







 本文介绍了FunQA比赛,旨在推动计算机视觉模型理解反直觉视频中的幽默、创意和魔术元素。FunQA数据集包含三个子集和多任务,强调对深层信息和推理能力的考察,要求参赛者利用Otter模型和高质量数据进行模型训练,解决时序信息处理和复杂输出控制等问题。
本文介绍了FunQA比赛,旨在推动计算机视觉模型理解反直觉视频中的幽默、创意和魔术元素。FunQA数据集包含三个子集和多任务,强调对深层信息和推理能力的考察,要求参赛者利用Otter模型和高质量数据进行模型训练,解决时序信息处理和复杂输出控制等问题。
赛题介绍
赛题背景及意义
人们很容易就能在反直觉视频——幽默的,创意的,充满视觉效果的视频中获得愉悦感,这吸引力不仅来自于视频对人类的视觉感官刺激,更来自于人类与生俱来的理解和发现快乐的能力——能够理解并在出乎意料和反直觉的时刻找到乐趣。尽管如今的计算机视觉大模型取得了重大进展,它们仍然无法很好地理解这类视频。
可以参考下图的例子,一个男人在和朋友们一起吃饭并专注地玩手机。突然他的一个同伴挤了大量的番茄酱,而这些番茄酱并没有落到薯条上,而是溅到了该男子的脸上,他震惊的表情和满是番茄酱的脸引人发笑。这种识别幽默的能力对于人类是寻常不过的。但事实上,从整体上理解这一场景是复杂的:一个模型需要认识到人们聚集在一起享受美食,并辨别出幽默元素来自于原本应倒在薯条上的番茄酱意外溅到了平静地玩手机的男人的脸上,并且这个不幸的受害者的无辜表情表明他没有受到重大伤害。
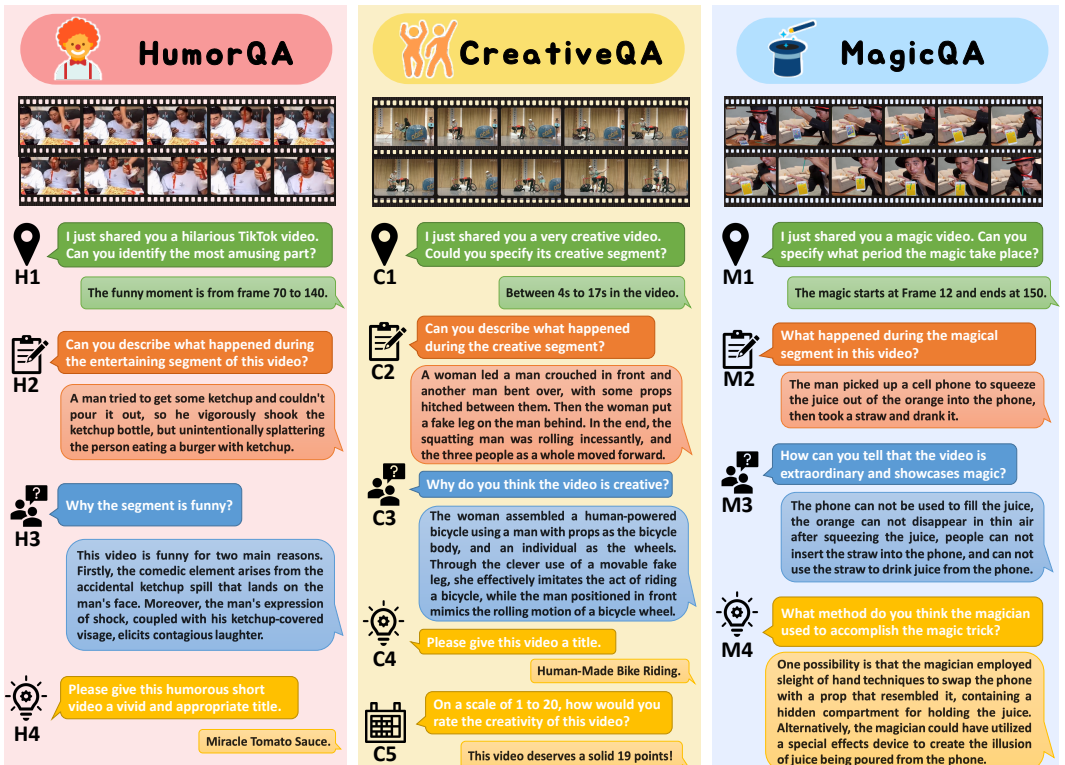
图1:FunQA概述。FunQA包括三个子集令人惊喜的视频:1. 幽默QA,2. 创意QA和 3. 魔术QA。每个子集都与三个常见任务相关:1. 反直觉的时间戳定位,2. 详细的视频描述,以及3. 围绕反直觉进行推理(参见H1-3、C1-3和M1-3)。此外,我们还为每种视频类型提供更高级别的定制任务,例如为幽默QA和创意QA(见H4、C4)分配一个合适而生动的标题等。
目前的视频问答(VideoQA)数据集仍集中于常见的、不太令人惊讶的视频和简单的任务(Multi-choice, Open-end),而仅仅回答出视频中简单的人事物(What, Who, How many, etc.)显然是不足以为理解视频提供帮助的,我们希望模型能对一个视频进行深层次的理解(Why)并给出详细的描述与解释(Free-text)。
为此我们制作并提供了FunQA [1]数据集和Otter模型 [2],并组织了这场比赛。我们希望参赛者能充分利用开源新颖框架Otter以及高质量数据集FunQA来提高模型理解深层信息和进行推理的能力。
[1] Xie, B., Zhang, S., Zhou, Z., Li, B., Zhang, Y., Hessel, J., Yang, J., Liu, Z., 2023. Funqa: Towards surprising video comprehension. arXiv preprint arXiv:2306.14899.
