







大模型的研究新方向:混合专家模型(MoE)
吴蔚喆 羚羊工业大模型 2024-05-27 21:40 安徽
随着GPT-4、DeepSeekMoE等模型的发布中均涉及到了混合专家模型(MoE,Mixture of Experts)的话题,MoE 模型已经成为开放 AI 社区的热门话题。2023年6月,美国知名骇客George Hotz在接受采访时透露,GPT-4由8个220B的专家模型组成。假如把8个专家模型比喻为比GPT-3还大的脑袋,那GPT-4就是一个八个头的超级大怪兽。

GPT-4(MoE)比GPT-3(Transformer)和GPT-3.5(RLHF)强大一个数量级的关键,可能就是来源于MoE架构。之前的GPT大模型增大参数的方法是在一个GPT模型上堆层数,现在变成了堆模型数。将来大语言模型的研究新方向,可能就不是增大单一模型的向量维度和层数了,而是增大整体架构的模型数了。GPT-4引入MoE似乎是个必然,因为无论是算力、数据、稳定性,万亿级参数的单个大模型训练很困难,而且推理成本也会居高不下,跑万亿个参数的计算才能算出一个token的速度和成本比较不可观。所以,将若干个模型堆成一个MoE大模型似乎是个必然趋势。
那么,究竟什么是MoE大模型?MoE大模型具备哪些优势呢?
MoE,全称为Mixed Expert Models,混合专家模型,简单理解就是将多个专家模型混合起来形成一个新的模型。在理解MOE之前,有两个思想前提,可以帮助我们更容易地理解MOE架构。一是在现实生活中,如果有一个包括了多个领域知识的复杂问题,我们该使用什么样的方法来解决呢?最简单的办法就是先拆分任务到各领域,然后把各个领域的专家集合到一起来攻克这个任务,最后再汇总结论。这个思想可以追溯到集成学习,MoE和集成学习的思想异曲同工,都是集成了多个模型的方法,区别在于集成学习不需要将任务分解为子任务。集成学习是通过训练多个基学习器来解决同一问题,并且将它们的预测结果简单组合(例如投票或平均)。而MOE是把大问题先做拆分,再逐个解决小问题,再汇总结论。二是模型规模是提升模型性能的关键因素之一。在有限的计算资源下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
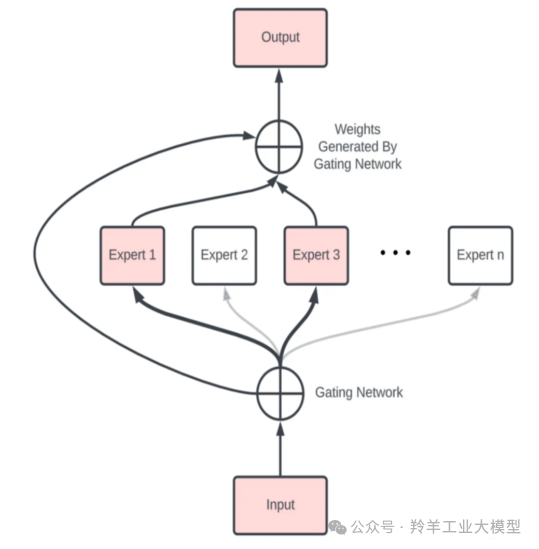
MoE正是基于上述的理念,它由多个专业化的子模型(即“专家”)组合而成,每一个“专家”都有其擅长的领域。而决定哪个“专家”参与解答特定问题的,是一个称为“门控网络”的机制。技术上常说的门控机制,可能会先想到LSTM的门控机制,但是这里的门控机制和LSTM里的门控不一样。LSTM的门是为了控制信息流动,这里的门就更像我们日常中提到的门,选择进门或是不进门,是一个控制是否使用某个专家模型的概率分布值。
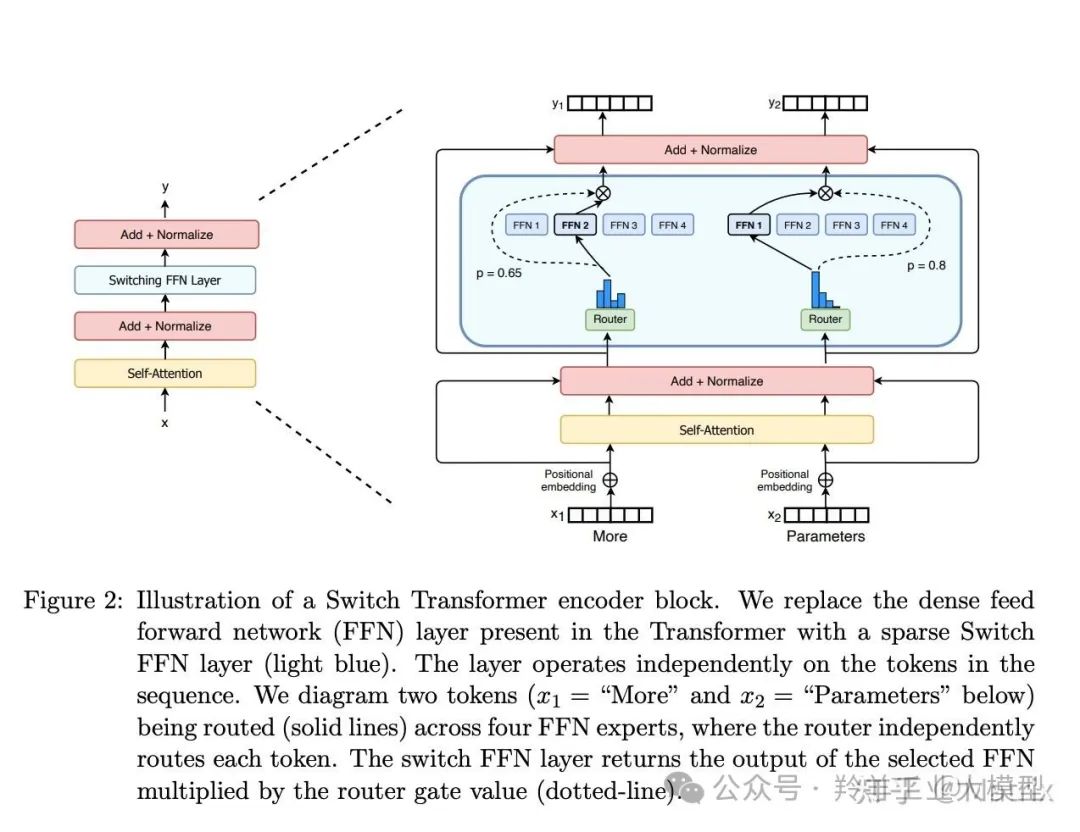
MoE基于Transformer架构,主要由两部分组成:
稀疏 MoE 层:MoE层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”模型,每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构。
