










在此前分享《小白如何挑选单细胞标记的marker基因?》中,我们系统梳理了单细胞marker挑选时常用的一系列数据库,想必大家都感受到了这些工具对于科研工作的强大助力。在这众多数据库里,CellMarker 2.0脱颖而出,成为医学方向科研人员使用最为频繁的数据库之一。那它为何能备受青睐?本期为您重点去解密下。
CellMarker1.0是由哈尔滨医科大学李霞教授团队在2018年建设完成。经过该团队的不懈努力, CellMarker 2.0数据库升级版于2022年在Nucleic Acids Research杂志发布,新增一系列单细胞测序数据分析相关的功能。与旧版本相比,CellMarker 2.0的优势在于以下几个方面:
· 数据资源的扩展:CellMarker 2.0增加了36300个组织细胞类型标记条目、474个组织、1901个细胞类型和4566个marker基因。总共提供了83361个组织细胞类型标记条目。
· 技术多样性:新增来自10xChromium、Smart-Seq2、Drop-seq等48种技术来源的标记信息
· 细胞类型和组织的丰富性:新增了29种细胞标记,包括蛋白编码基因、lncRNA和假基因等。
· 数据分析工具的升级:开发了6种灵活的网络工具,包括细胞注释分析、细胞聚类分析、细胞恶性分析、细胞分化分析、细胞特征分析和细胞通讯分析,这些工具可用于单细胞测序数据的分析和可视化。
数据库使用指南
1. 数据库主页介绍
-
网址:http://117.50.127.228/CellMarker/
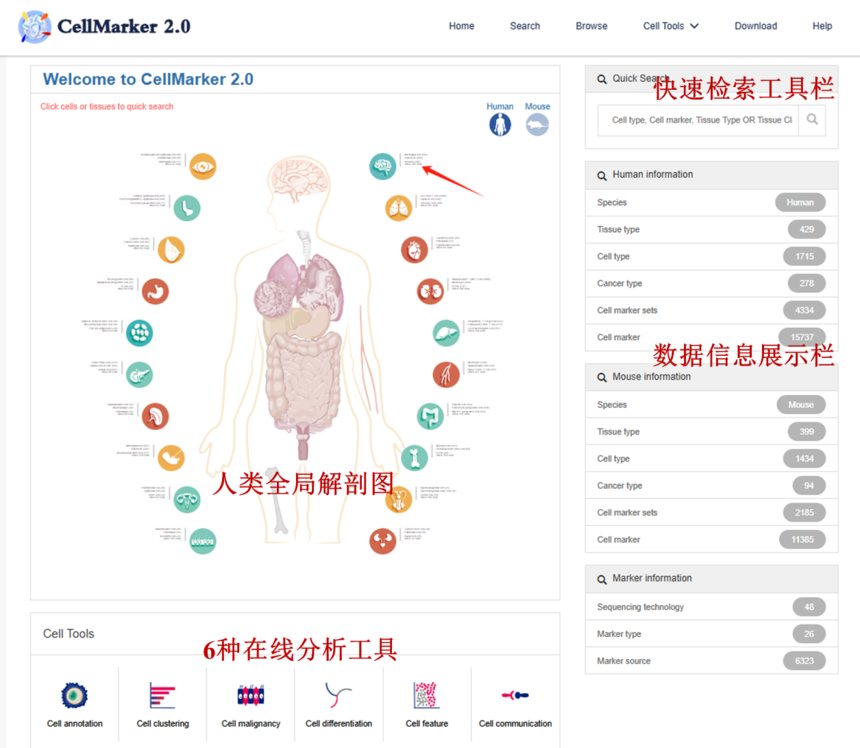
