







TPU原理技术与xPU
CPU、GPU、DPU、TPU、NPU……
人工智能的发展离不开算力的支持,算力又是依附于各种硬件设备的,没有了算力设备的加持,就好比炼丹少了丹炉一样,可想而知,人工智能智能也就无用武之地了。以深度学习为主的人工智能方向的发展更是离不开强大的算力支持。随着深度学习的不断发展,各种各样的芯片也逐渐抛头露面,见过的,没见过的,听过的没有听过的都出现在眼前,一下有些眼花缭乱,一时竟不知选择哪个?当然前提是不差钱。
本学徒在打杂的时候就发现了众多的XPU,例如GPU, TPU, DPU, NPU, BPU……,各种不同的XPU还分不同等级的系列,价格也大不相同,要起钱来一个比一个凶猛。突然觉得这玩意根本就不是这些穷人玩的,虽然当时看的头晕目眩,内心波涛汹涌,但是仍然还要表现的波澜不惊才行,毕竟做为一名资深的炼丹学徒,还是要有最基本的心里素质的。
参考文献链接
https://baijiahao.baidu.com/s?id=1706639922409916892&wfr=spider&for=pc
https://www.nextplatform.com/2022/05/11/google-stands-up-exascale-tpuv4-pods-on-the-cloud/
https://mp.weixin.qq.com/s/sOPhPJhhniMTIlZX3HaSUA
https://mp.weixin.qq.com/s/e8zOrmiIidy8IoV1yMfdKg
https://mp.weixin.qq.com/s/VEDxfx3il-d_zMPCSntsVg
https://mp.weixin.qq.com/s/305V7bDTJb8jOInz9l_xTA
首先介绍一下这些常见的XPU的英文全称:
CPU全称:Central Processing Unit, 中央处理器;
GPU全称:Graphics Processing Unit, 图像处理器;
TPU全称:Tensor Processing Unit, 张量处理器;
DPU全称:Deep learning Processing Unit, 深度学习处理器;
NPU全称:Neural network Processing Unit, 神经网络处理器;
BPU全称:Brain Processing Unit, 大脑处理器。
下面就来科普一下这些所谓的“XPU”
CPU
CPU( Central Processing Unit, 中央处理器)一般是指的设备的“大脑”,是整体布局、发布执行命令、控制行动的总指挥。
