






一步学习,一步回顾
Xiaolong Huang1, Qiankun Li2, 3, Xueran Li4, 5, Xuesong Gao1Corresponding authors (qklee@mail.ustc.edu.cn)
摘要
随着预训练视觉模型的兴起,视觉微调已引起广泛关注。 目前流行的方法,即完全微调,存在知识遗忘问题,因为它只关注拟合下游训练集。 在本文中,我们提出了一种新的基于权重回滚的微调方法,称为 OLOR(一步学习,一步回顾)。 OLOR 将微调与优化器相结合,在每一步的权重更新项中加入权重回滚项。 这确保了上游和下游模型的权重范围一致,有效地缓解了知识遗忘,并增强了微调性能。 此外,还提出了逐层惩罚,以使用惩罚衰减和多样化的衰减率来调整层的权重回滚水平,以适应不同的下游任务。 通过对图像分类、目标检测、语义分割和实例分割等各种任务进行广泛的实验,我们证明了我们提出的 OLOR 的通用性和最先进的性能。 代码可在 https://github.com/rainbow-xiao/OLOR-AAAI-2024 找到。
简介
随着深度学习技术的快速发展,已经建立了大量的大规模图像数据集 (Schuhmann 等人 2022; Russakovsky 等人 2015; Schuhmann 等人 2021),从而产生了许多很有希望的预训练视觉模型 (Radford 等人 2021; He 等人 2022; Bao 等人 2021)。 这些预训练模型可以通过迁移学习和微调技术有效地解决相关但不同的视觉任务 (Wu, Sun 和 Ouyang 2023; Shen 等人 2021)。 基本的微调方法是线性探测和完全微调 (Zhang, Isola 和 Efros 2017)。 在线性探测中,预训练模型的主干被冻结,只有针对下游任务的头被训练。 然而,这种方法通常会限制预训练主干的性能。 另一方面,完全微调涉及直接训练整个网络,但这通常会导致知识遗忘 (De Lange 等人 2021)。 基于重放机制的排练方法 (Rebuffi 等人 2017; Rolnick 等人 2019; Liu 等人 2020; Merlin 等人 2022) 涉及在学习新任务的同时,对存储的上游样本子集进行重新训练。 然而,这种方法效率很低。 EWC (Kirkpatrick 等人 2017) 提出了一种基于正则化的微调方法,该方法使用 Fisher 信息矩阵来确定权重参数的重要性。 这有助于调整上游和下游任务之间的参数,减少遗忘。 L2-SP (Xuhong、Grandvalet 和 Davoine 2018) 使用 L2 惩罚来限制参数的更新,解决微调过程中的知识遗忘问题。 然而,它与自适应优化器 (Loshchilov 和 Hutter 2017; Guan 2023) 不兼容,可能会产生错误的正则化方向。 参数隔离方法 (Jia 等人 2022; Sohn 等人 2023) 为不同的网络模型和下游任务创建新的分支或模块。 然而,它引入了额外的新的训练参数,需要一定的训练技能,并且比排练方法的泛化性更低。 在本文中,我们提出了一种结合优化器解决知识遗忘的新型微调方法,称为 OLOR(一步学习,一步回顾)。 具体来说,OLOR 在微调阶段将权重回滚项引入权重更新项,允许模型在学习下游任务的同时逐渐接近预训练权重。 这一过程避免了延迟缺陷,使上游和下游模型的权重更加相似。 此外,设计了一种逐层惩罚,使用惩罚衰减和多样化的衰减率来调整各层的权重回滚水平。 惩罚衰减将特征金字塔与迁移学习结合起来,对与浅层特征(如颜色和纹理)相关的浅层赋予更显著的权重回滚,对与深层特征(如语义信息)相关的深层赋予更小的权重回滚。 为了提高适用性,根据上游和下游任务之间的差异调整了不同的衰减率。 具有分层惩罚的 OLOR 使模型的每一层都能根据自身需求进行更新,从而更好地提取泛化特征。 最后,OLOR 被整合到优化器中,从而引入微不足道的额外计算开销。 它也与流行的优化器(例如 Adam (Loshchilov and Hutter 2017; Guan 2023) 和 SGD (Keskar and Socher 2017))配合良好,在各种条件下满足特定需求。 我们的 OLOR 微调方法在十个流行的视觉任务数据集上取得了最先进的性能,涵盖了通用分类、细粒度分类、长尾分类、跨域分类、目标检测、语义分割和实例分割。 验证实验和消融分析证明了 OLOR 在解决知识遗忘问题方面的性能以及参数的合理性。 主要贡献可以概括如下。
- •
我们提出了一种新的微调方法 OLOR,它与优化器协同工作以解决知识遗忘问题,从而提高微调性能。
- •
所设计的权重回滚通过将当前梯度整合到惩罚项中来避免延迟缺陷,从而纠正惩罚目标并平滑回顾过程。
- •
提出了分层惩罚,以采用惩罚衰减和不同的衰减率来调整各层的权重回滚级别,以适应不同的下游任务。
- •
该方法在广泛的下游任务中取得了最先进的性能,包括不同类型的图像分类、不同的预训练模型以及图像检测和分割。