CellMarker 2.0的主页提供了一个人类和小鼠的全局解剖地图,从整体布局上看,它的设计简洁明了,方便用户快速找到所需信息。
主页左上方:在页面的左方中心区域,醒目地展示了一幅涵盖人类与小鼠的全局解剖地图,每一个精细描绘的器官、组织部位,都对应着特定的细胞类型,用户只需轻轻点击感兴趣的图像区域(箭头所指区域),便能一键直达相应的数据模块,快速锁定目标组织、细胞类型所对应的marker基因,极大地节省了数据检索的时间成本。
主页左下方:排列着六种单细胞分析工具的快速通道,无论你是想要进行细胞聚类分析、差异表达基因挖掘,还是轨迹推断等复杂操作,只需点击对应的入口,就能迅速进入专业的分析版块。
主页右方:在主页的右边是一个快速搜索框。用户可以通过输入组织名称、细胞名称、marker基因名称等关键信息,就能迅速获得精准反馈。下方展示的是人类和小鼠在细胞标记等方面的丰富数据比如组织类型、癌症类型、细胞标记集等。
2. 物种/组织/细胞/基因检索

在菜单栏选择进入“Search”页面,数据库提供了三种检索的方式:
①.按照组织类型、细胞类型检索,用户可以直接在页面上选择相应的物种、组织、细胞类型,进而跳转到该细胞类型对应的marker基因页面。
②.按照基因检索,数据库支持三种基因输入形式,Genealias、Genesymbol和GeneEntrezID。
③.快速检索,是一种混合检索模式,既可以检索基因名,也可以检索组织、细胞类型。
我们以查找人类肝脏中的T细胞为例,这里的T细胞对应的marker以CD4为例。
-
2.1 物种组织器官查询Marker
Species:输入human
TissueType:输入liver
