






山寨版 OpenAI o1 实验记录
知乎:季逸超
链接:https://zhuanlan.zhihu.com/p/720575010
,时长00:27
纠结了一下还是决定把中秋假期捣鼓的山寨版 o1 模型开源出来。受限于数据和算力,该模型还只是个玩具,离 OpenAI o1 差十万八千里。但实验的过程中有些记录值得分享出来抛砖引玉:
-
起因是在测试 o1 时,种种迹象 (见下方附录) 表明它在 inference-time 似乎没有进行 MCTS 或外置的 agentic 的反思,更像是一个在 reasoning path 数据集上训练的 GPT-4o;
-
大家重点讨论的 RL self-play 更多应该是在合成 reasoning path 数据时,而有了 synthetic datasets 之后,整个 post-training 和 inference 应该和传统模型相差不大;
-
这让我想起 Nye, Maxwell, et al. 在 2021 年关于 "scratchpad tokens" 的工作,从某种意义上来说,o1 的 CoT 可能就是将 reasoning path 作为 scratchpad tokens 放在 output 之前,只是这些 reasoning tokens 长度非常长,质量非常高;
-
既然如此,我们不妨尝试在现有的开源 foundation 上,使用一定量的 reasoning path 数据来进行训练,只要是 reasoning path 数据就行,不一定非要是 RL self-play 或 tree search 挑选出来的;
-
个人资源有限,假期一共也只有三天,在固定的 compute-budge 下,考虑到 scratchpad tokens,我认为 longer sequence + smaller base model 会更有价值;
-
数据集首先是 30K 条来自 SkunkworksAI/reasoning-0.01 的样本,但这个 dataset 里基本是 step-by-step 的拆解,没有多少反思,因此又加上几千条我自己人工录入 + 用更强的模型合成的样本;
-
在输出中,我加上了两个额外的 token: "<|reasoning_start|>" 和 "<|reasoning_end|>",但是... 训练时忘了换改过的 tokenizer,导致这俩以 plain text 的形式存在了,但影响不大;
-
最终选择用 7B 的 Qwen2 作为 base model,用 8 张 A100 80GB 在 4096 的长度上训练得到 Peak-Reasoning-7B-preview。
一些观察:
-
现有的 reasoning path 数据的质和量都不行,而这正是 OpenAI o1 的 “护城河”:尤其是 o1 在 ChatGPT 上线后能够收集到更多更 diverse 的问题,这非常宝贵,因为 path 可以合成,提出好的问题很难;
-
目前的数据只能支持我做 SFT,但仔细想想其实 SFT 的 loss 并不适配 long reasoning path,单一 reward 的 RL 方法也不合适。最好是能有 by-step 或者 sub-goal 的 reward 去训练,这里的难度应该不小;
-
我很想看看 o1 完整的 reasoning 输出,可惜 OpenAI 藏的非常严实,只有官网几个例子最完整 (看起来甚至像真人解题的录音转录?),想跟 o1 套话的话会被 OpenAI 邮件警告,所以,我们只能靠自己了;
-
由于输出格式变了,所以没去跑现有的 benchmark,但我其实也试了 1.5B 的 base model,肉眼可见差距巨大。非常期待有更多资源的朋友能试试在 70B 甚至 100B+ 的 base model 上进行类似的实验,我感觉能出奇迹!
链接:
-
Demo 聊天界面: Peak-Reasoning-7B-preview
-
开源模型下载 (BF16/AWQ/GGUF): https://huggingface.co/collections/peakji/peak-reasoning-66e8fd22483df532fd424a0d
-
Nye, Maxwell, et al. "Show your work: Scratchpads for intermediate computation with language models." arXiv preprint arXiv:2112.00114 (2021).
