







CUDA架构与应用杂谈
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。
目前为止基于 CUDA 的 GPU 销量已达数以百万计,软件开发商、科学家以及研究人员正在各个领域中运用 CUDA,其中包括图像与视频处理、计算生物学和化学、流体力学模拟、CT 图像再现、地震分析以及光线追踪等等。
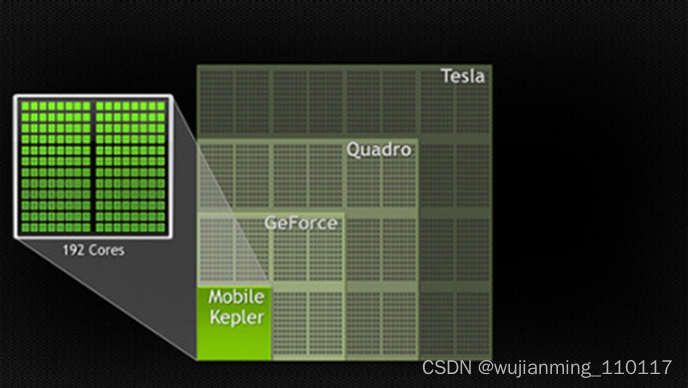
计算行业正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。为打造这一全新的计算典范,NVIDIA™(英伟达™)发明了CUDA(Compute Unified Device Architecture,统一计算设备架构)这一编程模型,是想在应用程序中充分利用CPU和GPU各自的优点。该架构已应用于GeForce™(精视™)、ION™(翼扬™)、Quadro以及Tesla GPU(图形处理器)上,对应用程序开发人员来说,这是一个巨大的市场。
参考文献链接
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
https://mp.weixin.qq.com/s/kxYSw_fR4QMZ2-O5fvOR8g
https://www.zhihu.com/question/461354739/answer/1964488472
https://blog.csdn.net/liusaoyue/article/details/5100656
1.深蓝学院课程讲解:https://www.shenlanxueyuan.com/course/410
2. D. Kirk and W. Hwu, “Programming Massively Parallel Processors –A Hands-on Approach, Second Edition”