CellName:输入T cell
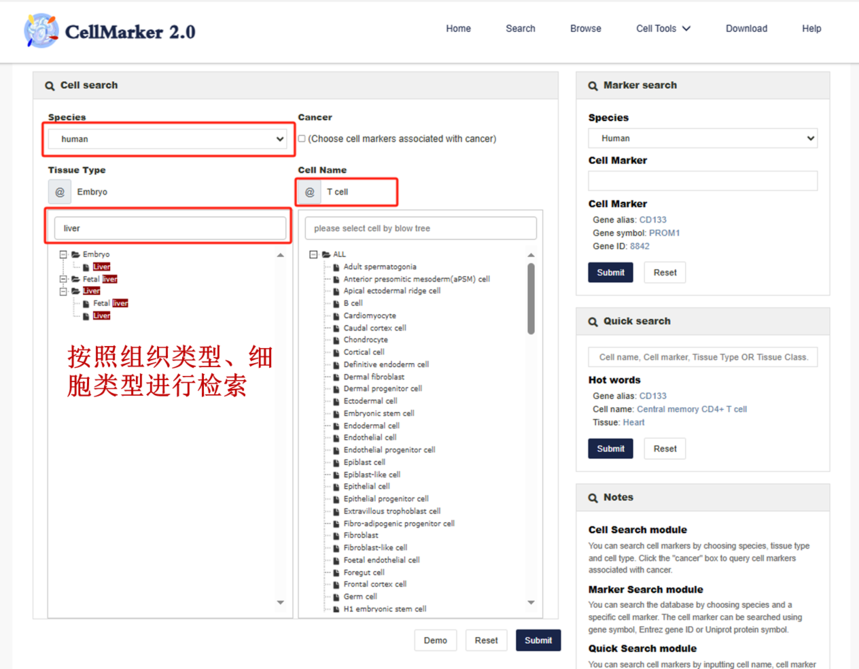
点击Submit,出现如下词云界面,选择CD4。

-
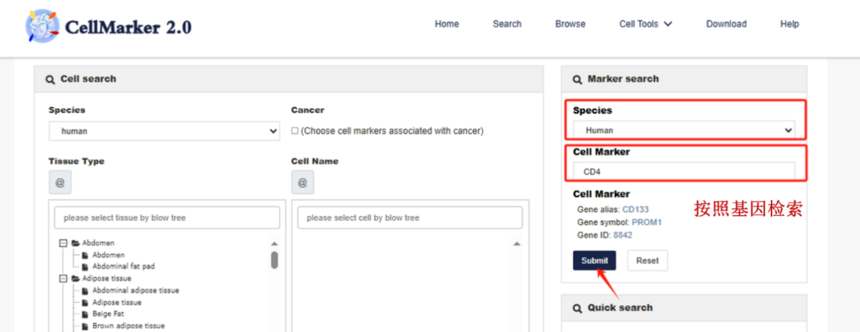
2.2 Markersearch
假设看一下CD4在不同器官组织中的不同细胞的情况,便可以在CellMarker栏输入CD4。
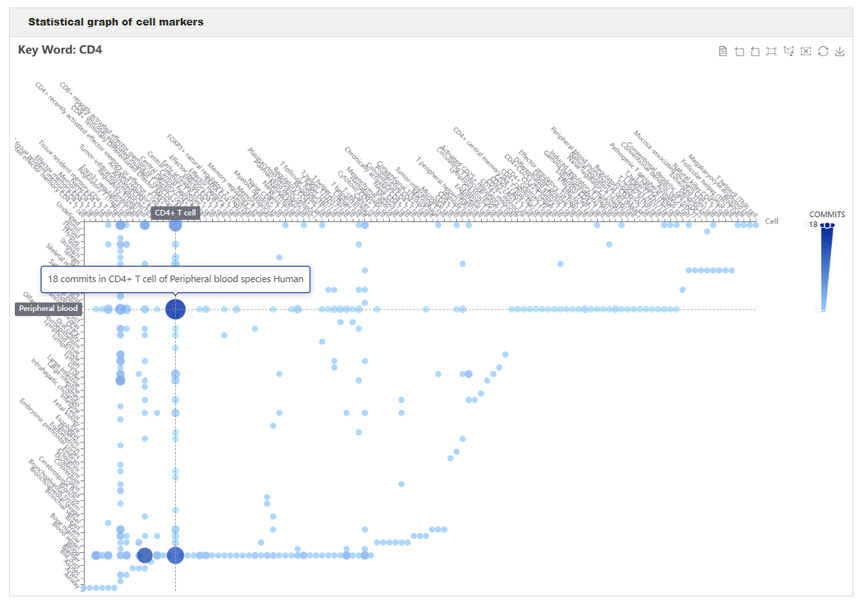
通过输入特定的marker基因名来检索的话,还会有一个特殊的结果呈现形式,结果中会展示组织-细胞类型的dotplot,对于该基因的分布情况非常清晰。
-
2.3 Quicksearch
另外一个查找功能就是Quicksearch了,可以输入Cellname,Cellmarker,Tissuetype或者Tissueclass。

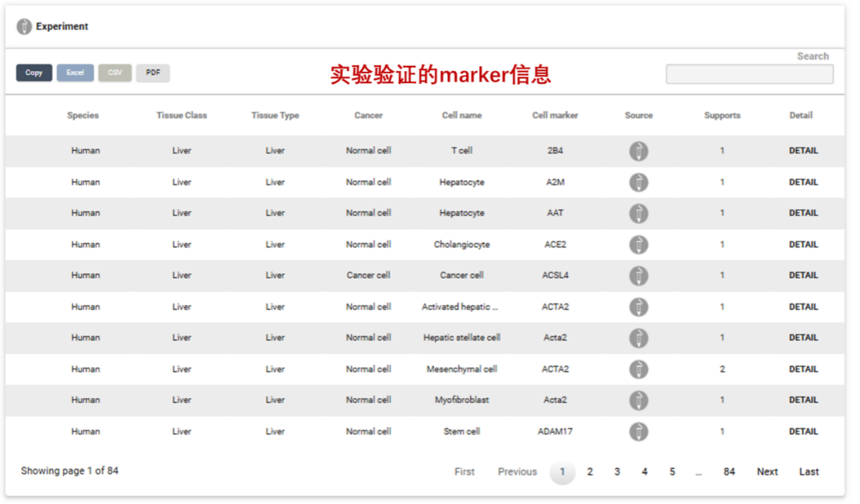
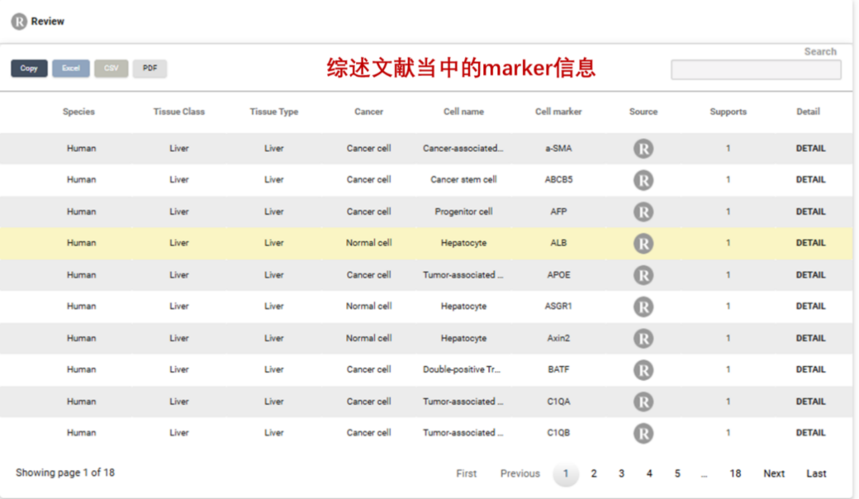
3. Browse内容概述
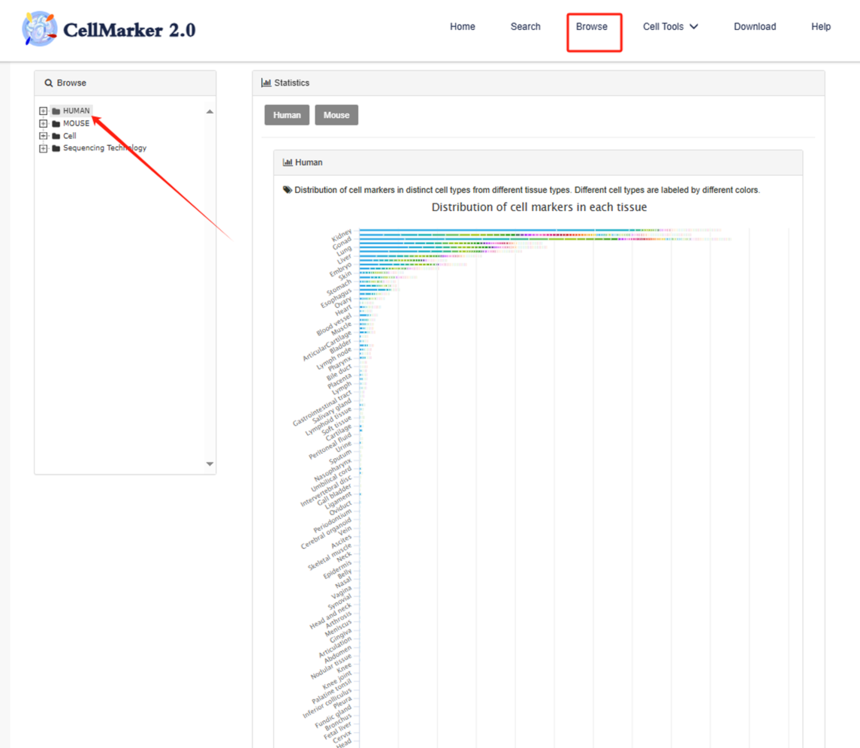
CellMarker 2.0数据库中的“Browse”页面是一个重要的信息浏览和检索板块。如果我们没有感兴趣的细胞类型,点进来只是来看看数据库都存储了哪些数据资源。“Browse”页面展示目的主要是为用户提供一种系统、全面且有条理的方式来浏览数据库中的丰富信息。“Browse”页面更适合用户在对特定研究领域或细胞类型有大致方向但不确定具体关键词时,进行逐步深入的信息探索。它有助于用户发现一些潜在的研究线索,比如在浏览某一组织的多种细胞类型时,可能会注意到一些之前未关注到的细胞特异性marker基因,从而启发新的研究思路。