相关工作
预训练资源
随着计算机视觉的快速发展,出现了大量的大规模数据集 (Russakovsky et al. 2015; Schuhmann et al. 2021, 2022) 和预训练模型。 这些上游预训练模型拥有丰富的特征,并具有很强的可迁移性,可以应用于其他特定下游任务。 ImageNet-21K (Russakovsky et al. 2015) 是最受欢迎的大规模数据集,拥有超过 1400 万张图像,大多数网络都在其上进行预训练。 最近,随着 LAION-2B (Schuhmann 等人,2022) 的发布,出现了一项突破性的发展。 该数据集现在是最大的数据集,包含超过 20 亿个图像-文本对。 然后,许多预训练模型被提出,例如 OpenClip (Radford 等人,2021)、BEiT (Peng 等人,2022)、MAE (He 等人,2022) 和 EVA (Fang 等人,2023)。 值得注意的是,这些模型中大多数的骨干都是建立在 ViT (Dosovitskiy 等人,2020) 和 ConvNeXt (Liu 等人,2022) 的基础上的。
微调方法
微调过程通常会遇到一个被称为知识遗忘的问题 (Toneva 等人,2018)。 它指的是模型在微调过程中丢失预训练学习表示 (Mosbach、Andriushchenko 和 Klakow,2020)。 这会导致上游和下游任务的准确率下降,因为模型无法有效地利用其潜在的知识 (De Lange 等人,2021;Vander Eeckt 和 Van Hamme,2023)。 为了解决这个问题,目前有三种方法,即重播方法、正则化方法和参数隔离方法。 重播涉及定期在上游任务数据子集上进行训练,从而保留先前任务的知识并平衡旧信息和新信息 (Rebuffi 等人,2017;Rolnick 等人,2019;Liu 等人,2020;Merlin 等人,2022)。 然而,存储和管理上游任务数据在效率方面带来了挑战,尤其是在当今大型数据集时代 (Schuhmann 等人,2022;Li 等人,2023)。 基于正则化的方法采用诸如费舍尔信息矩阵 (Kirkpatrick 等人,2017)、权重衰减 (Kumar 等人,2022) 和 L2 惩罚 (Xuhong、Grandvalet 和 Davoine,2018) 等技术来限制微调过程中的参数更新。 然而,这些技术可能无法完全防止知识遗忘。 此外,自适应优化器 (Loshchilov 和 Hutter,2017;Guan,2023) 的存在有时会影响正则化的方向 (Xuhong、Grandvalet 和 Davoine,2018)。 参数隔离方法在下游微调过程中将特定分支或模块整合到预训练网络中,旨在通过这些新模块实现知识转移 (Jia 等人,2022;Sohn 等人,2023;Wang 等人,2023)。 然而,架构修改引入了新的训练参数和复杂的设计。 此外,训练技巧在新模块的有效性中起着至关重要的作用,通常需要多轮冻结和解冻。 为了实现一种通用的简洁的微调方法来解决知识遗忘问题,本文提出的 OLOR 微调方法结合了权重回滚和优化器来调整参数更新的范围。 这使得可以增强预训练模型表示,从而提高下游微调性能。
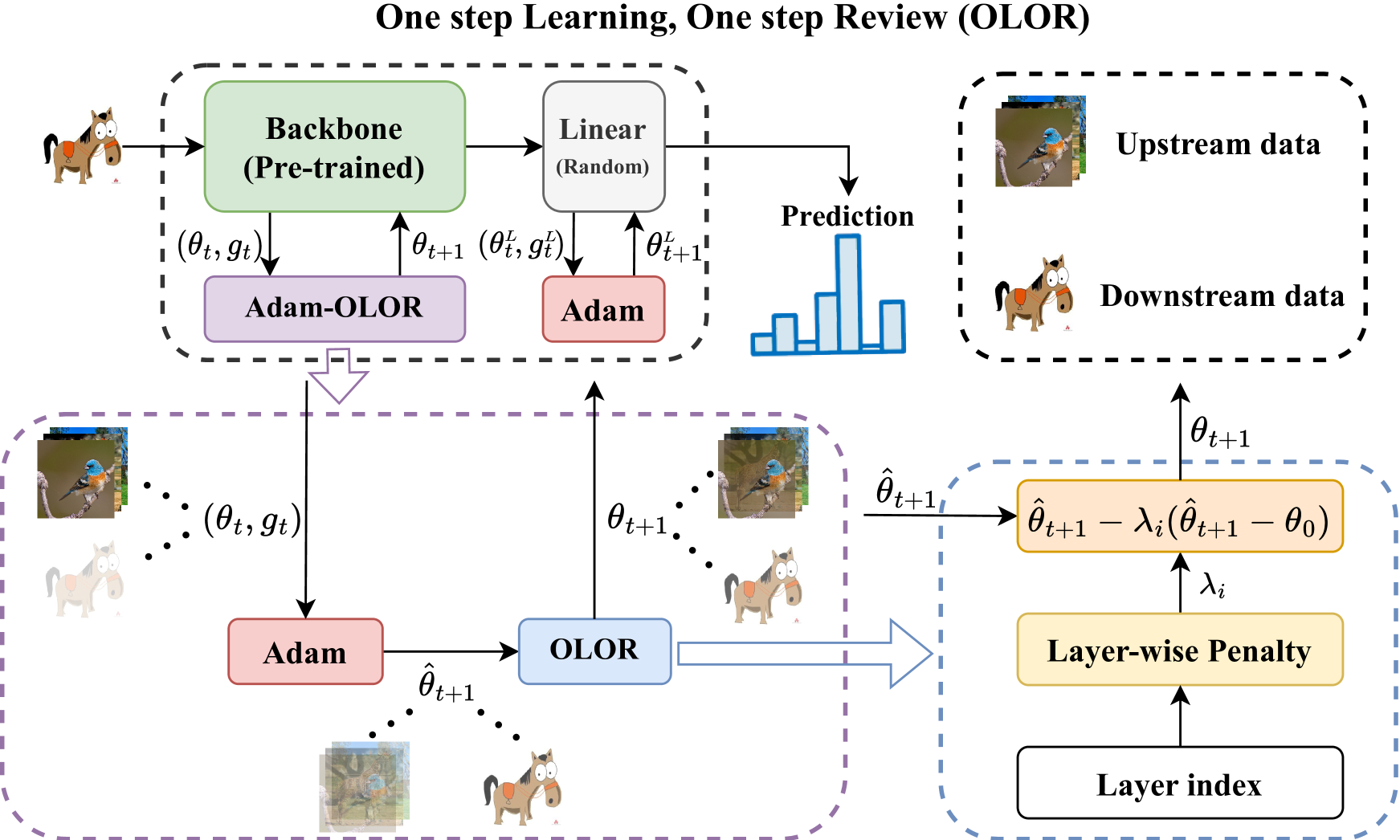
图 1: 使用 Adam 作为优化器的 OLOR 概述,其中 λi 表示 ith 层的惩罚因子,θt 和 θ^t+1 分别表示时间步 t 处的权重和下一个权重的估计(预权重)。 图像的透明度表示知识遗忘的程度。
方法
我们提出了一种一步学习、一步回顾 (OLOR) 方法来减少微调时的知识遗忘。 OLOR 可以无缝应用于各种下游任务,以及不同的优化器和模型。 整个框架如图 1 所示,算法 1 和算法 2 中描述了结合 SGD 和 Adam 的详细流水线。 本节介绍了先前正则化方法的延迟缺陷,然后详细解释了 OLOR 方法,该方法包括权重回滚和逐层惩罚。
算法 1 带动量的 SGD 的 OLOR
1: 输入: η∈IR: 初始学习率,β∈[0,1): 动量因子,θ0: 预训练权重,ι1,ι2∈[0,1],ι1≥ι2: 权重回滚的最高和最低级别,γ∈IR: 权重回滚幂
2: 初始化: t←0: 时间步长,m0←0: 初始动量向量,d0←0: 初始差异值,λi←f(λ,i,n,ι1,ι2)/η: 通过 λi=f(λ,i,n,ι1,ι2)=ι2+(1−in)γ(ι1−ι2) 计算惩罚因子 λi,然后通过除以 η 对其进行缩放以消除比例问题。
3: 重复
4: t←t+1
5: ηt←LRScheduler(ηt−1)(在时间步 ηt 计算 t)
6: gt←∇θft(θt−1)(在时间步 t 获取批梯度)
7: mt←βmt−1+(1−β)gt(计算动量)
8: θt←θt−1−ηtλidt−1−(1−ηtλi)ηtmt(更新权重)
9: dt←(1−ηtλi)(dt−1−ηtmt)(更新差异)
10: 直到 满足停止条件
