







 本文探讨了在语义分割中的多尺度注意力机制,以解决细节错误和类混淆问题。研究团队通过HRNet作为网络主干,结合RMI损失函数,实现了在Cityscapes和Mapillary数据集上的优异结果。他们还提出了一种层次的多尺度注意力方法,减少了训练成本,提高了预测精度。此外,利用自动标签生成技术改进了粗略数据的利用,从而提升了模型的泛化能力。
本文探讨了在语义分割中的多尺度注意力机制,以解决细节错误和类混淆问题。研究团队通过HRNet作为网络主干,结合RMI损失函数,实现了在Cityscapes和Mapillary数据集上的优异结果。他们还提出了一种层次的多尺度注意力方法,减少了训练成本,提高了预测精度。此外,利用自动标签生成技术改进了粗略数据的利用,从而提升了模型的泛化能力。
多尺度注意力机制的语义分割
Using Multi-Scale Attention for Semantic Segmentation
在自动驾驶、医学成像甚至变焦虚拟背景中,有一项重要的技术是常用的:语义分割。这是将图像中的像素标记为属于N个类(N是任意数量的类)之一的过程,其中类可以是汽车、道路、人或树等。对于医学图像,类对应于不同的器官或解剖结构。
NVIDIA是一种应用广泛的语义分割技术。还认为,改进语义分割的技术也可能有助于改进许多其密集预测任务,如光流预测(预测物体运动)、图像超分辨率等。 开发了一种新的语义分割方法,在两个共同的基准上实现了创纪录的最新结果:城市景观Cityscapes数据集和地图景观,如下表所示。IOU是union上的交集,是一种描述语义预测准确性的度量。
在城市景观Cityscapes数据集中,这种方法在测试集上达到85.4个IOU,与其条目相比有了很大的改进,因为这些分数彼此非常接近。
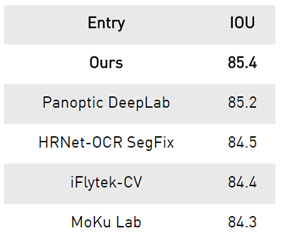
Table 1. Results on Cityscapes test set.
与使用集成实现58.7的次优结果相比,使用Mapillary,在使用单个模型的验证集上实现61.1 IOU。

Table 2. Results on Mapillary Vistas semantic segmentation validation set.
Research journey
为了开发这种新方法,考虑了图像的哪些特定区域需要改进。图1显示了当前语义分割模型的两种最大的失败模式:细节错误和类混淆。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