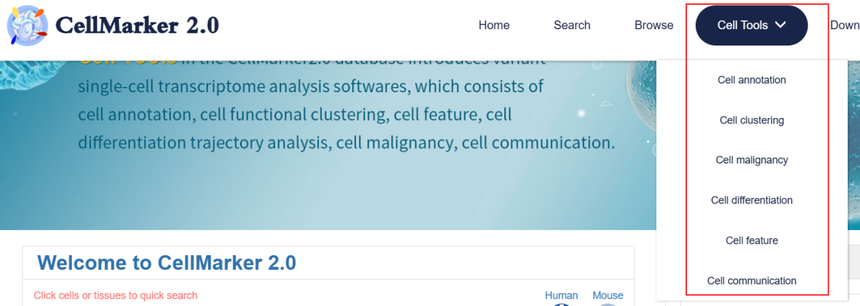
4. 在线分析小工具
与旧版本相比,CellMarker 2.0在数据分析工具上进行了全面升级。CellMarker 1.0可能仅提供了较为基础的查询功能,而新版本开发了6种灵活的网络工具,包括细胞注释、细胞聚类、细胞恶性、细胞分化、细胞特征和细胞通讯等分析。这些工具不仅能够对单细胞测序数据进行高效分析,还能以直观的可视化形式呈现结果,真正实现从数据收集到深度分析的一站式服务。
-
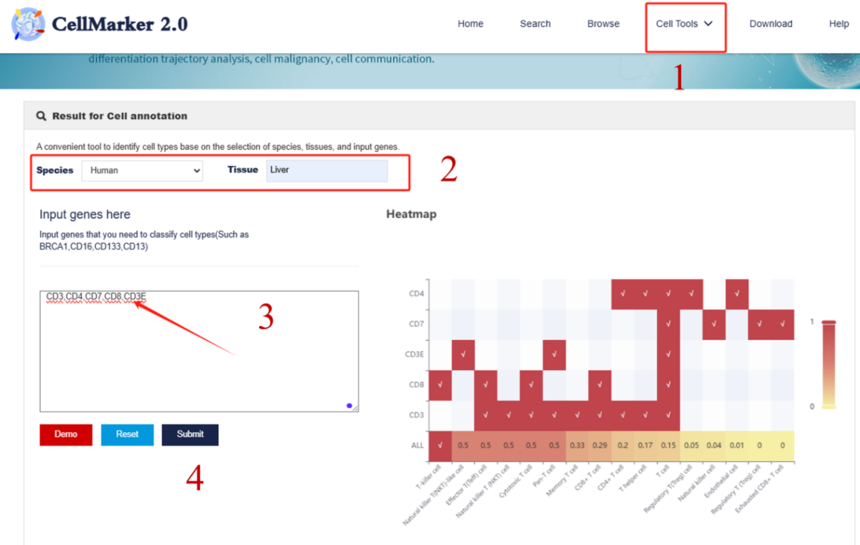
4.1 Cell Annotation
细胞注释分析工具,如同细胞身份的解码器。首先,在Result for Cell annotation下方的Species工具栏中输入human,在Tissue工具栏中输入liver,在Input genes here输入对应的marker基因,图中是以人类肝脏中的T细胞的一些marker基因为例,生成的Heatmapt图,图中ALL这一列展示的是Score值,Score值可以反映输入基因在细胞类型中的比例,数值越高,比例也越高,也就意味着该基因在细胞中表达量也越高。
凭借数据库中丰富且精准的细胞标记信息,快速且准确地判定每个细胞所属的类型。在复杂的组织样本中,如肿瘤组织包含多种细胞成分,该工具可有效区分癌细胞、免疫细胞、基质细胞等不同类型细胞,为后续深入分析细胞功能和相互作用奠定基础,让我们清晰把握细胞组成结构。