CPU主要包括运算器(ALU, Arithmetic and Logic Unit)和控制单元(CU, Control Unit),除此之外还包括若干寄存器、高速缓存器和之间通讯的数据、控制及状态的总线。CPU遵循的是冯诺依曼架构,即存储程序、顺序执行。一条指令在CPU中执行的过程是:读取到指令后,通过指令总线送到控制器中进行译码,并发出相应的操作控制信号。然后运算器按照操作指令对数据进行计算,并通过数据总线将得到的数据存入数据缓存器。因此,CPU需要大量的空间去放置存储单元和控制逻辑,相比之下计算能力只占据了很小的一部分,在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
简单一点来说CPU主要就是三部分:计算单元、控制单元和存储单元,其架构如下图所示:
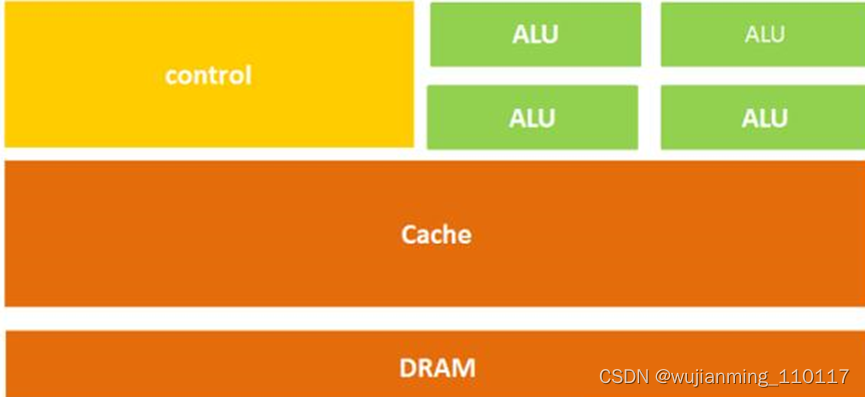
图:CPU微架构示意图
什么?这个架构太复杂,记不住?来,那么换一种表示方法:

:CPU微架构示意图
大概就是这个意思。
从字面上也很容易理解,上面的计算单元主要执行计算机的算术运算、移位等操作以及地址运算和转换;而存储单元主要用于保存计算机在运算中产生的数据以及指令等;控制单元则对计算机发出的指令进行译码,并且还要发出为完成每条指令所要执行的各个操作的控制信号。
所以在CPU中执行一条指令的过程基本是这样的:指令被读取到后,通过控制器(黄色区域)进行译码被送到总线的指令,并会发出相应的操作控制信号;然后通过运算器(绿色区域)按照操作指令对输入的数据进行计算,并通过数据总线将得到的数据存入数据缓存器(大块橙色区域)。过程如下图所示:
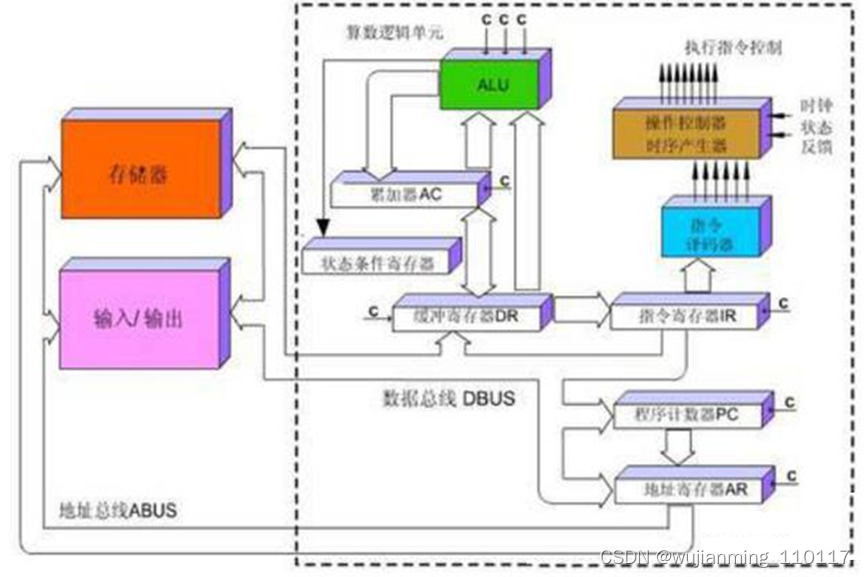
图:CPU执行指令图
这个过程看起来是不是有点儿复杂?没关系,这张图可以不用记住,只需要知道,CPU遵循的是冯诺依曼架构,其核心就是:存储计算程序,按照顺序执行。
讲到这里,有没有看出问题,没错——在上面的这个结构图中,负责计算的绿色区域占的面积似乎太小了,而橙色区域的缓存Cache和黄色区域的控制单元占据了大量空间。
高中化学有句老生常谈的话叫:结构决定性质,放在这里也非常适用。
因为CPU的架构中需要大量的空间去放置存储单元(橙色部分)和控制单元(黄色部分),相比之下计算单元(绿色部分)只占据了很小的一部分,所以在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
另外,因为遵循冯诺依曼架构(存储程序,顺序执行),CPU就像是个一板一眼的管家,人们吩咐事情总是一步一步来做,当做完一件事情才会去做另一件事情,从不会同时做几件事情。但是随着社会的发展,大数据和人工智能时代的来临,人们对更大规模与更快处理速度的需求急速增加,这位管家渐渐变得有些力不从心。
于是,大家就想,能不能把多个处理器都放在同一块芯片上,让一起来做事,相当于有了多位管家,这样效率不就提高了吗?
