






我们离 GPT-4V 还有多远?
利用开源套件缩小与商业多式联运模式的差距
Zhe Chen4,1∗†, Weiyun Wang5,1∗†, Hao Tian2∗, Shenglong Ye1∗, Zhangwei Gao1†, Erfei Cui1†, Wenwen Tong2,
Kongzhi Hu2, Jiapeng Luo2, Zheng Ma2, Ji Ma2, Jiaqi Wang1, Xiaoyi Dong6,1, Hang Yan1, Hewei Guo2,
Conghui He1, Botian Shi1, Zhenjiang Jin1, Chao Xu1, Bin Wang1, Xingjian Wei1, Wei Li1, Wenjian Zhang1,
Bo Zhang1, Pinlong Cai1, Licheng Wen1, Xiangchao Yan1, Min Dou1, Lewei Lu2, Xizhou Zhu3,1,2, Tong Lu4,
Dahua Lin6,1, Yu Qiao1, Jifeng Dai3,1, Wenhai Wang6,1🖂
1Shanghai AI Laboratory 2SenseTime Research 3Tsinghua University
4Nanjing University 5Fudan University 6The Chinese University of Hong Kong
Demo: https://internvl.opengvlab.com
Code: GitHub - OpenGVLab/InternVL: [CVPR 2024 Oral] InternVL Family: A Pioneering Open-Source Alternative to GPT-4o. 接近GPT-4o表现的可商用开源多模态对话模型
Model: https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5
摘要
在本报告中,我们介绍了 InternVL 1.5,这是一种开源多模态大语言模型 (MLLM),旨在弥合开源模型和专有商业模型在多模态理解方面的能力差距。 我们介绍三个简单的改进:
(1)强视觉编码器:我们为大规模视觉基础模型InternViT-6B探索了一种持续学习策略,提高了其视觉理解能力,并使其可以在不同的大语言中迁移和重用。模型。
(2)动态高分辨率:根据输入图像的长宽比和分辨率,将图像划分为1到40个448×448像素的图块,最高支持4K分辨率输入。
(3)高质量的双语数据集:我们精心收集了高质量的双语数据集,涵盖常见场景、文档图像,并用英文和中文问答对对其进行注释,显着提高了 OCR 和中文相关任务的性能。 我们通过一系列基准测试和比较研究来评估 InternVL 1.5。 与开源和专有商业模型相比,InternVL 1.5 显示出具有竞争力的性能,在 18 个多模式基准测试中的 8 个中取得了最先进的结果。
†
1简介
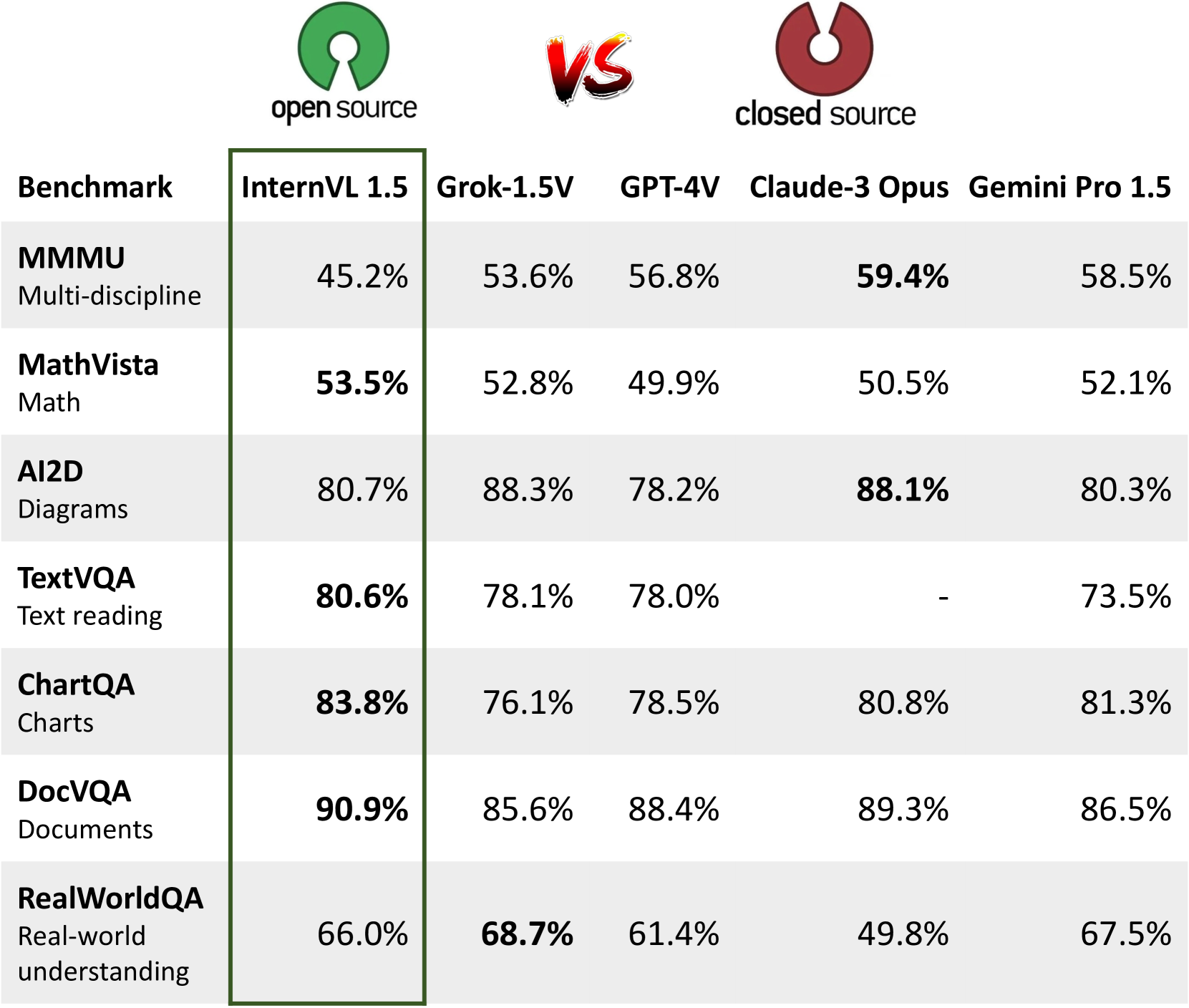
图1:InternVL 1.5 与专有商业模型。 这些基准测试的结果表明,InternVL 1.5 的性能可与领先的专有模型相媲美。
大型语言模型(大语言模型)在推进通用人工智能(AGI)系统方面发挥了重要作用,展示了处理开放世界语言任务的卓越能力。 利用大语言模型的进步,多模态大语言模型 (MLLM) [116, 5, 63, 62, 142, 18, 84, 23, 92] 取得了重大进展,促进了复杂的视觉-语言对话和互动弥合了文本和视觉信息之间的差距。 尽管取得了这些成就,开源模型和专有商业模型的功能之间仍然存在明显的鸿沟,例如、GPT-4V [87]、Gemini 系列 [92, 107] 和 Qwen-VL-Max [5]。
这种差距主要体现在以下三个方面:
(1)参数规模:最近专有的商业MLLM[87,92,5,102]通常规模不小于100十亿个参数,而开源模型通常采用3亿个参数的视觉基础模型(VFM),它与70亿或130亿个大语言模型集成。
(2) 图像分辨率:专有商业模型通常采用动态分辨率方法,保留原始纵横比,以方便详细的场景和文档理解。 相比之下,开源模型通常以固定分辨率[62,18,23,142,117,71]进行训练,例如336×336和448×448,导致相对于商业同行在能力上有相当大的差距。
