







 本文探讨了深度学习模型轻量化的三个层次:算法层、框架层和硬件层。算法层涉及结构优化如矩阵分解、权值共享、分组卷积和模型剪枝等;框架层包括编译优化和硬件特定的加速;硬件层关注AI芯片定制以加速模型运行。文章以实例详细阐述了结构优化中的各种方法,如矩阵分解和卷积优化。
本文探讨了深度学习模型轻量化的三个层次:算法层、框架层和硬件层。算法层涉及结构优化如矩阵分解、权值共享、分组卷积和模型剪枝等;框架层包括编译优化和硬件特定的加速;硬件层关注AI芯片定制以加速模型运行。文章以实例详细阐述了结构优化中的各种方法,如矩阵分解和卷积优化。
深度学习模型轻量化(上)
移动端模型必须满足模型尺寸小、计算复杂度低、电池耗电量低、下发更新部署灵活等条件。
模型压缩和加速是两个不同的话题,有时候压缩并不一定能带来加速的效果,有时候又是相辅相成的。压缩重点在于减少网络参数量,加速则侧重在降低计算复杂度、提升并行能力等。模型压缩和加速可以从多个角度来优化。总体来看,个人认为主要分为三个层次:
-
算法层压缩加速。这个维度主要在算法应用层,也是大多数算法工程师的工作范畴。主要包括结构优化(如矩阵分解、分组卷积、小卷积核等)、量化与定点化、模型剪枝、模型蒸馏等。
-
框架层加速。这个维度主要在算法框架层,比如tf-lite、NCNN、MNN等。主要包括编译优化、缓存优化、稀疏存储和计算、NEON指令应用、算子优化等
-
硬件层加速。这个维度主要在AI硬件芯片层,目前有GPU、FPGA、ASIC等多种方案,各种TPU、NPU就是ASIC这种方案,通过专门为深度学习进行芯片定制,大大加速模型运行速度。
下面也会分算法层、框架层和硬件层三个方面进行介绍。
2 算法层压缩加速
2.1 结构优化
2.1.1 矩阵分解
举个例子,将MN的矩阵分解为MK + K*N,只要让K<<M 且 K << N,就可以大大降低模型体积。比如在ALBERT的embedding层,就做了矩阵分解的优化。如下图所示
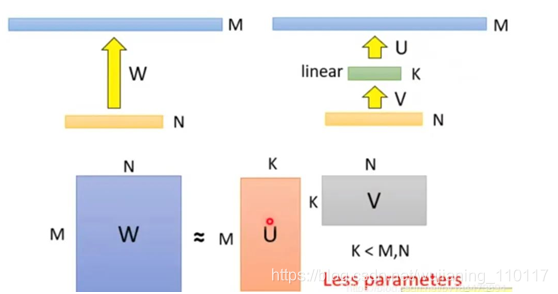
其中M为词表长度,也就是vocab_size,典型值为21128。N为隐层大小,典型值为1024,也就是hidden_size。K为我们设置的低维词嵌入空间,可以设置为128。
-
分解前:矩阵参数量为 (M * N)
-
分解后:参数量为 (MK + KN)
-
压缩量:(M * N) / (MK + KN), 由于M远大于N,故可近似为 N / k,当N=2014,k=128时,可以压缩8倍
2.1.2 权值共享
相对于DNN全连接参数量过大的问题,CNN提出了局部感受野和权值共享的概念。在NLP中同样也有类似应用的场景。比如ALBert中,12层共用同一套参数,包括multi-head self attention和feed-forward,从而使得参数量降低到原来的1/12。这个方案对于模型压缩作用很大,但对于推理加速则收
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