没错,就是这样的,使用的GPU便由此而诞生了。
GPU
在正式了解GPU之前,还是先来了解一下上文中提到的一个概念——并行计算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和数据处理能力的一种有效手段。基本思想是用多个处理器来共同求解同一个问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算完成。
并行计算可分为时间上的并行和空间上的并行。
时间上的并行是指流水线技术,比如说工厂生产食品的时候分为四步:清洗-消毒-切割-包装。
如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个或两个以上的操作,大大提高计算性能。

图:流水线示意图
空间上的并行是指多个处理机并发的执行计算,即通过网络将两个以上的处理机连接起来,达到同时计算同一个任务的不同部分,或者单个处理机无法解决的大型问题。
比如小李准备在植树节种三棵树,如果小李1个人需要6个小时才能完成任务,植树节当天他叫来了好朋友小红、小王,三个人同时开始挖坑植树,2个小时后每个人都完成了一颗植树任务,这就是并行算法中的空间并行,将一个大任务分割成多个相同的子任务,来加快问题解决速度。
所以说,如果让CPU来执行这个种树任务的话,就会一棵一棵的种,花上6个小时的时间,但是让GPU来种树,就相当于好几个人同时在种。
为了解决CPU在大规模并行运算中遇到的困难, GPU应运而生,GPU全称为Graphics Processing Unit,中文为图形处理器,就如名字一样,图形处理器,GPU最初是用在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
GPU采用数量众多的计算单元和超长的流水线,善于处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。近年来,人工智能的兴起主要依赖于大数据的发展、算法模型的完善和硬件计算能力的提升。其中硬件的发展则归功于GPU的出现。
为什么GPU特别擅长处理图像数据呢?这是因为图像上的每一个像素点都有被处理的需要,而且每个像素点处理的过程和方式都十分相似,也就成了GPU的天然温床。
GPU简单架构如下图所示:
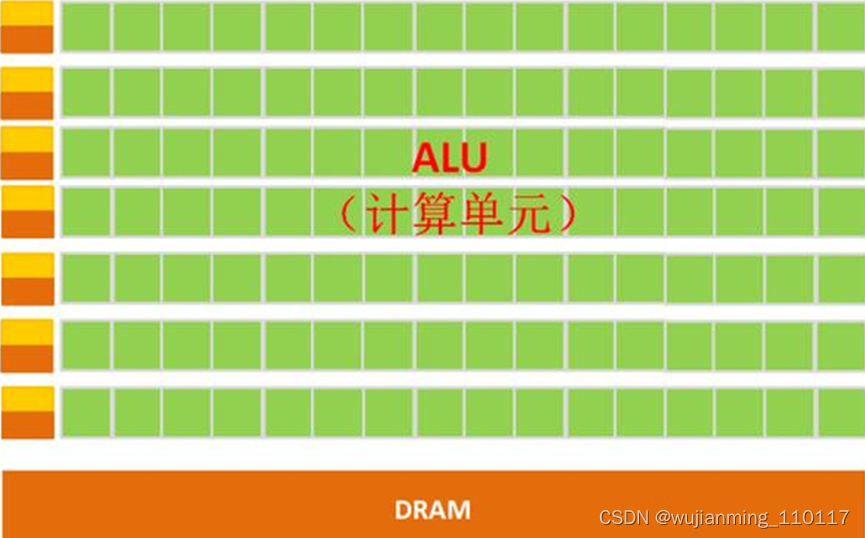
图:GPU微架构示意图
从架构图就能很明显的看出,GPU的构成相对简单,有数量众多的计算单元和超长的流水线,特别适合处理大量的类型统一的数据。
但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
注:GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram。
再把CPU和GPU两者放在一张图上看下对比,就非常一目了然了。
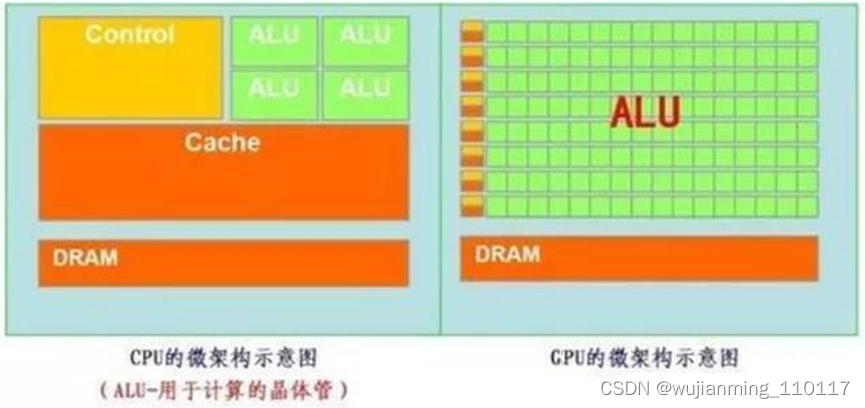
GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。
借用知乎上某大神的说法,就像有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已;而CPU就像老教授,积分微分都会算,就是工资高,一个老教授能顶二十个小学生,要是富士康雇哪个?
