







AI编译器TVM部署示例解析
AI编译器TVM(一)——一个简单的例子
概述
什么是TVM?
TVM可以称为许多工具集的集合,这些工具可以组合起来使用,实现一些神经网络的加速和部署功能。这也是为什么叫做TVM Stack了。TVM的使用途径很广,几乎可以支持市面上大部分的神经网络权重框架(ONNX、TF、Caffe2等),也几乎可以部署在任何的平台,如Windows、Linux、Mac、ARM等等。
参考文献
https://oldpan.me/archives/the-first-step-towards-tvm-1
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484929&idx=1&sn=3fcce36b5a50cd8571cf932a23083667&chksm=cf109e04f86717129c3381ebeec2d0c1f7baf6ed057c66310662f5935beea88baf23e99898f4&token=1276531538&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484930&idx=1&sn=ddc3da7b72c900ce2f8e6aad99a9e788&source=41#wechat_redirect
以下面一张图来形容一下,这张图来源于(https://tvm.ai/about):
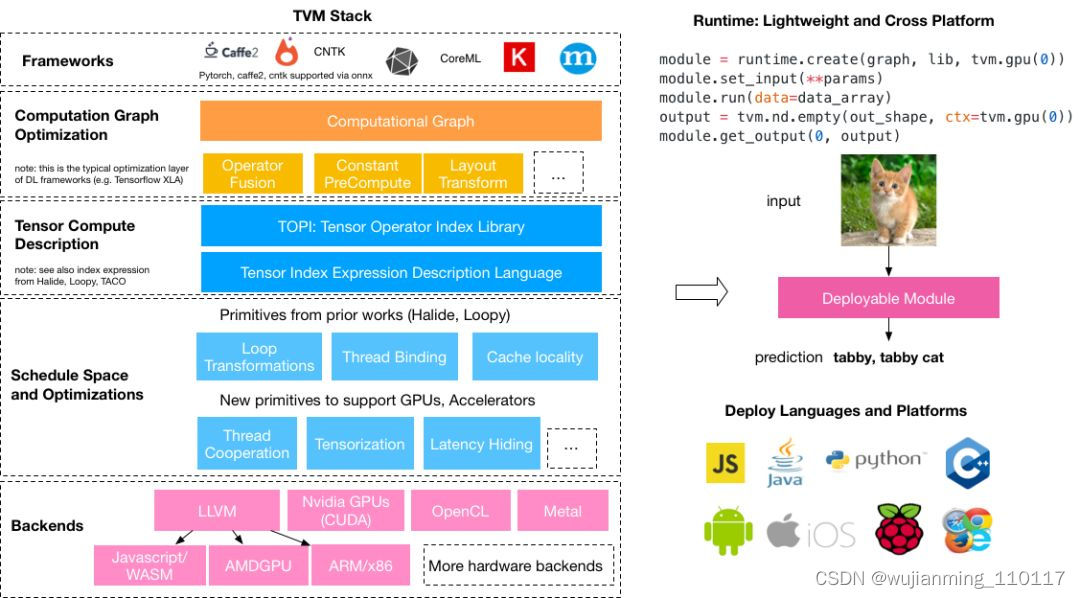
stack_tvmlang
只需要知道TVM的核心功能就可以:TVM可以优化的训练好的模型,将模型打包好,将这个优化好的模型放在任何平台去运行,可以说是与落地应用息息相关。
TVM包含的东西和知识概念都有很多,不仅有神经网络优化量化op融合等一系列步骤,还有其他更多细节技术的支持(Halide、LLVM),从而使TVM拥有很强大的功能。如果想多了解TVM的可以在知乎上直接搜索TVM关键字,那些大佬有很多关于TVM的介绍文章,大家可以去看看。
其实做模型优化这一步骤的库已经出现很多了,不论是Nvidia自家的TensorRT,还是Pytorch自家的torch.jit模块,都在做一些模型优化的工作,这里就不多说了,感兴趣的可以看看以下文章:
利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
利用TensorRT实现神经网络提速(读取ONNX模型并运行)
利用TensorRT对深度学习进行加速
开始使用
为什么要使用TVM?