[2] Li, B., Zhang, Y., Chen, L., Wang, J., Yang, J., Liu, Z., 2023. Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726.
在这些视频上,有以下几个难点有待参赛者解决。
1.FunQA数据集的困难任务
- 时间戳定位任务是非常基本且重要的任务,需要模型保证对时序信息的正确理解与分析。但是目前VLM却并没有很好的时间戳定位能力。
- 描述性任务需要更多的细节,如何在保证准确度的同时增加细节是个困难的问题。
- 解释性问题对模型理解能力有很大的挑战,如何让模型学习并利用常识分析视频内容并给出反直觉现象的解释是非常困难的。
- 标题问题需要模型高度概况视频的内容。
综上所述,要想回答好描述、解释和标题问题,模型首先需要具有对有趣内容定位的能力。
2.答案输出的高复杂度
Free-text类型的答案输出是不易控制的,参赛者要控制输出的长度,平衡详细与臃肿的关系,减少错误信息与未知信息的输出
3.算法与模型的高复杂度
目前大部分模型的输入方案是对视频进行抽帧,这也产生了以下问题:
- 如何在抽帧之后保证时序信息不丢失,并完成时间戳定位任务。
- 如何制定抽帧方案,不同帧包含的信息的复杂度和重要程度显然需要被考虑。
- 如何在有限的训练资源下输入更多帧数,或在输入相同帧数时获得更多信息。
赛题描述
本次赛题要求参赛者根据给定的视频和问题给出合适的答案。我们希望对于不同类型的问题,参赛者的模型能够给出有不同侧重点的答案,我们也希望参赛者充分利用Otter模型和FunQA数据集,提高模型提取信息和进行深层推理的能力。
算法输入输出需求:
输入:一段视频和一个问题
输出:自然语言答案
目标:准确地理解,描述和解释视频中的反直觉内容,输出详细,合理,符合人类常识的答案。
模型说明
Otter是最近新颖且流行的开源视觉大模型框架,是一种具有上下文指令调优的多模态模型。Otter采用了OpenFlamingo训练范式,其中预训练的OpenFlamingo模型包括一个LLaMA-7B语言编码器和一个CLIP ViT-L/14视觉编码器。在指令调优的微调过程中,Otter冻结了两个编码器,并且只对Perceiver重采样模块进行微调。
基于Otter的Baseline,以及预先提供的以Otter框架标准的FunQA的训练集的json文件,我们鼓励大家使用Otter为baseline发挥自己的创造来精调出具有优秀理解幽默视频的能力。
请参赛者访问以下链接获取Otter模型:
GitHub - Luodian/Otter: 🦦 Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo), trained on MIMIC-IT and showcasing improved instruction-following and in-context learning ability.
数据说明
我们为参赛者提供了3072个训练集视频和424个测试集视频,决赛中我们一共有869个视频供评价使用,具体的数据集数量分布如表一所示。
训练集和测试集都分为三个子集:HumorQA,CreatQA和MagicQA,每个子集涵盖了不同的来源和视频内容,但其共同点在于其有趣和吸引人的性质,例如,幽默视频中出人意料的反差,创意视频中耐人寻味的伪装,以及魔术视频中不可思议的表演。对于问答对,HumorQA有四个任务(H1-H4),CreativeQA有五个任务(C1-C5),MagicQA有三个任务(M1-M3),它们的描述和举例如表二。
我们希望参赛者基于提供的FunQA数据集进行模型训练,我们也十分欢迎大家投身有趣视频理解的队伍,我们鼓励参赛者使用FunQA之外的数据集进行训练,自己在日常生活中发掘有趣视频并自己生成高质量的问题回答对会有很大可能提升模型训练的效果。
参赛者可以参考FunQA: Towards Surprising Video Comprehension论文并访问链接:
GitHub - Jingkang50/FunQA: FunQA benchmarks funny, creative, and magic videos for challenging tasks including timestamp localization, video description, reasoning, and beyond.