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是通过前面的介绍可以发现,在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
所以GPU也可以认为是一种较通用的芯片。
TPU
按照上文所述,CPU和GPU都是较为通用的芯片,但是有句老话说得好:万能工具的效率永远比不上专用工具。
随着人们的计算需求越来越专业化,人们希望有芯片可以更加符合自己的专业需求,这时,便产生了ASIC(专用集成电路)的概念。
ASIC是指依产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。当然这概念不用记,简单来说就是定制化芯片。
因为ASIC很“专一”,只做一件事,所以就会比CPU、GPU等能做很多件事的芯片在某件事上做的更好,实现更高的处理速度和更低的能耗。但相应的,ASIC的生产成本也非常高。
而TPU(Tensor Processing Unit, 张量处理器)就是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款ASIC。
人工智能旨在为机器赋予人的智能,机器学习是实现人工智能的强有力方法。所谓机器学习,即研究如何让计算机自动学习的学科。TPU就是这样一款专用于机器学习的芯片,是Google于2016年5月提出的一个针对Tensorflow平台的可编程AI加速器,其内部的指令集在Tensorflow程序变化或者更新算法时也可以运行。TPU可以提供高吞吐量的低精度计算,用于模型的前向运算而不是模型训练,且能效(TOPS/w)更高。在Google内部,CPU,GPU,TPU均获得了一定的应用,相比GPU,TPU更加类似于DSP,尽管计算能力略有逊色,但是其功耗大大降低,而且计算速度非常的快。然而,TPU,GPU的应用都要受到CPU的控制。

图:谷歌第二代TPU
一般公司是很难承担为深度学习开发专门ASIC芯片的成本和风险的,但谷歌是谁,人家会差钱吗?
开个玩笑。更重要的原因是谷歌提供的很多服务,包括谷歌图像搜索、谷歌照片、谷歌云视觉API、谷歌翻译等产品和服务都需要用到深度神经网络。基于谷歌自身庞大的体量,开发一种专门的芯片开始具备规模化应用(大量分摊研发成本)的可能。
如此看来,TPU登上历史舞台也顺理成章了。
原来很多的机器学习以及图像处理算法大部分都跑在GPU与FPGA(半定制化芯片)上面,但这两种芯片都还是一种通用性芯片,所以在效能与功耗上还是不能更紧密的适配机器学习算法,而且Google一直坚信伟大的软件将在伟大的硬件的帮助下更加大放异彩,所以Google便想,可不可以做出一款专用机机器学习算法的专用芯片,TPU便诞生了。
据称,TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云来实时收集数据并产生结果,而训练过程还需要额外的资源;而第二代TPU既可以用于训练神经网络,又可以用于推理。
看到这里可能会问了,为什么TPU会在性能上这么牛逼呢?TPU是怎么做到如此之快呢?
