百科数据集。该数据集由维基百科的 dumps (https://dumps.wikimedia.org/) 构建,每种语言有一个子集,每个子集包含一个训练拆分。
每个示例包含一篇完整的维基百科文章的内容,并进行了清理以去除 markdown 和不需要的部分(例如参考文献等)。
数据集下载:https://huggingface.co/datasets/wikimedia/wikipedia
数据集来源:https://huggingface.co/datasets/wikimedia/wikipedia
数据集条数:>61.6M[百万] |71.8GB
数据集格式:
【012】legacy-datasets/wikipedia
数据集名称:legacy-datasets/wikipedia
数据集标签:【预训练数据】【多语种】【web领域】【QA】
数据集介绍:数据集中添加了202203月期间的维基百科dumps,涵盖20种语言,包括使用拉丁字母或西里尔字母的语言,然后对数据进行预处理,以去除超链接、评论和其他格式化的html模板。
数据集下载:https://huggingface.co/datasets/legacy-datasets/wikipedia
https://github.com/noanabeshima/wikipedia-downloader
数据集来源:https://huggingface.co/datasets/legacy-datasets/wikipedia
数据集条数:| 3T tokens
数据集格式:

【013】wikipedia-cn-20230720-filtered
数据集名称:wikipedia-cn-20230720-filtered
数据集标签:【预训练数据】【中文】【web领域】【202307】
数据集介绍:本数据集基于中文维基2023年7月20日的dump存档。作为一项以数据为中心的工作,本数据集仅保留了 254,547条 质量较高的词条内容。具体而言:过滤了Template, Category, Wikipedia, File, Topic, Portal, MediaWiki, Draft, Help等特殊类型的词条。使用启发式的方法和自有的NLU模型过滤了一部分质量较低的词条。过滤了一部分内容较为敏感或存在争议性的词条。进行了简繁转换和习惯用词转换,确保符合中国大陆地区的习惯用词。
数据集下载:https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered
数据集来源:https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered
数据集条数:254k | 524 MB
数据集格式:
【014】allenai/c4
数据集名称:allenai/c4
