







 本文深入探讨了GPU的GPGPU指令执行设计,包括指令执行流水线、吞吐影响因素、特点以及CUDA微架构与指令集。讨论了GPGPU的指令执行流程、吞吐量与指令集设计的关系,强调了静态资源分配、顺序执行和显式解决依赖等特性,并分析了如何优化指令发射和warp调度以提高性能。
本文深入探讨了GPU的GPGPU指令执行设计,包括指令执行流水线、吞吐影响因素、特点以及CUDA微架构与指令集。讨论了GPGPU的指令执行流程、吞吐量与指令集设计的关系,强调了静态资源分配、顺序执行和显式解决依赖等特性,并分析了如何优化指令发射和warp调度以提高性能。
GPU指令集技术分析
本文将两篇文章整理了一下。
参考文章链接如下:
https://zhuanlan.zhihu.com/p/391238629
https://zhuanlan.zhihu.com/p/166180054
一.GPGPU- 指令执行设计
本节主要内容:
• GPGPU指令执行简介
o GPGPU指令执行流水线
o GPGPU指令执行吞吐的影响因素
o GPGPU指令执行的特点
• 指令设计中的一些原则与思路
o 指令长度的问题
o 指令集设计与ILP的一些相关性
o 复合操作与附加操作
o 立即数操作数和Constant Memory操作数
o 格式的通用性与信息具体化
• 简单聊聊一些具体的指令
o FMA, MUL, ADD 系列
o IMAD, LEA, IADD3
o LOP3
o MUFU
o FSETP
o LDG/STG, LDS/STS, LDL/STL
o BAR
• 结语
二.CUDA微架构与指令集-指令发射与warp调度
CUDA指令的发射和warp调度问题。
指令发射的基本逻辑,主要是指令发射需要满足的条件,几代架构发射指令的一些简单描述等等。
control codes,主要是它与指令发射和warp调度的关系。
warp Scheduler的功能。
峰值算力的计算方法和达成条件。
现在分开来叙述
一.GPGPU- 指令执行设计
GPGPU指令吞吐和指令集设计的一些问题。NV GPU的机器码指令集叫SASS。
指令集是微架构与用户对接的途径。指令集相当于硬件提供给软件的API(或者也可以认为指令集是输入前端,微架构是执行后端)。按照
GPGPU指令执行简介
GPGPU指令执行流水线
首先,先简单介绍一下通用处理器的指令执行逻辑。对RISC V一种简单的五级流水线实现的描述:
- Instruction fetch cycle (IF):主要是获得Program Counter对应的指令内容。
- Instruction decode/register fetch cycle (ID):解码指令,同时读取输入寄存器的内容。由于RISC类指令的GPR编码位置相对固定,所以可以直接在解码时去读取GPR的值。
- Execution/effective address cycle (EX):这是指令进入执行单元执行的过程。比如计算memory地址的具体位置(把base和offset加起来),执行输入输出都是GPR或输入含立即数的ALU指令,或者是确认条件跳转指令的条件是否为真等。
- Memory access (MEM):对于load指令,读取相应的内存内容。对于store指令,将相应GPR的值写入到内存地址处。RISC类指令集通常都是load-store machine,ALU指令不能直接用内存地址做操作数(只能用GPR或立即数),因而通常ALU指令没有memory access。
- Write-back cycle (WB):将相应的ALU计算结果或memory load结果写入到相应的GPR中。
与复杂的CISC指令集相比,多数GPGPU的指令集还是比较接近load-store machine,总体来说与RISC更相似一些。GPGPU典型微架构可以简单表示为下图:
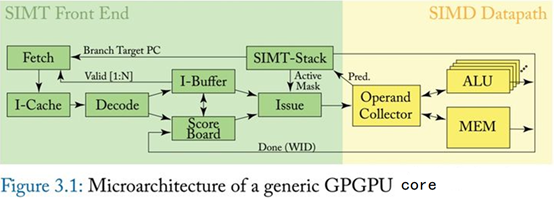
GPGPU指令执行流程示意图
这个图是微架构的模块示意图,而非流水线示意图。实际执行流程中Fetch、Decode、Execution这三步是必须的,而Memory access显然只针对memory指令,write-back则只针对需要写回的指令(比如memory load,带GPR输出的指令等)。