3. CUDA by example, Sanders and Kandrot
4. Nvidia CUDA C Programming Guide:https://docs.nvidia.com/cuda/cuda-c-programming-guide/
5. CS/EE217 GPU Architecture andProgramming
GPU架构
在消费级市场上,几乎每一款重要的消费级视频应用程序都已经使用CUDA加速或很快将会利用CUDA来加速,其中不乏Elemental Technologies公司、MotionDSP公司以及LoiLo公司的产品。
在科研界,CUDA一直受到热捧。例如,CUDA现已能够对AMBER进行加速。AMBER是一款分子动力学模拟程序,全世界在学术界与制药企业中有超过60,000名研究人员使用该程序来加速新药的探索工作。
在金融市场,Numerix以及CompatibL针对一款全新的对手风险应用程序发布了CUDA支持并取得了18倍速度提升。Numerix为近400家金融机构所广泛使用。
CUDA的广泛应用造就了GPU计算专用Tesla GPU的崛起。全球财富五百强企业已经安装了700多个GPU集群,这些企业涉及各个领域,例如能源领域的斯伦贝谢与雪佛龙以及银行业的法国巴黎银行。
随着微软Windows 7与苹果Snow Leopard操作系统的问世,GPU计算必将成为主流。在这些全新的操作系统中,GPU将不仅仅是图形处理器,它还将成为所有应用程序均可使用的通用并行处理器。
CUDA C 编程及 GPU 基本知识
1 CPU 和 GPU 的基础知识
提到处理器结构,有2个指标是经常要考虑的:延迟和吞吐量。所谓延迟,是指从发出指令到最终返回结果中间经历的时间间隔。而所谓吞吐量,就是单位之间内处理的指令的条数。
下图1是 CPU 的示意图。从图中可以看出 CPU 的几个特点:
- CPU 中包含了多级高速的缓存结构。 因为我们知道处理运算的速度远高于访问存储的速度,那么奔着空间换时间的思想,设计了多级高速的缓存结构,将经常访问的内容放到低级缓存中,将不经常访问的内容放到高级缓存中,从而提升了指令访问存储的速度。