11: 返回 参数 θt
算法 2 用于 Adam 的 OLOR
1: 输入: η∈IR: 初始学习率,β1,β2∈[0,1): 动量估计的指数衰减率,ϵ: 偏差,θ0: 预训练权重,ι1,ι2∈[0,1],ι1≥ι2: 权重回滚的最大值和最小值,γ∈IR: 权重回滚的幂次
2: 初始化: t←0: 时间步长,m0←0: 初始一阶矩向量,v0←0: 初始二阶矩向量,d0←0: 初始差异值,λi←f(λ,i,n,ι1,ι2)/η: 通过 λi 计算惩罚因子 λi=f(λ,i,n,ι1,ι2)=ι2+(1−in)γ(ι1−ι2),然后通过除以 η 来缩放它以消除尺度问题。
3: 重复
4: t←t+1
5: ηt←LR_调度器(ηt−1)(在时间步 t 处计算 ηt)
6: gt←∇ft(θt−1)(在时间步 t 处获取批次梯度)
7: mt←β1mt−1+(1−β1)gt(更新第一矩向量)
8: vt←β2vt−1+(1−β2)gt2(更新第二矩向量)
9: m^t←mt/(1−β1t)
10: v^t←vt/(1−β2t)
11: θt←θt−1−ηtλidt−1−(1−ηtλi)ηtm^t(v^t+ϵ)(更新权重)
12: dt←(1−ηtλi)(dt−1−ηtm^t(v^t+ϵ))(更新差异)
13: 直到 停止标准满足
14: 返回 优化后的参数 𝜽t
之前的正则化机制存在延迟缺陷
OLOR 的实现灵感来自 L2 正则化和权重衰减,它们是用于正则化模型参数的常用方法。 然而,我们的发现表明,它们的有效性与最初的预期不符。 在经典 SGD 优化器的情况下,L2 正则化可以被认为等同于权重衰减 (Loshchilov 和 Hutter 2017),它可以定义如下:
| θt=(1−λ)θt−1−ηtgt, | (1) |
其中 θt 表示迭代 t 时的模型权重,而 θt−1 是来自先前迭代的相应权重。 λ 是正则化因子(权重衰减强度)。 ηt 是迭代 t 时的学习率。 gt 是迭代 t 时从损失函数计算出的批次梯度。 权重衰减通过将先前迭代中获得的权重推向 0 来惩罚它们。 然而,在实践中,limλ→1θt=−ηtgt,权重往往会被推向当前梯度的负值而不是 0。 此行为可能与最初的预期不同。 此外,应用权重衰减实际上可以使当前权重比不应用它时更大。 这可以在以下不等式中看到:
| (θt−1−ηtgt−λθt−1)2>(θt−1−ηtgt)2, | (2) |
简化为:
| {ηgt<(1−λ2)θt−1,if θt−1<0,ηgt>(1−λ2)θt−1,if θt−1>0. |
如果 η,gt,λ 和 θt−1 处于上述条件,则使用权重衰减将使当前权重远离 0,这与它的目标相反。 同样,这种衰减效应问题也存在于其他正则化机制中,例如 L1 正则化、L2-SP 和类似方法。
权重回滚
提出的权重回滚是一种实时正则化方法,它紧密地跟随每个权重更新步骤。 其目标是将当前模型权重更接近预训练权重,以执行知识回顾。 具体而言,第一步是通过梯度计算预权重 θpre:
| θpre=θt−1−ηtgt, | (3) |
其中 θt−1 表示先前时间步的模型权重,ηt 是当前时间步的学习率,gt 表示梯度。 随后,计算 θpre 与预训练权重 θ0 之间的差异 Δd 为:
| Δd=θpre−θ0. | (4) |
最后,权重更新过程结合了 Δd,从而得到调整后的模型权重 θt:
| θt=θt−1−ηtgt−λΔd. | (5) |
| θt=(1−λ)(θt−1−ηtgt)+λθ0. | (6) |
该公式 6 确保 limλ→1θt=θ0 符合我们的预期并防止异常情况。 此外,由于梯度 gt 也受到惩罚,此过程可能有助于缓解梯度爆炸。 总之,权重回滚技术在每一步都适度地调节了 θt 和 θ0 之间的偏差,从而减轻了对当前任务的过度拟合以及对先前任务的知识遗忘。
层次惩罚
惩罚衰减。
对于深度学习神经网络,每一层可以被概念化为处理其输入的函数。 给定层索引 i,此过程可以描述如下:
| xi+1=fi(xi*), | (7) |
其中 fi 表示 ith 层。 令 xiu 表示上游任务中 fi 的输入,其分布为 qi(xiu),xid 表示下游任务中 fi 的输入,其分布为 pi(xid)。 由于 qi(xiu) 始终不同于 pi(xid),我们首先解冻所有层以确保 fi 有足够更新来更好地处理这种差距。 在图像特征提取的研究中,一种普遍的理解是浅层主要负责捕捉表层特征(Lin et al. 2017),例如颜色、纹理和形状。 相反,深层则专注于提取更深层的特征,例如语义信息。 这意味着浅层与数据的分布密切相关,而深层则更多地与特定任务的目标相一致。 迁移学习的基础假设是qi(xiu)与pi(xid)之间存在一定程度的相似性。 因此,浅层在预训练和微调阶段往往表现出相似性。 此外,与更深层的层相比,浅层需要更少的更新。 基于这些观察结果,我们提出了一种用于权重回滚的分层惩罚衰减机制。 这种方法随着层深度的增加而逐渐降低回滚级别。 这种策略鼓励浅层在后续任务中提取更通用的特征,同时保留模型的整体能力。 对于索引为i的任何层,惩罚因子λi使用以下公式计算:
| λi=ι2+(1−in)(ι1−ι2), | (8) |
其中n表示预训练模型中的总层数,ι1和ι2分别表示最大和最小回滚级别。
多样化衰减率。
在各种后续任务中,目标目标与上游任务的目标往往表现出不同程度的差异。 为了适应这种可变性,我们建议通过引入权重回滚值的幂指数γ来调整层间惩罚衰减的速率。 在数学上,这种调整可以表示为:
| 1−in⟶(1−in)γ. | (9) |
这种动态调整有助于缓解来自qi(xiu)和pi(xid)之间在不同层索引i上的相似性的固定速率衰减所带来的偏差。 因此,惩罚衰减变得更加适应和灵活,可以满足各种后续任务所规定的各种需求。
| Dataset | Images | Categories | Type |
|---|---|---|---|
| CIFAR-100 | 60,000 | 100 | General |
| SVHN | 600,000 | 10 | General |
| CUB-200 | 11,788 | 200 | Fine-grained |
| Stanford Cars | 16,185 | 196 | Fine-grained |
| Places-LT | 62,500 | 365 | Long-tailed |
| IP102 | 75,222 | 102 | Long-tailed |
| OfficeHome | 15,500 | 4 × 65 | Cross-domain |
| PACS | 9,991 | 4 × 7 | Cross-domain |
| COCO2017 | 163,957 | 80 | Detection |
| ADE20K | 27,574 | 3688 | Segmentation |
表 1: 微调数据集的详细信息。
| General (ID) | Fine-Grained (ID) | Long-Tailed (OOD) | Cross-Domain (OOD) | |||||
|---|---|---|---|---|---|---|---|---|
| Method | Cifar-100 | SVHN | CUB-200 | StanfordCars | Places-LT | IP102 | OfficeHome | PACS |
| ViT-B Backbone | ||||||||
| Linear | 72.50 | 58.79 | 75.01 | 38.03 | 31.95 | 64.93 | 79.96 | 71.88 |
| Full | 87.76 | 97.27 | 81.34 | 75.55 | 31.59 | 74.09 | 84.39 | 87.79 |
| L2-SP | 88.17 | 97.12 | 81.65 | 75.55 | 31.22 | 73.75 | 84.74 | 87.74 |
| VPT | 91.49 | 94.37 | 81.86 | 58.24 | 37.02 | 70.41 | 86.48 | 77.44 |
| OLOR-Adam (ours) | 92.89 | 97.35 | 84.84 | 82.02 | 38.07 | 75.34 | 89.05 | 94.38 |
| ConvNeXt-B Backbone | ||||||||
| Linear | 81.70 | 69.21 | 87.85 | 50.21 | 36.41 | 70.77 | 92.40 | 93.46 |
| Full | 92.72 | 96.97 | 88.59 | 88.67 | 38.61 | 75.01 | 91.78 | 95.51 |
| L2-SP | 92.84 | 97.01 | 88.82 | 88.83 | 38.52 | 75.20 | 90.61 | 95.90 |
| VPT | 88.71 | 81.58 | 87.88 | 51.58 | 36.32 | 71.22 | 92.31 | 93.75 |
| OLOR-SGD (ours) | 92.86 | 97.12 | 89.47 | 88.99 | 39.36 | 75.44 | 92.59 | 96.63 |
表 2: 比较不同类型分类数据集(通用、细粒度、长尾、跨域)上的微调结果。
实验
实验配置
预训练主干网络。
实验采用基于 CNN 的 ConvNeXt (Liu 等人,2022) 和基于 Transformer 的 Vision Transformers (ViT) (Dosovitskiy 等人,2020) 作为主干网络。 对于这两种类型的模型,都使用了来自 ImageNet-1K (MAE) (Deng 等人,2009)、ImageNet-21K (监督) (Russakovsky 等人,2015) 和 LAION-2B (CLIP) (Schuhmann 等人,2022) 数据集的预训练权重,其中来自 ImageNet-21K 的权重经过监督预训练,而其他权重则基于自监督预训练图。