-
4.2 Cell Clustering
细胞聚类分析工具宛如细胞关系的梳理大师。用户可依据自身研究需求设定参数,它依据基因表达模式对细胞进行聚类。通过直观的可视化界面,如3D图形展示,清晰呈现细胞群体间基因表达的相似性与差异性。在研究细胞分化进程或寻找新的细胞亚群时,可帮助我们发现潜在的细胞分化分支路径和未被识别的细胞亚群,挖掘细胞异质性背后的规律。
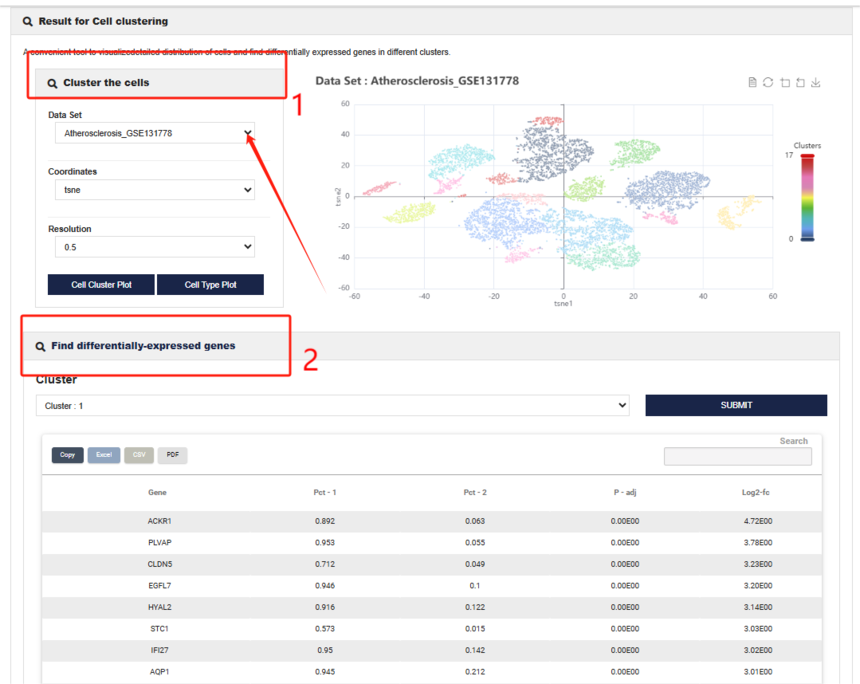
总的来说,该工具的功能是可视化细胞分布并查找不同聚类中的差异表达基因。该工具主要由两大部分组成:
第一个部分是细胞聚类结果(Cluster the cells),DataSet下拉菜单中显示与特定的疾病和基因表达数据相关信息,可以按照自己的需求进行选取,Resolution该参数用于控制聚类的力度,数值越大,聚类的数量可能越多,“Cell Cluster Plot”代表细胞聚类图,“Cell Type Plot”代表细胞类型图。
第二部分是代表差异表达的基因(Find differentially-expressed genes),用于查找不同聚类中的差异表达基因。
-
4.3 Cell Malignancy
细胞恶性分析工具恰似癌细胞的照妖镜。聚焦于癌细胞的特征分析,通过检测癌基因的表达水平、细胞周期调控基因的异常变化等关键指标,对细胞的恶性程度进行量化评估,对细胞的类型进行划分,区分哪些是正常细胞、哪些是肿瘤细胞。基于肿瘤细胞常常会发生大片段的拷贝数扩增或缺失的基因组特征,开发者整合了通过scRNA-seq推测CNV的inferCNV工具,对多个数据集进行处理,用户可以探索特定癌症类型/GEO数据集编号的每种细胞类型所携带的拷贝数特征信息。