- CPU 中包含了很多控制单元。 具体有2种,一个是分支预测机制,另一个是流水线前传机制。
- CPU 的运算单元 (Core) 强大,整型浮点型复杂运算速度快。
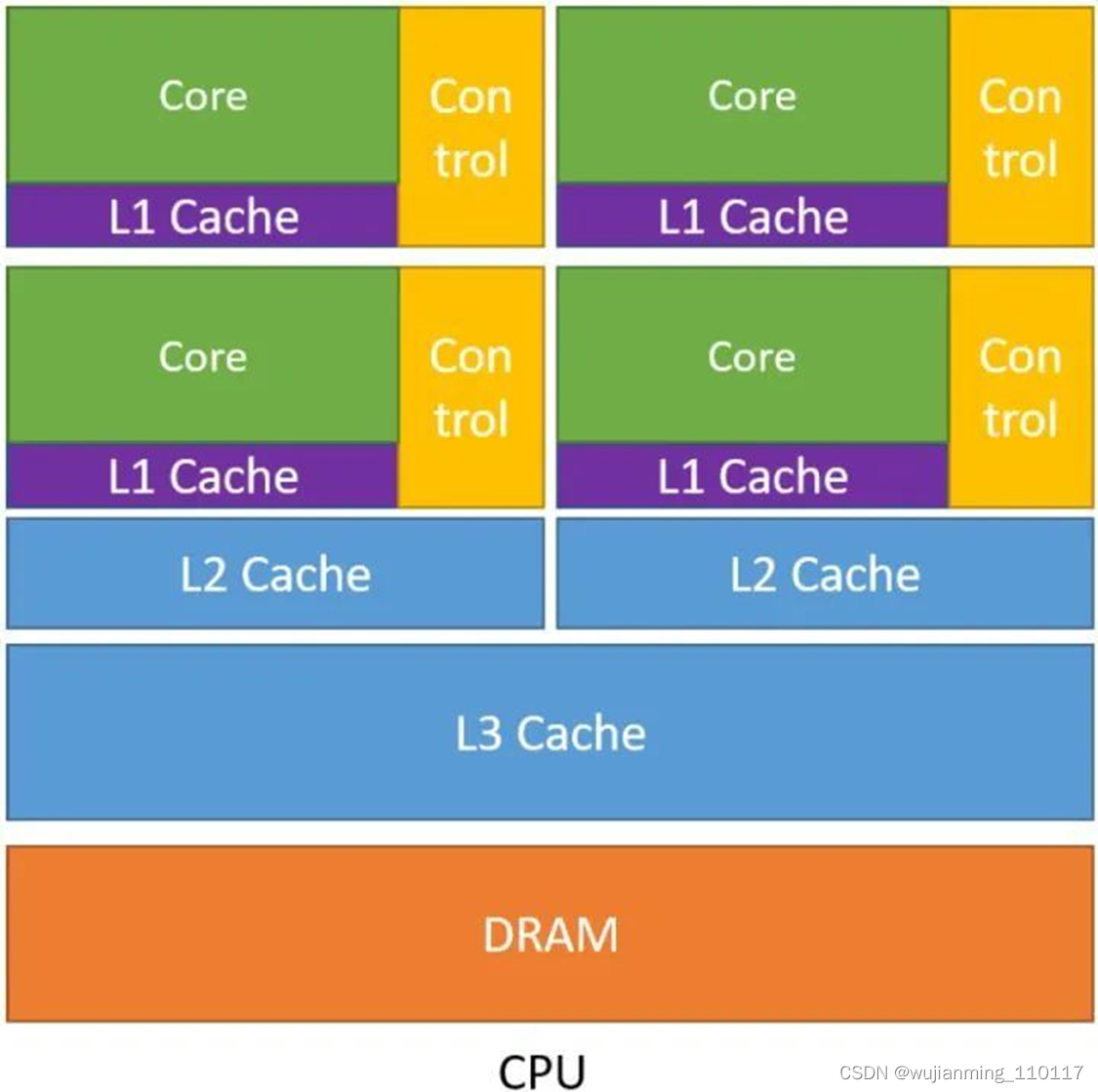
图1:CPU 的示意图
所以综合以上三点,CPU 在设计时的导向就是减少指令的时延,我们称之为延迟导向设计,如下图3所示。
下图2是 GPU 的示意图,它与之前 CPU 的示意图相比有着非常大的不同。从图中可以看出 GPU 的几个特点 (注意紫色和黄色的区域分别是缓存单元和控制单元): - GPU 中虽有缓存结构但是数量少。 因为要减少指令访问缓存的次数。
- GPU 中控制单元非常简单。 控制单元中也没有分支预测机制和数据转发机制。对于复杂的指令运算就会比较慢。
- GPU 的运算单元 (Core) 非常多,采用长延时流水线以实现高吞吐量。 每一行的运算单元的控制器只有一个,意味着每一行的运算单元使用的指令是相同的,不同的是它们的数据内容。那么这种整齐划一的运算方式使得 GPU 对于那些控制简单但运算高效的指令的效率显著增加。
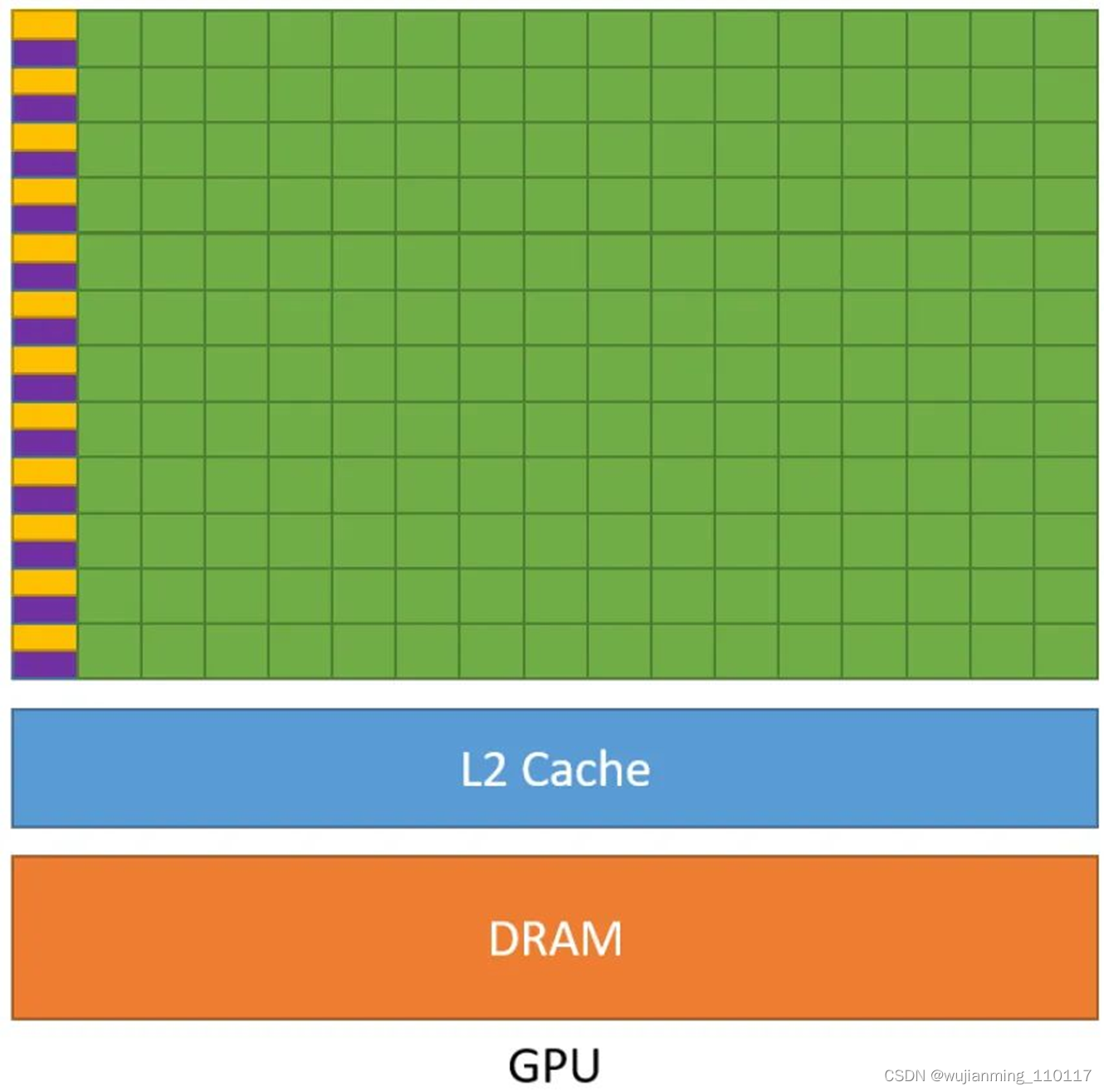
图2:GPU 的示意图
所以,GPU 在设计过程中以一个原则为核心:增加简单指令的吞吐。因此,我们称 GPU 为吞吐导向设计,,如下图3所示。
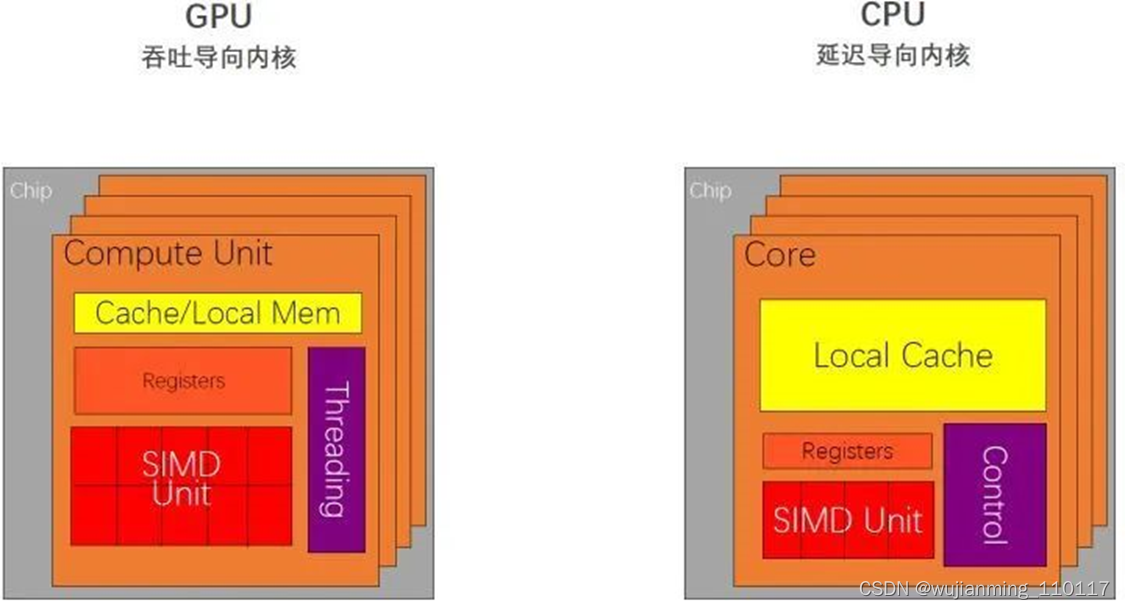
图3:CPU 是延迟导向设计,GPU 是吞吐导向设计
那么究竟在什么情况下使用 CPU,什么情况下使用 GPU 呢?
CPU 在连续计算部分,延迟优先,CPU 比 GPU ,单条复杂指令延迟快10倍以上。
GPU 在并行计算部分,吞吐优先,GPU 比 CPU ,单位时间内执行指令数量10倍以上。
