







NPU架构与算力分析
参考文献链接
https://mp.weixin.qq.com/s/xc_-5SmtWLGQuX3w-ptPfA
https://mp.weixin.qq.com/s/samT5gYMsrwBguvMTHbS9Q
https://mp.weixin.qq.com/s/uJkAhJzUpGeyYvO92p4-Ow
https://mp.weixin.qq.com/s/BRY2ExcWztl7vf69UyNAUw
https://mp.weixin.qq.com/s/BKzNwfVe-Bsoh_2090HHcQ
芯片的NPU算力
算力简单说就是计算能力,按《中国算力发展指数白皮书》中的定义算力是设备通过处理数据,实现特定结果输出的计算能力。2018年诺贝尔经济学奖获得者William D. Nordhau滤《计算过程》一文中提出:“算力是设备根据内部每秒可处理的信息数据量"。算力实现的核心是CPU、GPU等各类计算芯片,并由计算机、服务器、高性能计多集群和各类智能终端等承载,海量数据处理和各种数字化应用都离不开算力的加工和计算。
以AI为例,CPU、GPU、DSP等都可以运行,但是还是有专用的AI芯片,为什么呢?也跟算力有关。
• CPU(central processing unit)是通用处理器,可以处理一切事物,就像一把瑞士军刀,哪方面都能做但都不是专业高效的。
• GPU(Graphics Processing Unit)是专门用来处理图形图像相关的处理器,与CPU相比GPU处理的数据类型单一,因为运算与AI相似以及容易组成大的集群,所以进行AI运算时在性能、功耗等很多方面远远优于CPU,经常被拿来处理AI运算。
• DSP(digital signal processor),是专门用来处理数字信号的,DSP与GPU情况相似,也会被拿来做AI运算,比如高通的手机SoC。
AI芯片是专门用来处理AI相关运算的芯片,这与CPU、GPU、DSP的“兼职”做AI运算不同,即便是最高效的GPU与AI芯片相比也是有差距的,AI芯片在时延、性能、功耗、能效比等方面全面的超过上面提到的各种处理器。以知名的谷歌的TPU为例,如下图所示,TPU的主要计算资源为:
• Matrix Multiply Unit:矩阵乘单元
• Accumulators:存储矩阵乘加输出的中间结果
• Activation:激活单元
• Unified Buffer:统一缓存
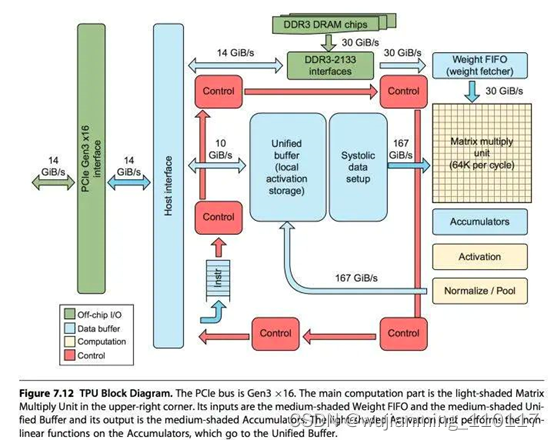
当时谷歌资深硬件工程师Norman Jouppi表示,谷歌的专用机器学习芯片TPU处理速度要比GPU和CPU快15-30倍(和TPU对比的是英特尔Haswell CPU以及Nvidia Tesla K80 GPU),而在能效上,TPU更是提升了30到80倍,这并不意外,因为TPU运行的CNN运算主要就是矩阵乘,专用芯片好处就是这样。其实对于对于AI来说,又分为训练和推理,训练就像AlphaGo一样需要学很多的棋谱(数据),通常采用数据精度为FP32。
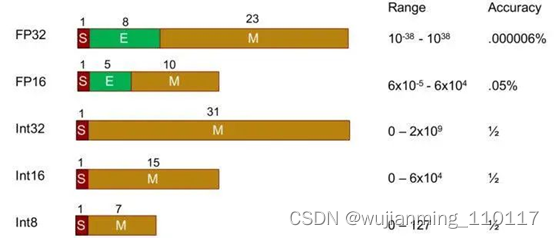
• FP32(Full Precise Float 32,单精度)占用4个字节,共32bit,
• FP16(float,半精度)占用2个字节,共16bit,
• INT8,占用1个字节,也就是8bit,精度更低,因此数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
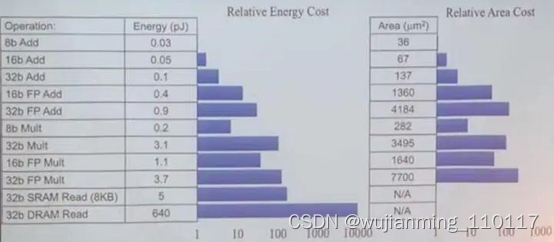
不同精度计算消耗的Bill Dally 在ACMMM 2017 上的《Efficient Methods and Hardware for Deep Learning》演讲中曾经列过一个不同精度计算的消耗能量和硅片面积对比,可以看出一个FP32精度的乘法运算消耗是INT8精度的18.5倍。因此同样一块芯片运算INT8的数据与运算FP32的数据在同一时间内运算次数相差很多,也就是说不同精度OPS不同,算力不同。
这样的精度如果运行在手机等终端上是不行的,所以在在手机、汽车、安防等终端领域,都是执行模型的推理,现有的推理芯片有很多,比如特斯拉FSD、寒武纪NPU、地平线BPU、OPPO的马里亚纳、荣耀使用的AI-ISP等。与训练阶段不同,在推理的时候,精度要求并不高,以知名的对象监测算法YOLO(You Only Look Once)为例,FP32的精度与INT8的精度相差甚小,但是因为模型更小,神经网络模型的推理速度却大幅加快。这在终端上很重要,比如在汽车的自动驾驶上,如果推理计算的数据慢了会造成巨大的影响。

