






ViT 原理解析 (Transformers for Image Recognition at Scale)
原创 小白 小白研究室 2024年06月10日 21:09 北京

如何将 transformer 应用到图像领域
Transformer模型最开始是用于自然语言处理(NLP)领域的,NLP主要处理的是文本、句子、段落等,即序列数据。
视觉领域处理的是图像数据,因此将Transformer模型应用到图像数据上面临着诸多挑战,理由如下:
-
与单词、句子、段落等文本数据不同,图像中包含更多的信息,并且是以像素值的形式呈现。
-
如果按照处理文本的方式来处理图像,即逐像素处理的话,复杂度较高,硬件难以实现。
-
Transformer缺少CNNs的归纳偏差,比如平移不变性和局部受限感受野。
-
CNNs是通过相似的卷积操作来提取特征,随着模型层数的加深,感受野也会逐步增加。但是由于Transformer的本质,其在计算量上会比CNNs更大。
-
Transformer无法直接用于处理基于网格的数据,比如图像数据。
为了解决上述问题,Google的研究团队提出了ViT模型,它的本质其实也很简单,既然Transformer只能处理序列数据,那么我们就把图像数据转换成序列数据就可以了呗。下面来看下ViT是如何做的。
基本结构
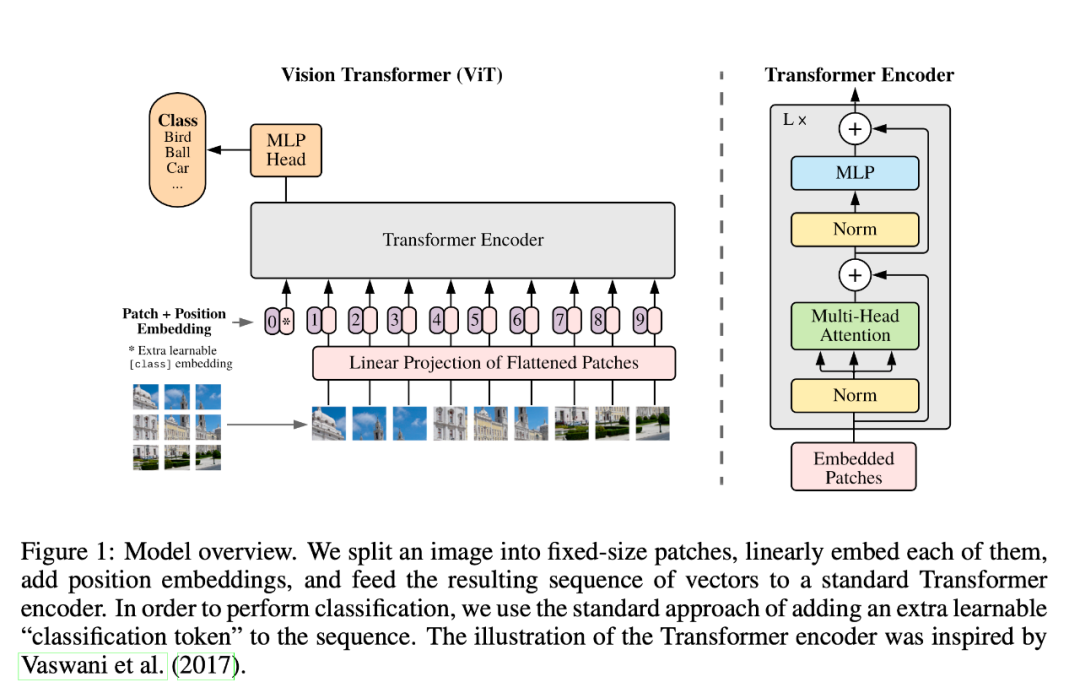
另外,从网上也看到有人绘制了比较详细的算法结构图,对于理解 ViT 也是有比较大的帮助,就复用粘贴在这里供大家学习:
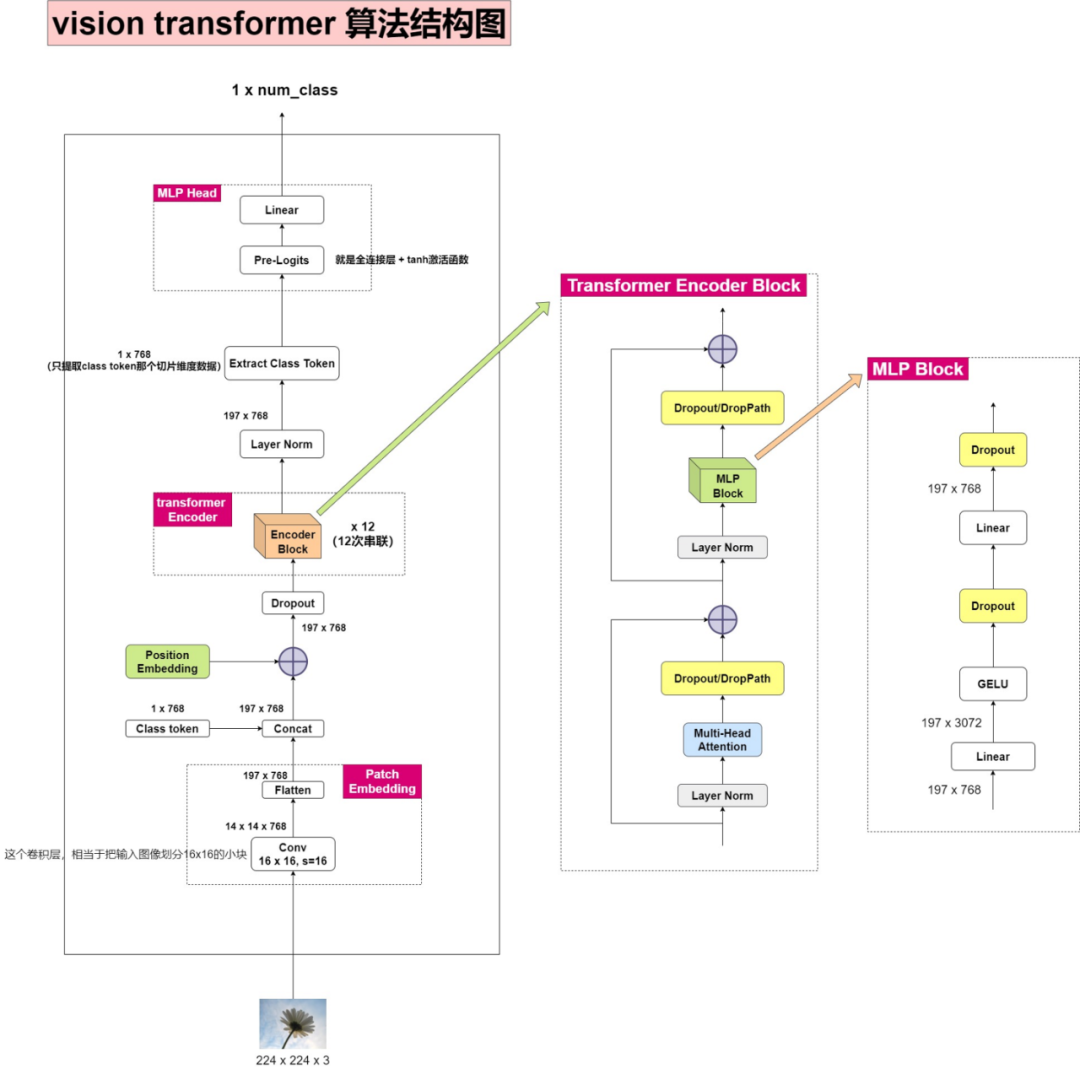
(结构图来自https://blog.csdn.net/weixin_42118657/article/details/121789116)
模块细节
将图片转换成 patches 序列
对于图像数据而言,其数据格式为[H, W, C],是三维矩阵,明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。
首先将一张图片按给定大小分成一堆Patches。
以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
# https://github.com/lucidrains/vit-pytorch/blob/90be7233a3f55c29692a72da6ee4dcb5aab267d4/vit_pytorch/twins_svt.py#L59
class PatchEmbedding(nn.Module):
def __init__(self, *, dim, dim_out, patch_size):
super().__init__()
self.dim = dim
self.dim_out = dim_out