下游任务。
我们在十个流行的视觉任务数据集上进行了实验,即 CIFAR-100 (Krizhevsky, Hinton 等人,2009)、SVHN (Netzer 等人,2011)、CUB-200 (Wah 等人,2011)、斯坦福汽车 (Krause 等人,2013)、Places-LT (Zhou 等人,2014)、IP102 (Patterson 等人,2014)、OfficeHome (Venkateswara 等人,2017) 和 PACS (Li 等人,2017),涵盖一般分类、细粒度分类、长尾分类、跨域分类、目标检测、语义分割和实例分割。 更多详细信息列在表 1 中。
基线。
为了确保全面比较,我们选择了最先进的和经典的方法作为我们的基线。 这些方法包括完全微调(Full)、线性探测(Linear)(Zhang, Isola 和 Efros, 2017)、L2-SP (Xuhong, Grandvalet 和 Davoine, 2018) 和 VPT (Jia 等人,2022)。 遵循先前工作 (Carion 等人,2020),基于 CNN 的主干网络通常与 SGD 优化器结合使用,而基于 Transformer 的主干网络则与 Adam 优化器配对。
实现细节。
输入图像大小设置为 224×224。 批次大小根据冻结策略而异。 具体来说,对于完全解冻、参数隔离和完全冻结的方法,分别选择 128、256 和 512。 关于学习率,对于 ConvNeXt 主干网络,我们使用 SGD 优化器,动量为 0.9。 学习率根据冻结策略的不同而有所不同。 详细来说,对于完全解冻、参数隔离和完全冻结的方法,分别为 1e-2、2e-2 和 4e-2。 对于 ViT 主干网络,我们使用 Adam 优化器,动量为 (0.9, 0.999)。 ViT 主干网络的学习率也根据冻结策略的不同而有所不同,即对于完全解冻、部分解冻和完全冻结,分别为 1e-4、2e-4 和 4e-4。 我们在跨域数据集上训练 30 个 epoch,而在其他数据集上,我们训练 50 个 epoch。 实验在两台拥有 24GB 内存的 A5000 GPU 和 Ubuntu 20.04 操作系统上进行。 Python 3.8.3 作为编程语言,而 PyTorch 2.0.0 框架被使用。 此外,源代码在 GitHub 上公开可用。
主要结果
分类任务的结果。
为了验证 OLOR 在各种类型的数据集上的广泛适应性,我们与其他最先进的微调方法进行了全面比较。 我们在 10 个流行的分类数据集上评估了这些方法,每个数据集都展示了一系列数据分布和特征。 此外,实验中的主干包括 ViT-B 和 ConvNeXt-B,分别对应于 Adam 和 SGD 优化器。 实验结果列在表 2 中。 可以观察到,我们的 OLOR 在所有数据集上都取得了新的最先进水平。 值得注意的是,在分布内 (ID) 数据集中,OLOR-Adam 在准确率方面以 6.47% 的可观优势超越了之前领先的 L2-SP 方法。 此外,在面对两个更具挑战性的分布外 (OOD) 数据集时,OLOR-Adam 分别实现了 2.57% 和 7.38% 的准确率提升,优于最佳方法。 由于预训练的 ConvNeXt 模型比 ViT 结构更稳定,因此在微调方面,不同方法之间没有太大差异。 然而,我们的 OLOR-SGD 在所有数据集上始终如一地提高了微调精度。 这些结果证明了所提出的 OLOR 在各种任务中的鲁棒性和有效性。
检测和分割任务的结果。
由于检测和分割任务的复杂性,大多数现有的微调方法在适用性和验证方面都面临挑战。 然而,与优化器集成后,我们的 OLOR 方法可以轻松应用于这些任务。 表 3 显示了在 COCO2017 数据集上进行目标检测和实例分割的结果,而表 4 展示了在 ADE20K 数据集上进行语义分割的性能。 OLOR 在所有指标中始终优于基线约 1%,这证明了其在更复杂检测和分割任务中的多功能性和有效性。
| Method | Model | Dataset | Bboxm | Segmm |
|---|---|---|---|---|
| Full | Mask R-CNN | COCO2017 | 40.20 | 36.00 |
| OLOR | Mask R-CNN | COCO2017 | 41.10 | 36.90 |
表 3: 使用 ConvNeXt-B 作为主干的目标检测和实例分割结果。
| Method | Model | Dataset | IOUm |
|---|---|---|---|
| Full | UperNet | ADE20K | 43.65 |
| OLOR | UperNet | ADE20K | 44.62 |
表 4: 使用 ViT-B 作为主干的语义分割结果。
| Method | Supervised | OpenCLIP | MAE |
