






端到端开源“音频+面部”驱动头像视频扩散模型ACTalker
原创 弹贝斯的鱼 带你学AI 2025年04月26日 21:38 广东
对话头合成对虚拟头像和人机交互至关重要。然而,大多数现有方法通常仅接受来自单一主模态的控制,限制了它们的实际应用。数字人说话时眼神飘忽,像在背课文,面部动画像提线木偶,每个器官各动各的。因此,香港科技大学携手腾讯和清华提出了ACTalker,一个端到端的视频扩散框架,支持多信号控制和单信号控制,用于对话头视频的生成。(链接在文章底部)
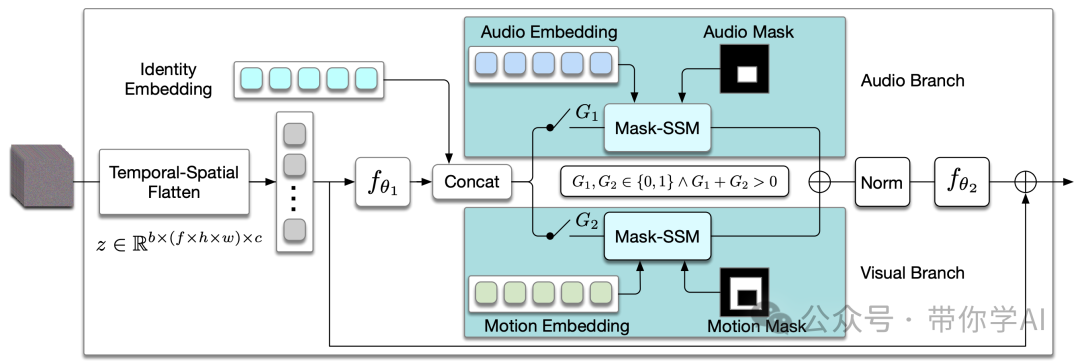
对于多重控制,设计了一个并行的mamba结构,包含多个分支,每个分支利用独立的驱动信号来控制特定的面部区域。一个门控机制应用于所有分支,提供对视频生成的灵活控制。为了确保受控视频在时间和空间上的自然协调,采用了mamba结构,使得驱动信号能够在每个分支中跨越两个维度操控特征令牌。此外,引入了一种mask-drop策略,使得每个驱动信号能够独立控制其对应的面部区域,从而避免控制冲突。
—
ACTalker框架示意图:ACTalker接受多个信号输入(即音频和视觉面部运动信号),驱动语音合成头像视频的生成。除了稳定视频扩散模型中的标准层(例如空间卷积、时间卷积、空间注意力和时间注意力)外,还引入了并行控制mamba层,以充分利用多信号控制的优势。音频和面部运动信号与其相应的掩码一起输入到并行控制mamba层中,掩码指示需要聚焦并进行操作的区域。
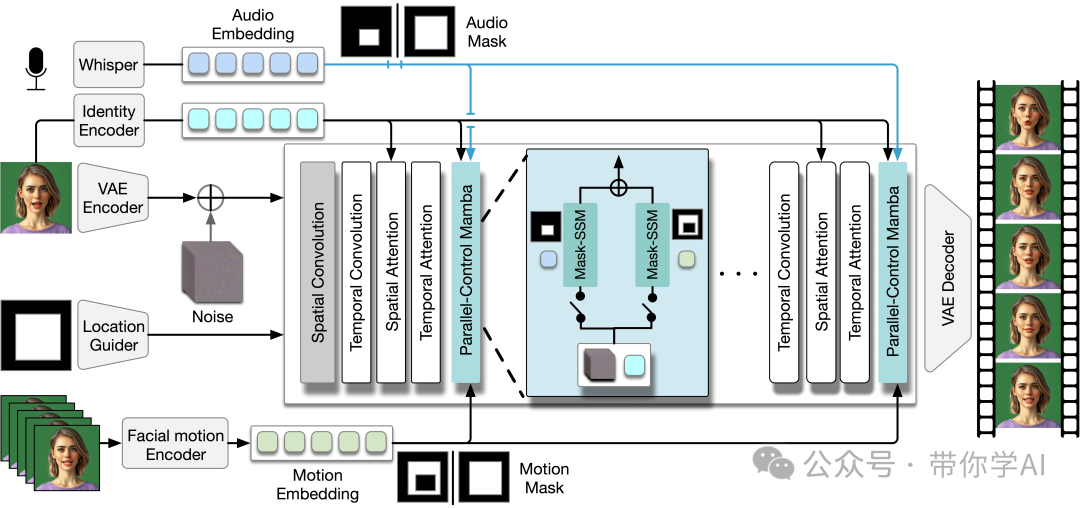
并行控制mamba层示意图:该层包含两个并行分支,一个用于音频控制,另一个用于表情控制。在每个分支中使用门控机制来控制训练过程中控制信号的访问。在推理时,可以手动修改门控状态,以启用单一信号控制或多信号控制。
,时长00:20
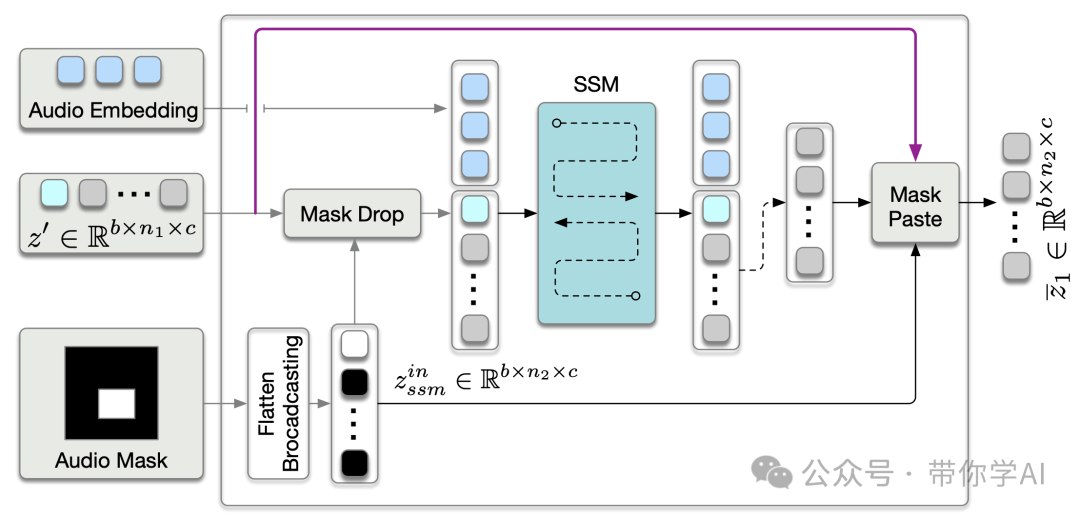
并行控制mamba层中音频分支的Mask-SSM示意图:视觉分支与此相同,只是将其替换为运动嵌入和运动掩码。
02 演示效果与对比
—
音频直接驱动人像说话:
,时长01:28
自然面部运动:
,时长00:12
局部微小面部运动:
,时长00:21
同时由音频和面部运动驱动:
,时长00:49
ACTalker能够准确生成嘴部动作并减少伪影,同时呈现自然的头部姿势和表情,区别于其他方法仅操控嘴形,其他区域保持静止。其mamba设计有效结合音频信号与面部特征令牌,确保自然表情和精确嘴型同步,且通过面部掩码作为音频掩码,音频驱动方式融合几乎所有面部特征。
,时长00:36
https://github.com/harlanhong/ACTalkerhttps://arxiv.org/pdf/2504.02542



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