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:Common Crawl网络爬虫开放数据库。CommonCrawl和C4有着很强的关系,因为都是同源的,重点研究选取它的纯英文过滤版(C4)作为数据集。C4数据集是Common Crawl在2019年的快照,包含新闻、法律、维基百科和通用网络文档等多种文本类型。C4的预处理也包含重复数据删除和语言识别步骤:与CCNet的主要区别是质量过滤,主要依靠启发式方法,如是否存在标点符号,以及网页中的单词和句子数量。
数据集下载:https://huggingface.co/datasets/allenai/c4
数据集来源:https://huggingface.co/datasets/allenai/c4
数据集条数:2.15M
数据集格式:
【015】cerebras/SlimPajama-627B
数据集名称:cerebras/SlimPajama-627B
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:SlimPajama数据集由 59166 个 jsonl 文件组成,压缩后约为 895GB。SlimPajama 是通过使用 MinHashLSH 对 Together 的 RedPajama 数据集进行清理和去重而创建的。RedPajama 是对 LLaMA 数据收集方法的开源再现。广泛去重 RedPajama 数据集,以生成一个信息密度更高的数据集。这意味着当使用 SlimPajama 时,与其他数据集相比,可以在相同的计算预算下实现更高的准确性。主要是英文数据,包含一些来自 Wikipedia 的非英文文件。
数据集下载:https://huggingface.co/datasets/cerebras/SlimPajama-627B
数据集来源:https://huggingface.co/datasets/cerebras/SlimPajama-627B
https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama
https://github.com/Cerebras/modelzoo/tree/main
数据集条数: 627B Tokens|895GB
数据集格式:
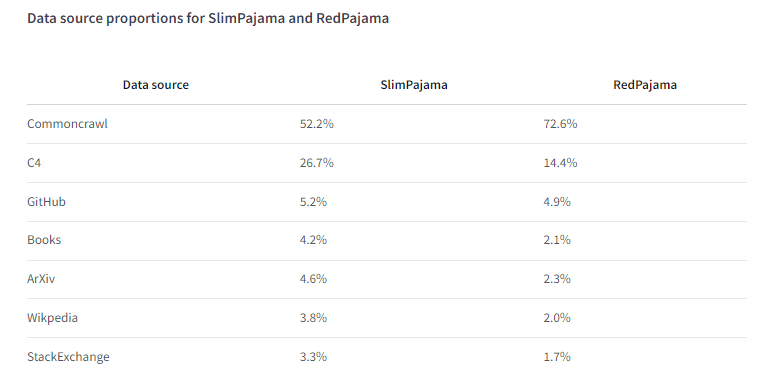
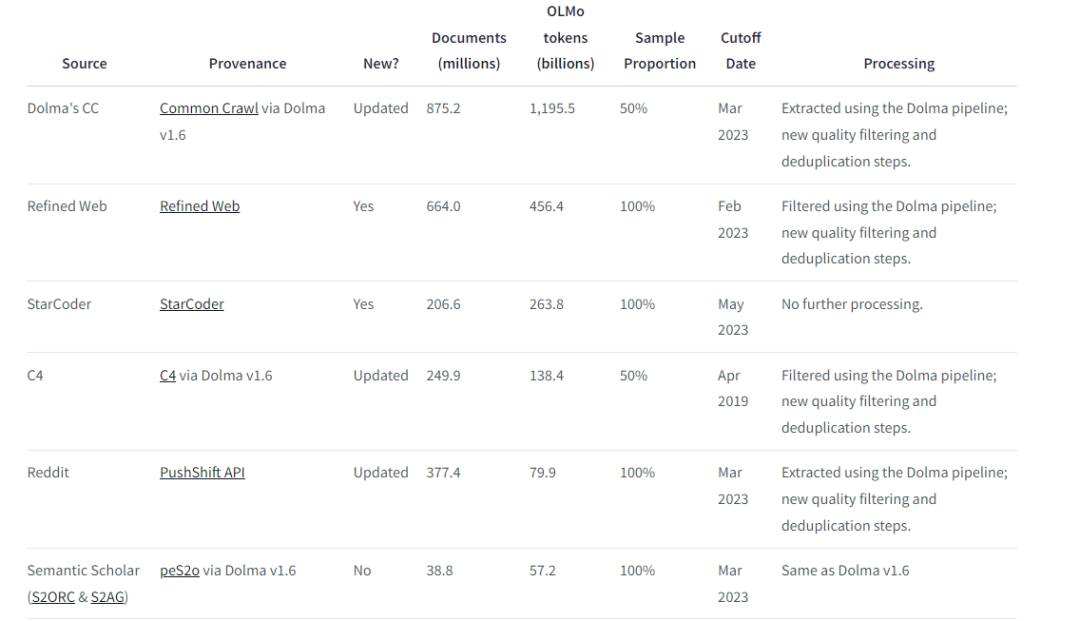
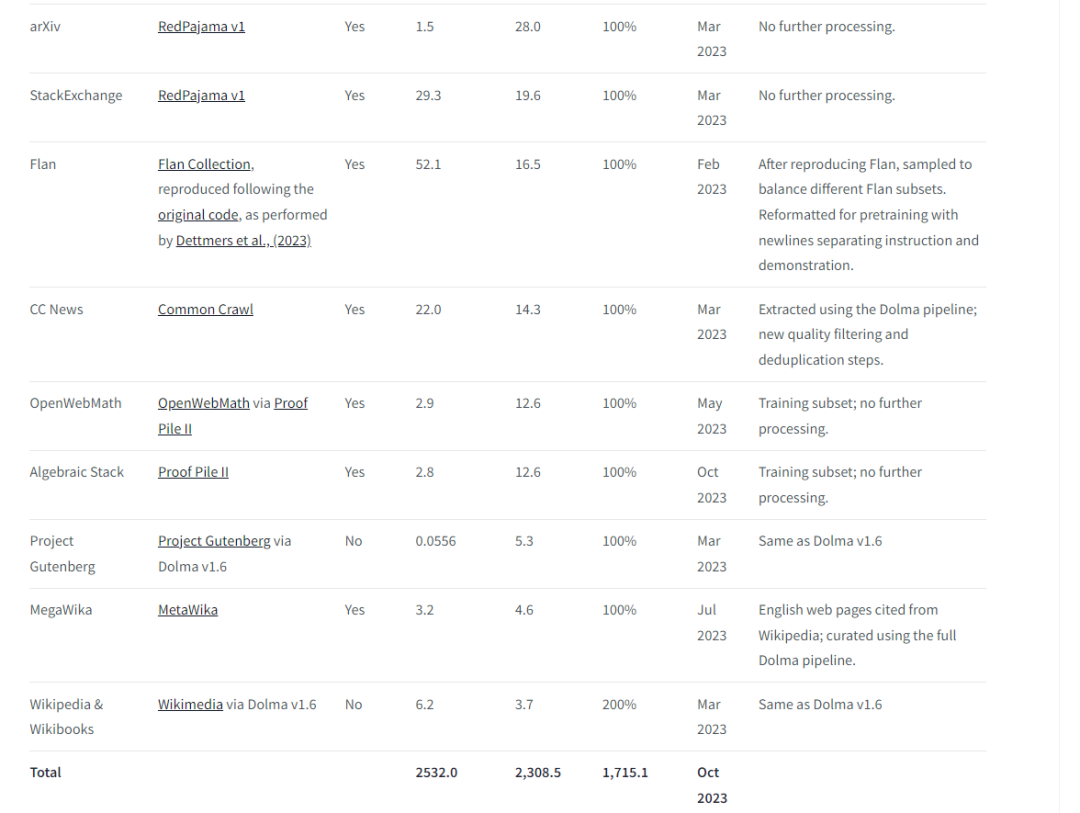
SlimPajama 和 RedPajama 的数据来源比例:
【016】wikipedia-2023-11-embed-multilingual-v3
数据集名称:Cohere/wikipedia-2023-11-embed-multilingual-v3
数据集标签:【预训练数据】【多语种】【web领域】