(3) 多语言能力:专有模型通常利用广泛的多语言数据集进行训练,从而提高其在不同语言上的性能。 然而,开源模型主要利用英文数据,依赖于大语言模型对其他语言的零样本能力,例如 LLaVA-NeXT [64]。 这会导致非英语场景理解和 OCR 任务中的性能不佳。
为了弥补这一差距,我们推出了 InternVL 1.5,集成了三项重大改进,以增强其性能和可用性。 (1) 我们对大规模 VFM——InternViT-6B [18] 实施了持续学习方法,并使用高质量的图像文本数据对其进行了改进。 这个过程不仅增强了模型理解视觉内容的能力,而且提高了其在各种大语言模型中的适应性。 此外,使用InternLM2-20B[11]作为语言基础模型还提供了强大的初始语言处理能力。 (2)我们采用动态高分辨率策略,将图像分割为448×448个图块,图块数量范围从1到40(即,4K分辨率)关于图像的长宽比和分辨率。 为了捕获全局上下文,我们还添加了缩略图视图。 (3)我们收集了多样化的公共数据集,涵盖高质量的自然场景、图表、文档和中英文对话。 此外,我们使用开源大语言模型开发了数据翻译管道,可以轻松扩展到更多语言。
这些设计赋予我们的模型几个优点:
(1) 灵活的分辨率:类似于 GPT-4V [87] 中可用的“低”或“高”模式,InternVL 1.5 使用户能够为图像选择最佳分辨率,例如使用低分辨率进行场景主题描述,使用高分辨率(高达 4K 分辨率)进行文档理解,有效平衡计算效率和细节保留。
(2)双语能力:InternVL 1.5展现出强大的双语能力,能够熟练处理中英双语的多模态感知和理解任务。 值得注意的是,在与中文相关的任务中,我们的模型通常优于领先的商业模型 GPT-4V [87]。
(3) 强大的视觉表示:通过实施持续学习策略,我们增强了 InternViT-6B [18] 的视觉表示能力,使其能够适应灵活的输入分辨率和各种视觉领域。 受益于 InternViT-6B 的海量参数,我们的模型实现了与拥有超过 200 亿个参数的大语言模型的语言能力相媲美的视觉表示水平。 视觉和语言处理之间的协同作用赋予我们的系统强大的多模式功能。
我们在 18 个具有代表性的多模态基准上评估了 InternVL 1.5,这些基准分为四个特定组:OCR 相关、一般多模态、数学和多轮对话基准。 与开源和专有模型相比,InternVL 1.5 显示出具有竞争力的性能,在 18 个基准测试中的 8 个中取得了最先进的结果。 值得注意的是,如图1所示,它甚至超越了Grok-1.5V [125]、GPT-4V [87]等领先的专有型号、Claude-3 Opus [3] 和 Gemini Pro 1.5 [92] 在四个特定基准测试中,特别是在 OCR 相关数据集(例如 TextVQA [100])中、ChartQA [81] 和 DocVQA [82]。 此次评测表明,InternVL 1.5有效缩小了开源模型与领先商业模型之间的差距。 我们希望我们的方法和开源模型权重能够为 MLLM 社区的发展做出贡献。

图2:InternVL 1.5 的特点。 InternVL 1.5 通过持续学习、灵活的解析能力和强大的中英文双语能力,具有强大的视觉表现力,将其定位为具有竞争力的 MLLM。
2相关工作
2.1专有商业 MLLM
大型语言模型(大语言模型)[1, 112, 122, 113, 141, 108, 104, 25, 4, 7, 106, 123, 11, 8] 通过启用复杂的语言任务以前被认为是人类独有的。 在此基础上,专有商业 MLLM 的开发代表了重大发展。 例如,OpenAI 的 GPT-4V [87] 通过合并视觉输入扩展了 GPT-4 的功能,使其能够处理文本和图像内容,这是 MLLM 领域的一项重大发展。 随后,Google 的 Gemini 系列从 Gemini 1.0 [107] 发展到 Gemini 1.5 [92],增强了 MLLM 处理文本、图像和音频的能力,并支持高达100 万个 Token ,显着提升性能。 Qwen-VL-Plus/Max 是阿里巴巴 Qwen-VL 系列[5]中的领先型号,以在无需 OCR 工具的情况下执行多模式任务的卓越能力而闻名。 专有 MLLM 的最新进展包括 Anthropic 的 Claude-3V 系列[3]、HyperGAI 的 HPT Pro [35]、Apple 的 MM1 [84]、StepFun 的Step-1V [102],以及 xAI 的 Grok-1.5V [125]。
2.2开源 MLLM
