







 本文详细分析了Nvidia下一代Ada Lovelace GPU的规格,包括AD102、AD103、AD104和AD106的架构、性能和成本。Ada Lovelace系列预计将显著提升性能,特别是在高端的AD102,拥有96MB L2 Cache,对比上一代GA102有70%的CUDA核心增加。尽管制造成本增加,但由于工艺改进和架构优化,预计整体性能和能效将得到提升。此外,文章还探讨了AMD的Infinity Cache和Nvidia的3D芯片技术在计算领域的应用和发展趋势。
本文详细分析了Nvidia下一代Ada Lovelace GPU的规格,包括AD102、AD103、AD104和AD106的架构、性能和成本。Ada Lovelace系列预计将显著提升性能,特别是在高端的AD102,拥有96MB L2 Cache,对比上一代GA102有70%的CUDA核心增加。尽管制造成本增加,但由于工艺改进和架构优化,预计整体性能和能效将得到提升。此外,文章还探讨了AMD的Infinity Cache和Nvidia的3D芯片技术在计算领域的应用和发展趋势。
从GPU规格、架构、成本和性能说起

Nvidia 是2月底网络攻击的受害者,被黑客入侵并丢失了大量数据。这次黑客攻击不仅对英伟达来说是一场灾难,对所有芯片公司和所有“西方”国家的国家安全来说都是一场灾难。
据介绍,被黑的数据包括英伟达下一代GPU Hopper 和 Ada 的详细规格和模拟数据。Hopper现在正在发货,并由 Nvidia 在 GTC 上发布。规格与这次泄漏完全匹配,但以 Ada Lovelace 命名的 Ada 仍然需要几个月的时间。
Ada,下一代客户端和视频专业 GPU 将是本文的主题。基于泄露的规范和模拟,SemiAnalysis 和Locuza联手分析了各种芯片的架构、裸片尺寸,并对 GPU ASIC 进行成本分析。
SemiAnalysis 和Locuza没有从 LAPSUS$ hack下载任何泄露的文件,但许多人在网上分享了摘录。
根据泄漏的这些摘录 ,能够为 Nvidia 的下一代 Ada Lovelace GPU 阵容提取以下规格,并将与当前一代 Ampere GPU 阵容进行比较。
参考链接
https://mp.weixin.qq.com/s/fJfQv8_PmoEIDp8_Y74Cfg