在癌症研究中,能够为研究者提供重要参考,预测肿瘤的侵袭性、转移风险以及患者的预后情况,辅助制定个性化的治疗方案。
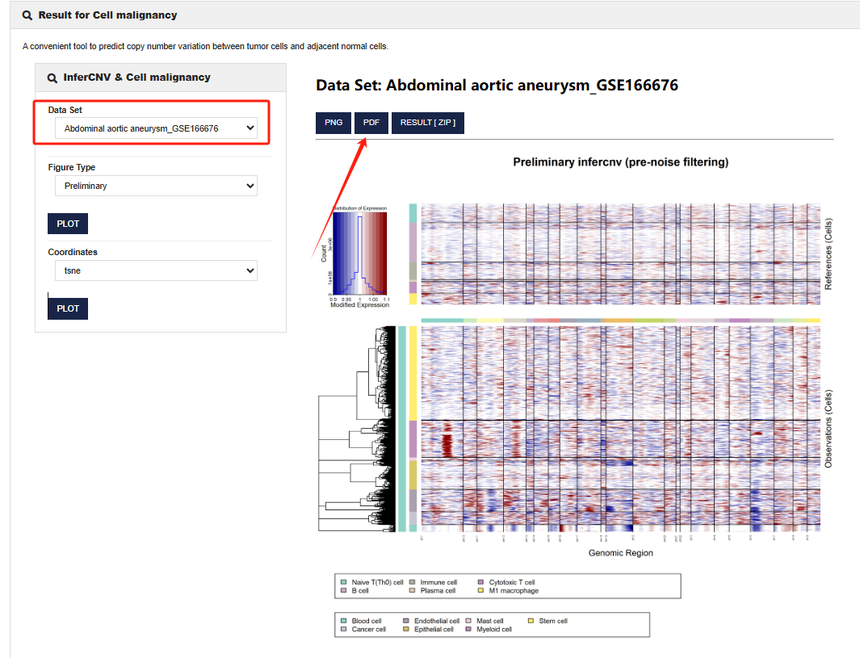
该页面左侧展示的是参数设置区域,Data Set是目前整理出来的基因表达GEO的数据库;
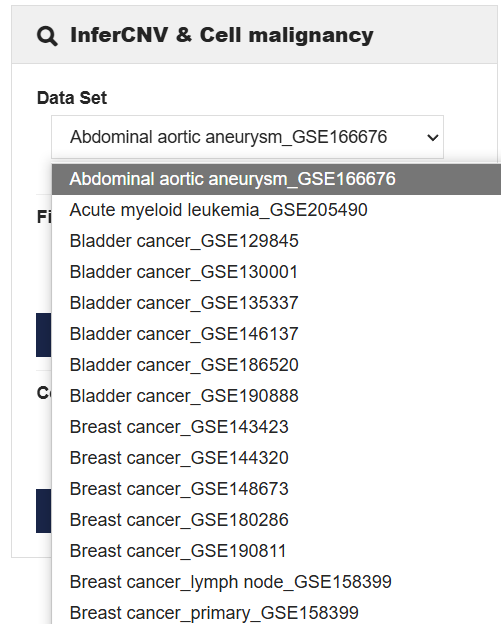
“Figure Type”存在两种选项:Infercnv和Preliminary;Coordinates则是有“tsne”和“umap”两个选项。“tsne”是一种用于降维和可视化高维数据的方法,常用于单细胞数据的展示。分别点击Plot,右侧会呈现不同可视化结果。
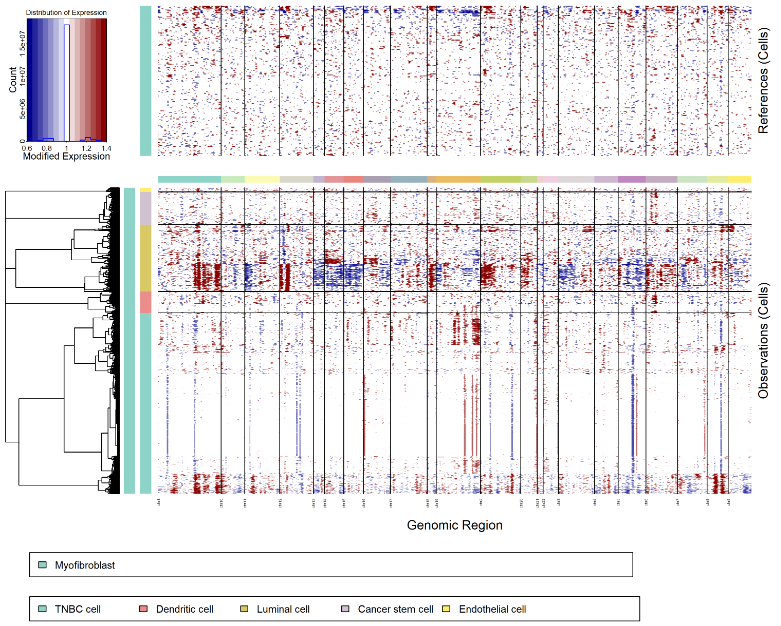
右侧为结果展示区域,上方图中:展示的是Reference Cells的CNV 情况,横轴表示基因组区域(Genomic Region),纵轴表示细胞,从蓝色到红色的渐变表示某种基因表达水平变化。下方图中:展示的是不同细胞(Observation Cells)的 CNV变化情况,同样横轴为基因组区域,纵轴为细胞,这个热图反映了不同细胞在不同基因组区域的拷贝数变异情况。下方左侧树状图:展示的是细胞聚类分析的结果,用于展示不同细胞之间的关系和聚类情况。通过这种方式,可以观察到不同细胞类型在 CNV 模式上的相似性和差异性。
-
4.4 Cell Differentiation