开源MLLM的发展[138, 139, 124, 103, 2, 43, 48, 55, 51, 56, 69, 70, 110, 118, 120, 13]对通过整合和增强处理视觉和文本数据的能力来打造 AGI 格局。 过去一年,不少开源MLLM已为人熟知,包括LLaVA系列[63,62,64]、MiniGPT-4[142]、VisionLLM [116]、Qwen-VL [5]、CogVLM [117]、Shikra [15] 和其他[119,90,18,23]。 然而,这些模型通常在具有较小固定分辨率的图像上进行训练,例如 336×336 或 448×448,这会导致在具有异常长宽比的图像上表现不佳或文档数据。 为了解决这个问题,人们探索了许多在高分辨率图像上进行训练的方法。 目前常见的技术路线有两种:一种是设计双分支图像编码器[32,77,121,76,53],另一种是将高分辨率图像划分为许多低分辨率图像。 - 分辨率图块 [33, 47, 55, 57, 64, 68, 126, 127, 24]。 尽管在高分辨率训练方面进行了这些探索,但与领先的商业模型相比,这些开源模型在理解文档、图表和信息图表以及识别场景文本方面仍然表现出巨大差距。
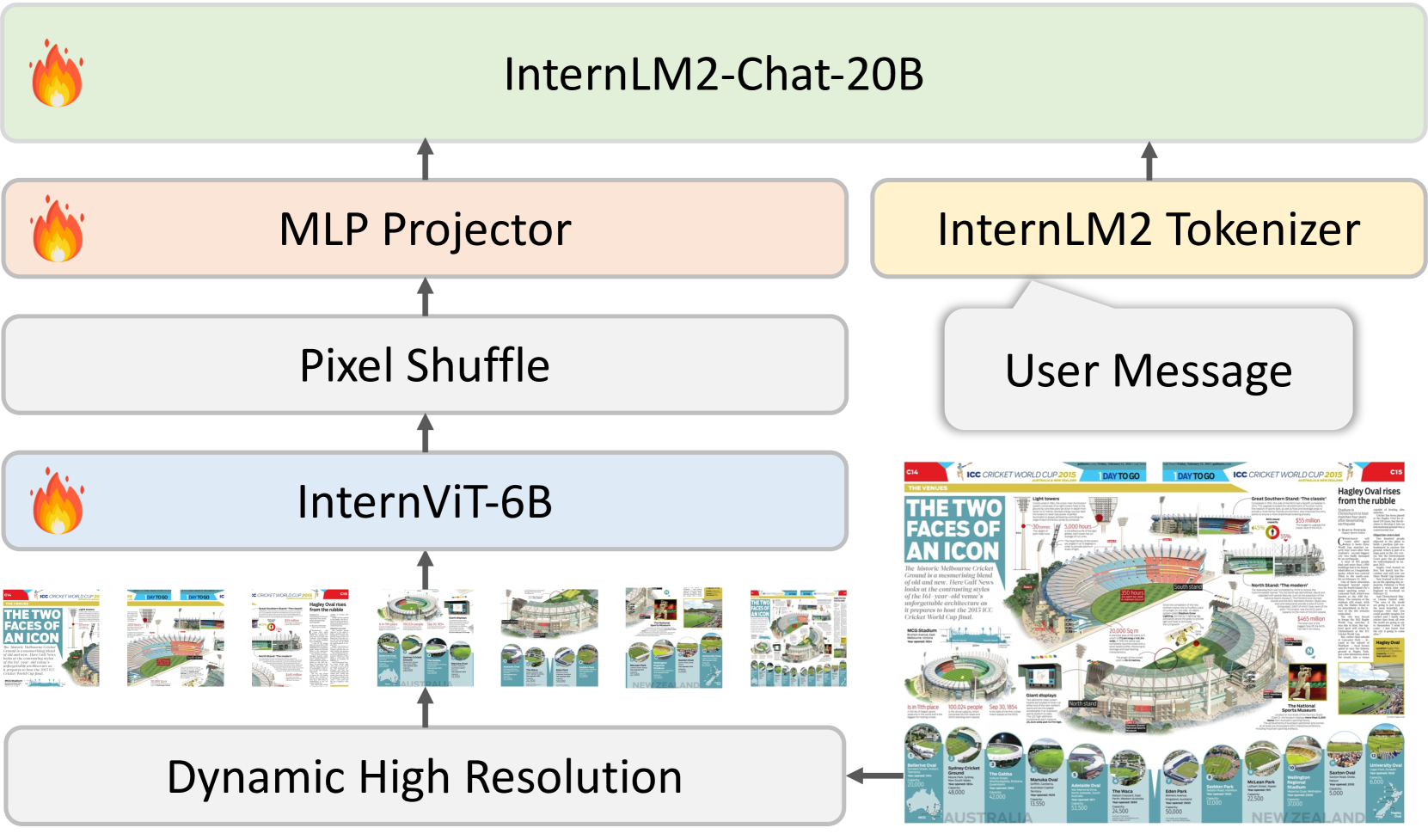
图3:整体架构。 InternVL 1.5 采用类似于流行的 MLLM [62, 64] 的 ViT-MLP-LLM 架构,将预训练的 InternViT-6B [18] 与 InternLM2-20B 相结合[11] 通过 MLP 投影仪。 在这里,我们采用简单的像素洗牌将视觉标记的数量减少到四分之一。
2.3MLLM 的视觉基础模型
视觉基础模型 (VFM) 是 MLLM 社区内的研究焦点。 目前普遍使用的模型有CLIP-ViT [91]和SigLIP [136]等;然而,已经进行了许多研究来寻找最适合 MLLM 的视觉编码器[57,111,76,71]。 例如,Tong等人。 [111]观察到 CLIP 和 DINOv2 视觉模式的显着差异[88],导致开发了一个混合功能模块,该模块结合了这两个 VFM。 LLaVA-HR [76] 引入了一种双分支视觉编码器,利用 CLIP-ViT 实现低分辨率路径,使用 CLIP-ConvNext 实现高分辨率路径。 同样,DeepSeek-VL[71]采用了双视觉编码器设计,对于低分辨率图像使用SigLIP-L,对于高分辨率图像使用SAM-B。 在本报告中,我们为视觉基础模型 InternViT-6B [18] 提出了一种持续学习策略,该策略不断提高视觉理解能力,并且可以在不同的大语言模型之间迁移和重用。
3实习生VL 1.5
3.1整体架构
如图 3 所示,InternVL 1.5 采用类似于广泛使用的开源 MLLM 的架构,特别是各种现有研究中引用的“ViT-MLP-LLM”配置[62, 64 、23、18、142、63、71]。 我们对此架构的实现使用随机初始化的 MLP 投影仪将预训练的 InternViT-6B [18] 与预训练的 InternLM2-20B [11] 集成。
在训练过程中,我们实现了动态分辨率策略,根据输入图像的宽高比和分辨率,将图像划分为 448×448 像素、大小范围为 1 到 12 的图块。 在测试过程中,这可以是零样本,可缩放至 40 个图块(即,4K 分辨率)。 为了增强高分辨率的可扩展性,我们简单地采用了像素洗牌操作,将视觉标记的数量减少到原始的四分之一。 因此,在我们的模型中,448×448 图像由 256 个视觉标记表示。
3.2强视觉编码器
在现有的 MLLM [62, 63, 64, 23, 142, 5, 78] 中,最常用的视觉基础模型通常是对比预训练的 ViT [36, 18, 91 ,136]。 然而,这些 ViT 通常是在以固定的低分辨率(例如,224×224)从互联网上爬取的图像文本对上进行训练的,因此在执行处理任务时,它们的性能会下降高分辨率图像或来自互联网以外来源的图像,例如文档图像。
InternViT-6B-448px-V1.2。 为了解决这个问题,InternVL 1.2 更新涉及对 InternViT-6B 模型进行持续预训练。 首先,我们发现倒数第四层的特征对于多模态任务表现最好,因此我们直接丢弃最后三层的权重,将InternViT-6B从48层减少到45层。 然后,我们将InternViT-6B的分辨率从224提高到448,并将其与Nous-Hermes-2-Yi-34B [130]集成。 为了使模型具备高分辨率处理和 OCR 功能,视觉编码器和 MLP 均被激活进行训练,并结合使用图像字幕 [93, 10, 90, 17, 100] 和OCR 特定数据集[29, 94]。 从此过程中新导出的 InternViT 权重发布为 InternViT-6B-448px-V1.21。