(1)深度学习的定制化研发:TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款 ASIC(专用集成电路)。
(2)大规模片上内存:TPU 在芯片上使用了高达 24MB 的局部内存,6MB 的累加器内存以及用于与主控处理器进行对接的内存。
(3)低精度 (8-bit) 计算:TPU 的高性能还来源于对于低运算精度的容忍,TPU 采用了 8-bit 的低精度运算,也就是说每一步操作 TPU 将会需要更少的晶体管。
嗯,谷歌写了好几篇论文和博文来说明这一原因,所以仅在这里抛砖引玉一下。
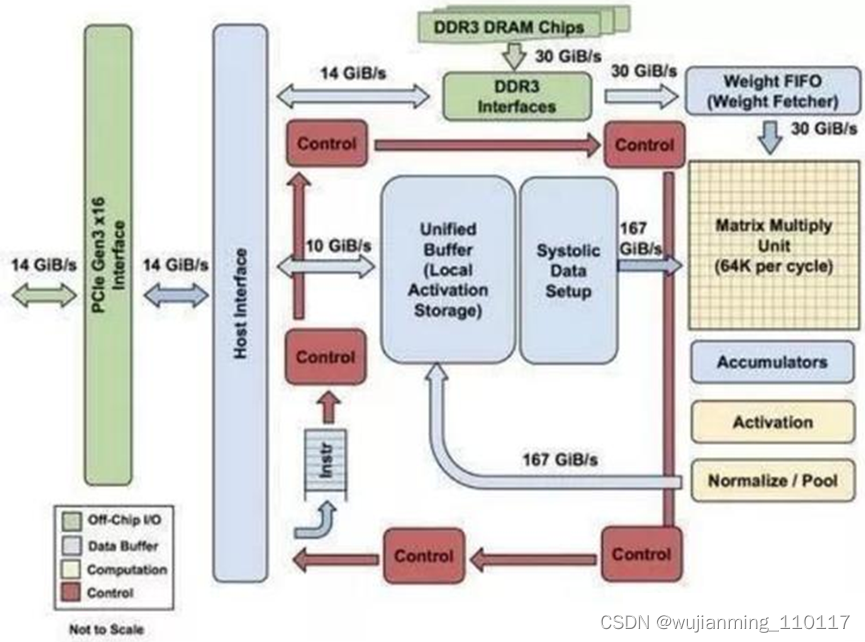
图:TPU 各模块的框图
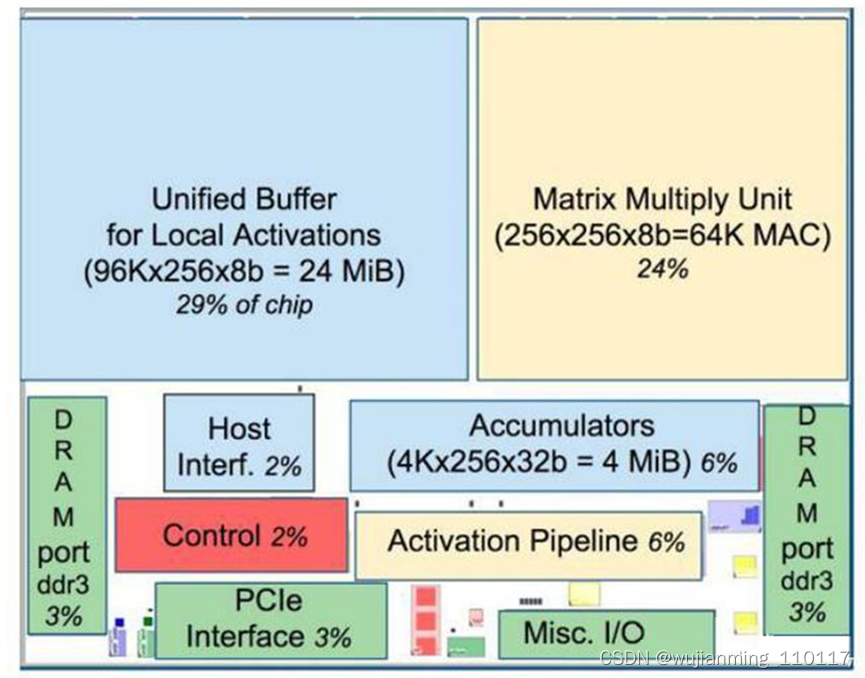
图:TPU芯片布局图
如上图所示,TPU在芯片上使用了高达24MB的局部内存,6MB的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的37%(图中蓝色部分)。
这表示谷歌充分意识到了片外内存访问是GPU能效比低的罪魁祸首,因此不惜成本的在芯片上放了巨大的内存。相比之下,英伟达同时期的K80只有8MB的片上内存,因此需要不断地去访问片外DRAM。
另外,TPU的高性能还来源于对于低运算精度的容忍。研究结果表明,低精度运算带来的算法准确率损失很小,但是在硬件实现上却可以带来巨大的便利,包括功耗更低、速度更快、占芯片面积更小的运算单元、更小的内存带宽需求等…TPU采用了8比特的低精度运算。
其它更多的信息可以去翻翻谷歌的论文。
到目前为止,TPU其实已经干了很多事情了,例如机器学习人工智能系统RankBrain,是用来帮助Google处理搜索结果并为用户提供更加相关搜索结果的;还有街景Street View,用来提高地图与导航的准确性的;当然还有下围棋的计算机程序AlphaGo!
