




 本文详细解析了Transformer库中的Trainer类及其核心方法`train()`,包括参数处理、模型初始化、训练循环、优化器和学习率调度器的使用。Trainer类在模型训练中起到关键作用,它封装了训练逻辑,支持混合精度、分布式训练等功能。`train()`方法执行训练循环,计算损失,更新模型参数,并进行评估和检查点保存。
本文详细解析了Transformer库中的Trainer类及其核心方法`train()`,包括参数处理、模型初始化、训练循环、优化器和学习率调度器的使用。Trainer类在模型训练中起到关键作用,它封装了训练逻辑,支持混合精度、分布式训练等功能。`train()`方法执行训练循环,计算损失,更新模型参数,并进行评估和检查点保存。
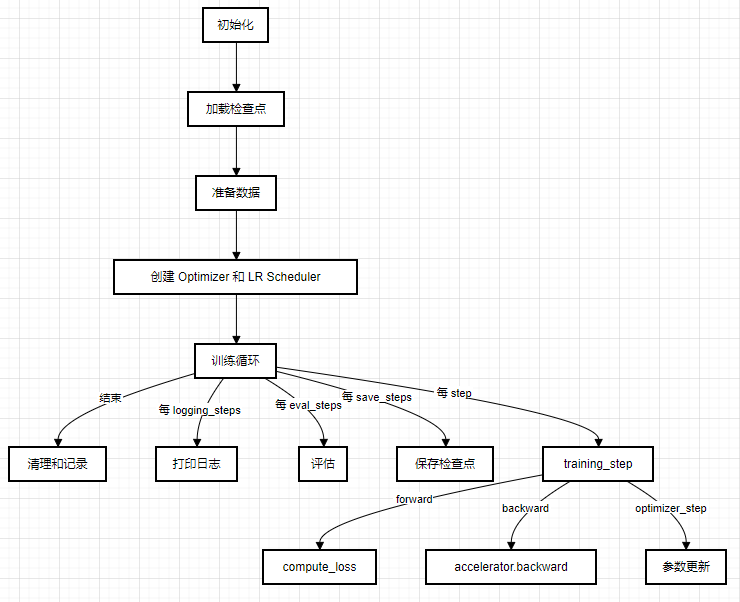
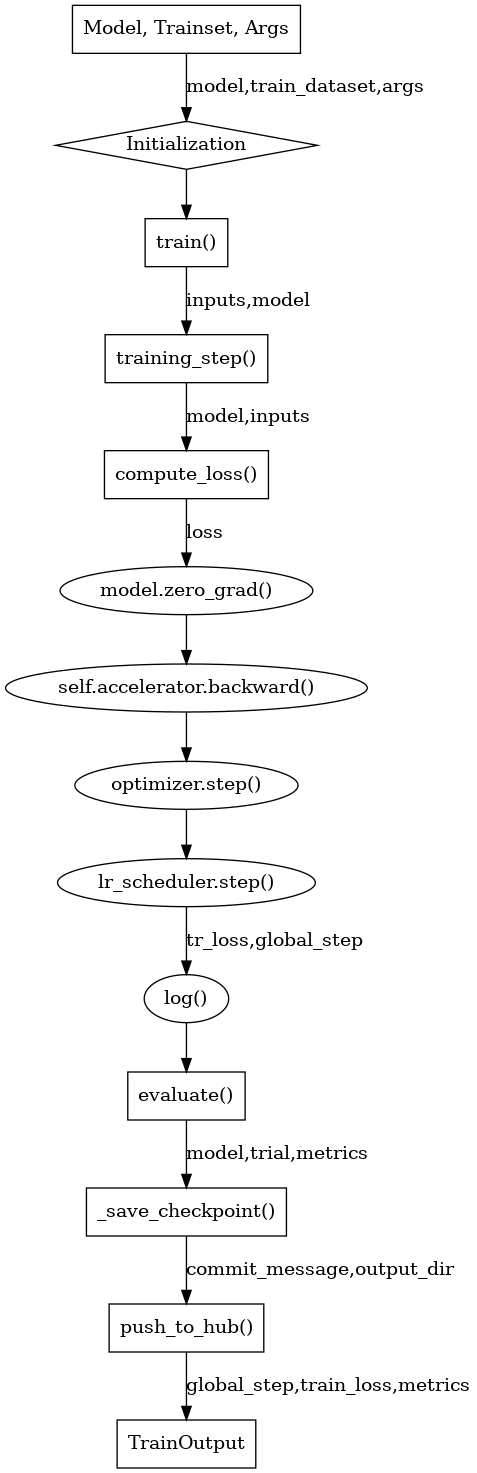
我会根据你提供的trainer.py源代码,用python的Graph包画出流程图,并着重介绍train()方法。以下是我的分析:
Trainer类是Transformers库中用于训练模型的核心类。它封装了训练循环的主要逻辑,并提供了许多功能,如混合精度训练、分布式训练、梯度累积等。
主要的输入参数有:
- model: 要训练的模型,可以是继承自PreTrainedModel的HuggingFace模型,也可以是自定义的nn.Module
- args: TrainingArguments对象,包含训练所需的各种参数
- data_collator: 用于将样本列表整理成batch的函数
- train_dataset: 用于训练的Dataset对象
- eval_dataset: 用于评估的Dataset对象
- tokenizer: 用于数据预处理的tokenizer
- model_init: 用于初始化模型的可调用对象
- compute_metrics: 用于在评估阶段计算各项指标的函数
- optimizers: 一个元组(optimizer, scheduler),如果不提供则会由Trainer自动创建
主要的属性有:
- self.model: 原始的模型对象
- self.model_wrapped: 如果模型被 wrapper(如 DP、DDP 等并行包装器)包装过,指被包装后的模型,否则与 self.model 相同
- self.optimizer: 优化器