InternViT-6B-448px-V1.5。 InternVL 1.5的开发延续了InternViT-6B-448px-V1.2强大基础的预训练。 在本次更新中,训练图像的分辨率从固定的 448×448 扩展到动态 448×448,其中基本图块大小为 448×448,瓷砖数量范围为 1 到 12。 此外,我们还增强了预训练数据集的数据规模、质量和多样性,从而使 1.5 版本模型具有强大的鲁棒性、OCR 能力和高分辨率处理能力2 . 动态分辨率和训练数据集的详细信息在 3.3 和 3.4 节中描述。
值得注意的是,尽管InternVL 1.5中的大语言模型由Nous-Hermes-2-Yi-34B改为InternLM2-20B[11],但InternViT仍然保持了与新大语言模型良好的兼容性和可移植性。语言模型。 这表明 InternViT-6B 在 MLLM 的预训练阶段学习的视觉特征具有广泛的适用性,并且与特定的大语言模型没有紧密的联系。
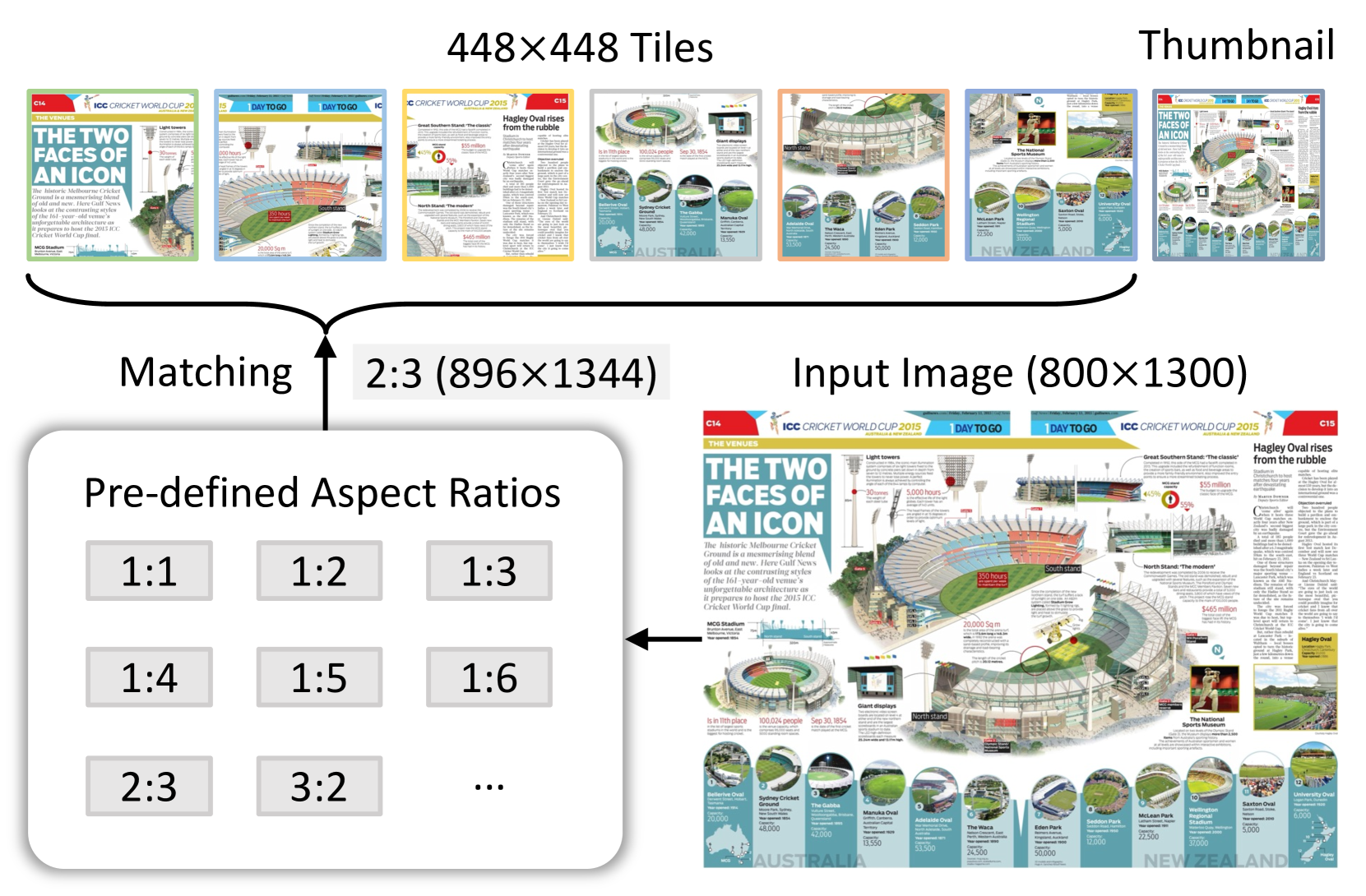
图4:动态高分辨率的插图。 我们根据预定义的比例动态匹配最佳纵横比,将图像划分为 448×448 像素的图块,并为全局上下文创建缩略图。 此方法可最大程度地减少纵横比失真并适应训练期间不同的分辨率。
3.3动态高分辨率
受 UReader [127] 的启发,我们采用动态高分辨率训练方法,可以有效适应输入图像的不同分辨率和长宽比。 该方法利用将图像分割成图块的灵活性,增强模型处理详细视觉信息的能力,同时适应不同的图像分辨率。 主要包括以下几个步骤:
动态纵横比匹配。 如图4所示,为了在处理过程中保持自然的宽高比,我们从一组预定义的宽高比中动态匹配最佳的宽高比。 由于计算资源有限,我们在训练期间最多允许 12 个图块。 因此,该集合包括由 1 到 12 个图块形成的所有 35 种可能的宽高比组合,例如 {1:1、1:2、2:1、3:1、…、2:6}。 在匹配过程中,对于每个输入图像,我们计算其纵横比,并通过测量绝对差将其与 35 个预定义的纵横比进行比较。 如果多个预定义的宽高比匹配(例如、1:1和2:2),我们会优先考虑不超过输入图像面积两倍的宽高比,从而防止低分辨率图像过度放大。
图像分割和缩略图。 一旦确定了适当的宽高比,图像的大小就会调整为相应的分辨率。 例如,800×1300 图像将调整为 896×1344。 然后,调整大小的图像被分成 448×448 像素的图块。 除了图块之外,我们还包含整个图像的缩略图以捕获全局上下文。 该缩略图缩小至 448×448,帮助模型理解整个场景。 因此,在训练过程中,视觉标记的数量范围为256至3,328。 在测试过程中,图块数量最多可以增加到 40 个,从而产生 10,496 个视觉标记。
| task | ratio | dataset |
| Laion-EN (en) [93], Laion-ZH (zh) [93], COYO (zh) [10], | ||
| Captioning | 53.9% | GRIT (zh) [90], COCO (en) [17], TextCaps (en) [99] |
| Objects365 (en&zh) [97], GRIT (en&zh) [90], | ||
| Detection | 5.2% | All-Seeing (en&zh) [119] |
| Wukong-OCR (zh) [29], LaionCOCO-OCR (en) [94], | ||
| OCR (large) | 32.0% | Common Crawl PDF (en&zh) |
| MMC-Inst (en) [61], LSVT (zh) [105], ST-VQA (en) [9] | ||
| RCTW-17 (zh) [98], ReCTs (zh) [137], ArT (en&zh) [19], | ||
| SynthDoG (en&zh) [41], COCO-Text (en) [114], | ||
| ChartQA (en) [81], CTW (zh) [134], DocVQA (en) [82], | ||
| OCR (small) | 8.9% | TextOCR (en) [101], PlotQA (en) [85], InfoVQA (en) [83] |
(a)Datasets used in the pre-training stage.