注:流水线的配置与ALU的latency有很大的关系。比如Volta前FFMA的延迟是6cycle,Volta及之后FFMA的延迟是4cycle,这绝对与流水线的改进有关。不过,这里的Latency并不是所有流水线的级数。因为Latency在程序中的表现形式是:一个指令发射后,其结果需要多少周期才能就绪(也就是能被其他指令使用)。两个back-to-back dependent的ALU指令(比如FFMA R0, R1, R2, R0; FFMA R0, R3, R4, R0;),前一个FFMA只要在第二个FFMA读取操作数之前把结果写回GRF,那后一个FFMA就可以得到正确值。对应到上面的5级流水线形式,就是前一个指令的WB要在后一个指令的ID前执行完就行(相当于4cycle延迟),最开始的IF那一级是不影响的。CPU对于这种形式的依赖还有更激进的旁路逻辑(forwarding),可以直接在前一个ALU的EX后把结果直接送给后一个ALU的EX当输入,从而减少流水线的bubble,提高性能。NV的GPU应该是没有这么紧凑的forwarding,但是NV的operand collector可以作为一个公共的操作数中转站,理论上前一个ALU的结果写回到operand collector就可以被下一个ALU看到了,不一定要回到GRF。
由于GPU运行模型的复杂性,在Decode后Execution前,还有大量其它的步骤:比如scoreboard的判断(主要用来保证每个指令的执行次序,防hazard),warp Scheduler的仲裁(多个eligible warp中选一个),dispatch unit和dispatch port的仲裁(发射或执行资源冲突时需要等待),还可能有读取作为立即数操作数的constant memory,读取predicate的值生成执行mask,等等。在执行过程中,也有很多中间步骤,比如输入GPR操作数的bank仲裁,跳转指令要根据跳转目标自动判断divergence并生成对应的mask,访存指令要根据地址分布做相应的请求广播、合并等等。在写回这一级的时候,由于一些指令的完成是异步的(比如一些内存指令),所以也可能需要GPR端口的仲裁,等等。
当然,步骤虽然多而琐碎,但未必都会新增单独的一级流水。GPU应该是为了简化设计和节约功耗,不愿意把流水线拉得太细长,因而很多操作都是塞在同一级流水线里,各种组合逻辑非常复杂。这样也导致它的主频往往就不能太高。比如最近几代NV GPU旗舰和次旗舰的主频:
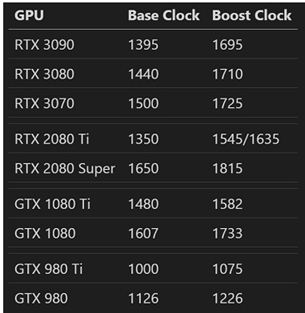
可以看到主频基本都在1~2 GHz之间,次旗舰的频率往往比旗舰要稍高一些(这里选的公版频率,但非公也大致是这个趋势),有些低端芯片频率可能还会更高一点。而如今(2021年)常见的桌面端x86 CPU,基准频率3~4 GHz,最大睿频4~5 GHz是很寻常的事。很多Arm CPU的大核,主频也能接近甚至超过3 GHz。当然,这么比也许不是特别公平。因为多数独立GPU的功耗很大,会极大的限制频率提升。一些众核CPU的频率也会比少核版的降一些,不过差别不会太大(类似上面GPU的旗舰与次旗舰的关系)。但即使算上这些,GPU的主频比常见CPU的主频还是显著低一些(实际上带核芯显卡的CPU里,GPU频率往往也是显著小于CPU频率)。这里面具体的因果关系我也不是特别明白,感觉肯定还是有些故事的~
GPGPU指令执行吞吐的影响因素
指令执行吞吐一般指的是每个时钟周期内可以执行的指令数目,不同指令的吞吐会有所不同。通常GPU的指令吞吐用每个SM每周期可以执行多少指令来计量。对于多数算术逻辑指令而言,指令执行吞吐只与SM内的单元有关,整个GPU的吞吐就是每个SM的吞吐乘以SM的数目。而GPU的FMA指令(通常以F32计算)往往具有最高的指令吞吐,其他指令吞吐可能与FMA吞吐一样,或是只有一半、四分之一等等。所以很多英文文档会说FMA这种是full throughput,一半吞吐的是half rate,四分之一的是quarter rate等。当然,有些微架构下也会有1/3、1/6之类非2的幂次的比率。NV GPU近几代微架构的常见指令吞吐如下:
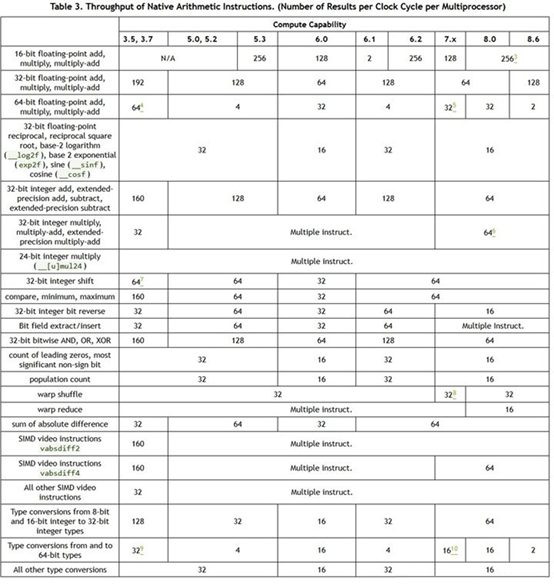
CUDA算术逻辑指令吞吐表
从图中可以发现,指令吞吐不仅与指令类型有关,还与微架构具体设计实现有关。主要会受到以下一些因素的影响:
- 功能单元的数目。绝大多数指令的功能都需要专用或共享的硬件资源去实现,设计上配置的功能单元多,指令执行的吞吐才可能大。显然,只有最常用的那些指令,才能得到最充分的硬件资源。而为了节约面积,很多指令的功能单元会相互共享,所以他们的吞吐往往也会趋于一致。比如浮点的FFMA、FMUL都要用到一个至少24bit的整数乘法器(32bit浮点数有23bit尾数,小数点前还有1bit)。以前一些处理器有24bit的整数乘法指令,两者乘法器就可以共用,从而具有相同的吞吐(不过NV最近几代好像都没有这个指令,ptx以及内置函数的24bit乘法应该是多个指令模拟的)。而FADD虽然用不上那个乘法器,但可以与FFMA共用那个很宽的加法器,以及一些通用的浮点操作(特殊数的处理,subnormal flush之类)。32bit的整数乘法因为需要更宽的乘法器,有的就不会做成full throughput,甚至可能被拆分成多个指令(比如Maxwell和Pascal用三个16bit乘法指令XMAD完成一次32bit整数乘法)。Turing的IMAD应该是有意识的加宽了,所以32bit的IMAD与FFMA吞吐一样,但印象中带64bit加数的IMAD应该还是一半。再比如一些超越函数指令(MUFU类,比如rcp,rsq,sin,exp之类),由于实际使用量相对不会太频繁,多数是1/4的throughput。
- 指令Dispatch Port和Dispatch Unit的吞吐。这个在之前的专栏文章也详细讲过。一个warp的指令要发射,首先要eligible,也就是不要因为各种原因stall,比如指令cache miss,constant immediate的miss,scoreboard未就位,主动设置了stall count等等。其次要被warp scheduler选中,由Dispatch Unit发送到相应的Dispatch Port上去。Kepler、Maxwell和Pascal是一个Warp Scheduler有两个Dispatch Unit,所以每cycle最多可以发射两个指令,也就是双发射。而Turing、Ampere每个Warp Scheduler只有一个Dispatch Unit,没有双发射,那每个周期就最多只能发一个指令。但是Kepler、Maxwell和Pascal都是一个Scheduler带32个单元(这里指full-throughput的单元),每周期都可以发新的warp。而Turing、Ampere是一个Scheduler带16个单元,每个指令要发两cycle,从而空出另一个cycle给别的指令用。最后要求Dispatch Port或其他资源不被占用,port被占的原因可能是前一个指令的执行吞吐小于发射吞吐,导致要Dispatch多次,比如Turing的两个FFMA至少要stall 2cycle,LDG之类的指令至少是4cycle。更详细的介绍大家可以参考之前的专栏文章。
- GPR读写吞吐。绝大部分的指令都要涉及GPR的读写,由于Register File每个bank每个cycle的吞吐是有限的(一般是32bit),如果一个指令读取的GPR过多或是GPR之间有bank conflict,都会导致指令吞吐受影响。GPR的吞吐设计是影响指令发射的重要原因之一,有的时候甚至占主导地位,功能单元的数目配置会根据它和指令集功能的设计来定。比如NV常用的配置是4个Bank,每个bank每个周期可以输出一个32bit的GPR。这样FFMA这种指令就是3输入1输出,在没有bank conflict的时候可以一个cycle读完。其他如DFMA、HFMA2指令也会根据实际的输入输出需求,进行功能单元的配置。
- 很多指令有replay的逻辑,这就意味着有的指令一次发射可能不够。这并不是之前提过的由于功能单元少,而连续占用多轮dispath port,而是指令处理的逻辑上有需要分批或是多次处理的部分。比如constant memory做立即数时的cache miss,memory load时的地址分散,shared memory的bank conflict,atomic的地址conflict,甚至是普通的cache miss或是TLB的miss之类。根据上面Greg的介绍,Maxwell之前,这些replay都是在warp scheduler里做的,maxwell开始将它们下放到了各级功能单元,从而节约最上层的发射吞吐。不过,只要有replay,相应dispath port的占用应该是必然的,这样同类指令的总发射和执行吞吐自然也就会受影响。
几个需要注意的点: - 指令发射吞吐和执行吞吐有时会有所区别。有些指令有专门的Queue做相应的缓存,这样指令发射的吞吐会大于执行的吞吐。这类指令通常需要访问竞争性资源,比较典型的是各种访存指令。但也有一些ALU指令,比如我们之前提过的Turing的I2F只有1/4的吞吐,但是可以每cycle连发(也就是只stall 1cycle)。不过多数ALU指令的发射吞吐和执行吞吐是匹配的。