或观看视频:
Introducing FunQA - Surprising Video Question Answering Datasets._哔哩哔哩_bilibili 了解数据集的更多细节。
数据获取链接
百度网盘
链接:百度网盘 请输入提取码
提取码:x6rq
夸克网盘
链接:夸克网盘分享
提取码:UZBV
各渠道下载数据集内容一致,请选手选择自己需要的渠道进行下载
数据集分布:
| 数据集 | HumorQA | CreativeQA | MagicQA | (总计)FunQA |
|---|---|---|---|---|
| 训练集(完全公开) | 1244 | 657 | 1171 | 3072 |
| 测试集(初赛)(完全公开) | 172 | 85 | 167 | 424 |
| 测试集(决赛)(不公开) | - | - | - | 869 |
数据集举例
| 任务 | 任务描述 | 问题举例 | 答案举例 |
|---|---|---|---|
| H1 | 定位视频幽默的部分 | Locate the amusing part of the video. | [0000, 0195] |
| H2 | 给出视频中幽默部分的描述 | Provide a detailed account of the video's funny. moment. | A black and white cow-patterned feline is crammed inside a water glass and wildly shaking its head. |
| H3 | 解释视频中的幽默感 | "Why is the video as a whole comedic? | The cat is trying hard to stick its head into the cup to drink water. However, it couldn't pull its head out and started to frantically shake its head. The contrast between its initial effort and later embarrassment is amusing. |
| H4 | 为视频起一个合适的标题 | Provide a brief title for the video. | Cat: The water in the human's cup is the best to drink. |
| C1 | 定位视频中有创意的部分 | Identify the video's imaginative scene. | [0005,0094] |
| C2 | 给出视频中有创意部分的描述 | Provide a detailed account of the video's imaginative scene. | In the middle of the stage is a blue cloth floor, and behind it is a man holding a fishing rod, making a casting motion. At this time, a person wearing blue clothes jumps onto the blue floor with a fish bait puppet. Then the man begins to reel in the line, and they repeat the previous actions. This time, the person in blue clothes hugs a stone puppet at the edge, and after the fisherman forcefully reels in the line, they repeat the previous actions again. This time, the person in blue clothes goes under the blue cloth and emerges wearing a fish-shaped costume. The fisherman is overjoyed after reeling in the line and bends over to hug the fish-shaped puppet. |
| C3 | 解释视频中创意的来源 | Why is the video as a whole innovative? | The ingenuity of this video is that two people collaborate to simulate the atmosphere of fishing. The first person wearing a blue shirt simply climbs into the blue area and then climbs back, simulating that the fisherman didn't catch anything. The second person wearing a blue shirt climbs over and embraces a stone doll, simulating the hook getting caught on the stone. The fisherman pulls the fishing rod back vigorously, and the last person wearing a blue shirt simulates a fish getting away by changing clothes. |
| C4 | 为视频起一个合适的标题 | Provide a brief title for the video. | Fish bait. |
| C5 | 为视频的创意性给出[0,20]范围的评分 | Evaluate the video's artistic creativity using a scale of 0 to 20. | Considering a scale of 20, I'm inclined to give a rating of 18 to the creative concept of this video. |
| M1 | 定位视频中魔术的部分 | Pinpoint the video's magical segment. | [0032, 0072] |
| M2 | 给出视频中有魔术部分的描述 | Provide a detailed account of the video's enchanting moment. | Upon hearing the alarm clock, a hand seized it and slammed it onto the desk, causing it to break into a pile of coins. |
| M3 | 解释魔术使人感到不可思议的原因 | What factors create the magical atmosphere throughout the video? | The physical appearance of an object remains constant, and it's impossible for an alarm clock to turn into a stack of coins. |
竞赛规则
参赛形式
大赛分为初赛和决赛两个比赛环节。
初赛
初赛提交形式:选手通过赛题页-数据集,下载竞赛数据集,基于竞赛数据集在本地进行算法训练开发;根据【提交指南】提交结果文件,查看排行榜分数。
初赛晋级:排行榜分数最高的前十五支团队晋级决赛,角逐最终奖项
初赛规则:
- 禁止用测试集训练模型;
- 提交的模型输出结果必须符合大赛规范。
决赛
决赛时间: 10月下旬开启
决赛内容: 选手下载训练集,线下训练,并根据【提交指南】进行提交。评测组使用决赛测试集进行测试算出最终得分,进行排名。
决赛规则:
- 提交训练以及测试代码源码;
- 提交预训练模型;
- 提交代码文档和配置说明;
- 模型训练以及测试过程可以由大赛主办方完全复现;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