| task | dataset |
| Captioning | TextCaps (en) [99], ShareGPT4V (en&zh) [16] |
| VQAv2 (en) [28], GQA (en) [34], OKVQA (en) [80], | |
| General QA | VSR (en) [59], VisualDialog (en) [22] |
| Science | AI2D (en) [39], ScienceQA (en) [73], TQA (en) [40] |
| ChartQA (en) [81], MMC-Inst (en) [61], DVQA (en) [38], | |
| Chart | PlotQA (en) [85], LRV-Instruction (en) [60] |
| GeoQA+ (en) [12], TabMWP (en) [74], MathQA (en) [132], | |
| Mathematics | CLEVR-Math/Super (en) [58, 54], Geometry3K (en) [72] |
| KVQA (en) [96], A-OKVQA (en) [95], ViQuAE (en) [45], | |
| Knowledge | Wikipedia (en&zh) [31] |
| OCRVQA (en) [86], InfoVQA (en) [83], TextVQA (en) [100], | |
| ArT (en&zh) [19], COCO-Text (en) [114], CTW (zh) [134], | |
| LSVT (zh) [105], RCTW-17 (zh) [98], ReCTs (zh) [137], | |
| OCR | SynthDoG (en&zh) [41], ST-VQA (en) [9] |
| Document | DocVQA (en) [20], Common Crawl PDF (en&zh) |
| Grounding | RefCOCO/+/g (en) [131, 79], Visual Genome (en) [42] |
| LLaVA-150K (en&zh) [63], LVIS-Instruct4V (en) [115], | |
| ALLaVA (en&zh) [14], Laion-GPT4V (en) [44], | |
| Conversation | TextOCR-GPT4V (en) [37], SVIT (en&zh) [140] |
| OpenHermes2.5 (en) [109], Alpaca-GPT4 (en) [106], | |
| Text-only | ShareGPT (en&zh) [141], COIG-CQIA (zh) [6] |
(b)Datasets used in the fine-tuning stage. 表1:InternVL 1.5 中使用的数据集摘要。 为了构建大规模 OCR 数据集,我们利用 PaddleOCR [49] 对《悟空传》[29]中的图像执行中文 OCR,并对《LAION-COCO》[94]中的图像执行英文 OCR。
3.4高质量双语数据集
预训练数据集。 InternVL 1.5 中使用的预训练数据集包含各种可公开访问的来源。 我们在表 1(a) 中提供了这些数据集的概述。 这些数据集涵盖多个任务,包括字幕,主要使用 Laion-EN [93]、Laion-ZH [93]、COYO [10] 等数据集和GRIT[90],占总数据的53.9%。 检测和接地任务使用 Objects365 [97]、GRIT [90] 和 All-Seeing [119] 等数据集,占 5.2% 。 对于 OCR 任务,我们使用了 Wukong-OCR、LaionCOCO-OCR 和 Common Crawl PDF 等大型数据集,这些数据集占我们数据的 32.0%。 这些数据集是使用 PaddleOCR [49] 构建的,对 Wukong [29] 的中文图像和 LaionCOCO [94] 的英文图像执行 OCR 。 较小的 OCR 数据集包括 MMC-Inst [61]、LSVT [105]、ST-VQA [9]、RCTW-17 [98]、ArT [19] 等,占数据的 8.9%,重点关注更具体或受限的 OCR 挑战。 这种多样化的数据集组装确保了 InternVL 的稳健模型预训练,满足跨任务的不同语言和视觉元素。
| System:You are a translator proficient in English and {language}. Your task is to translate the following English text into {language}, focusing on a natural and fluent result that avoids “translationese.” Please consider these points:1. Keep proper nouns, brands, and geographical names in English.2. Retain technical terms or jargon in English, but feel free to explain in {language} if necessary.3. Use {language} idiomatic expressions for English idioms or proverbs to ensure cultural relevance.4. Ensure quotes or direct speech sound natural in {language}, maintaining the original’s tone.5. For acronyms, provide the full form in {language} with the English acronym in parentheses.User:Text for translation: {text}Assistant:{translation results} |
图5: 我们的数据转换管道的说明。 根据这个提示,我们将英文数据翻译成中文,同时保持语言自然流畅。 其中,{language}表示目标语言,{text}表示英文原文,{translation results}表示翻译后的文本。
| open- | OCR-related Benchmarks | General Multimodal Benchmarks | Math | ||||||||||||||