- self.lr_scheduler: 学习率调度器
- self.state: 一个字典,用于记录训练过程中的状态信息,如当前epoch数、最佳评估结果等
- self.args: TrainingArguments参数对象
- self.callbacks: 回调函数列表
下面重点介绍train()方法的流程:
-
根据 args 和训练环境进行一些初始化工作,如设置 logger、初始化 tensorboard 等
-
加载检查点(如果指定了 resume_from_checkpoint)
-
准备 train_dataloader
-
计算总共需要训练的步数 max_steps 和 num_train_epochs
-
创建 optimizer 和 lr_scheduler(如果没有传入的话)
-
开始训练循环:
For epoch in range(num_train_epochs):
For step, inputs in enumerate(train_dataloader):
- 将 inputs 通过 self._prepare_inputs 方法处理后传给 self.training_step
- 在 self.training_step 中:
- 调用 self.compute_loss 计算loss
- 调用 self.accelerator.backward 计算梯度
- 调用 optimizer.step() 和 lr_scheduler.step() 进行参数更新
- 每 args.logging_steps 个步骤打印训练日志
- 每 args.eval_steps 个步骤进行一次评估
- 每 args.save_steps 个步骤保存一次检查点
- 如果实现了自己的回调,则会在特定的步骤被调用 -
训练结束后的一些清理和日志记录工作
-
返回一个 TrainOutput 对象,包含训练损失和最终的metrics结果
核心方法:train()
def train(
self,
resume_from_checkpoint: Optional[Union[str, bool]] = None,
trial: Union["optuna.Trial", Dict[str, Any]] = None,
ignore_keys_for_eval: Optional[List[str]] = None,
**kwargs,
):
"""
Main training entry point.