门控网络或路由: 这个部分用于决定哪些 token 被发送到哪个专家。例如,在上图中,“More”这个 token 可能被发送到第二个专家,而“Parameters”这个 token 被发送到第一个专家。同时,一个 token 也可以被发送到多个专家。token 的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。例如Google的Switch Transformer,模型大小是T5-XXL的15倍,在相同计算资源下,Switch Transformer模型在达到固定困惑度 PPL 时,比T5-XXL模型快4倍。
国内的团队DeepSeek 开源了国内首个 MoE 大模型 DeepSeekMoE。
DeepSeekMoE 2B可接近2B Dense,仅用了17.5%计算量。
DeepSeekMoE 16B性能比肩 LLaMA2 7B 的同时,仅用了40%计算量。
DeepSeekMoE 145B 优于Google 的MoE大模型GShard,而且仅用 28.5%计算量即可匹配 67B Dense 模型的性能。
此外,MoE大模型的优点还有:
-
训练速度更快,效果更好。
-
相同参数,推理成本低。
-
扩展能力强,允许模型在保持计算成本不变的情况下增加参数数量,这使得它能够扩展到非常大的模型规模,如万亿参数模型。
-
多任务学习能力,MoE在多任务学习中具备很好的性能。
MoE结合大模型属于老树发新芽,MOE大模型的崛起是因为大模型的发展已经到了一个瓶颈期,包括大模型的“幻觉”问题、逻辑理解能力、数学推理能力等,想要解决这些问题就不得不继续增加模型的复杂度。随着应用场景的复杂化和细分化,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,尤其在多模态大模型的发展浪潮之下,每个数据集可能完全不同,有来自文本的数据、图像的数据、语音的数据等,数据特征可能非常不同,MoE是一种性价比更高的选择。国内大模型已经开始朝着MoE方向大步前进,在2024年,估计会有越来越多大模型选择MoE架构。
后文将介绍MoE的主要原理,以此来理解MoE大模型优势产生的原因。
一、Adaptive mixtures of local experts
Adaptive mixtures of local experts,这是大多数MoE论文都引用的最早的一篇文章,发表于1991年。论文介绍了一种新的监督学习过程——由多个独立网络组成一个系统,每个网络单独处理训练集合的子集。因为对于多任务学习,如果是常见的多层网络学习,各层之间的网络通常会有强烈的干扰效应,这会导致学习过程变慢和泛化能力差。为了解决这个问题,论文提出了使用多个模型(即专家,expert)去学习,使用一个门控网络(gating network)来决定每个数据应该被哪个模型去训练的权重,这样就可以减轻不同类型样本之间的干扰。
对于一个样本 c,第 i 个 expert 的输出为
![]()
,期望的输出向量为dc,那么损失函数为:
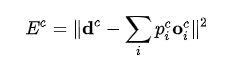
其中
![]()
是门控网络分配给第 i 个expert的权重。
但是,作者提到这个损失函数可能会导致专家网络之间的强烈耦合,因为是所有专家网络的权重加总来共同计算损失的,一个专家权重的变化会影响到其他专家网络的loss。这种耦合可能会导致多个专家网络被用于处理每条样本,而不是专注于它们各自擅长的子任务。为了解决这个问题,论文重新定义了损失函数,以鼓励专家网络之间的相互竞争。