| model | source | #param | DocVQA | ChartQA | InfoVQA | TextVQA | OCRBench | MME | RWQA | AI2D | MMMU | MMB-EN/CN | CCB | MMVet | SEED | HallB | MathVista |
| GPT-4V [1] | ✗ | − | 88.4 | 78.5 | − | 78.0 | 645 | 1926.6 | 61.4 | 78.2 | 56.8 | 77.0 / 74.4 | 46.5 | 67.6 | 71.6 | 46.5 | 49.9 |
| Gemini Ultra 1.0 [107] | ✗ | − | 90.9 | 80.8 | 80.3 | 82.3 | − | − | − | 79.5 | 59.4 | − / − | − | − | − | − | 53.0 |
| Gemini Pro 1.0 [107] | ✗ | − | 88.1 | 74.1 | 75.2 | 74.6 | 659 | 1933.4 | − | 73.9 | 47.9 | 73.6 / 74.3 | 52.5 | 64.3 | 70.7 | 45.2 | 45.2 |
| Gemini Pro 1.5 [92] | ✗ | − | 86.5 | 81.3 | 72.7 | 73.5 | − | − | 67.5 | 80.3 | 58.5 | − / − | − | − | − | − | 52.1 |
| Qwen-VL-Max [5] | ✗ | − | 93.1 | 79.8 | 73.4 | − | 723 | 2433.6 | − | 79.3 | 51.3 | 77.6 / 75.7 | 63.5 | 66.6 | − | 41.2 | 51.0 |
| Qwen-VL-Plus [5] | ✗ | − | 91.4 | 78.1 | − | − | 694 | 2183.4 | − | 75.9 | 45.2 | 67.0 / 70.7 | 55.1 | 61.1 | 72.7 | 40.6 | 43.3 |
| Claude-3 Opus [3] | ✗ | − | 89.3 | 80.8 | − | − | 694 | 1586.8 | 49.8 | 88.1 | 59.4 | 63.3 / 59.2 | 26.3 | 58.1 | − | 37.8 | 50.5 |
| Claude-3 Sonnet [3] | ✗ | − | 89.5 | 81.1 | − | − | 646 | 1625.9 | 51.9 | 88.7 | 53.1 | 67.8 / 64.2 | 27.8 | − | − | 41.3 | 47.9 |
| Claude-3 Haiku [3] | ✗ | − | 88.8 | 81.7 | − | − | 658 | 1453.2 | − | 86.7 | 50.2 | 60.7 / 57.2 | 24.5 | − | − | 39.2 | 46.4 |
| HPT Pro [35] | ✗ | − | − | − | − | − | − | − | − | − | 52.0 | 77.5 / 76.7 | − | − | 73.1 | − | − |
| MM1 [84] | ✗ | 30B | − | − | − | 73.5 | − | 2069.0 | − | − | 44.7 | 75.1 / − | − | 48.7 | 72.1 | − | 39.4 |
| Step-1V [102] | ✗ | 100B | − | − | − | − | 625 | 2206.4 | − | 79.2 | 49.9 | 80.7 / 79.9 | 71.2 | 63.3 | 70.3 | 48.4 | 44.8 |
| Grok-1.5V [125] | ✗ | − | 85.6 | 76.1 | − | 78.1 | − | − | 68.7 | 88.3 | − | − / − | − | − | − | − | 52.8 |
| Text-Monkey [68] | ✓ | 10B | 66.7 | 59.9 | 28.6 | 64.3 | 561 | − | − | − | − | − / − | − | − | − | − | − |
| DocOwl-1.5 [33] | ✓ | 8B | 82.2 | 70.2 | 50.7 | 68.6 | 599 | − | − | − | − | − / − | − | − | − | − | − |
| Mini-Gemini [53] | ✓ | 35B | − | − | − | 74.1* | − | 2141.0 | − | − | 48.0 | 80.6 / − | − | 59.3 | − | − | 43.3 |
| LLaVA-NeXT [64] | ✓ | 35B | 84.0 | 68.7 | 51.5 | 69.5* | 574 | 2028.0 | − | 74.9 | 51.1 | 81.1 / 79.0 | 49.2 | 57.4 | 75.9 | 34.8 | 46.5 |
| InternVL 1.2 (ours) | ✓ | 40B | 57.7 | 68.0 | 39.5 | 72.5* | 569 | 2175.4 | 67.5 | 79.0 | 51.6 | 82.2 / 81.2 | 59.2 | 48.9 | 75.6 | 47.6 | 47.7 |
| InternVL 1.5 (ours) | ✓ | 26B | 90.9 | 83.8 | 72.5 | 80.6 | 724 | 2187.8 | 66.0 | 80.7 | 45.2 | 82.2 / 82.0 | 69.8 | 62.8 | 76.0 | 49.3 | 53.5 |
表2:在 16 个多模式基准上与 SoTA 模型进行比较。 OCR 相关基准包括:DocVQA 测试 [82]、ChartQA 测试 [81]、InfographicVQA 测试 [83]、TextVQA val [100] 和 OCRBench [67]。 一般多模态基准包括:MME [26]、RealWorldQA [125]、AI2D 测试 [39]、MMMU val [135] 、MMBench-EN/CN 测试 [66]、CCBench 开发 [66]、MMVet [133]、SEED 图像 [46] 和 HallusionBench [30]。 此外,数学数据集包括 MathVista testmini [75]。 * 表示在 TextVQA 测试中使用 Rosetta OCR Token 。 我们报告的 MME 结果是感知和认知得分的总和。 OCRBench、MMBench、CCBench 和 HallusionBench 的结果来自 OpenCompass 排行榜[21]。