https://mp.weixin.qq.com/s/B_pNd0662c0t1gb7HwwBsQ
https://mp.weixin.qq.com/s/bSowhmoRqVJm5jHArm6XsA
https://semianalysis.substack.com/p/nvidia-ada-lovelace-leaked-specifications?s=r
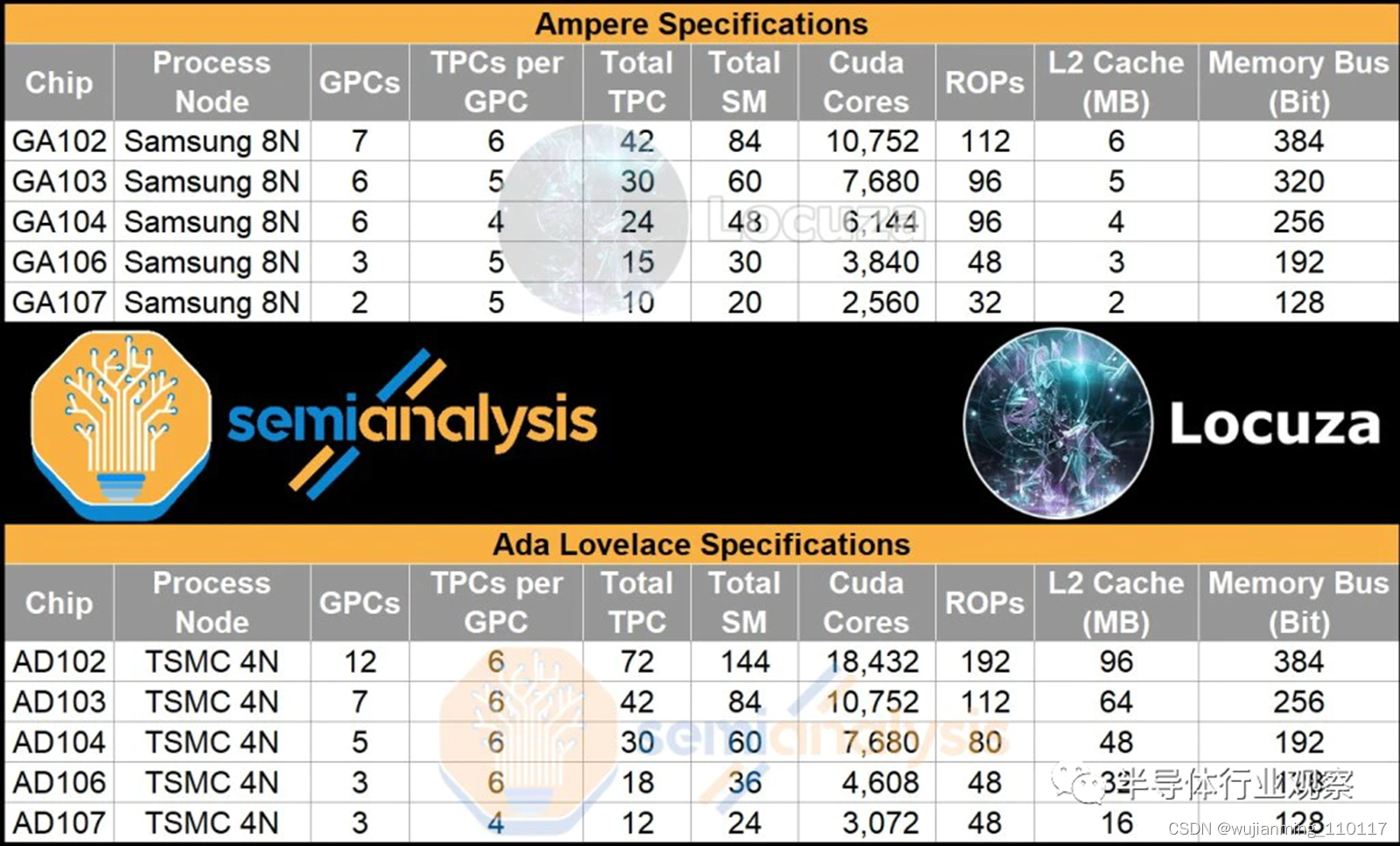
将展示每个芯片的框图、架构分析、估计的裸片尺寸、如何得出这些裸片尺寸,以及一些成本和定位分析。
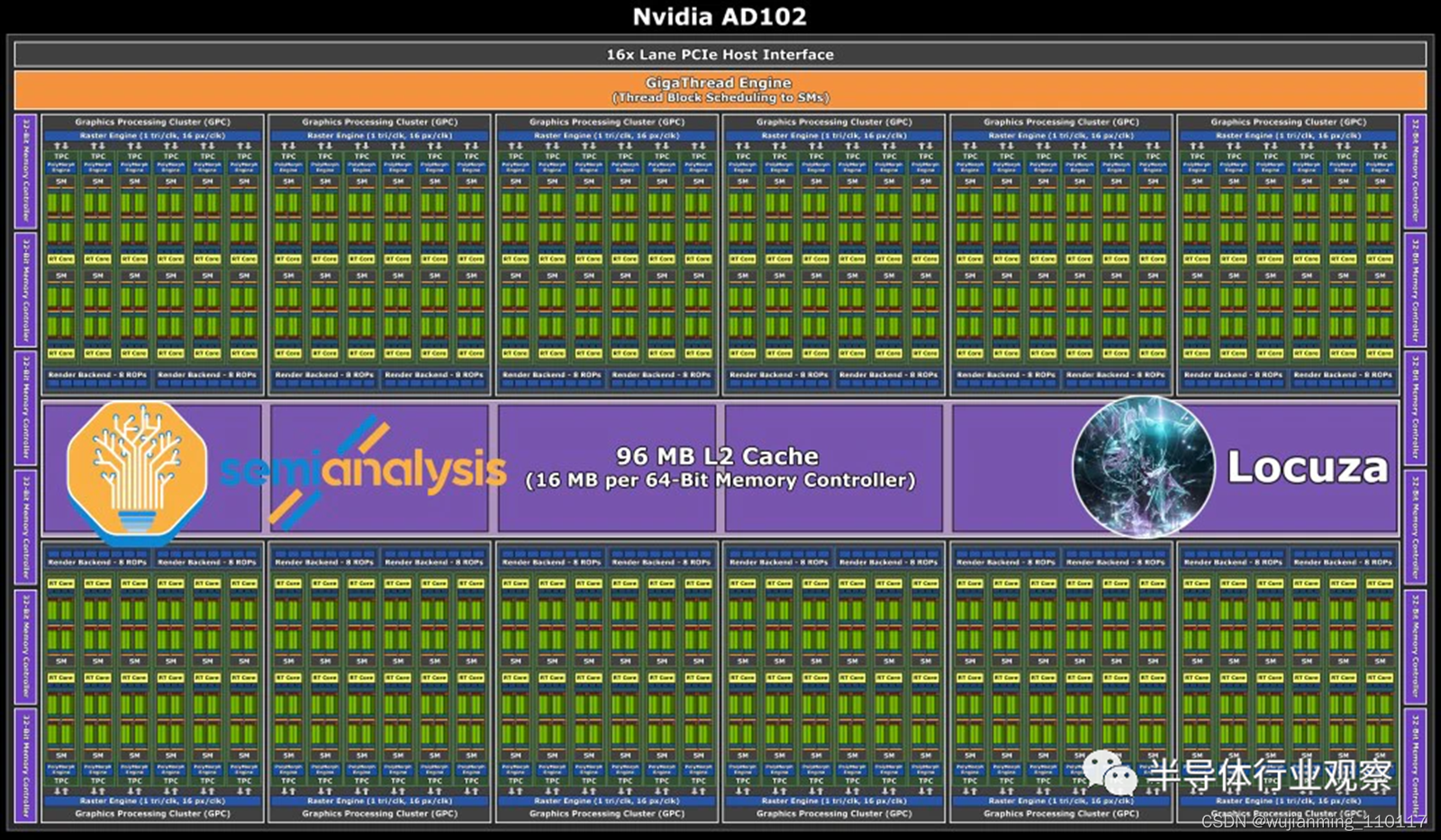
Ada 架构中的佼佼者是 AD102,估计其面积约为 611.3mm²。与上一代 GA102 相比,这是一个巨大的飞跃,因为通过 5 个额外的 GPC,获得70% 的 CUDA 内核增加。内存总线宽度则保持384 位不变,但预计内存速度会略微提高到 21Gbps 左右。尽管增加了,但这还不足支持该野兽芯片运行。AD102拥有96MB L2 Cache,远高于上一代GA102的6MB L2 Cache。