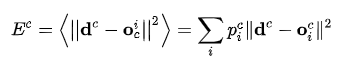
就是先让不同的expert单独计算loss,然后再加权求和得到总体的loss。这意味着,每个expert在处理特定样本的目标是独立于其他expert的。如果门控网络和expert都使用这个新的loss进行梯度下降训练,系统会倾向于将某类特定样本分配给特定的expert。因为当一个expert在给定样本上的的loss小于所有expert的平均loss时,它对该样本的门控score会增加;当它的表现不如平均loss时,它的门控score会减少。这种机制鼓励expert之间的竞争,而不是合作,从而提高了学习效率和泛化能力。
二、Sparsely-Gated MoE
在 2010 至 2015 年间,两个独立的研究领域为混合专家模型 (MoE) 的后续发展做出了显著贡献:
组件专家:Eigen、Ranzato 和 Ilya 探索了将 MoE 作为更深层网络的一个组件。这种方法允许将 MoE 嵌入到多层网络中的某一层,使得模型既大又高效。
条件计算(Conditional Computation):传统的神经网络通过每一层处理所有输入数据。Yoshua Bengio 等研究人员开始探索基于输入 token 动态激活或停用网络组件的方法。
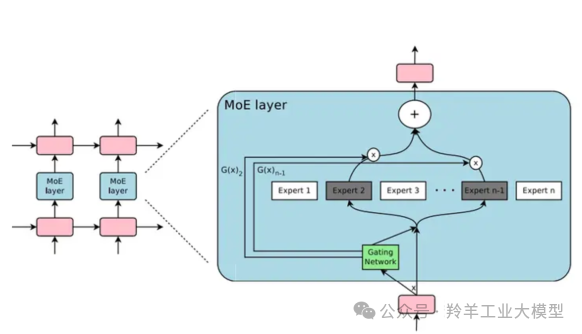
2017 年,Shazeer 等人将上述概念应用于 137B 的 LSTM 。通过引入稀疏性,这项工作在保持极高规模的同时实现了快速的推理速度。在牺牲极少的计算效率的情况下,把模型规模提升1000多倍。这项工作被发表在论文Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer中,和 1991 年Adaptive mixtures of local experts的工作对比,这里的 Sparsely-Gated MoE 主要有两个区别:
-
Sparsely-Gated:不是所有expert都会起作用,而是极少数的expert会被使用来进行推理。这种稀疏性,也使得我们可以使用海量的experts来把模型多倍扩大。
-
token-level:相比于sample-level,即不同的样本,使用不同的专家,采用token-level,即一个句子中不同的token使用不同的专家。
如上图所示,每个token都会接一层MoE Layer,每个MoE layer中包含了多个experts,还有一个Gating Network会根据当前 token,选择少数几个expert来进行计算。
2.1 门控网络(Gating Network)
门控网络(Gating Network)的设计和实现是Sparsely-Gated MoE 层的核心组成部分。门控网络负责为每个输入 token 选择一个稀疏的专家组合。一般门控网络最简单的就是概率分布形式,根据概率去做出相应的选择。那么在深度学习中,最简单的网络就是,设定门控网络为一个简单的前馈神经网络,最后接一层softmax,作为每个专家的使用权重。
设 G(x) 和 Ei(x) 分别是门控网络和第 i 个 expert 的输出,那么对于在当前的输入x,输出就是所有 experts 的加权和:
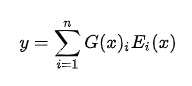
那么一个典型的门控网络就是一个带有 softmax 函数的简单的网络。这个网络将学习将输入发送给哪个expert:

在这种设置下,所有expert都会对输入进行运算,再通过门控网络的输出进行加权求和,如果experts的数量太大,就会导致计算量非常大。但是,如果有一种方法能使某些专家模型的门控网络的输出为0,就没有必要对这个专家进行相应的计算,就可以节省计算资源。其中效果比较好的包括带噪声的 TopK 门控 (Noisy Top-K Gating)。这种门控方法引入了一些可调整的噪声,然后保留前 k 个值。具体来说:
1. 添加一些噪声
![]()
2. 选择保留前 k 个值
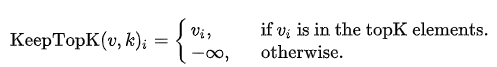
3. 应用 Softmax 函数
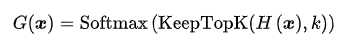
对于非TopK的部分,由于值是负无穷,这样在经过Softmax之后就会变成 0,不会被选中。噪声可以使得不同expert的负载更加均衡。在具体实验中,作者使用的 K=2~4。
在MoE模型中加入噪声的原因主要有以下几点:
-
提高模型的鲁棒性和泛化能力。当模型在训练或推理阶段遇到不确定或嘈杂的数据时,鲁棒性较强的模型更能保持稳定的性能。
-
减少过拟合的风险。
-
负载均衡:在MoE模型中,通过加入噪声可以实现不同专家之间的负载均衡。
2.2 辅助损失——均衡专家利用负载率(Balancing Expert Utilization)
要理解专家负载均衡,可以从batch size的角度出发。通常来讲,较大的 batch size 推理性能更好,但是由于样本在MoE层激活专家时需要并行,MoE层中每个专家的实际batch size会减少。举个例子,假设当前 batch 有10个token,其中5个token被路由到了某个专家网络,而其他5个token被路由到了其它5个不同的专家网络,这就会导致各专家网络获得的 batch size 不均匀,一个是另外的5倍,就会导致算力利用率不足的问题。
并且,如果我们把所有的token都发送给少数几个头部专家,训练效率将会变得低下。因为在训练中,门控网络会收敛至仅选择少数几个头部专家。这种情况会不断自我强化,因为受青睐的专家训练得更快,它的效果一直在被优化,因此选择它们的频率也会更高。那么此时,这几个少数专家就会过载,每次需要计算大量token,其他的专家模型就得不到训练而被闲置,就会导致模型失衡,性能下降。因此,MoE模型中需要控制专家均衡。上文加入噪声机制,可能就会导致门控在做出选择时跳过几个最优专家模型,去选择其余的专家模型,从而更好地协同工作。
此外,为了缓解这种情况,可以添加辅助损失,鼓励给予所有专家同等的重视。论文提出了一种软约束方法。作者定义了专家相对于一批训练样本的重要性 Importance(X) ,即该专家在这批样本中门控值的总和。然后定义了一个额外的损失函数 LImportance(X) ,这个损失函数被添加到模型的整体损失函数中。这个损失函数等于重要性值集合的CV(coefficient of variation)平方(变异系数,可以度量一组数据的离散程度),乘以一个手动调整的缩放因子 wImportance 。这个额外的损失鼓励所有专家具有相等的重要性,具体计算公式如下所示:
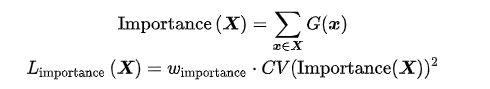
这种损失确保所有专家能收到数量大致相等的训练样本。
三、GShard
GShard是谷歌2021年在论文GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding中提出的使用GShard实现MoE跨设备分片的方法,是第一个将MoE的思想拓展到Transformer上的工作。它具体的做法是,把Transformer的encoder和decoder中,每隔一个的FFN层,替换成使用Top-2门控的MoE层。
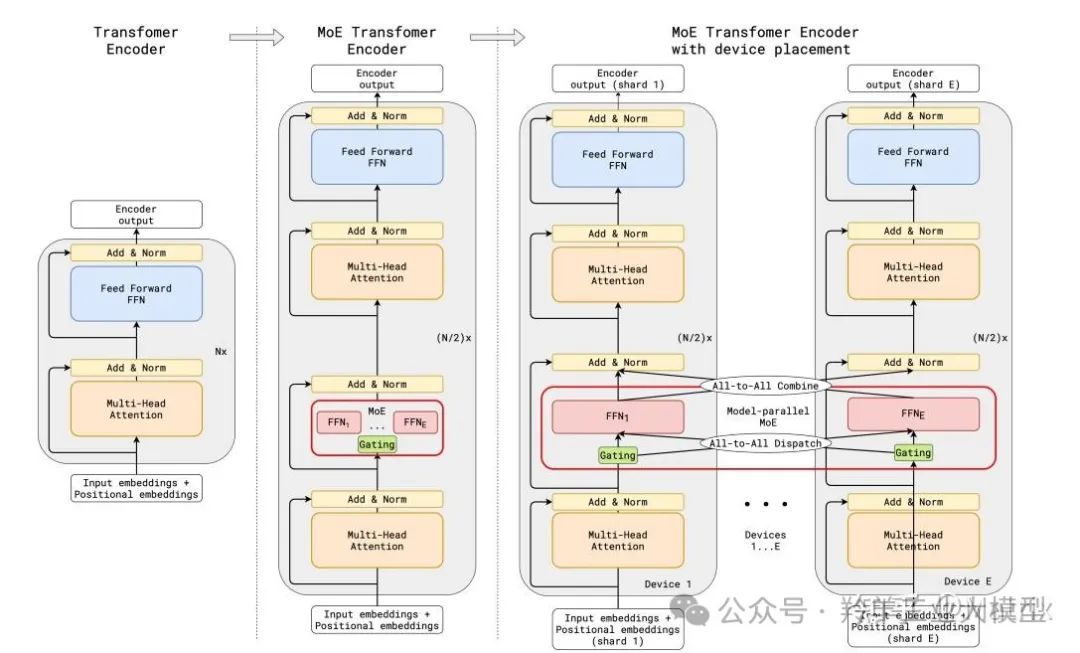
上图展示了编码器部分的结构。这种架构对于大规模计算非常有效:当扩展到多个设备时,MoE 层在不同设备间共享,而其他所有层则在每个设备上复制。GShard MoE层中的专家网络(experts)被分布在不同的设备上。每个专家网络负责处理一部分输入数据,并且每个token根据门控机制的输出被分配到一个或两个专家网络中。这样,整个 MoE 层的计算被分散到了多个设备上,每个设备负责处理一部分计算任务。
实现 MoE 跨设备分片的关键技术是模型并行化(model parallelism)和数据并行化(data parallelism)的结合。在模型并行化中,模型的不同部分(这里指MoE层的专家网络)被分配到不同的设备上。在数据并行化中,输入数据被分割成多个部分,每个部分被分配给不同的设备进行处理。由于专家被分配到不同设备,可以并行计算,大大提升了模型的计算效率,这也解释了为什么 MoE 可以实现更大模型参数、更低训练成本。
为了保持负载平衡和训练效率,GShard 的作者除了引入上节 Sparsely-Gated MoE 中的辅助 loss 外,还引入了一些关键变化:
-
随机路由:在 Top-2 设置中,GShard 始终选择排名最高的专家,但第二个专家是根据其权重比例随机选择的。
-
专家容量:设定一个阈值,定义一个专家最多能处理多少 token。如果专家容量达到上限,token 就会溢出,并通过残差连接传递到下一层,或被完全丢弃。专家容量是 MoE 中最重要的概念之一。为什么需要专家容量呢?因为我们无法提前知道多少 token 会分配给每个专家,因此需要一个固定的容量因子,来防止专家过载。其计算公式为:
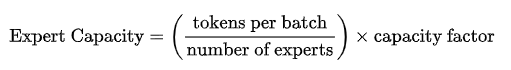
专家容量希望将 batch 中的总 token 数平均分配给所有专家。然后,为了应对 token 特征分布不均的情况,会通过一个容量因子来扩展每个专家的容量。容量因子是一个大于 1.0 的数,它的作用是为每个专家提供额外的缓冲空间,以容纳可能超出平均分配的 token。这样,在数据分布不均的情况下,即使某些专家接收到的 token 数量超过了平均值,也能够处理这些额外的 token,而不会因为容量不足而导致计算跳过。但是,如果容量因子设置得过高,会导致计算资源和内存的浪费,因为模型可能永远不会用到这额外的资源。经过研究,容量因子 在1至1.25下表现出色。