微调数据集。 在微调阶段,我们精心选择数据集,以提高模型在各种多模式任务中的性能。 表1(b)总结了本阶段使用的数据集。
对于图像字幕,我们添加了 TextCaps [99] 和双语 ShareGPT4V [16],这有助于模型学习生成英文和中文的描述性字幕。 在一般 QA 领域,VQAv2 [28]、GQA [34] 和 VisualDialog [22] 等数据集教导模型处理不同的问答场景。
对于科学图像理解,AI2D [39]、ScienceQA [73] 和 TQA [40] 等数据集提供内容丰富的场景来增强模型解释科学图表和文本的能力。 图表解释由 ChartQA [81]、MMC-Inst [61] 和 PlotQA [85] 提供支持,用于训练要分析的模型并理解图表图像。 GeoQA+ [12]、TabMWP [74] 和 MathQA [132] 等数学数据集引入了复杂的数值和几何问题解决任务。 基于知识的 QA 得益于 KVQA [96] 和双语维基百科 [31] 等数据集的包含,使模型能够跨多种语言提取事实信息并进行推理。
对于涉及 OCR 的任务,我们利用 OCRVQA [86]、TextVQA [100] 以及几个专注于中英文文本识别的数据集,例如 SynthDoG [41 ],提高图像中的文本识别能力。 通过 DocVQA [82] 和 Common Crawl PDF 等数据集,文档理解得到了提升,这有助于模型进行真实世界的文档分析。 使用 RefCOCO [131, 79] 和 Visual Genome [42] 训练视觉基础,帮助模型在图像中精确定位对象。 在多模态对话领域,LLaVA-150K [63] 和 ALLaVA [14] 等数据集通过模拟交互式和引人入胜的场景来增强模型的对话能力。 最后,纯文本数据集包括 OpenHermes2.5 [109]、Alpaca-GPT4 [106] 等 [6, 141],用于保持大语言模型原有的语言能力。
总之,这些数据集共同建立了丰富多样的微调基础,增强了我们的模型处理各种多模态任务的能力,并确保其为实际应用做好准备。
数据翻译管道。 如图5所示,为了增强模型的多语言能力,我们实现了数据翻译管道。 该管道利用最先进的开源大语言模型[11,4,130]或GPT-3.5将英语数据集转换为另一种语言(例如 ,中文),保持双语标注的一致性和准确性。 此外,它可以通过调整语言提示轻松扩展以涵盖更多语言,而无需依赖手动标注流程。
在表1中,我们注释了每个数据集的语言。 对于原本是英文的数据集,标注为“zh”表示我们已使用翻译管道将其翻译为中文。 例如,COYO [10]和GRIT [90]原本是英文数据集,我们已将它们翻译成中文。 通过利用这个翻译管道,InternVL 1.5的中文能力得到了极大的增强。
| open- | ConvBench (Pairwise Grading) | ConvBench (Direct Grading) | ||||||||||||
| model | source | #param | 𝑅1 | 𝑅2 | 𝑆1 | 𝑆2 | 𝑆3 | 𝑆𝑂 | 𝑅1 | 𝑅2 | 𝑆1 | 𝑆2 | 𝑆3 | 𝑆𝑂 |
| GPT-4V [1] | ✗ | − | 39.51 | 38.47 | 38.47 | 39.34 | 37.61 | 40.55 | 7.09 | 7.30 | 7.30 | 7.48 | 7.12 | 6.88 |
| Claude-3 Opus [3] | ✗ | − | 36.60 | 37.49 | 38.99 | 39.17 | 34.32 | 35.70 | 6.54 | 6.75 | 6.53 | 7.04 | 6.68 | 6.32 |
| Reka Flash [89] | ✗ | − | 25.60 | 24.67 | 25.13 | 27.56 | 21.32 | 26.52 | 6.78 | 6.86 | 6.93 | 7.25 | 6.41 | 6.70 |
| Gemini Pro 1.0 [107] | ✗ | − | 8.44 | 8.55 | 9.01 | 9.36 | 7.28 | 8.32 | 4.42 | 4.60 | 5.18 | 4.95 | 3.66 | 4.24 |
| ShareGPT4V-13B [16] | ✓ | 13B | 17.56 | 17.45 | 17.85 | 18.72 | 15.77 | 17.68 | 4.85 | 5.03 | 5.16 | 5.06 | 4.86 | 4.67 |
| LLaVA-1.5-13B [62] | ✓ | 13B | 16.93 | 18.08 | 20.45 | 18.02 | 15.77 | 15.77 | 4.94 | 5.14 | 5.03 | 5.41 | 4.99 | 4.74 |
| XComposer2 [23] | ✓ | 8B | 15.83 | 16.41 | 17.16 | 19.06 | 13.00 | 15.25 | 5.82 | 5.98 | 5.98 | 6.17 | 5.78 | 5.66 |
| mPLUG-Owl2 [128] | ✓ | 8B | 14.93 | 15.83 | 17.50 | 17.16 | 12.82 | 14.04 | 5.04 | 5.17 | 4.98 | 5.38 | 5.14 | 4.91 |
| Qwen-VL-Chat [5] | ✓ | 10B | 14.33 | 14.62 | 16.29 | 18.37 | 9.19 | 14.04 | 5.54 | 5.65 | 5.96 | 5.78 | 5.22 | 5.43 |
| MiniGPT-4 [142] | ✓ | 8B | 10.95 | 10.80 | 11.61 | 11.27 | 9.53 | 11.09 | 3.85 | 4.04 | 3.99 | 4.40 | 3.73 | 3.66 |
| LLaMA-A-V2 [27] | ✓ | 7B | 9.04 | 9.59 | 8.84 | 10.92 | 9.01 | 8.49 | 4.77 | 4.91 | 4.77 | 5.47 | 4.48 | 4.64 |
| InternVL 1.2 (ours) | ✓ | 40B | 21.17 | 22.41 | 24.96 | 21.31 | 20.97 | 19.93 | 5.49 | 5.69 | 5.80 | 5.88 | 5.39 | 5.29 |
| InternVL 1.5 (ours) | ✓ | 26B | 17.65 | 20.22 | 26.00 | 17.33 | 17.33 | 15.08 | 5.60 | 5.76 | 6.11 | 5.93 | 5.25 | 5.43 |