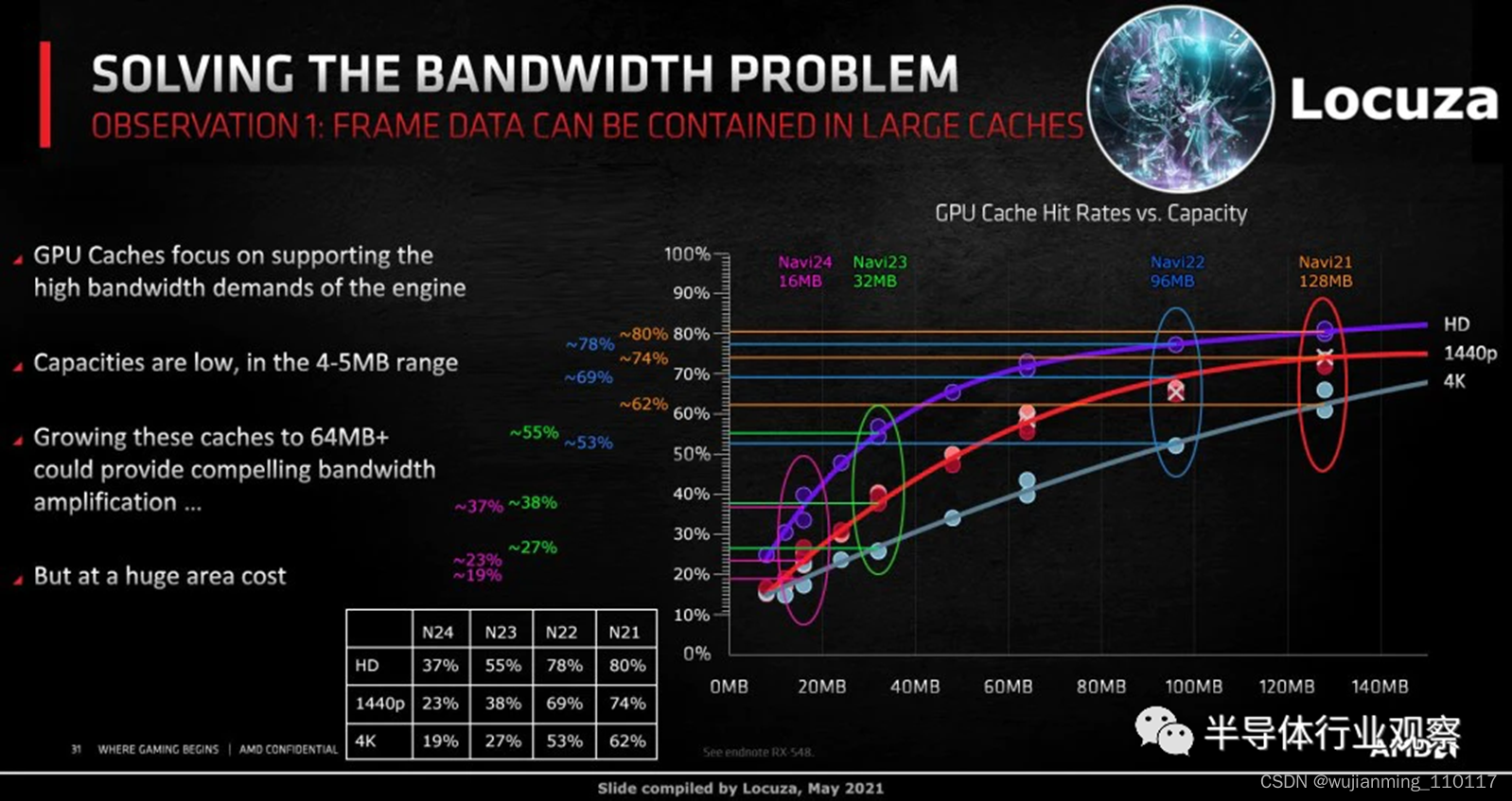
有趣的是,这与 AMD 的 Navi 22 GPU 具有“InfinityCache”的 L2 缓存数量相同。希望 Nvidia 将大型 L2 命名为“Nfinity Cache”只是为了吸引所有人。
AMD 的 Infinity Cache 是 L3 缓存,尽管两家供应商之间的缓存层次结构存在差异,但预计hit rates的总体趋势是相同的。以 AMD 为例,1080p 的hit rates为 78%,1440p 的hit rates为 69%,4k 的hit rates为 53%。这些高hit rates有助于降低内存带宽需求。
如果 Nvidia 的大型 L2 以类似的方式工作,尽管内存带宽略有增加,但将极大地帮助馈送 AD102。Ada 的高端配置应该配备24GB 的 GDDR6X,但预计会有一些配置因此而减少。
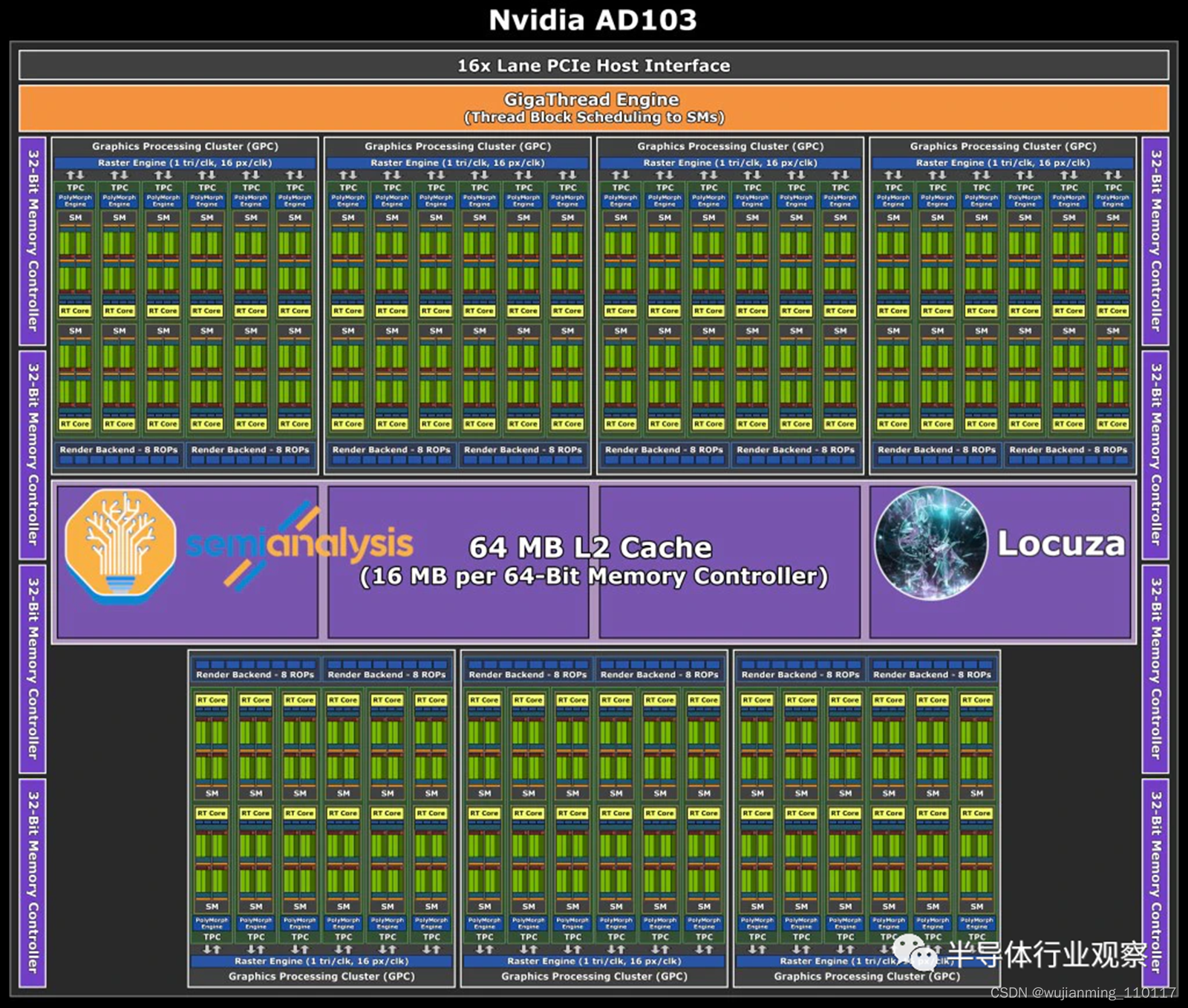
AD103 的配置非常有趣,估计约为379.69mm²。与 AD102 相比,这是一个巨大的降级。这可能是 GPU 一代中顶级芯片和第二个芯片之间近期内存中最大的差距,其中 AD102 的 CUDA 内核比 AD103 多70% 以上。