注意:在推理过程中,有些计算过程是共享的,例如自注意力 (self-attention) 机制,它适用于所有 token。这就解释了为什么Mixtrial 8×7B不是56B,而是47B。同理,如果采用 Top-2 门控,模型会使用 14B 的参数。但是,由于自注意力操作 (专家间共享) 的存在,实际上模型运行时使用的参数数量是 12B。
四、Switch Transformers
2022年,Google提出Switch Transformers,对MoE大模型的复杂性、通信成本以及训练微调过程的不稳定性进行了优化。Switch Transformers是一个1.6万亿参数的MoE,拥有2048个专家,可以使用transformers库运行。
Switch Transformers 简化了 MoE 路由算法,设计了直观的改进模型,降低了通信和计算成本。Switch Transformers 的训练方法减轻了不稳定性,并且首次展示了用较低精度(bfloat16)格式训练大型稀疏模型的可能性。
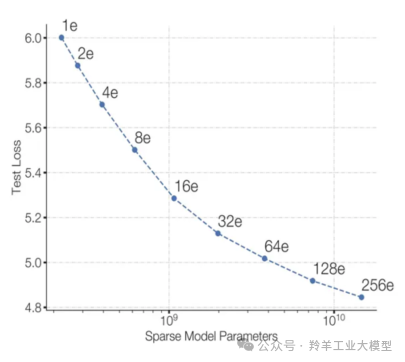
上图模型参数随着专家数量的增加而增加,训练时,保持了相同的计算成本,loss逐渐降低。这表明模型在保持计算效率的同时,能够利用更多的参数来提高性能。
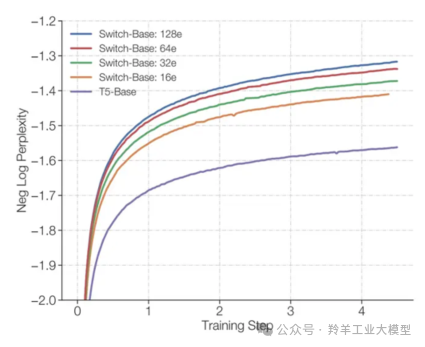
上图比较了使用相同计算资源下,Switch Transformer 和 T5-Base 的 PPL。可以看到 Switch Transformer 模型在保持相同计算资源的情况下,相对于 T5-Base 有显著的提升,而且专家数越多(模型参数越多、模型更稀疏),效果越好。
4.1 Switch Transformer主要优化
Swith Transformer 在论文中提到其设计指导原则是——尽可能地把 Transformer 模型的参数量做大!(即加专家数量!堆叠专家模型!)
和其他 MoE 模型的一个显著不同就是,Switch Transformer 的门控网络每次只路由到 1 个 expert,也就是每次只选取 Top1 的专家,而其他的模型都是至少 2 个。这样从 MoE layer 的计算效率上讲是最高的,同时也降低了 MoE 中的通信成本
4.2 改进预训练和Fine-Tuning技术
1. 改进预训练——精度选择
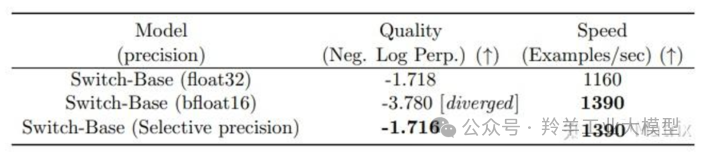
作者尝试了混合精度改进预训练,较低的精度可以减少处理器间的通信成本、计算成本以及存储 tensor 的内存。然而,在最初的实验中,当专家和门控网络都使用 bfloat16 精度训练时,出现了不稳定的训练现象。这种不稳定性主要是由门控计算引起的,因为门控涉及指数函数等操作,这些操作对精度要求较高。因此,为了保持计算的稳定性和精确性,保持更高的精度是重要的。为了减轻不稳定性,门控过程使用了全精度。
下表显示了混合精度训练的效果,将路由器输入转换为 float32,同时保持其他部分的精度为 bfloat16。这种策略允许模型在几乎与 bfloat16 精度相同的训练速度下,实现与 float32 训练相当的稳定性。
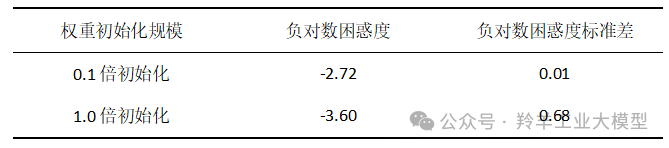
2. 改进预训练——更小的参数初始化
在深度学习中,适当的权重初始化对于模型的成功训练至关重要。作者观察到,在 Switch Transformer 模型中,这一点尤其明显。
