










情感分析和数据集
Sentiment Analysis and the Dataset Natural Language Processing:
Applications
如图1所示,描述使用不同类型的深度学习架构(如MLPs、cnn、rnn和attention)设计自然语言处理模型的基本思想。虽然在图1中,可以将任何预训练文本表示与任何体系结构结合起来,用于任何下游的自然语言处理任务,但是选择了一些具有代表性的组合。具体来说,将探索基于RNNs和CNNs的流行架构来进行情感分析。对于自然语言推理,选择注意力和MLPs来演示如何分析文本对。最后,介绍了如何在序列级(单个文本分类和文本对分类)和令牌级(文本标记和问答)上微调预训练的BERT模型。作为一个具体的实证案例,将对BERT进行微调,使其适用于自然语言处理。
BERT需要对广泛的自然语言处理应用程序进行最小的体系结构更改。然而,这种好处是以为下游应用程序微调大量BERT参数为代价的。在空间或时间有限的情况下,基于MLPs、CNNs、RNNs和attention构建的模型更加可行。接下来,从情感分析应用程序入手,分别阐述了基于RNNs和CNNs的模型设计。
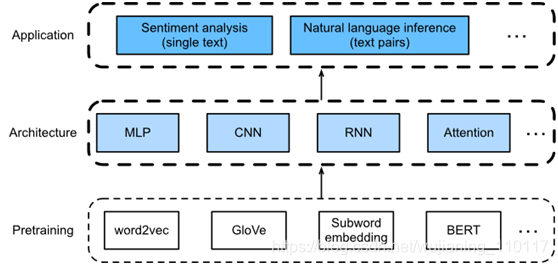
Fig. 1 Pretrained text representations can be fed to various deep learning architectures for different downstream natural language processing applications. This chapter focuses on how to design models for different downstream natural language processing applications.
文本分类是自然语言处理中的一项常见任务,将不确定长度的文本序列转化为一类文本。类似于本书中最常用的应用程序图像分类。唯一的区别是,文本分类的例子是文本句子,而不是图像。
这一部分将着重于为这一领域的一个子问题加载数据:使用文本情感分类来分析文本作者的情绪。这个问题也被称为情绪分析,有着广泛的应用。例如,可以分析用户对产品的评论,以获得用户满意度统计数据,或者分析用户对市场状况的情绪,并用来预测未来的趋势。
from d2l import mxnet as d2l
from mxnet import gluon, np, npx
import os
npx.set_np()
- The Sentiment Analysis Dataset
使用斯坦福大学的大型电影评论数据集作为情绪分析的数据集。该数据集分为两个数据集,用于训练和测试,每个数据集包含从IMDb下载的25000个电影评论。在每个数据集中,标记为“正”和“负”的注释数相等。
1.1. Reading the Dataset
首先将这个数据集下载到“…/data”路径并将其提取到“…/data/aclImdb”。
#@save
d2l.DATA_HUB[‘aclImdb’] = (
'http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz',
'01ada507287d82875905620988597833ad4e0903')
data_dir = d2l.download_extract(‘aclImdb’, ‘aclImdb’)
Downloading …/data/aclImdb_v1.tar.gz from http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz…
接下来,阅读训练和测试数据集。每个例子都是一个评论,对应的标签是:1表示“积极”,0表示“消极”。
#@save
def read_imdb(data_dir, is_train):
data, labels = [], []
for label in ('pos', 'neg'):
folder_name = os.path.join(data_dir, 'train' if is_train else 'test', label)
for file in os.listdir(folder_name):
with open(os.path.join(folder_name, file), 'rb') as f:
review = f.read().decode('utf-8').replace('\n', '')
data.append(review)
labels.append(1 if label == 'pos' else 0)
return data, labels
train_data = read_imdb(data_dir, is_train=True)
print(’# trainings:’, len(train_data[0]))
for x, y in zip(train_data[0][:3], train_data[1][:3]):
print(‘label:’, y, ‘review:’, x[0:60])
# trainings: 25000
label: 1 review: Normally the best way to annoy me in a film is to include so
label: 1 review: The Bible teaches us that the love of money is the root of a
label: 1 review: Being someone who lists Night of the Living Dead at number t
1.2. Tokenization and Vocabulary
使用一个单词作为标记,然后根据训练数据集创建字典。
train_tokens = d2l.tokenize(train_data[0], token=‘word’)
vocab = d2l.Vocab(train_tokens, min_freq=5, reserved_tokens=[’’])
d2l.set_figsize((3.5, 2.5))
d2l.plt.hist([len(line) for line in train_tokens], bins=range(0, 1000, 50));
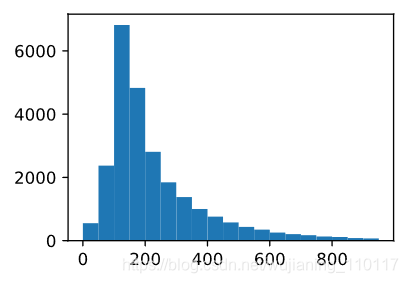
1.3. Padding to the Same Length
因为评审的长度不同,所以不能直接组合成小批量。这里通过截断或添加“”索引将每条注释的长度固定为500。
num_steps = 500 # sequence length
train_features = np.array([d2l.truncate_pad(
vocab[line], num_steps, vocab['<pad>']) for line in train_tokens])
train_features.shape
(25000, 500)
1.4. Creating the Data Iterator
将创建一个数据迭代器。每次迭代都将返回一小批数据。
train_iter = d2l.load_array((train_features, train_data[1]), 64)
for X, y in train_iter:
print('X', X.shape, 'y', y.shape)
break
‘# batches:’, len(train_iter)
X (64, 500) y (64,)
(’# batches:’, 391)
- Putting All Things Together
将把一个函数load_data_imdb保存到d2l中,返回词汇表和数据迭代器。
#@save
def load_data_imdb(batch_size, num_steps=500):
data_dir = d2l.download_extract('aclImdb', 'aclImdb')
train_data = read_imdb(data_dir, True)
test_data = read_imdb(data_dir, False)
train_tokens = d2l.tokenize(train_data[0], token='word')
test_tokens = d2l.tokenize(test_data[0], token='word')
vocab = d2l.Vocab(train_tokens, min_freq=5)
train_features = np.array([d2l.truncate_pad(
vocab[line], num_steps, vocab.unk) for line in train_tokens])
test_features = np.array([d2l.truncate_pad(
vocab[line], num_steps, vocab.unk) for line in test_tokens])
train_iter = d2l.load_array((train_features, train_data[1]), batch_size)
test_iter = d2l.load_array((test_features, test_data[1]), batch_size,
is_train=False)
return train_iter, test_iter, vocab
- Summary
· Text classification can classify a text sequence into a category.
· To classify a text sentiment, we load an IMDb dataset and tokenize its words. Then we pad the text sequence for short reviews and create a data iterator.














 7336
7336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