附录:为啥我感觉 o1 在 inference-time 没有进行 MCTS:
-
OpenAI 官网有几个完整的 CoT 放出来,看起来不是 search 的,里面有很多 "wait..."、"perfect! I think I get it!",当然不排除是 search 的结果;
-
o1 report 的 benchmark 全都是 pass@1 和 majority voting (64),明确说了没有 tree search;
-
网友在 OpenAI AMA 提问时,OpenAI 说 o1 是 single model,不是 system/framework;
-
ChatGPT 里 o1 的 reasoning 虽然是摘要,但确实是动态 stream 输出的,而我从没见过他回溯;
-
我统计了一下 o1 API 里 reasoning token count (API 不给看具体的 token,但为了收钱会告诉你数量) 与推理耗时的曲线,如果是 MCTS 应该是 sub-linear 关系,为了复用 cache 要尽量并行推理。o1 API 可以锁 seed 但是不支持改 temperature 等 samping 参数。为了减少 pre-fill 对耗时的影响,都是选的 短输入 + 长输出 的 prompt,然后挂了一晚上,每个样本跑 3 次。结果见下图:
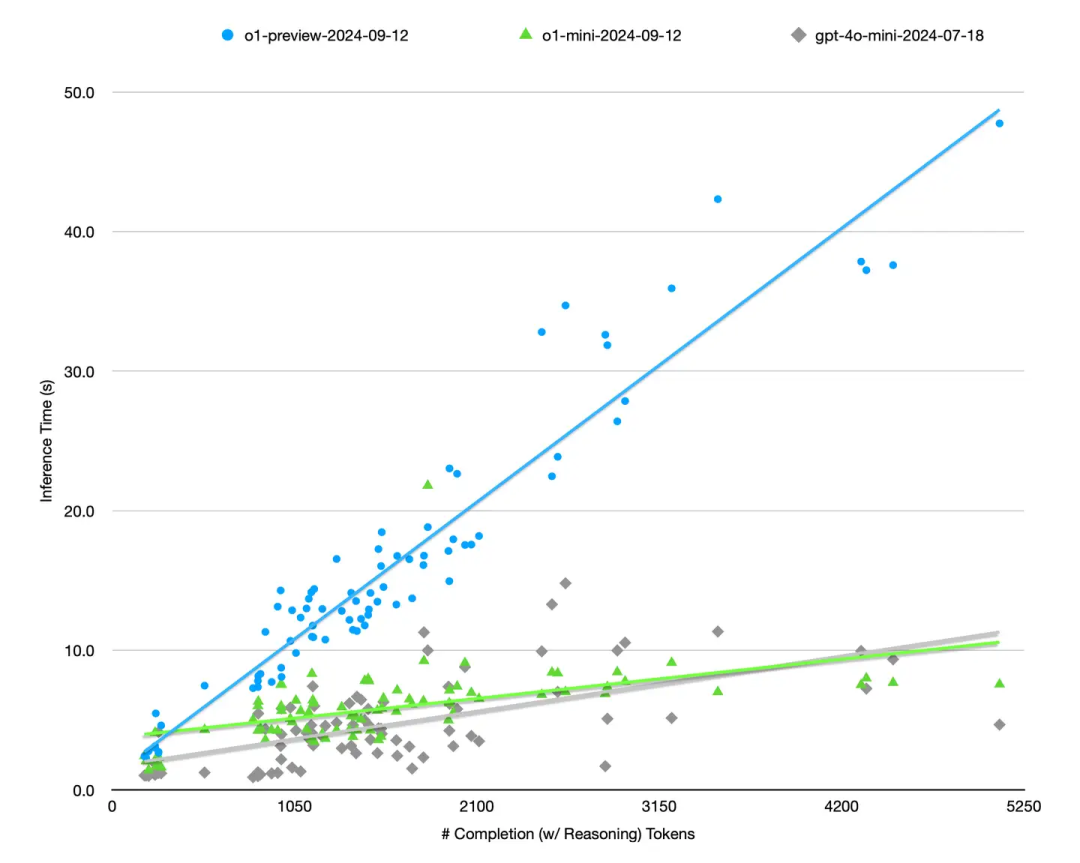
o1 的推理耗时与总输出 tokens (reasoning+completion) 的关系非常线性,不像是并行 MCTS。
















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