NPU
讲到这里,相信大家对这些所谓的“XPU”的套路已经有了一定了解,接着来。
所谓NPU(Neural network Processing Unit), 即神经网络处理器。神经网络处理器(NPU)采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。
在GX8010中,CPU和MCU各有一个NPU,MCU中的NPU相对较小,习惯上称为SNPU。NPU处理器包括了乘加、激活函数、二维数据运算、解压缩等模块。乘加模块用于计算矩阵乘加、卷积、点乘等功能,NPU内部有64个MAC,SNPU有32个。
激活函数模块采用最高12阶参数拟合的方式实现神经网络中的激活函数,NPU内部有6个MAC,SNPU有3个。二维数据运算模块用于实现对一个平面的运算,如降采样、平面数据拷贝等,NPU内部有1个MAC,SNPU有1个。解压缩模块用于对权重数据的解压。为了解决物联网设备中内存带宽小的特点,在NPU编译器中会对神经网络中的权重进行压缩,在几乎不影响精度的情况下,可以实现6-10倍的压缩效果。
既然叫神经网络处理器,顾名思义,这家伙是想用电路模拟人类的神经元和突触结构啊!
怎么模仿?那就得先来看看人类的神经结构——生物的神经网络由若干人工神经元结点互联而成,神经元之间通过突触两两连接,突触记录了神经元之间的联系。
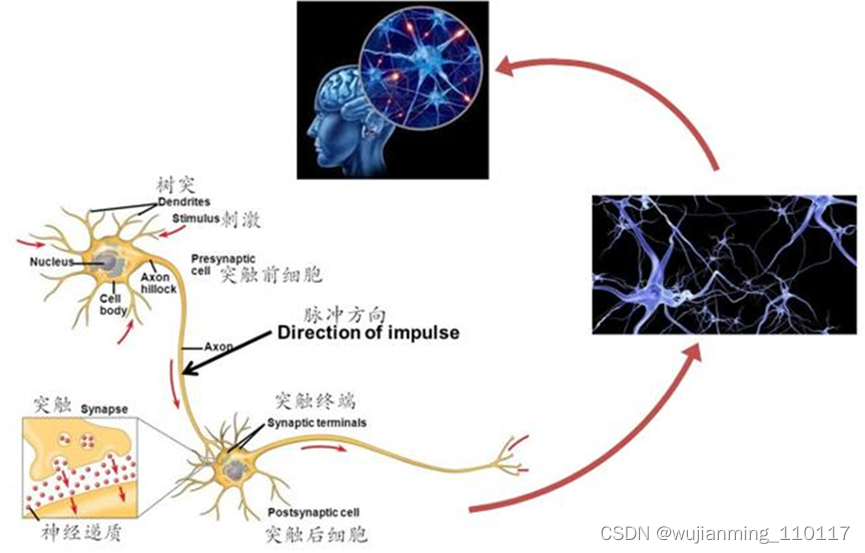
高中生物还记得吗?
如果想用电路模仿人类的神经元,就得把每个神经元抽象为一个激励函数,该函数的输入由与其相连的神经元的输出以及连接神经元的突触共同决定。
为了表达特定的知识,使用者通常需要(通过某些特定的算法)调整人
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 9427
9427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









