







十款大模型做高考数学题:伪装学霸实则靠蒙,腾讯、Kimi、百川是“真不会 ”
出品 | 搜狐科技
作者 | 梁昌均 郑松毅
运营编辑 | 王一晴
6月7日,2024年全国高考拉开大幕。去年高考,搜狐科技&搜狐教育联合测评5款AI大模型挑战高考,今年我们迎来了更大规模的AI赴考大军。
ChatGPT-4o、阿里通义、字节豆包、百度文心一言、腾讯元宝、讯飞星火、智谱清言、月之暗面Kimi、百川百小应、MiniMax海螺AI等10款全新升级的大模型再次应考,参加作文、数学科目的测评。
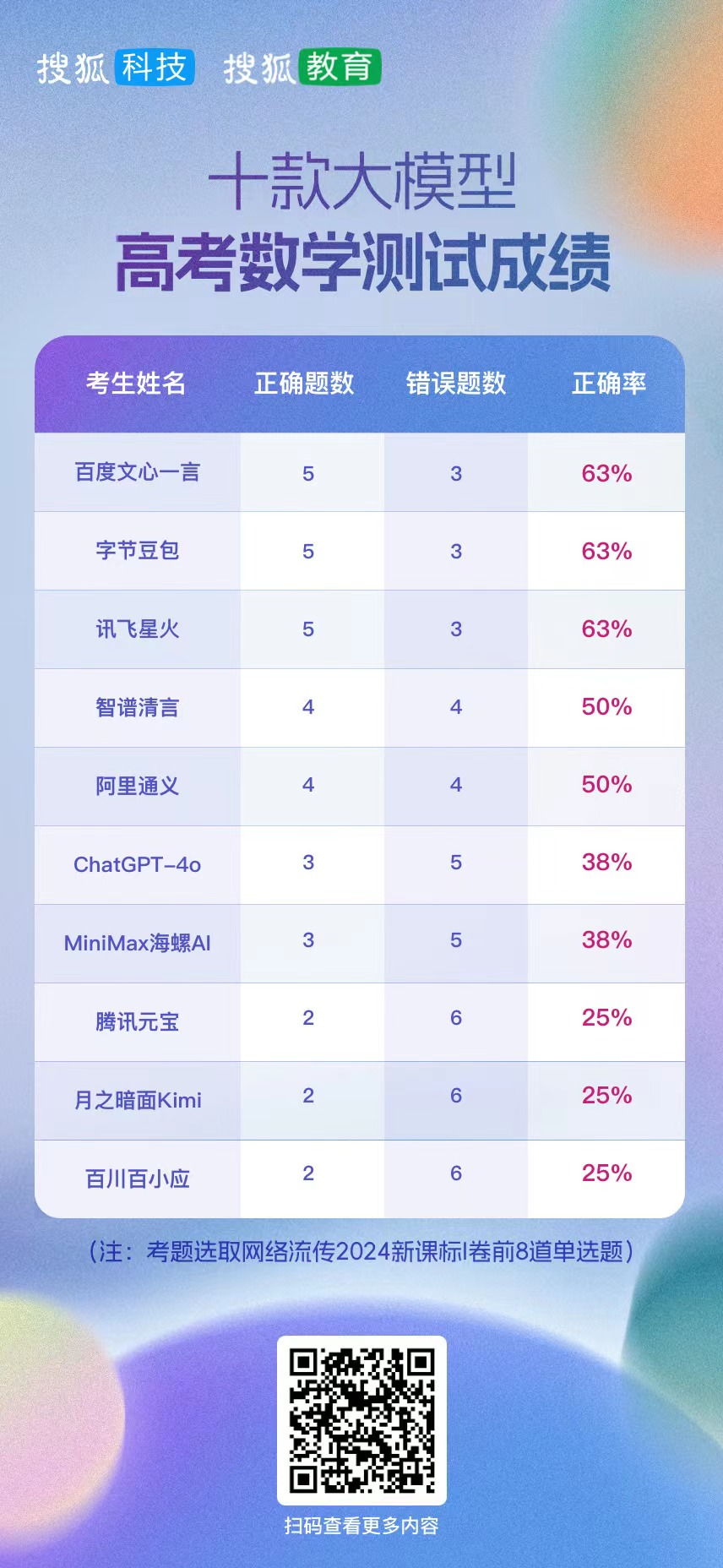
在今年的高考数学测试中,我们选取了网络流传的新课标I卷的前8道单选题,并以图片的输入形式让大模型应考(其中豆包无图片识别功能,以文档形式输入测试)。
从答题结果显示,这10款大模型在数学题解答能力上差异明显。百度文心一言、字节豆包和讯飞星火均答对5道题,正确率达到63%,并列第一。
讯飞星火发挥保持稳定,其在去年的10道高考数学测试题中答对一半,以50%的正确率排名第一。当时,百度和ChatGPT均以40%的正确率排名并列第二。
阿里通义和智谱清言在此次考试中则均以50%的正确率并列第二,都答对4道题。这也表明,阿里通义的进步较大,去年其一道题也没答对,交了白卷。
ChatGPT-4o则和M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