如果想将训练模型移植到Window端、ARM端(树莓派、其他一系列使用该内核的板卡)或者其他的一些平台,利用其中的CPU或者GPU来运行,希望可以通过优化模型来使模型,在该平台运算的速度更快(这里与模型本身的算法设计无关),实现落地应用研究,那么TVM就是不二之选。另外TVM源码是由C++和Pythoh共同搭建,阅读相关源码也有利于程序编写方面的提升。
安装
安装其实没什么多说的,官方的例子说明的很详细。大家移步到那里按照官方的步骤一步一步来即可。
不过有两点需要注意下:
• 建议安装LLVM,虽然LLVM对于TVM是可选项,但是如果想要部署到CPU端,那么llvm几乎是必须的
• 因为TVM是python和C++一起的工程,python可以说是C++的前端,安装官方教程编译好C++端后,这里建议选择官方中的Method 1来进行python端的设置,这样就可以随意修改源代码,再重新编译,Python端就不需要进行任何修改就可以直接使用了。
(官方建议使用Method 1)
利用Pytorch导出Onnx模型
这里以一个简单的例子,演示一下TVM是怎么使用的。
首先要做的是,得到一个已经训练好的模型,这里选择这个github仓库中的mobilenet-v2,model代码和在ImageNet上训练好的权重都已经提供。将github中的模型代码移植到本地,然后调用并加载已经训练好的权重:
import torch
import time
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
with torch.no_grad():
model.eval()
since = time.time()
for i in range(10000):
model(example)
time_elapsed = time.time() - since
print(‘Time elapsed is {:.0f}m {:.0f}s’.
format(time_elapsed // 60, time_elapsed % 60)) # 打印出来时间
这里加载训练好的模型权重,设定了输入,在python端连续运行了10000次,这里所花的时间为:6m2s。
然后将Pytorch模型导出为ONNX模型:
import torch
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
torch_out = torch.onnx.export(model,
example,
“mobilenetv2.onnx”,
verbose=True,
export_params=True # 带参数输出
)
这样就得到了mobilenetv2.onnx这个onnx格式的模型权重。这里要带参数输出,因为之后要直接读取ONNX模型进行预测。
导出来之后,建议使用Netron来查看模型的结构,可以看到这个模型由Pytorch-1.0.1导出,共有152个op,以及输入id和输入格式等等信息,可以拖动鼠标查看到更详细的信息:
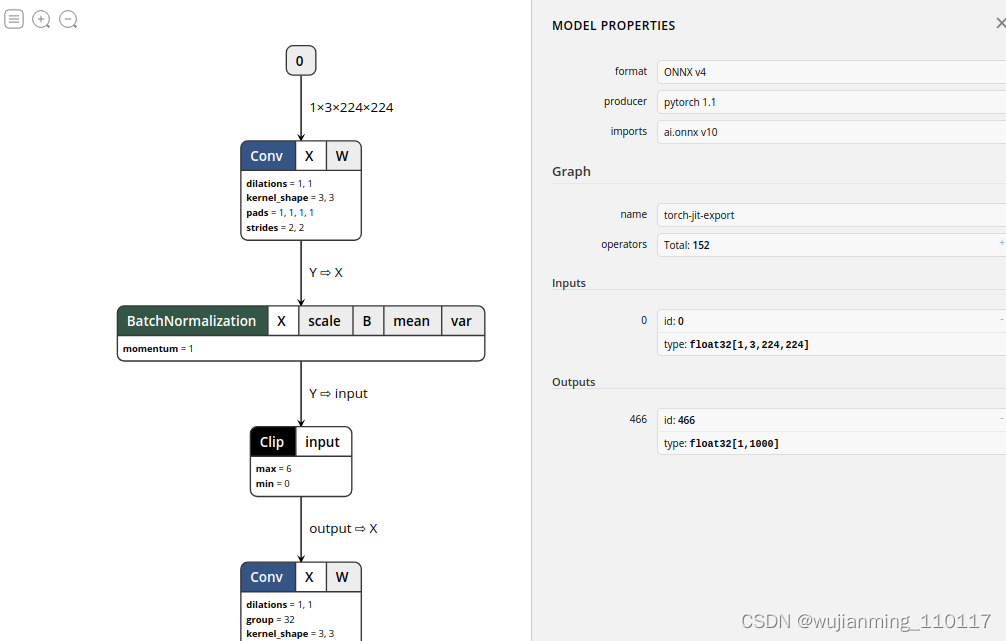
mobilenetv2-test
至此mobilenet-v2模型已经顺利导出了。
利用TVM读取并预测ONNX模型
在成功编译并且可以在Python端正常引用TVM后,首先导入onnx格式的模型。这里准备了一张飞机的图像:
tvm_plane

这个图像在ImageNet分类中属于404: ‘airliner’,也就是航空客机。
下面将利用TVM部署onnx模型并对这张图像进行预测。
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
from PIL import Image
onnx_model = onnx.load(‘mobilenetv2.onnx’) # 导入模型
mean = [123., 117., 104.] # 在ImageNet上训练数据集的mean和std
std = [58.395, 57.12, 57.375]
def transform_image(image): # 定义转化函数,将PIL格式的图像转化为格式维度的numpy格式数组
image = image - np.array(mean)
image /= np.array(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