self.patch_size = patch_size
self.proj = nn.Sequential(
LayerNorm(patch_size ** 2 * dim),
nn.Conv2d(patch_size ** 2 * dim, dim_out, 1),
LayerNorm(dim_out)
)
def forward(self, fmap):
p = self.patch_size
fmap = rearrange(fmap, 'b c (h p1) (w p2) -> b (c p1 p2) h w', p1 = p, p2 = p)
return self.proj(fmap)
这里增加了 class token,class token的维度是[1,768],然后将其与第1步得到的tokens进行拼接,即Cat([1, 768], [196, 768]) -> [197, 768]。
在传统CNN分类任务中,会对最后卷积输出的 feature map 进行一个 global average pooling 操作,用以进行最后的类别预测;在 vision transformer 里面能否进行相同的操作呢,即把 16 个 patch 的 token 进行一个 average pooling 来替代 class token。作者消融实验下来验证是可以的,但是要验证使用不同的学习率。论文中作者是为了尽可能的和 transformer 结构保持一致、所以才默认使用了 class token (In order to stay as close as possible to the original Transformer model)
添加 Position embedding

从公式可以看出,其实一个词语的位置编码是由不同频率的余弦函数函数组成的,从低位到高位,余弦函数对应的频率由 1 降低到了 110000 ,按照论文中的说法,也就是,波长从 2𝜋 增加到了 10000⋅2𝜋 。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
Transformer Encoder
将patch embedding和class token拼接起来输入标准的Transformer Encoder中。
Transformer的架构图:
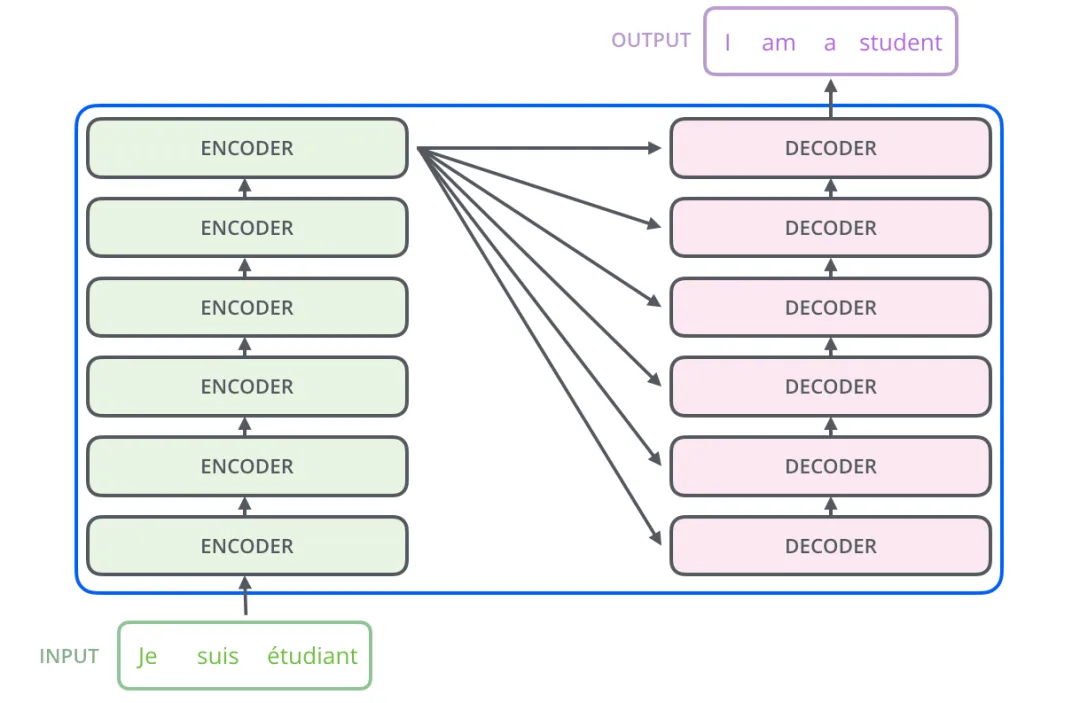
Transformer是由一堆encoder和decoder形成的,那encoder一般的架构图如下:
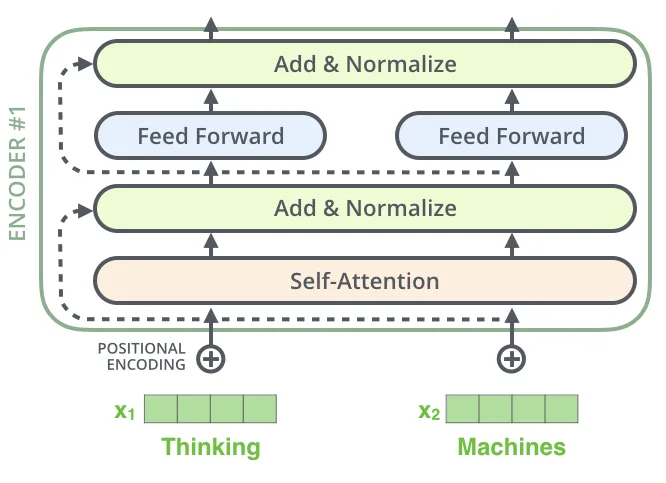
Transformer Encoder其实就是重复堆叠Encoder Block L次,实现细节如下面代码所示(layer normalization -> multi-head attention -> drop path -> layer normalization -> mlp -> drop path)
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
# 将每个样本的每个通道的特征向量做归一化
# 也就是说每个特征向量是独立做归一化的
# 我们这里虽然是图片数据,但图片被切割成了patch,用的是语义的逻辑
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
# 全连接,激励,drop,全连接,drop,若out_features没填,那么输出维度不变。
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
# 最后一维归一化,multi-head attention, drop_path
# (B, N, C) -> (B, N, C)
x = x + self.drop_path(self.attn(self.norm1(x)))
# (B, N, C) -> (B, N, C)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
分类头
注意Transformer Encoder的输出其实也是一个序列,但是在ViT模型中只使用了class token的输出,将其送入MLP模块中,去输出最终的分类结果。
参考资料
-
https://github.com/google-research/vision_transformer
-
https://blog.csdn.net/weixin_42118657/article/details/121789116
-
https://blog.csdn.net/lsb2002/article/details/135320751
-
https://zhuanlan.zhihu.com/p/338592312
-
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?- 猛猿的回答 - https://www.zhihu.com/question/347678607/answer/2301693596
-
https://zhuanlan.zhihu.com/p/427388113
-
【ViT论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV15P4y137jb/?share_source=copy_web&vd_source=fe71fe6eb662a29ef2a5866a5fa7b14a
















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