Args:
resume_from_checkpoint (`str` or `bool`, *optional*):
If a `str`, local path to a saved checkpoint as saved by a previous instance of [`Trainer`]. If a
`bool` and equals `True`, load the last checkpoint in *args.output_dir* as saved by a previous instance
of [`Trainer`]. If present, training will resume from the model/optimizer/scheduler states loaded here.
trial (`optuna.Trial` or `Dict[str, Any]`, *optional*):
The trial run or the hyperparameter dictionary for hyperparameter search.
ignore_keys_for_eval (`List[str]`, *optional*)
A list of keys in the output of your model (if it is a dictionary) that should be ignored when
gathering predictions for evaluation during the training.
kwargs (`Dict[str, Any]`, *optional*):
Additional keyword arguments used to hide deprecated arguments
"""
if resume_from_checkpoint is False:
resume_from_checkpoint = None
# memory metrics - must set up as early as possible
self._memory_tracker.start()
args = self.args
self.is_in_train = True
# Attach NEFTune hooks if necessary
if self.neftune_noise_alpha is not None:
self.model = self._activate_neftune(self.model)
# do_train is not a reliable argument, as it might not be set and .train() still called, so
# the following is a workaround:
if (args.fp16_full_eval or args.bf16_full_eval) and not args.do_train:
self._move_model_to_device(self.model, args.device)
if "model_path" in kwargs:
resume_from_checkpoint = kwargs.pop("model_path")
warnings.warn(
"`model_path` is deprecated and will be removed in a future version. Use `resume_from_checkpoint` "
"instead.",
FutureWarning,
)
if len(kwargs) > 0:
raise TypeError(f"train() received got unexpected keyword arguments: {', '.join(list(kwargs.keys()))}.")
# This might change the seed so needs to run first.
self._hp_search_setup(trial)
self._train_batch_size = self.args.train_batch_size
# Model re-init
model_reloaded = False
if self.model_init is not None:
# Seed must be set before instantiating the model when using model_init.
enable_full_determinism(self.args.seed) if self.args.full_determinism else set_seed(self.args.seed)
self.model = self.call_model_init(trial)
model_reloaded = True
# Reinitializes optimizer and scheduler
self.optimizer, self.lr_scheduler = None, None
# Load potential model checkpoint
if isinstance(resume_from_checkpoint, bool) and resume_from_checkpoint:
resume_from_checkpoint = get_last_checkpoint(args.output_dir)
if resume_from_checkpoint is None:
raise ValueError(f"No valid checkpoint found in output directory ({args.output_dir})")
if resume_from_checkpoint is not None:
if not is_sagemaker_mp_enabled() and not self.is_deepspeed_enabled and not self.is_fsdp_enabled:
self._load_from_checkpoint(resume_from_checkpoint)
# In case of repeating the find_executable_batch_size, set `self._train_batch_size` properly
state = TrainerState.load_from_json(os.path.join(resume_from_checkpoint, TRAINER_STATE_NAME))
if state.train_batch_size is not None:
self._train_batch_size = state.train_batch_size
# If model was re-initialized, put it on the right device and update self.model_wrapped
if model_reloaded:
if self.place_model_on_device:
self._move_model_to_device(self.model, args.device)
self.model_wrapped = self.model
inner_training_loop = find_executable_batch_size(
self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size
)
if args.push_to_hub:
try:
# Disable progress bars when uploading models during checkpoints to avoid polluting stdout
hf_hub_utils.disable_progress_bars()
return inner_training_loop(
args=args,
resume_from_checkpoint=resume_from_checkpoint,
trial=trial,
ignore_keys_for_eval=ignore_keys_for_eval,
)
finally:
hf_hub_utils.enable_progress_bars()
else:
return inner_training_loop(
args=args,
resume_from_checkpoint=resume_from_checkpoint,
trial=trial,
ignore_keys_for_eval=ignore_keys_for_eval,
)
def _inner_training_loop(
self, batch_size=None, args=None, resume_from_checkpoint=None, trial=None, ignore_keys_for_eval=None
):
self.accelerator.free_memory()
self._train_batch_size = batch_size
if self.args.auto_find_batch_size:
if self.state.train_batch_size != self._train_batch_size:
from accelerate.utils import release_memory
(self.model_wrapped,) = release_memory(self.model_wrapped)
self.model_wrapped = self.model
# Check for DeepSpeed *after* the intial pass and modify the config
if self.is_deepspeed_enabled:
# Temporarily unset `self.args.train_batch_size`
original_bs = self.args.per_device_train_batch_size
self.args.per_device_train_batch_size = self._train_batch_size // max(1, self.args.n_gpu)
self.propagate_args_to_deepspeed(True)
self.args.per_device_train_batch_size = original_bs
self.state.train_batch_size = self._train_batch_size
logger.debug(f"Currently training with a batch size of: {self._train_batch_size}")
# Data loader and number of training steps
train_dataloader = self.get_train_dataloader()
if self.is_fsdp_xla_v2_enabled:
train_dataloader = tpu_spmd_dataloader(train_dataloader)
# Setting up training control variables:
# number of training epochs: num_train_epochs
# number of training steps per epoch: num_update_steps_per_epoch
# total number of training steps to execute: max_steps
total_train_batch_size = self._train_batch_size * args.gradient_accumulation_steps * args.world_size
len_dataloader = None
num_train_tokens = None
if has_length(train_dataloader):
len_dataloader = len(train_dataloader)
num_update_steps_per_epoch = len_dataloader // args.gradient_accumulation_steps
num_update_steps_per_epoch = max(num_update_steps_per_epoch, 1)
num_examples = self.num_examples(train_dataloader)
if args.max_steps > 0:
max_steps = args.max_steps
num_train_epochs = args.max_steps // num_update_steps_per_epoch + int(
args.max_steps % num_update_steps_per_epoch > 0
)
# May be slightly incorrect if the last batch in the training dataloader has a smaller size but it's
# the best we can do.
num_train_samples = args.max_steps * total_train_batch_size
if args.include_tokens_per_second:
num_train_tokens = (
self.num_tokens(train_dataloader, args.max_steps) * args.gradient_accumulation_steps
)
else:
max_steps = math.ceil(args.num_train_epochs * num_update_steps_per_epoch)
num_train_epochs = math.ceil(args.num_train_epochs)
num_train_samples = self.num_examples(train_dataloader) * args.num_train_epochs
if args.include_tokens_per_second:
num_train_tokens = self.num_tokens(train_dataloader) * args.num_train_epochs
elif args.max_steps > 0: # Rely on max_steps when dataloader does not have a working size
max_steps = args.max_steps
# Setting a very large number of epochs so we go as many times as necessary over the iterator.
num_train_epochs = sys.maxsize
num_update_steps_per_epoch = max_steps
num_examples = total_train_batch_size * args.max_steps
num_train_samples = args.max_steps * total_train_batch_size
if args.include_tokens_per_second:
num_train_tokens = self.num_tokens(train_dataloader, args.max_steps) * args.gradient_accumulation_steps
else:
raise ValueError(
"args.max_steps must be set to a positive value if dataloader does not have a length, was"
f" {args.max_steps}"
)
if DebugOption.UNDERFLOW_OVERFLOW in self.args.debug:
if self.args.n_gpu > 1:
# nn.DataParallel(model) replicates the model, creating new variables and module
# references registered here no longer work on other gpus, breaking the module
raise ValueError(
"Currently --debug underflow_overflow is not supported under DP. Please use DDP"
" (torchrun or torch.distributed.launch (deprecated))."
)
else:
debug_overflow = DebugUnderflowOverflow(self.model) # noqa
delay_optimizer_creation = is_sagemaker_mp_enabled() or self.is_fsdp_xla_enabled or self.is_fsdp_enabled
# We need to reset the scheduler, as its parameters may be different on subsequent calls
if self._created_lr_scheduler:
self.lr_scheduler = None
self._created_lr_scheduler = False
if self.is_deepspeed_enabled:
self.optimizer, self.lr_scheduler = deepspeed_init(self, num_training_steps=max_steps)
if not delay_optimizer_creation:
self.create_optimizer_and_scheduler(num_training_steps=max_steps)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











