







 本文详细介绍了CUDA 9中张量核(Tensor Cores)的编程,包括张量核的概念、优势和在CUDA库(cuBLAS、cuDNN)中的应用。张量核提供高吞吐量的矩阵运算,适用于深度学习和高计算需求的场景。通过简单的代码示例展示了如何在cuBLAS和cuDNN中启用张量核,以及如何在CUDA C++中直接编程使用张量核。
本文详细介绍了CUDA 9中张量核(Tensor Cores)的编程,包括张量核的概念、优势和在CUDA库(cuBLAS、cuDNN)中的应用。张量核提供高吞吐量的矩阵运算,适用于深度学习和高计算需求的场景。通过简单的代码示例展示了如何在cuBLAS和cuDNN中启用张量核,以及如何在CUDA C++中直接编程使用张量核。
CUDA 9中张量核(Tensor Cores)编程
Programming Tensor Cores in CUDA 9
一.概述
新的Volta GPU架构的一个重要特点是它的Tensor核,使Tesla V100加速器的峰值吞吐量是上一代Tesla P100的32位浮点吞吐量的12倍。Tensor内核使人工智能程序员能够使用混合精度来获得更高的吞吐量,而不牺牲精度。
Tensor核心已经在许多深度学习框架(包括Tensorflow、PyTorch、MXNet和Caffe2)中支持深度学习训练,无论是在主版本中还是通过pull请求。有关在使用这些框架时启用Tensor核心的更多信息,请参阅《混合精度训练指南》。对于深度学习推理,最近的TensorRT 3版本也支持Tensor核心。
本文将展示如何使用CUDA库在自己的应用程序中使用张量核,以及如何在CUDA C++设备代码中直接编程。

二.什么是张量核(Tensor Cores)?
特斯拉V100的张量核心是可编程的矩阵乘法和累加单元,可以提供多达125 Tensor tflop的训练和推理应用。特斯拉V100
GPU包含640个Tensor Cores:8/SM。Tensor内核及其相关的数据路径是定制的,以显著提高浮点计算吞吐量,只需适当的区域和功耗。时钟选通广泛应用于最大限度地节省功耗。
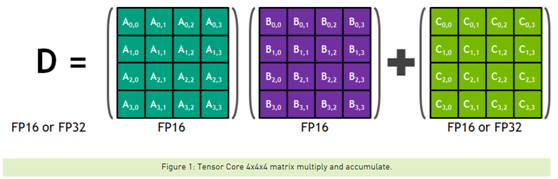
每个张量核提供一个4x4x4矩阵处理数组,它执行操作D=a*B+C,其中a、B、C和D是4×4矩阵,如图1所示。矩阵乘法输入A和B是FP16矩阵,而累积矩阵C和D可以是FP16或FP32矩阵。

每个张量核执行64个浮点FMA混合精度操作每个时钟(FP16输入乘法与全精度积和FP32累加,如图2所示)和8张量核在一个SM执行总共1024个浮点操作每个时钟。与使用标准FP32操作的Pascal GP100相比,每SM深度学习应用程序的吞吐量显著增加了8倍,因此Volta V100 GPU的吞吐量与Pascal P100 GPU相比总共增加了12倍。张量核对FP16输入数据进行运算,FP32累加。如图2所示,对于4x4x4矩阵乘法,FP16乘法产生的全精度结果是在FP32运算中与给定点积中的其他乘积累积的结果。
三. CUDA库中的张量核
使用Tensor核的两个CUDA库是cuBLAS和cuDNN。cuBLAS使用张量核加速GEMM计算(GEMM是矩阵-矩阵乘法的BLAS术语);cuDNN使用张量核加速卷积和递归神经网络(RNNs)。
许多计算应用程序使用GEMM:信号处理、流体动力学等等。随着这些应用程序的数据大小呈指数级增长,这些应用程序需要在处理速度上进行匹配。图3中的混合精度GEMM性能图显示,张量核显然满足了这一需求。
提高卷积速度的需求同样巨大;例如,深神经网络(DNNs)使用了许多层卷积。人工智能研究人员每年都在设计越来越深的神经网络;最深的神经网络中的卷积层现在有几十个。训练DNNs需要卷积层在正向和反向传播期间重复运行。
图4中的卷积性能图显示,张量核满足卷积性能的需要。
两个性能图表都显示,特斯拉V100的张量核心提供了数倍于上一代特斯拉P100的性能。性能改进这一巨大的变化如何在计算领域工作:使交互性成为可能,启用“假设”方案研究,或减少服务器场使用。如果在应用程序中使用GEMM或卷积,请使用下面的简单步骤来提高工作效率。
四.如何在立方体中使用张量核
通过对现有cuBLAS代码进行一些更改,可以利用张量核。这些变化是在使用cuBLAS API时的小变化。
下面的示例代码应用一些简单的规则来指示cuBLAS应该使用张量核;这些规则在代码后面显式枚举。
示例代码
下面的代码与以前的架构中用于调用cuBLAS中GEMM的通用代码基本相同。
// First, create a cuBLAS hand
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