|---|---|---|---|
| Linear | 71.88 | 95.61 | 36.72 |
| Full | 87.79 | 47.17 | 84.18 |
| L2-SP | 87.74 | 45.56 | 85.79 |
| VPT | 76.76 | 97.46 | 50.54 |
| OLOR (ours) | 92.87 | 98.10 | 89.26 |
表 5: 在 PACS 数据集上使用不同预训练模型的结果。
使用不同预训练模型的结果。
考虑到使用不同的预训练模型时,不同的微调方法的性能可能会有所不同,我们进一步进行实验以探索和比较。 预训练的 ViT-B 模型权重来自 ImageNet-21K(监督)、LAION-2B(CLIP)和 ImageNet-1K(MAE)。 微调实验基于具有挑战性的 PACS 数据集。 如表 5 所示,我们的 OLOR 在所有预训练模型上始终如一地取得了最先进的结果。 具体来说,当分别使用监督、CLIP 和 MAE 时,OLOR 超过了其他领先方法 5.08%、0.64% 和 3.47%。 虽然其他方法难以同时适应所有预训练模型,但我们的 OLOR 在所有预训练模型中都展现出潜力。
主要结果摘要。
总之,以上实验表明,OLOR 应用于多个下游任务时,利用不同的预训练主干,实现了 SOTA。 这些结果证明了 OLOR 微调方法的泛化性和有效性。
分析与讨论
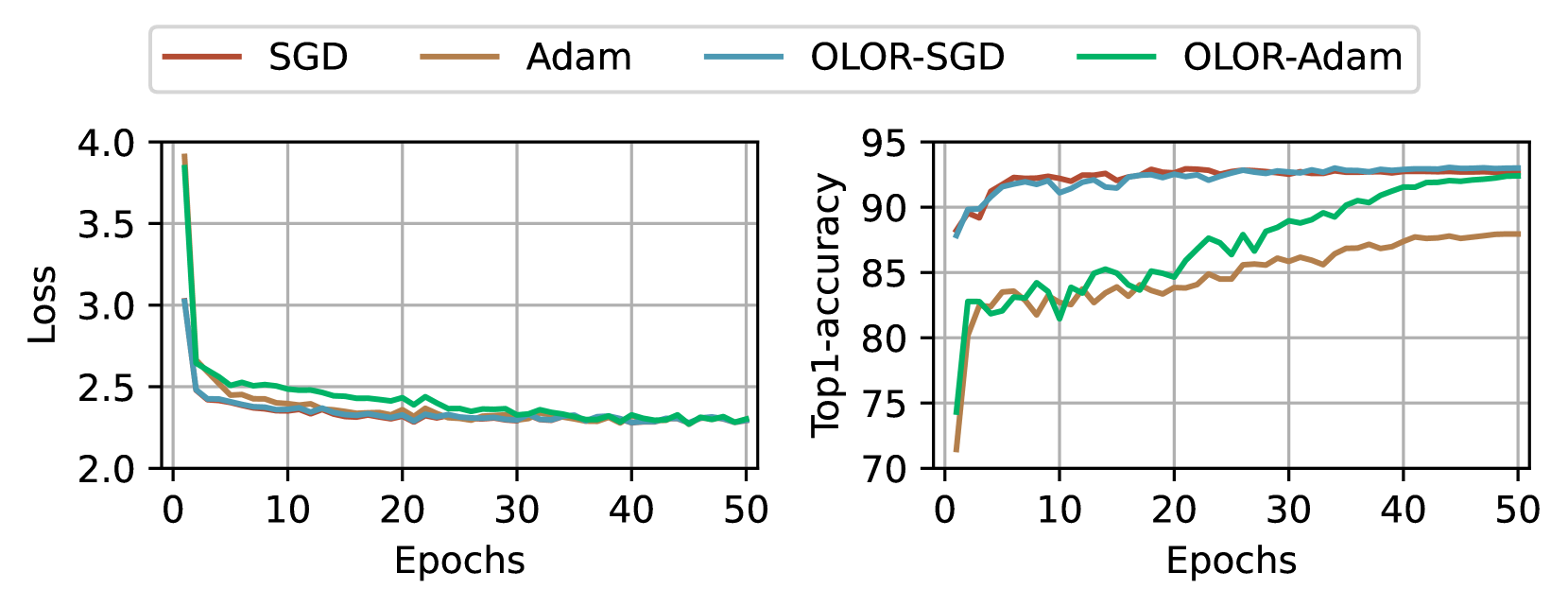
图 2: 使用 ViT-B 和 Adam 以及 ConvNext-B 和 SGD 在 CIfar-100 上训练损失和验证 top1 准确率。
兼容性分析。
如图 2 所示,在不同类型的模型和优化器中采用权重回滚通常会提高性能。 由于参数的限制,OLOR 最初会导致损失收敛速度较慢,但最终会与完整方法相媲美。 根据验证结果,OLOR 可能有助于减少知识遗忘,从而导致更优异的 top1 准确率,尤其是在与应用于视觉 Transformer 的 Adam 协作时。
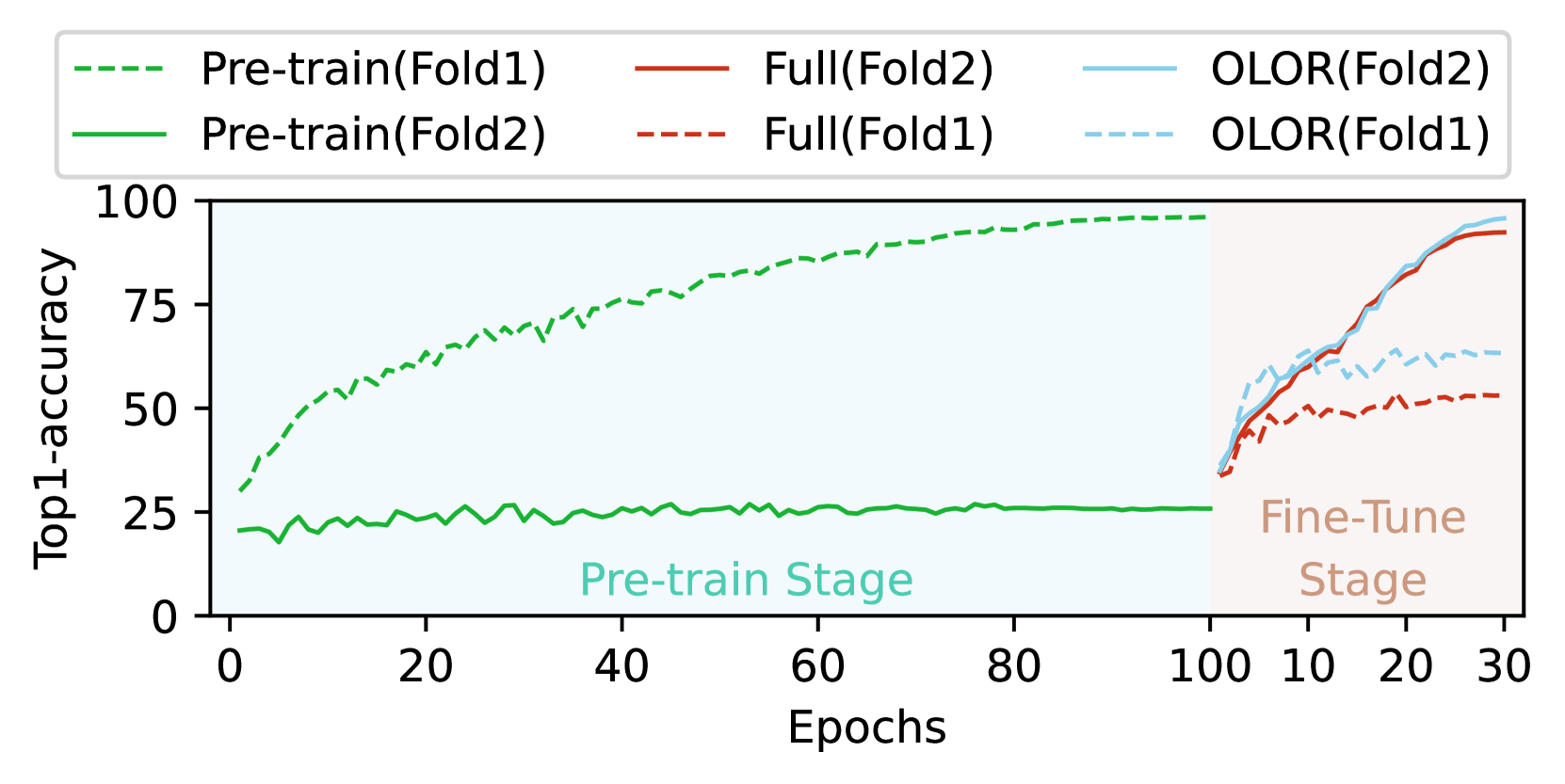
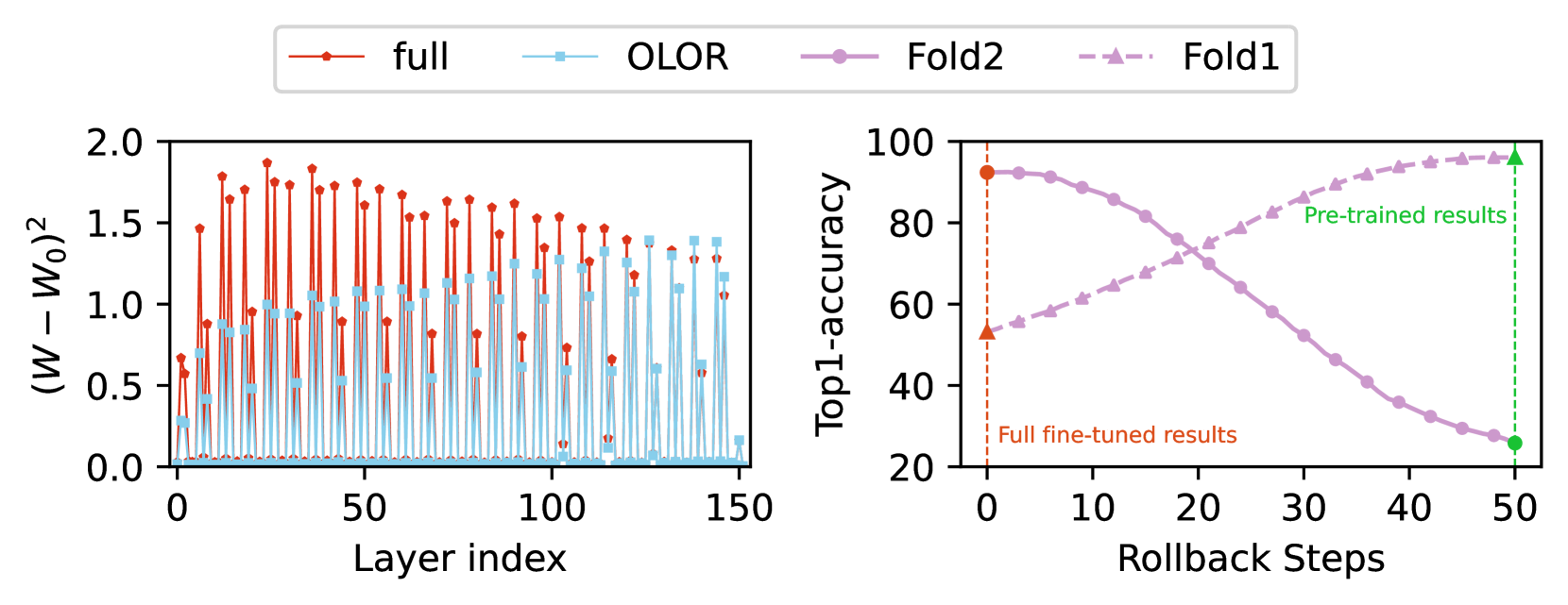
图 3: PACS 上的知识遗忘测试。 在预训练期间将折叠 1 作为训练集,将折叠 2 作为验证集,微调期间的分割与预训练相反。
知识遗忘测试。
为了评估潜在的知识遗忘,我们使用 ViT-B 和 Adam 对 PACS 数据集进行了一项研究。 首先,将数据集分成两个折叠,第一个折叠包含来自三个域的数据,分别是卡通、照片和素描,分别表示为 𝒟1,第二个折叠包含来自艺术绘画域的数据,表示为 𝒟2。 在训练阶段,我们首先使用 𝒟1 作为训练集,𝒟2 作为验证集,对模型进行 100 个 epochs 的预训练,然后使用 𝒟2 作为训练集,𝒟1 作为验证集,通过完整方法和 OLOR 方法对模型进行 30 个 epochs 的微调,记录使用不同方法微调后的权重 θ 与预训练后的权重 θ0 之间的差异。 此外,我们执行零样本回顾,将完整的微调权重回滚到预训练权重,共 50 步。 图 3 报告了结果,使用 OLOR 时权重差异通常要小得多,当将最大回滚级别 ι1 设置为 0.01,回滚能力 γ 设置为 1 时,OLOR 不仅在知识回顾方面表现良好,而且对当前学习也有益。 零样本回顾结果表明,权重回滚本身确实是一种有助于仅仅进行回顾的方法。
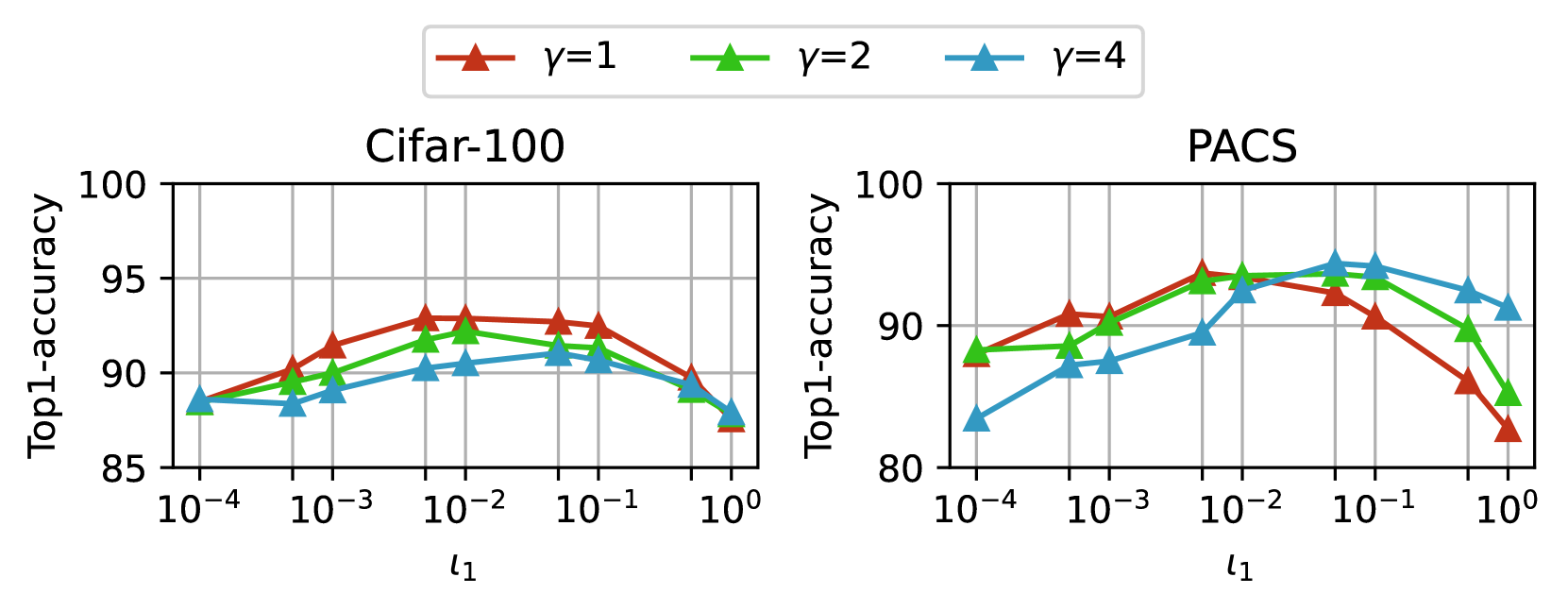
图 4: 在 Cifar-100(左)和 PACS(右)上进行超参数探索实验,两者都使用 ViT-B 和 Adam。
超参数探索。
我们在 Cifar-100(ID)和 PACS(OOD)上进行实验,以研究不同类型任务的适当超参数。 深层网络通常需要大量的更新才能有效地提取与下游任务相关的特征,因此我们将最小回滚级别 ι2 默认设置为 0,以简化超参数设置,对于最大回滚级别 ι1,我们从 {0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1} 中搜索,对于权重回滚幂 γ,我们从 {1, 2, 4} 中搜索。 图 4 显示了发现结果。 我们建议如果微调阶段的任务目标与预训练阶段相似,则应用小幂,如果下游任务的数据分布与上游任务相似,则应用大的最大回滚级别。
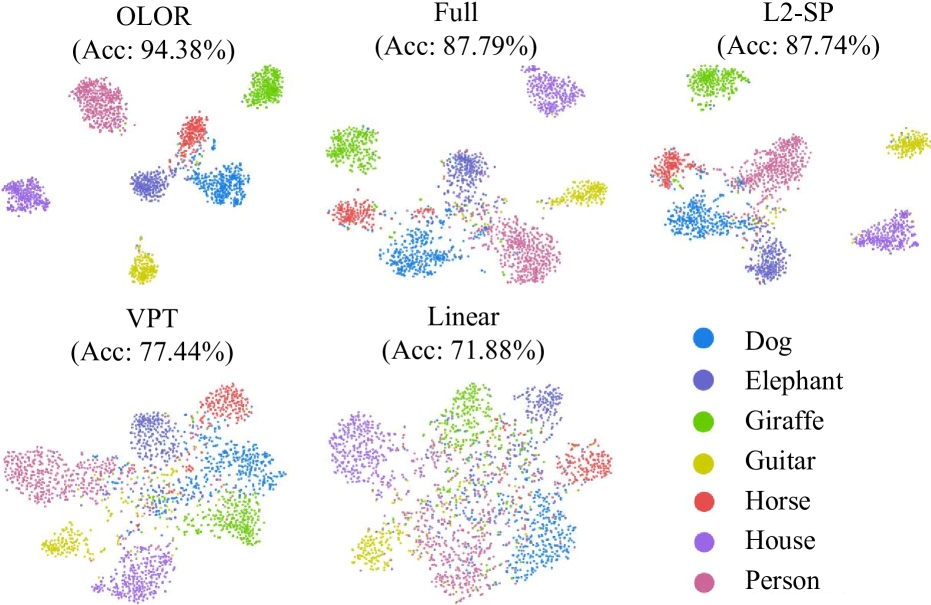
图 5: PACS 测试集上的特征可视化。 我们使用由主干提取的特征来执行 t-SNE 可视化,并另外报告 Top1 准确率。
特征可视化。
我们通过 t-SNE 对所有方法在 PACS 测试集上的特征分布进行了可视化,以评估提取特征的质量。 实验基于 ViT-B 和 Adam。 如图 5 所示,与以前的方法相比,OLOR 通常将不同类别的表示向量更好地分离,证明了其在表示方面的优越能力。