适合 GPU 的问题: - 计算密集:数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖。
- 数据并行:大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
2 CUDA 编程的重要概念
CUDA (Compute Unified Device Architecture),由英伟达公司2007年开始推出,初衷是为 GPU 增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。
OpenCL (Open Computing Languge) 是2008年发布的异构平台并行编程的开放标准,也是一个编程框架。OpenCL 相比 CUDA,支持的平台更多,除了 GPU 还支持 CPU、DSP、FPGA 等设备。
下面我们将以 CUDA 为例,介绍 GPU 编程的基本思想和基本操作。
首先主机端 (host) 和设备端 (device),主机端一般指我们的 CPU,设备端一般指我们的 GPU。
一个 CUDA 程序,我们可以把它分成3个部分:
第1部分是: 从主机 (host) 端申请 device memory,把要拷贝的内容从 host memory 拷贝到申请的 device memory 里面。
第2部分是: 设备端的核函数对拷贝进来的东西进行计算,来得到和实现运算的结果,图4中的 Kernel 就是指在 GPU 上运行的函数。
第3部分是: 把结果从 device memory 拷贝到申请的 host memory 里面,并且释放设备端的显存和内存。
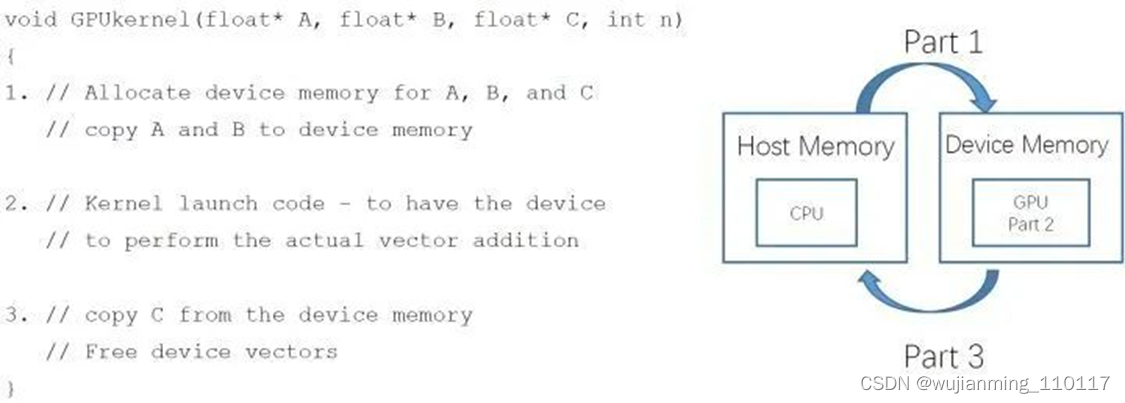
图4:一个 CUDA 程序可以分成3个部分
CUDA 编程中的内存模型
这里就引出了一个非常重要的概念就是 CUDA 编程中的内存模型。
从硬件的角度来讲:
CUDA 内存模型的最基本的单位就是 SP (线程处理器)。每个线程处理器 (SP) 都用自己的 registers (寄存器) 和 local memory (局部内存)。寄存器和局部内存只能被自己访问,不同的线程处理器之间呢是彼此独立的。
由多个线程处理器 (SP) 和一块共享内存所构成的就是 SM (多核处理器) (灰色部分)。多核处理器里边的多个线程处理器是互相并行的,是不互相影响的。每个多核处理器 (SM) 内都有自己的 shared memory (共享内存),shared memory 可以被线程块内所有线程访问。
再往上,由这个 SM (多核处理器) 和一块全局内存,就构成了 GPU。一个 GPU 的所有 SM 共有一块 global memory (全局内存),不同线程块的线程都可使用。
上面这段话可以表述为:每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread (包括不同 block 的 thread) 都共享一份 global memory。不同的 grid 则有各自的 global memory。
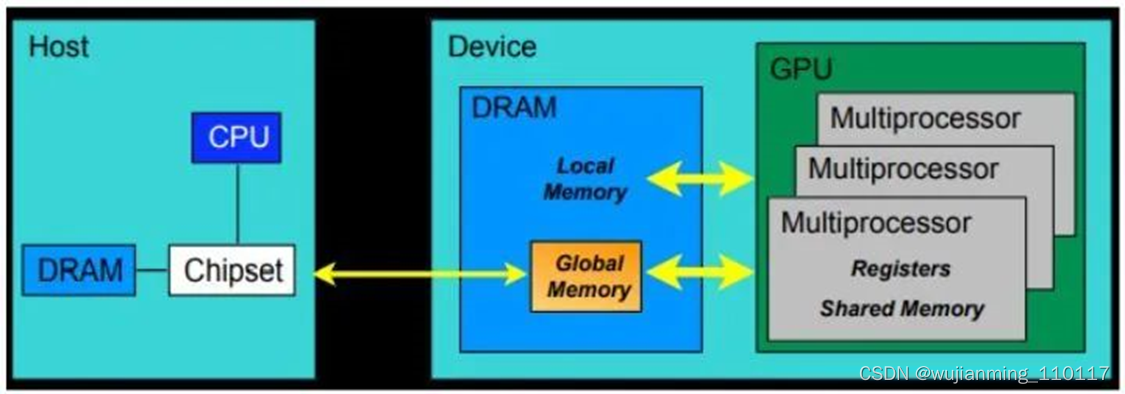
图5:CUDA 内存模型,硬件角度
从软件的角度来讲: - 线程处理器 (SP) 对应线程 (thread)。
- 多核处理器 (SM) 对应线程块 (thread block)。
- 设备端 (device) 对应线程块组合体 (grid)。

图6:CUDA 内存模型,软件角度
如下图6所示,所谓线程块内存模型在软件侧的一个最基本的执行单位,所以我们从这里开始梳理。线程块就是线程的组合体,它具有如下这些特点: - 块内的线程通过共享内存、原子操作和屏障同步进行协作 (shared memory, atomic operations and barrier synchronization)
- 不同块中的线程不能协
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