- 要注意区分指令吞吐与常说的FLOPS或是IOPS的区别。通常的FLOPS和IOPS是按乘法和加法操作次数计算,这样FMUL、FADD是一个FLOP,FFMA是两个FLOP。这也是通常计算峰值FLOPS时乘2的由来。但是有些指令,可以计算更多FLOP。比如HFMA2 R0, R1, R2, R3;可以同时算两组F16的FMA,相当于每个GPR上下两个16bit分开独立计算(类似于CPU的SIMD指令),所以SM86以前的架构HFMA2的指令吞吐与FFMA是一样的,只是每条指令算4个F16的FLOP,而FFMA是2个F32的FLOP。这也就是TensorCore出现前F16的峰值通常是F32两倍的原因。DFMA由于输入宽度比FFMA再翻倍,所以功能单元做成一半就能把GPR吞吐用满(这里说的是满配Tesla卡,消费卡F64常有缩减)。因此,在TensorCore出现以前,通常的Tesla卡HFMA2、FFMA的指令吞吐一样,DFMA吞吐是一半,而看峰值FLOP就是H:F:D=4:2:1的关系。TensorCore出现后,指令(比如HMMA)本身的吞吐和指令入口的GPR输入量没有变化,但由于同一个warp的指令可以相互共享操作数数据,一个指令能算的FLOP更多了,因而峰值又提高了。当然,这里说的是一般情况,实际上根据产品市场定位的不同,有些功能可能会有所调整。
- SM86(Ampere的GTX 30系列)的F32比较另类。Turing把普通ALU和FFMA(包括FFMA、FMUL、FADD、IMAD等)的PIPE分开,从而一般ALU指令可以与FFMA从不同的Dispatch Port发射,客观上是增加了指令并行度。NVIDIA对CUDA Core的定义是F32核心的个数,所以Turing的一个SM是64个Core。Ampere则把一般ALU PIPE中再加了一组F32单元,相当于一个SM有了128个F32单元(CUDA Core),但是只有64个INT32单元。也就是说SM86的F32类指令的吞吐是128/SM/cycle,但其中有一半要与INT32的64/SM/cycle共享。或者说,Turing的F32和INT32可以同时达到峰值(包括A100),而SM86的INT32和F32不能同时达到峰值。
GPGPU指令执行的特点
与传统的x86 CPU相比,GPGPU在指令执行的逻辑上有很多独特的地方。
静态资源分配:GPU有一个很重要的设计逻辑是尽量减少硬件需要动态判断的部分。GPU的每个线程和block运行所需的资源尽量在编译期就确定好,在每个block运行开始前就分配完成(Block是GPU进行运行资源分配的单元,也是计算Occupancy的基础)。典型的运行资源有GPR和shared memory。GPU程序运行过程中,一般也不会申请和释放内存(当然,现在有device runtime可以在kernel内malloc和free,供Dynamic Parallelism用,但这个不影响当前kernel能用的资源)。CPU在运行过程中有很多所需的资源是动态调度的。比如,x86由于继承了祖上编码的限制,ISA的GPR数目往往比物理GPR少,导致常常出现资源冲突造成假依赖。实际运行过程中,通常会有register renaming将这些ISA GPR映射到不同的物理GPR,从而减少依赖(有兴趣的同学可以研究下tomasulo算法)。GPU没有这种动态映射逻辑,每个线程的GPR将一一映射到物理GPR。由于每个线程能用的GPR通常较多,加上编译器的指令调度优化,这种假依赖对性能的影响通常可以降到很低的程度。
每个block在运行前还会分配相应的shared memory,这也是静态的。这里需要明确的是,每个block的shared memory包括两部分,写kernel时固定长度的静态shared memory,以及启动kernel时才指定大小的动态shared memory。虽然这里也分动静态,但指的是编译期是否确定大小,在运行时总大小在kernel启动时已经确定了,kernel运行过程中是不能改变的。
其实block还有一些静态资源,比如用来做block同步的barrier,每个block最多可以有16个。我暂时没测试到barrier的数目对Occupancy的影响,也许每个block都可以用16个。另一种是Turing后才出现的warp内的标量寄存器Uniform Register,每个warp 63个+恒零的URZ。因为每个warp都可以分配到足额,应该对Occupancy也没有影响。另外每个线程有7个predicate,每个warp有7个Uniform predicateÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