结论
在本文中,我们提出了一种名为 OLOR 的新型微调方法,以解决神经网络中知识遗忘的挑战。 OLOR 包含权重回滚和逐层惩罚。 OLOR 在每一步将权重回滚项合并到权重更新项中,并且可以在流行的优化器中实现。 此操作允许模型在学习下游任务的同时逐渐接近预训练权重,使上游和下游模型的权重更加相似。 此外,逐层惩罚采用惩罚衰减和多样化的衰减率来调整各层的权重回滚水平,以适应不同的下游任务。 我们的 OLOR 在广泛的下游任务上取得了最先进的性能。 验证实验和消融分析证明了所提出方法的有效性。
其他实现细节
在主要结果部分,在对各种下游任务进行实验时,OLOR 使用表 6 中列出的超参数配置。 对于涉及不同预训练模型的实验,OLOR 的超参数配置列在表 7 中。
| Datasets | ViT-Based | CNN-based | ||||
| ι1 | ι2 | γ | ι1 | ι2 | γ | |
| Cifar-100 | 5e-3 | 0 | 2 | 5e-3 | 0 | 2 |
| SVHN | 5e-3 | 0 | 2 | 1e-4 | 0 | 2 |
| CUB-200 | 5e-2 | 0 | 2 | 1e-2 | 0 | 2 |
| StanfordCars | 1e-2 | 0 | 4 | 1e-4 | 0 | 2 |
| Places-LT | 1e-1 | 0 | 4 | 1e-2 | 0 | 4 |
| IP102 | 1e-1 | 0 | 1 | 5e-3 | 0 | 1 |
| OfficeHome | 1e-2 | 0 | 1 | 1 | 0 | 1 |
| PACS | 1e-1 | 0 | 4 | 5e-2 | 0 | 4 |
| COCO2017 | - | - | - | 1e-2 | 0 | 2 |
| ADE20K | 1e-4 | 0 | 1 | - | - | - |
表 6: OLOR 针对不同下游任务的超参数配置。
| Pre-trained Method | ι1 | ι2 | γ |
|---|---|---|---|
| Supervised | 1e-2 | 0 | 2 |
| OpenCLIP | 1e-2 | 0 | 2 |
| MAE | 1e-2 | 0 | 2 |
表 7: OLOR 针对不同预训练模型的超参数配置。
致谢
本工作得到了中国科学技术大学学生创新创业基金 (编号:XY2023S007) 的资助。 我们衷心感谢匿名审稿人提出的宝贵建议,这些建议帮助我们改进了这篇论文。
参考文献
- Bao et al. (2021)Bao, H.; Dong, L.; Piao, S.; and Wei, F. 2021.Beit: Bert pre-training of image transformers.ArXiv Preprint arXiv:2106.08254.
- Carion et al. (2020)Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020.End-to-end object detection with transformers.In European Conference on Computer Vision, 213–229. Springer.
- De Lange et al. (2021)De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; and Tuytelaars, T. 2021.A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7): 3366–3385.
- Deng et al. (2009)Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009.ImageNet: A large-scale hierarchical image database.In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255. Ieee.
- Dosovitskiy et al. (2020)Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020.An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv Preprint arXiv:2010.11929.
- Fang et al. (2023)Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; and Cao, Y. 2023.Eva-02: A visual representation for neon genesis.ArXiv Preprint arXiv:2303.11331.