数据集介绍:多语言Wikipedia嵌入数据集。该数据集包含2023年11月1日从Wikipedia所有300多种语言的wikimedia/wikipedia数据集转储。每篇文章都被分块,并使用最先进的多语言Cohere Embed V3嵌入模型进行嵌入。这使得可以轻松地在整个Wikipedia中进行语义搜索,或将其用作你的RAG应用程序的知识来源。总共约有2.5亿段落/嵌入。
数据集下载:https://huggingface.co/datasets/Cohere/wikipedia-2023-11-embed-multilingual-v3
数据集来源:https://huggingface.co/datasets/Cohere/wikipedia-2023-11-embed-multilingual-v3
数据集条数:247M
数据集格式:
【017】BAAI/CCI2-Data
数据集名称:BAAI/CCI2-Data
数据集标签:【预训练数据】【中文】【医疗领域】【QA】
数据集介绍:为了应对中文高质量安全数据集稀缺的问题,于2023年11月29日开源了CCI(Chinese Corpora Internet)数据集。在此基础上,我们继续扩展数据来源,采用更严格的数据清洗方法,完成了CCI 2.0数据集的构建。该数据集由来自可信来源的高质量、可靠的互联网数据组成。数据集经过严格的数据清洗和去重,并对内容质量和安全性进行了有针对性的检测和过滤。数据处理规则包括:
基于规则的过滤:基于关键词的安全过滤、垃圾信息过滤等。基于模型的过滤:通过训练分类模型过滤低质量内容。去重:在数据集内和数据集之间进行去重。发布的CCI 2.0语料库大小为501GB。
数据集下载:https://huggingface.co/datasets/BAAI/CCI2-Data?row=0
数据集来源:https://huggingface.co/datasets/BAAI/CCI2-Data?row=0
数据集条数:179M
数据集格式:
【018】CASIA-LM/ChineseWebText
数据集名称:CASIA-LM/ChineseWebText
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:ChineseWebText是按照RefinedWeb的思路做的中文版本[2021-2023],由中科院自动化所发布,「仅包含」网络数据,共1.42TB,并且每条数据都有一个打分,其中高质量数据有600GB。通过对每条文本基于BERT进行打分,基于阈值为0.4过滤出高质量文本600GB。基于这个阈值过滤的文本,人工评估显示90%均为高质量的文本。不过相比RefinedWeb,本文没有具体的训练模型进行对比,所以基于该数据集训练的模型实际效果还有待验证。
数据集下载:https://huggingface.co/datasets/CASIA-LM/ChineseWebText
数据集来源:https://github.com/CASIA-LM/ChineseWebText
数据集条数:| 1.42TB
数据集格式:

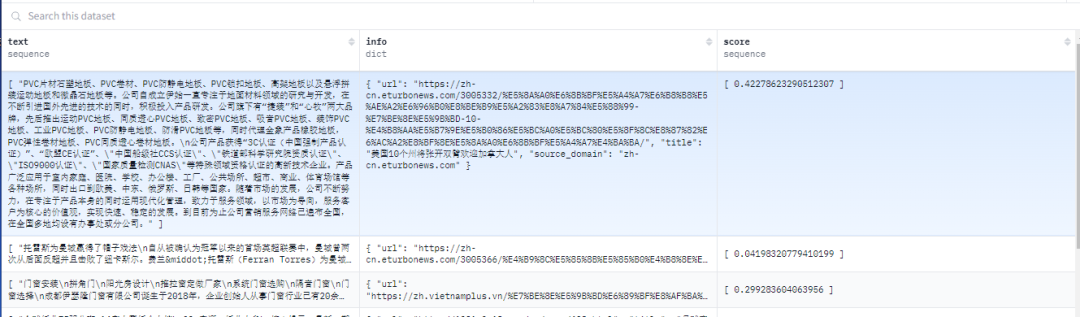
【019】allenai/dolma
数据集名称:allenai/dolma
数据集标签:【预训练数据】【英文】【混合数据】
数据集介绍:Dolma 数据集包含3万亿个标记,来源于各种网络内容、学术出版物、代码、书籍和百科全书资料的多样混合。
数据集下载:https://huggingface.co/datasets/allenai/dolma
数据集来源:https://huggingface.co/datasets/allenai/dolma
数据集条数:3T tokens
数据集格式:
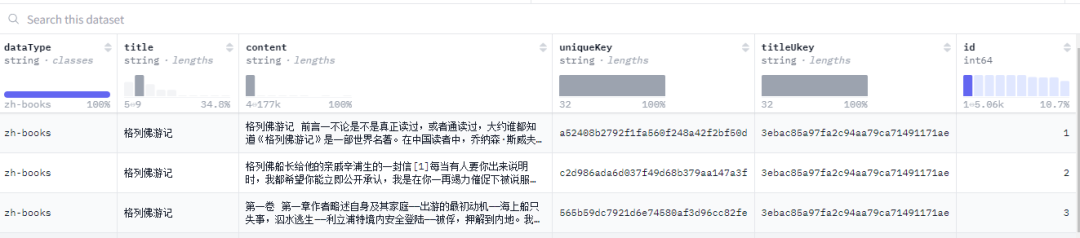
【020】TigerResearch/pretrain_zh
数据集名称:TigerResearch/pretrain_zh
数据集标签:【预训练数据】【中文】【web领域】【书籍】【百科】
数据集介绍:Tigerbot pretrain数据的中文部分。pretrain_zh包含(未压缩前) 中文书籍zh-books 12G, 中文互联网zh-webtext 25G, 中文百科zh-wiki 19G
数据集下载:https://huggingface.co/datasets/TigerResearch/pretrain_zh
数据集来源:https://huggingface.co/datasets/TigerResearch/pretrain_zh
https://github.com/TigerResearch/TigerBot
数据集条数:16.9M = 1690w
数据集格式:
【021】维基百科(wiki2019zh)
数据集名称:维基百科(wiki2019zh)-nlp_chinese_corpus
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:维基百科(wiki2019zh),100万个结构良好的中文词条。104万个词条(1,043,224条; 原始文件大小1.6G,压缩文件519M;数据更新时间:2019.2.7)。可能的用途:可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。
数据集下载:https://github.com/brightmart/nlp_chinese_corpus
数据集来源:https://github.com/brightmart/nlp_chinese_corpus
数据集条数:104w | 519M
数据集格式:


【022】新闻语料json版(news2016zh)
数据集名称:新闻语料json版(news2016zh)-nlp_chinese_corpus
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:新闻语料json版(news2016zh)。250万篇新闻( 原始数据9G,压缩文件3.6G;新闻内容跨度:2014-2016年)。数据描述:包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。可能的用途:可以做为【通用中文语料】,训练【词向量】或做为【预训练】的语料。
数据集下载:https://github.com/brightmart/nlp_chinese_corpus
数据集来源:https://github.com/brightmart/nlp_chinese_corpus
数据集条数:250w | 3.6 GB
数据集格式:


【023】百科问答(baike2018qa)
数据集名称:百科问答(baike2018qa)-nlp_chinese_corpus
数据集标签:【预训练数据】【中文】【web领域】【QA】
数据集介绍:百科问答(baike2018qa),150万个带问题类型的问答。150万个问答( 原始数据1G多,压缩文件663M;数据更新时间:2018年)。数据描述:含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。
数据集下载:https://github.com/brightmart/nlp_chinese_corpus
数据集来源:https://github.com/brightmart/nlp_chinese_corpus
数据集条数:150w |663MB
数据集格式:


【024】社区问答json版(webtext2019zh)
数据集名称:社区问答json版(webtext2019zh)-nlp_chinese_corpus
数据集标签:【预训练数据】【中文】【web领域】【QA】
数据集介绍:社区问答json版(webtext2019zh),410万个高质量社区问答,适合训练超大模型
410万个问答( 过滤后数据3.7G,压缩文件1.7G;数据跨度:2015-2016年)。数据描述:含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。
数据集下载:https://github.com/brightmart/nlp_chinese_corpus
数据集来源:https://github.com/brightmart/nlp_chinese_corpus
数据集条数:410w |1.7 GB
数据集格式:


【025】翻译语料(translation2019zh)
数据集名称:翻译语料(translation2019zh)-nlp_chinese_corpus
数据集标签:【预训练数据】【中文】【web领域】
数据集介绍:翻译语料(translation2019zh),520万个中英文句子对。520万个中英文平行语料( 原始数据1.1G,压缩文件596M)。数据描述:中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词(单词如“she”)。可做为通用中文语料,训练词向量或做为预训练的语料。
数据集下载:https://github.com/brightmart/nlp_chinese_corpus
数据集来源:https://github.com/brightmart/nlp_chinese_corpus
数据集条数:520w |596 MB
数据集格式:


【026】FreedomIntelligence/huatuo_encyclopedia_qa
数据集名称:FreedomIntelligence/huatuo_encyclopedia_qa
数据集标签:【预训练数据】【中文】【医疗领域】【QA】
数据集介绍:该数据集共有364,420条医疗问答数据,其中一些包含多种方式的多个问题。我们从纯文本(例如,医学百科全书和医学文章)中提取医疗问答对。我们从中文维基百科收集了8,699条疾病百科全书条目和2,736条药物百科全书条目。此外,我们还从Qianwen Health网站爬取了226,432篇高质量的医学文章。
数据集下载:https://huggingface.co/datasets/FreedomIntelligence/huatuo_encyclopedia_qa
数据集来源:https://github.com/jind11/MedQA,
数据集条数:364k
数据集格式:

【027】中文文本分类数据集THUCNews
数据集名称:中文文本分类数据集THUCNews
数据集标签:【预训练数据】【中文】【新闻领域】
数据集介绍:THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。使用THUCTC工具包在此数据集上进行评测,准确率可以达到88.6%。
数据集下载:http://thuctc.thunlp.org/#%E4%B8%AD%E6%96%87%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E6%95%B0%E6%8D%AE%E9%9B%86THUCNews
数据集来源:http://thuctc.thunlp.org/#%E4%B8%AD%E6%96%87%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E6%95%B0%E6%8D%AE%E9%9B%86THUCNews
数据集条数:74w | 2.19G
数据集格式:xxx
【028】OpenDataLab/MiChao
数据集名称:OpenDataLab/MiChao
数据集标签:【预训练数据】【中文】【web领域】【QA】
数据集介绍:蜜巢·花粉1.0开源数据集为文本数据集。数据集由互联网公开可访问网站2022年历史数据收集整理而成,数据总量超过1亿条。数据集具备来源可靠,数据质量高,可持续稳定更新等特点。蜜巢·花粉数据集已被应用于多个大模型的训练,为媒体垂直领域提供基于材料的知识问答与内容生成、分析报告自动生成、文稿内容审校与润色改写等各类智能生成式服务。
数据集下载:https://opendatalab.org.cn/OpenDataLab/MiChao
数据集来源:https://opendatalab.org.cn/OpenDataLab/MiChao
数据集条数:7000w
数据集格式:

【029】arxiv-community/arxiv_dataset
数据集名称:arxiv-community/arxiv_dataset
数据集标签:【预训练数据】【英文】【arxiv】
数据集介绍:arxiv_dataset数据集包含170万篇arXiv文章,可用于趋势分析、论文推荐引擎、类别预测、共引网络、知识图谱构建和语义搜索界面等应用。该数据集是原始ArXiv数据的镜像。由于完整数据集非常大(1.1TB并且还在增长),该数据集仅提供一个json格式的元数据文件。
数据集下载:https://huggingface.co/datasets/allenai/dolma
数据集来源:https://huggingface.co/datasets/allenai/dolma
数据集条数:170w
数据集格式:xxx
【030】bigcode/the-stack-dedup
数据集名称:bigcode/the-stack-dedup
数据集标签:【预训练数据】【代码】【web领域】
数据集介绍:The Stack 数据集包含超过6TB的宽松许可源代码文件,涵盖了358种编程语言。该数据集是 BigCode 项目的一部分。The Stack 数据集用于作为 Code LLMs 的预训练数据集,这些代码生成 AI 系统可以根据自然语言描述以及其他代码片段生成程序。这是接近去重的版本,数据大小为3TB。
数据集下载:https://huggingface.co/datasets/bigcode/the-stack-dedup
数据集来源:https://huggingface.co/datasets/bigcode/the-stack-dedup
https://zhuanlan.zhihu.com/p/641013454
数据集条数:236M | 996GB
数据集格式:


【031】bigcode/starcoderdata
数据集名称:bigcode/starcoderdata
数据集标签:【预训练数据】【代码】【web领域】
数据集介绍:StarCoder 训练数据集。starcoderdata是用于训练 StarCoder 和 StarCoderBase 的数据集。该数据集包含 86 种编程语言的 783GB 代码,包括 54GB 的 GitHub Issues、13GB 的 Jupyter Notebooks(以脚本和文本代码对的形式)和 32GB 的 GitHub 提交记录,总共约 2500 亿个 token。数据集创建 The Stack 数据集的创建和过滤方法在原始数据集中进行了说明,对数据集中所有 86 种编程语言、GitHub issues、Jupyter Notebooks 和 GitHub 提交记录进行了去污染和清理。此外,我们还应用了近重复数据消除并删除了 PII。
数据集下载:https://huggingface.co/datasets/bigcode/starcoderdata
数据集来源:https://huggingface.co/datasets/bigcode/starcoderdata
数据集条数:206M | 311G
数据集格式:

【032】open-web-math/open-web-math
数据集名称:open-web-math/open-web-math
数据集标签:【预训练数据】【英文】【数学领域】
数据集介绍:OpenWebMath 是一个包含大部分高质量数学文本的数据集,这些文本来源于互联网上的不同资源。该数据集经过筛选和提取,从 Common Crawl 的超过 2000 亿个 HTML 文件中提取出 630 万份文件,总计 147 亿个 token。OpenWebMath 旨在用于大语言模型的预训练和微调。
数据集特点-数据来源:OpenWebMath 数据集包含来自 13 万多个不同域名的文档,包括论坛、教育页面和博客等。覆盖领域:数据集中的文档覆盖了数学、物理、统计学、计算机科学等多个学科。
数据集下载:https://opendatalab.com/OpenDataLab/OpenWebText
数据集来源:https://opendatalab.com/OpenDataLab/OpenWebText
数据集条数:6.31M | 27.4GB
数据集格式:


【033】flax-sentence-embeddings/stackexchange_math_jsonl
数据集名称:flax-sentence-embeddings/stackexchange_math_jsonl
数据集标签:【预训练数据】【英文】【数学领域】
数据集介绍:自动从 Stack Exchange 网络中提取了问答对(Q&A)。Stack Exchange 汇集了多个问答社区,涵盖了 50 个在线平台,包括著名的 Stack Overflow 和其他技术网站。每月有 1 亿开发者访问 Stack Exchange。该数据集是一个平行语料库,每个问题都对应到评分最高的答案。数据集按社区划分,涵盖了从 3D 打印、经济学、Raspberry Pi 到 Emacs 等各种领域。
数据集下载:https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_math_jsonl
数据集来源:https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_math_jsonl
数据集条数:6.31M | 27.4GB
数据集格式:
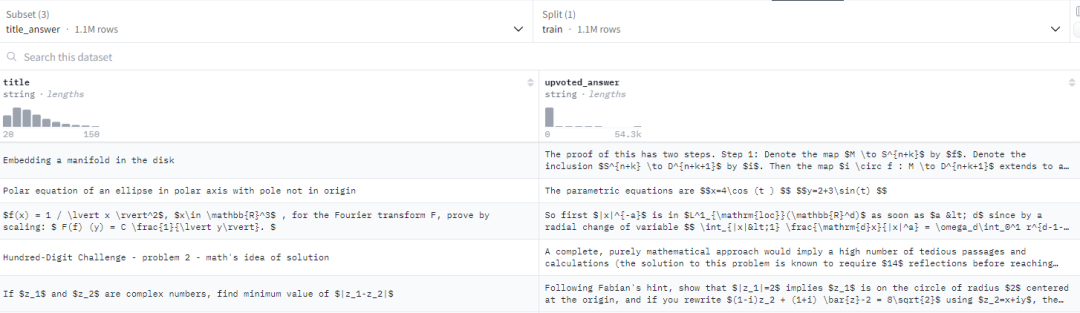
【034】Skylion007/openwebtext
数据集名称:Skylion007/openwebtext
数据集标签:【预训练数据】【英文】【web领域】
数据集介绍:OpenWebText 是 WebText 语料库的开源再造。该文本是从 Reddit 上共享的 URL 中提取的 Web 内容,至少获得了 3 次赞成(38GB)。开源的 WebText 数据集复刻版,原始数据集由 OpenAI 用于训练 GPT-2。
数据集下载:https://skylion007.github.io/OpenWebTextCorpus/
https://huggingface.co/datasets/Skylion007/openwebtext
https://huggingface.co/datasets/Bingsu/openwebtext_20p
数据集来源:https://opendatalab.com/OpenDataLab/OpenWebText
数据集条数:33.16M
数据集格式:

【035】Linly-AI/Chinese-pretraining-dataset
数据集名称:Linly-AI/Chinese-pretraining-dataset
数据集标签:【预训练数据】【中英文】【平行语料】【通用数据】
数据集介绍:中英文无监督、平行语料。包括ParaCrawl-v9.jsonl,UNv1-0.jsonl,WikiMatrix.jsonl,zhwiki_2023.jsonl,translation2019zh.jsonl,news-commentary.jsonl,news-crawl.jsonl,csl.jsonl
数据集下载:https://huggingface.co/datasets/Linly-AI/Chinese-pretraining-dataset
数据集来源:https://github.com/CVI-SZU/Linly/wiki/Linly-OpenLLaMA
https://github.com/shibing624/MedicalGPT?tab=readme-ov-file
数据集条数:23.1M[百万] |16GB
数据集格式:

【036】OpenDataLab/OpenNewsArchive
数据集名称:OpenDataLab/OpenNewsArchive
数据集标签:【预训练数据】【英文】【新闻领域】
数据集介绍:开放新闻库数据集(OpenNewsArchive)是由OpenDataLab、联合蜜度、商汤等多家联盟机构进行开源开发,其中包含了880万篇新闻文章的信息,涵盖了各种不同主题和来源的新闻内容。每篇新闻文章包括字段如标题、内容、发布日期、语言等,且数据集的内容经过数据清洗去重等处理,为研究人员和数据科学家提供了丰富的文本数据资源。以下是数据集的三大亮点:内容全面覆盖多个板块:包含财经、健康、军事、体育、房产、社会、学术等多个板块分类的新闻内容,涵盖广泛。无毒性内容和价值偏见:新闻内容不含有害信息或偏见观点,确保信息公正客观。保持新闻内容更新:数据集中包含的新闻大多数在2023年发布,与其他数据集不同,避免了历史数据集中年代久远的问题,确保新闻时效性。
数据集下载:https://opendatalab.org.cn/OpenDataLab/OpenNewsArchive
数据集来源:https://opendatalab.org.cn/OpenDataLab/OpenNewsArchive
数据集条数:27GB;880万篇文章
数据集格式:

【037】chinese-poetry
数据集名称:chinese-poetry
数据集标签:【预训练数据】【中文】【文学领域】
数据集介绍:The most comprehensive database of Chinese poetry 🧶最全中华古诗词数据库, 唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。
数据集下载:https://github.com/chinese-poetry/chinese-poetry
数据集来源:https://github.com/chinese-poetry/chinese-poetry
数据集条数:21k
数据集格式:

【XXX】更多预训练数据集链接
1.https://huggingface.co/datasets
2.https://github.com/lmmlzn/Awesome-LLMs-Datasets
3.https://mp.weixin.qq.com/s/e80F0LxA_WGlmOfVDnPirQ
4.https://huggingface.co/BAAI
5.https://huggingface.co/spaces/bigscience/BigScienceCorpus
6.天池:https://tianchi.aliyun.com/dataset/
7.千言数据集:https://www.luge.ai/#/
8.THUOCL:清华大学开放中文词库http://thuocl.thunlp.org/
9.https://mp.weixin.qq.com/s/GdkA3C0znsX6H9odFRZ8yw
10.FreedomAI:https://huggingface.co/FreedomIntelligence
11.NLP工程化数据集预料库
·END·
■ ■ ■ ■
#LLM数据工程1
阅读 300
















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