为了提高模型的稳定性,作者建议减少默认的 Transformer 初始化规模。在 Transformer 模型中,权重矩阵通常是从一个正态分布开始。作者建议将这个初始化正态分布标准差的超参数 s 从默认值1.0 减少 10 倍到 s = 0.1,模型效果和稳定性得到了提升。
3. 改进微调——Fine-Tuning 过程正则化
为了解决 Fine-Tuning 过程中的过拟合问题,作者提出了增加 dropout的策略,特别是在专家层(expert layers)中,称之为“expert dropout”,即在 Fine-Tuning 时只在专家层增加 dropout 率。
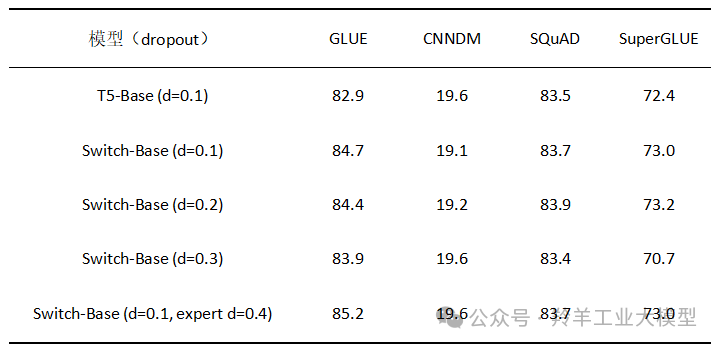
通过这种 expert dropout 策略,有效地减少了过拟合的风险,同时保持了模型在下游任务上的性能。这种正则化方法对于处理具有大量参数的稀疏模型特别有用,因为它可以帮助模型更好地泛化到未见过的数据。
五、ST-MOE——用 Router z-loss 稳定模型训练
在论文 ST-MOE: Designing Stable and Transferable Sparse Expert Models 中,作者提出了一种新的辅助损失函数,称为 Router z-loss,用于提高稀疏模型的训练稳定性,同时保持或稍微提高模型质量。这个损失函数是针对稀疏专家模型中的路由器(router)部分设计的,路由器负责将输入的 token 路由到最合适的专家(expert)层。这个损失函数的目标是鼓励路由器产生较小的logits 值,因为较大的 logits 值在 softmax 激活函数中会导致较大的梯度,这可能会引起训练不稳定。
Router z-loss 的定义如下:
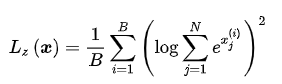
其中, B 是 batch 中的 token 数量, N 是专家的数量, x是门控的 logits值。这个损失函数通过惩罚较大的 logits 值来工作,因为这些值在 softmax 函数中会导致较大的梯度。通过这种方式,Router z-loss 有助于减少训练过程中的不稳定性。
-
稳定梯度更新:在训练深度神经网络时,梯度的更新可能会因为logits值过大而导致不稳定,造成梯度消失或是爆炸(激活函数的使用问题,涉及指数计算导致梯度消失)。适当减小logits的幅度可以使梯度更新更加平稳,从而提高训练的稳定性。
-
提高泛化能力:过大的logits值可能会导致模型对训练集中的某些特征过度敏感,通过对logits进行适当的惩罚,可以使模型更加谨慎地做出预测,避免对训练数据过拟合。
此外,ST-MOE 的作者还提到了两个MoE模型的现象:
-
专家如何学习?
encoder层的专家倾向于专注于特定类型的 token 或浅层概念。例如,某些专家可能专门处理标点符号,而其他专家则专注于专有名词等。decoder 中的专家通常具有较低的专业化程度。此外,研究者们还对这一模型进行了多语言训练,发现模型并不会按照人们期望的结构进行训练,尽管人们可能会预期每个专家处理一种特定语言,但实际上并非如此。由于 token 路由和负载均衡的机制,没有任何专家被特定配置以专门处理某一特定语言。
-
专家的数量对模型有何影响?