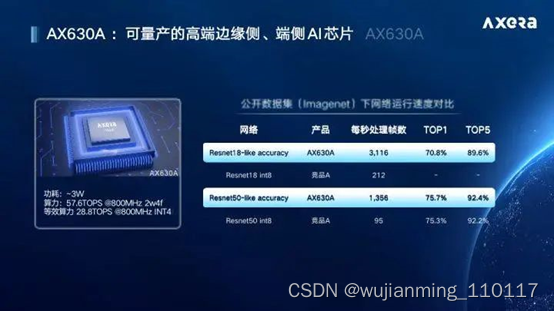
当然在安防等对精度要求更低的地方,还有很多采用的是INT4精度的,比如爱芯科技的AX630A在INT4精度下的算力达到了28.8TOPS,可应用于智能盒子,运动相机,智能加速卡,工业摄像头等领域,如果是INT8精度就是7.2TOPS(这里要注意的是并不是所有的AI芯片支持不同精度下的算力转换,这需要硬件实现上的支持)
在终端芯片上,厂商宣称的算力有时候甚至不是AI芯片的算力,因为CPU、GPU、DSP都可以进行AI的运算,所以在宣传算力的时候采用的是CPU算力 + GPU算力 + DSP算力的算法,虽然这些处理单元都在一颗芯片上但是在实际使用上不可能同时进行AI运算。

因为一些手机芯片的AI处理能力不足,以及处理流程在YUV域较为靠后,所以像OPPO等厂商开始推出马里亚纳这样的AI芯片,18TOPS并前置在手机SOC之前在RAW域进行 AI降噪的处理,可以大幅的提升夜景拍摄能力,保留更多细节。
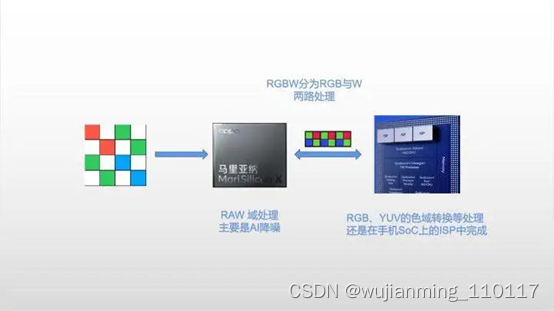
荣耀采用的AI-ISP也是一样的道理,其实这类芯片本质上是一个处理AI运算的NPU,从业务上来说更好的叫法是Pre-ISP,并不是真正的ISP芯片。
打破内存墙、功耗墙,国产芯片AI-NPU
随着5G的落地,物联网的成本效益显现,工业数字化、城市智慧化等演进趋势日益明显,越来越多的企业和城市开始在物联网创新中加入数字孪生这种颠覆性的概念,来提高生产力和生产效率、降低成本,加速新型智慧城市的建设。值得一提的是,数字孪生技术已被写进国家“十四五”规划,为数字孪生城市建设提供国家战略指引。
关于数字孪生,可以举个例子,前几年亚马逊和京东推过的无人零售概念型实体店,将线下零售店变成了线上淘宝店,人们去店里购物前只需打开APP,在设置中完成刷脸登录,脸部认证成功后,在刷脸开门时即可自动关联账户,购物后不用排队手动结账,只靠刷脸即可离开。看似无人管理,但背后却是人工智能的全程跟踪,消费者的一举一动都被摄像头捕捉了下来,比如把什么商品拿起来看了又看,意味着对这个商品很有兴趣,但是出于某种顾虑又没买,最终买了另外的商品,这样的数据会被抓取下来,进行深层次的分析,形成基础数据库,之后就可以根据所有的购物记录和消费习惯进行周期性的推送等。
通过这个例子,可以看到将物理世界数字化带来的便利性。而视觉是人类感知世界的一个重要手段。人类进入智能社会的基础是数字化,感知是将物理世界数字化的前提,而前端视觉感知的种类、数量和质量决定了这个社会智能化程度的高低。由此可见,智能化未来的基础是“感知 + 计算”,AI视觉在智能化的进程中会起到非常关键的作用,具备非常广阔的应用前景。有行业分析师认为,数字孪生技术即将超越制造业,进入物联网、人工智能和数据分析等整合领域。这也就是选择了这个创业方向的原因。
而视觉芯片作为物理世界到数字孪生世界最重要的入口,正受到广泛关注,尤其是能够对物理世界进行80%-90%还原的AI视觉感知芯片。
那么什么是AI视觉感知芯片呢?从需求端的角度来看,AI视觉感知芯片需要具备两大功能:一是看得清,二是看得懂,其中AI-ISP负责的就
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