细胞分化分析工具是细胞成长轨迹的追踪者。利用时间序列数据以及关键转录因子在不同时间点的动态变化,绘制出详细的细胞分化路线图。在干细胞研究领域,可清晰展现干细胞向不同功能细胞分化的过程,确定分化过程中的关键节点基因,助力揭示细胞分化的分子机制,为再生医学等研究提供理论支持。
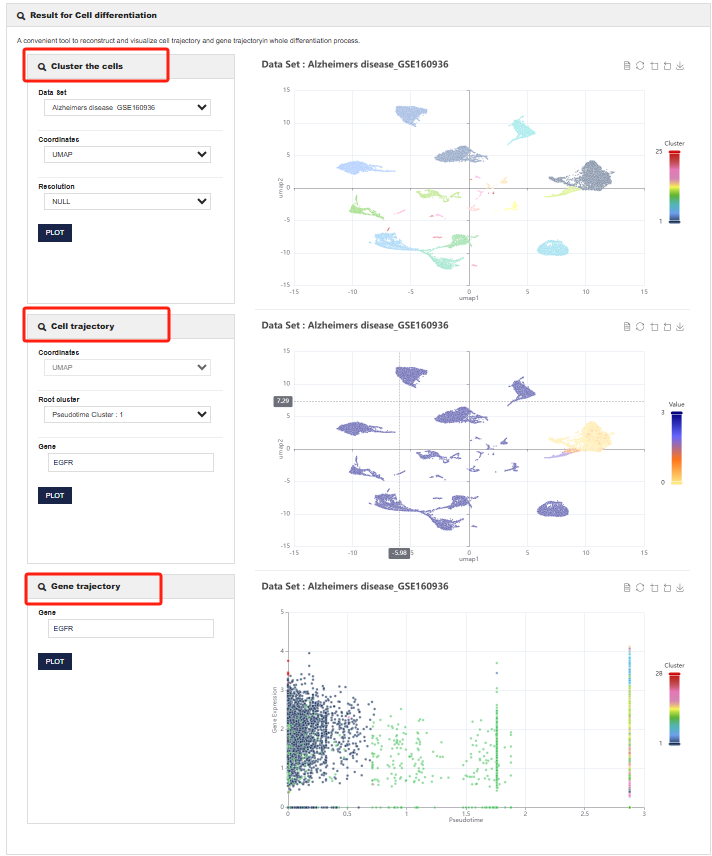
该小工具的开发者整了Monocle3的方法分析多个公开数据集,并将tSNE、UMAP、伪时序分析结果集成到一个页面,方便用户比较分析。Cluster the cells代表细胞聚类的结果,下拉菜单中有已经整理出来的基因表达集,Cell trajectory代表细胞轨迹变化,用于描述细胞分化过程中细胞状态变化,Gene trajectory代表基因轨迹变化,可以根据所选基因生成基因轨迹图。通过该结果可以观察细胞在分化过程中的动态变化轨迹,了解细胞从一个状态到另一个状态的转变过程。
-
4.5 Cell Feature
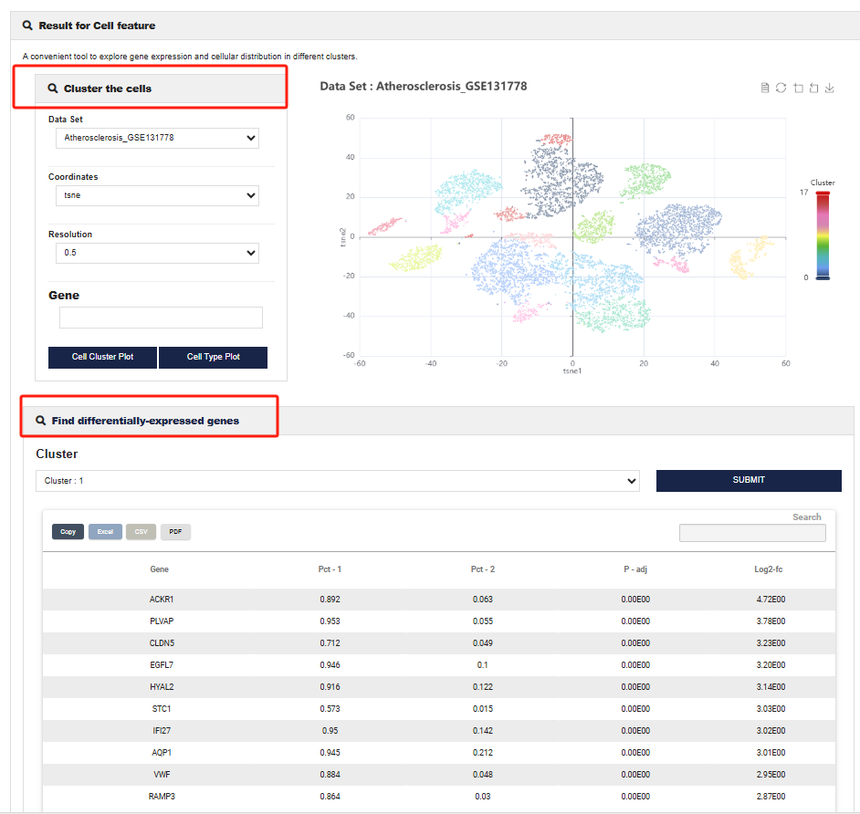
细胞特征分析工具犹如细胞功能的放大镜。从多个维度深入剖析细胞的功能特性,包括细胞的代谢活性、信号通路的激活状态等。无论是正常生理状态下细胞功能的研究,还是疾病发生发展过程中细胞功能异常的探索,都能为研究者提供全面而细致的细胞功能信息,帮助理解细胞在不同环境下的行为表现。用户选择感兴趣的数据集之后,输入相应的基因名称,可以查询该基因在哪个cluster中是处于高表达的状态。
-
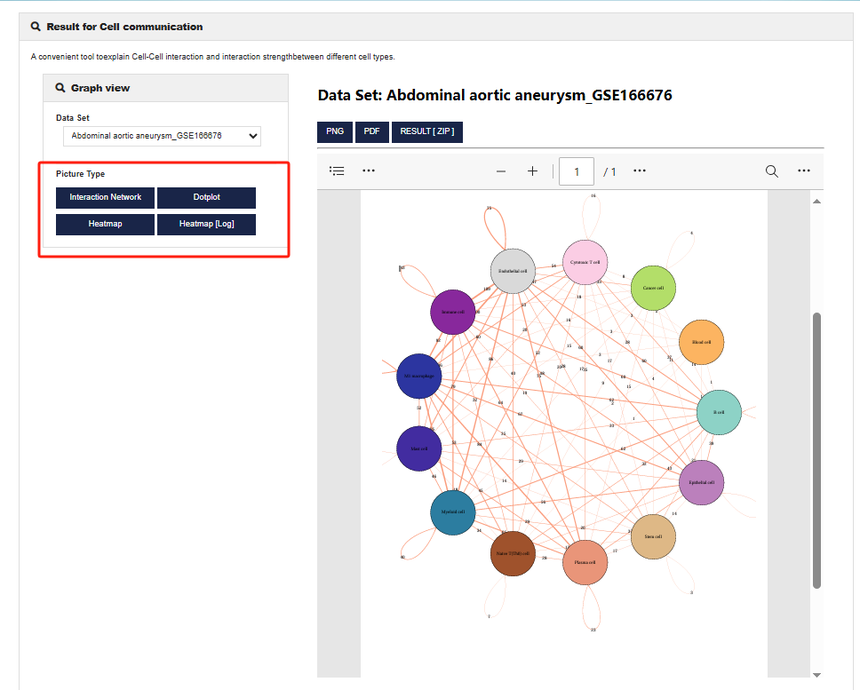
4.6 Cell Communication