增加更多专家可以提升效率,但这些优势随着专家数量的增加而递减 (尤其是当专家数量达到 256 或 512 之后更为明显),比较符合常见的边际效用递减现象。并且,这种特性在小规模模型下也同样适用,即便是每层仅包含 2、4 或 8 个专家,也会存在这种情况。所以在设计MoEt模型时要考虑这个算力和模型质量的均衡,专家数量不是越多越好。
六、微调MoE模型
稠密模型和稀疏模型在过拟合的动态表现上存在显著差异。稀疏模型更易于出现过拟合现象,因此在处理这些模型时,尝试更强的内部正则化措施是有益的,比如使用更高比例的 dropout。例如,我们可以为稠密层设定一个较低的 dropout 率,而为稀疏层设置一个更高的 dropout 率,以此来优化模型性能。
另一种可行的 Fine-Tuning 策略是尝试冻结所有非专家层的权重。然而实验发现这会导致性能大幅下降,我们可以尝试相反的方法:仅冻结 MoE 层的参数。实验结果显示,这种方法几乎与更新所有参数的效果相当,同时可以加速 Fine-Tuning 过程,并降低显存需求。
在Fine-Tuning时还需要考虑的一个问题是,它们有需要特殊设置的超参数,例如,稀疏模型往往更适合使用较小的batch size和较高的学习率,这样可以获得更好的训练效果。
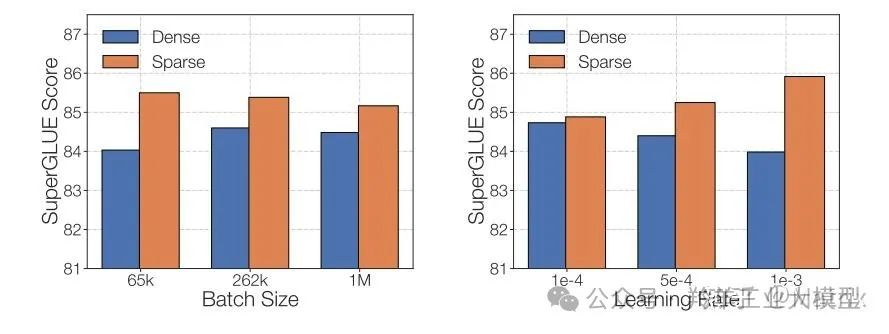
论文 MoEs Meets Instruction Tuning(2023 年 7 月)还做了以下几个实验:
-
非MoE模型微调
-
MoE模型微调
-
非MoE模型指令微调
-
MoE模型指令微调
结论:MoE模型指令微调 > 非MoE模型指令微调 > 非MoE模型微调 > MoE模型微调,并且子任务类型越多,MoE模型指令微调的效果越好
七、MoE 模型后续研究方向
MoE模型现在的几个值得探索的方向:
1、将 MoE蒸馏成稠密模型。Switch Transformers 的作者做了一些初步的蒸馏实验。通过将 MoE 蒸馏成一个稠密模型,能够保留 30-40% 的稀疏性增益。
2、探索专家聚合技术。该技术对专家的权重进行了合并,从而减少了参数量。
3、对MoE执行极致量化。QMoE(2023年10月)通过将MoE量化至每参数不足 1 比特,从而将1.6T的Switch Transformer模型的内存使用量从3.2TB压缩至仅需160GB。
八、开源 MoE 模型
-
国内的MoE大模型:DeepSeek团队开源的DeepSeekMoE,模型、代码、论文均已同步发布。
-
-
模型下载:https://huggingface.co/deepseek-ai
-
微调代码:https://github.com/deepseek-ai/DeepSeek-MoE
-
技术报告:https://github.com/deepseek-ai/DeepSeek-MoE/blob/main/DeepSeekMoE.pdf
-
-
此外还有一些国外的开源 MoE 模型,开源了训练代码。
-
Megablocks:https://github.com/stanford-futuredata/megablocks
-
Fairseq:https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm(dita)
-
OpenMoE:https://github.com/XueFuzhao/OpenMoE
-
下面是开源了模型,但是没有开源代码:
-
Switch Transformers:基于T5的MoE,专家数量共2048,最大模型有1.6万亿个参数。
-
NLLB MoE (Meta):NLLB 翻译模型的一个 MoE 变体。
-
OpenMoE:社区对基于 Llama 的模型的 MoE 尝试。
-
Mixtral 8x7B:一个性能超越了 Llama 2 70B 的高质量 MoE,并且具有更快的推理速度。此外,还发布了一个指令微调的版本。
















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