另一个有趣的事情是 CUDA 核心数量与当前一代高端 GA102 完全相同。内存总线采用 256 位总线,远小于 AD102 的 384 位总线。因此,基于 AD103 的游戏 GPU 最大容量为16GB,但可能会存在缩减版本。尽管内存带宽远低于 GA102,但包含 64MB L2 缓存仍将允许该 GPU 被馈送。
鉴于英伟达将使用定制的台积电“4N”节点,预计时钟频率将高于 GA102。时钟增加加上架构改进将使 AD103 的性能优于当前一代旗舰产品 RTX 3090 Ti;如果带到高功耗的桌面上。需要注意的是,GA103 从未出现在台式机上,仅在笔记本 GPU 的高端上可用,因此 Ada 一代可能会再次出现这种情况。
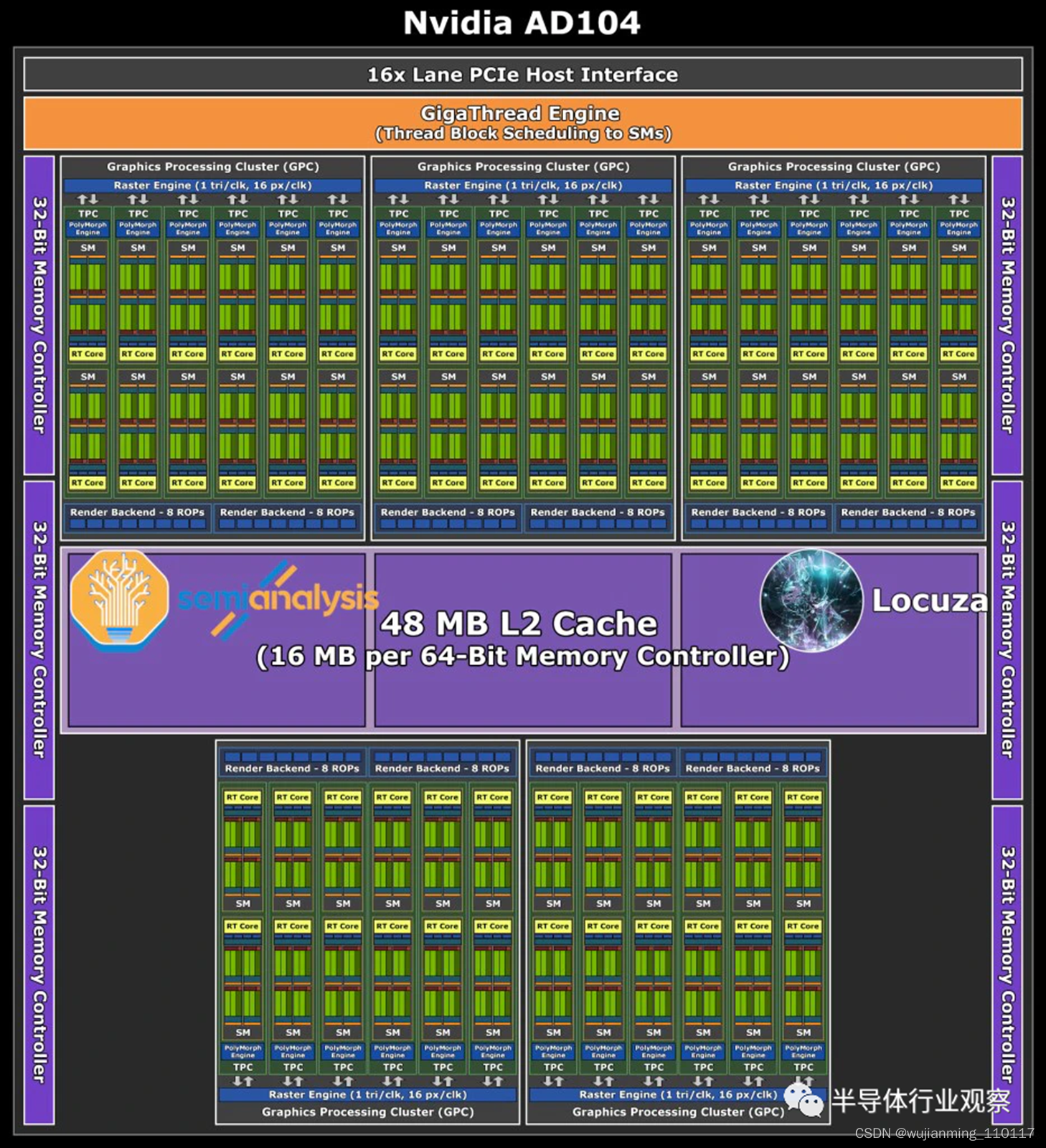
AD104 估计约为 300.45mm²,由于其性能和成本效益,Ada 系列中的最佳选择。192 位总线为游戏 GPU 带来了 12GB 内存,具有足够高的容量,同时将材料清单 (BOM) 保持在合理水平。
同时,Nvidia GPU 的 104 设计往往具有与上一代 102 相似的性能。如果这种趋势持续下去,成本/性能应该会非常出色。事实上,甚至可能有更多,因为 Nvidia 可能会增加相当多的时钟以达到 3090 以上的性能水平。
预计 Nvidia 的顶级 AD104 桌面 GPU 与GDDR6X 的功率将高达 350W 甚至 400W。因此,预计这将是大多数发烧友最终购买的 GPU。GPU 也可以是高效的,期望在没有 G6X 内存和时钟回退一点的情况下实现这一点。

AD106 是真正的大众市场 GPU,估计约为 203.21mm²。可能是该系列中容量最大的 GPU,因为 106 个 GPU 是 Pascal、Turing 和 Ampere 世代的最大容量。由于是 128 位总线,主要配备 8GB 内存。
在高端配置中,预计性能与GA104 相
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2365
2365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