- Guan (2023)Guan, L. 2023.Weight Prediction Boosts the Convergence of AdamW.In Pacific-Asia Conference on Knowledge Discovery and Data Mining, 329–340. Springer.
- He et al. (2022)He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; and Girshick, R. 2022.Masked autoencoders are scalable vision learners.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16000–16009.
- Jia et al. (2022)Jia, M.; Tang, L.; Chen, B.-C.; Cardie, C.; Belongie, S.; Hariharan, B.; and Lim, S.-N. 2022.Visual prompt tuning.In European Conference on Computer Vision, 709–727. Springer.
- Keskar and Socher (2017)Keskar, N. S.; and Socher, R. 2017.Improving generalization performance by switching from adam to sgd.ArXiv Preprint arXiv:1712.07628.
- Kirkpatrick et al. (2017)Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A. A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. 2017.Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13): 3521–3526.
- Krause et al. (2013)Krause, J.; Stark, M.; Deng, J.; and Fei-Fei, L. 2013.3D object representations for fine-grained categorization.In Proceedings of the IEEE International Conference on Computer Vision Workshops, 554–561.
- Krizhevsky, Hinton et al. (2009)Krizhevsky, A.; Hinton, G.; et al. 2009.Learning multiple layers of features from tiny images.
- Kumar et al. (2022)Kumar, A.; Shen, R.; Bubeck, S.; and Gunasekar, S. 2022.How to fine-tune vision models with sgd.ArXiv Preprint arXiv:2211.09359.
- Li et al. (2017)Li, D.; Yang, Y.; Song, Y.-Z.; and Hospedales, T. M. 2017.Deeper, broader and artier domain generalization.In Proceedings of the IEEE International Conference on Computer Vision, 5542–5550.
- Li et al. (2023)Li, Y.; Zhang, K.; Liang, J.; Cao, J.; Liu, C.; Gong, R.; Zhang, Y.; Tang, H.; Liu, Y.; Demandolx, D.; et al. 2023.Lsdir: A large scale dataset for image restoration.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1775–1787.
- Lin et al. (2017)Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; and Belongie, S. 2017.Feature pyramid networks for object detection.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125.
- Liu et al. (2020)Liu, X.; Wu, C.; Menta, M.; Herranz, L.; Raducanu, B.; Bagdanov, A. D.; Jui, S.; and de Weijer, J. v. 2020.Generative feature replay for class-incremental learning.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 226–227.
- Liu et al. (2022)Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; and Xie, S. 2022.A convnet for the 2020s.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11976–11986.
- Loshchilov and Hutter (2017)Loshchilov, I.; and Hutter, F. 2017.Decoupled weight decay regularization.ArXiv Preprint arXiv:1711.05101.
- Merlin et al. (2022)Merlin, G.; Lomonaco, V.; Cossu, A.; Carta, A.; and Bacciu, D. 2022.Practical recommendations for replay-based continual learning methods.In International Conference on Image Analysis and Processing, 548–559. Springer.
- Mosbach, Andriushchenko, and Klakow (2020)Mosbach, M.; Andriushchenko, M.; and Klakow, D. 2020.On the stability of fine-tuning bert: Misconceptions, explanations, and strong baselines.ArXiv Preprint arXiv:2006.04884.
- Netzer et al. (2011)Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; and Ng, A. Y. 2011.Reading digits in natural images with unsupervised feature learning.
- Patterson et al. (2014)Patterson, G.; Xu, C.; Su, H.; and Hays, J. 2014.The sun attribute database: Beyond categories for deeper scene understanding.International Journal of Computer Vision, 108: 59–81.
- Peng et al. (2022)Peng, Z.; Dong, L.; Bao, H.; Ye, Q.; and Wei, F. 2022.Beit v2: Masked image modeling with vector-quantized visual tokenizers.ArXiv Preprint arXiv:2208.06366.
- Radford et al. (2021)Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. 2021.Learning transferable visual models from natural language supervision.In International Conference on Machine Learning, 8748–8763. PMLR.
- Rebuffi et al. (2017)Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; and Lampert, C. H. 2017.icarl: Incremental classifier and representation learning.In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2001–2010.
- Rolnick et al. (2019)Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; and Wayne, G. 2019.Experience replay for continual learning.Advances in Neural Information Processing Systems, 32.
- Russakovsky et al. (2015)Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. 2015.ImageNet large scale visual recognition challenge.International Journal of Computer Vision, 115: 211–252.
- Schuhmann et al. (2022)Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; et al. 2022.Laion-5B: An open large-scale dataset for training next generation image-text models.ArXiv Preprint arXiv:2210.08402.
- Schuhmann et al. (2021)Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; and Komatsuzaki, A. 2021.Laion-400M: Open dataset of clip-filtered 400 million image-text pairs.ArXiv Preprint arXiv:2111.02114.
- Shen et al. (2021)Shen, Z.; Liu, Z.; Qin, J.; Savvides, M.; and Cheng, K.-T. 2021.Partial is better than all: revisiting fine-tuning strategy for few-shot learning.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 9594–9602.
- Sohn et al. (2023)Sohn, K.; Chang, H.; Lezama, J.; Polania, L.; Zhang, H.; Hao, Y.; Essa, I.; and Jiang, L. 2023.Visual prompt tuning for generative transfer learning.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19840–19851.
- Toneva et al. (2018)Toneva, M.; Sordoni, A.; Combes, R. T. d.; Trischler, A.; Bengio, Y.; and Gordon, G. J. 2018.An empirical study of example forgetting during deep neural network learning.ArXiv Preprint ArXiv:1812.05159.
- Vander Eeckt and Van Hamme (2023)Vander Eeckt, S.; and Van Hamme, H. 2023.Using adapters to overcome catastrophic forgetting in end-to-end automatic speech recognition.In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. IEEE.
- Venkateswara et al. (2017)Venkateswara, H.; Eusebio, J.; Chakraborty, S.; and Panchanathan, S. 2017.Deep hashing network for unsupervised domain adaptation.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5018–5027.
- Wah et al. (2011)Wah, C.; Branson, S.; Welinder, P.; Perona, P.; and Belongie, S. 2011.The caltech-ucsd birds-200-2011 dataset.
- Wang et al. (2023)Wang, R.; Zheng, H.; Duan, X.; Liu, J.; Lu, Y.; Wang, T.; Xu, S.; and Zhang, B. 2023.Few-Shot Learning with Visual Distribution Calibration and Cross-Modal Distribution Alignment.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 23445–23454.
- Wu, Sun, and Ouyang (2023)Wu, W.; Sun, Z.; and Ouyang, W. 2023.Revisiting classifier: Transferring vision-language models for video recognition.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2847–2855.
- Xuhong, Grandvalet, and Davoine (2018)Xuhong, L.; Grandvalet, Y.; and Davoine, F. 2018.Explicit inductive bias for transfer learning with convolutional networks.In International Conference on Machine Learning, 2825–2834. PMLR.
- Zhang, Isola, and Efros (2017)Zhang, R.; Isola, P.; and Efros, A. A. 2017.Split-brain autoencoders: Unsupervised learning by cross-channel prediction.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1058–1067.
- Zhou et al. (2014)Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; and Oliva, A. 2014.Learning deep features for scene recognition using places database.Advances in Neural Information Processing Systems, 27.
















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