细胞通讯分析工具则是细胞间交流的探测器。基于大量的配体-受体相互作用数据,构建出细胞间的通讯网络。在免疫反应研究中,可清晰展示免疫细胞之间如何通过信号传递协同作战;在器官发育研究中,能揭示不同细胞类型在发育过程中的相互调控关系,为理解细胞群体行为和组织器官的形成机制提供关键线索。
图片展示共有4种类型,分别是“Interaction Network”(相互作用网络)、“Dotplot”(点图)、“Heatmap”(热图)、“Heatmap(Log)”(热图(Log格式))。右侧中每个彩色的圆圈代表一种细胞类型,圆圈内标注了细胞类型的名称,圆圈之间的连线表示细胞类型之间的相互作用,连线的粗细可能代表相互作用的强度,通过该图可以直观地观察不同细胞类型之间的相互作用关系和潜在的通讯网络,有助于发现关键的细胞间相互作用模式。
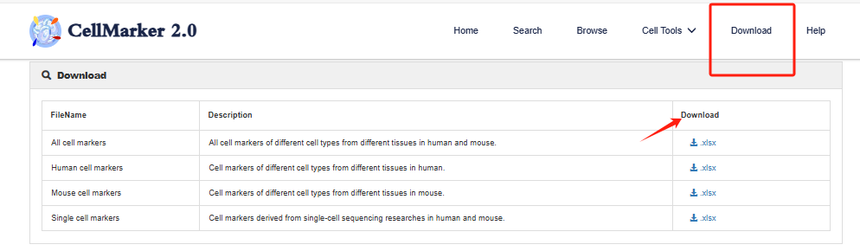
5. 数据下载
所有的列表可以通过点击“xlsx”下载对应格式的列表。在Download栏下可以直接下载所有的标记基因信息。对专业的分析人员来说,他们会将下载的所有数据整理成rds文件,方便后续在R中使用。
综上所述,CellMarker 2.0数据库以其丰富的数据资源、广泛的细胞与组织类型、强大的分析工具以及便捷的数据下载功能,在单细胞研究领域展现出卓越的价值。它助力科研工作者在复杂的单细胞研究世界中高效挖掘信息、获取突破,有望持续引领单细胞研究数据库领域的发展潮流,激发更多创新研究成果的诞生。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