| open- | MMT-Bench | |||
| model | source | #param | Overall | Overall* |
| GPT-4V [1] | ✗ | − | 62.0 | 55.5 |
| Qwen-VL-Plus [4] | ✗ | − | 62.3 | 56.6 |
| Gemini Pro 1.0 [107] | ✗ | − | 61.6 | 55.1 |
| Claude-3 Haiku [3] | ✗ | − | 52.2 | 46.4 |
| LLaVA-NeXT [64] | ✓ | 35B | 60.8 | 56.3 |
| XComposer2 [23] | ✓ | 8B | 55.7 | 50.0 |
| BLIP-2-XXL [50] | ✓ | 12B | 54.8 | 49.1 |
| Yi-VL-34B [130] | ✓ | 35B | 54.2 | 48.6 |
| Monkey-Chat [107] | ✓ | 10B | 53.4 | 46.0 |
| DeepSeek-VL [71] | ✓ | 7B | 53.2 | 46.5 |
| CogVLM-Chat [117] | ✓ | 17B | 51.6 | 44.2 |
| InternVL 1.2 (ours) | ✓ | 40B | 63.4 | 58.2 |
| InternVL 1.5 (ours) | ✓ | 26B | 59.0 | 56.2 |
表3:与 ConvBench 和 MMT-Bench 上的 SoTA 模型进行比较。 ConvBench [65] 是专为 MLLM 设计的多轮对话评估基准。 该表显示了对人类的胜率,其中 𝑆1、𝑆2 和 𝑆3 分别代表感知、推理和创造的分数。 𝑅2 的计算方式为 (𝑆1+𝑆2+𝑆3)/3,反映了三轮的平均性能。 𝑅1源自(𝑅2+𝑆0)/2,表示模型的总体得分。 MMT-Bench [129] 是一个综合基准,旨在评估需要专业知识和深思熟虑的视觉识别、定位、推理和规划的大规模多模态任务中的 MLLM。 总分是根据 162 个子任务计算得出的,不包括用 * 表示的视觉识别。
4实验
4.1实施细节。
InternVL 1.5 是通过将 InternViT-6B [18] 视觉编码器与 InternLM2-20B [11] 语言模型集成而开发的,采用动态高分辨率策略。 在这种方法中,图像被分割成 448×448 像素图块,根据训练期间图像的长宽比和分辨率,图块数量最多可达 12 个。 在测试阶段,该模型可以处理多达 40 个图块,相当于 4K 分辨率,以零样本的方式展示了其对高分辨率输入的适应性。 值得注意的是,我们基于 InternLM2-20B 的聊天版本而不是基本模型构建了模型。
InternVL 1.5的训练分为两个阶段。 最初,预训练阶段的重点是训练 InternViT-6B 视觉编码器和 MLP 投影仪,以优化视觉特征提取。 随后,对整个模型的260亿个参数进行了微调,以增强多模态能力。 在训练的两个阶段中,我们都使用 4096 的上下文长度,并采用与 LLaVA 1.5 [52] 相同的响应格式提示。 此外,评估主要由VLMEvalKit [21]支持。
4.2与最先进的 MLLM 的比较
4.2.118 个基准的定量结果
在本节中,我们对一系列基准进行了广泛的评估,以评估我们模型的多模态理解和推理能力。 我们研究中使用的基准分为四种不同的类型:OCR 相关基准、通用多模态基准、数学基准和多轮对话基准。 如表 2 所示,InternVL 1.5 在大多数基准测试中都表现出领先的性能。
OCR相关的图像理解。 我们评估了 OCR 四个关键维度的模型性能:文档理解 (DocVQA [82])、图表理解 (ChartQA [81])、信息图表理解 (InfographicVQA [83])和场景文本解释(TextVQA [100])。 此外,我们使用 OCRBench [67] 对模型的整体 OCR 能力进行综合评估。 如表 2 所示,我们的模型在这些基准测试中表现出与专有模型相当的性能,并且显着优于开源 LLaVA-NeXT [64] 以及 InternVL 1.2, InternVL 1.5 的前身。 值得注意的是,我们的模型在 ChartQA 和 OCRBench 上实现了最先进的性能,优于所有竞争的专有模型。
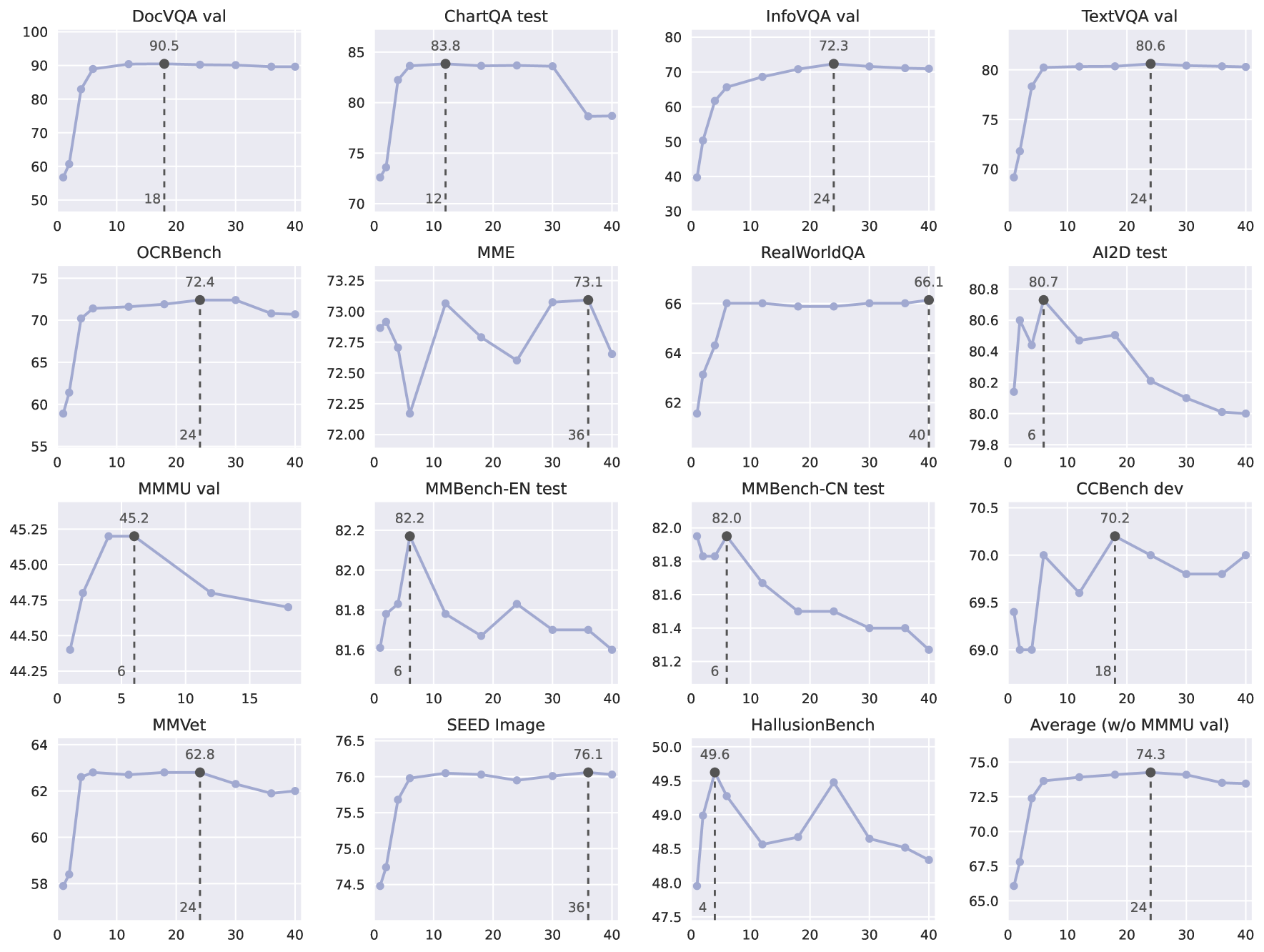
图6:不同图像分辨率下 InternVL 1.5 性能的比较。 X 轴表示图块数量,Y 轴表示基准性能。 最高值及其相应的图块数量会突出显示。 MME [26] 和 OCRBench [67] 的分数已标准化为最高分数 100。 我们发现,虽然训练期间只使用了 1 到 12 个图块,但在测试过程中可以将零样本扩展到 40 个图块(即,4K 分辨率)。 请注意,由于 MMMU [135] 每个样本包含多个图像,因此当图块数量很大时,它可能会耗尽内存。 因此,我们最多只测试了 18 个图块,并且在计算平均分数时不包括 MMMU。
一般多模式评估。 除了与 OCR 相关的基准之外,我们还在几个通用的多模式基准上测试了我们的模型。 我们使用 RealWorldQA [125] 来评估模型的现实世界空间理解能力。 HallusionBench [30] 用于评估其控制幻觉的能力。 此外,MMMU [135] 用于评估模型的多学科能力,AI2D [39] 用于评估其对科学图表的理解。 我们还分别通过MMBench-CN测试[66]和CCBench[66]测试了模型的中文熟练程度和对中国文化的理解。 其他综合基准测试如 MME [26]、MMBench-EN [66]、MMVet [133]、SEED [46] 和MMT-Bench[129]也被用来评估模型的视觉理解和推理能力。
与 Text-Monkey [68]、DocOwl-1.5 [33] 和 LLaVA-NeXT [64] 等其他开源模型相比,我们的 InternVL 1.5 在这些基准测试中显着缩小了与专有模型的差距。 具体来说,我们的模型在 HallusionBench [30] 上取得了最佳性能,展示了其出色的减少幻觉的能力。 此外,得益于我们高质量的双语数据集,我们的模型展现出了强大的中文能力,显着超越了 MMBench-CN 和 CCBench 上的开源和专有方法。 然而,虽然 InternVL 1.5 在 MMMU 上超越了 MM1 [84] 并与 Gemini Pro 1.0 [107] 相当,但与前身 InternVL 1.2 相比略有下降。 我们将这种适度的减少归因于语言模型规模较小,这在 MMT-Bench [129] 结果中也观察到了类似的现象,如表 3 所示。
数学推理。 MathVista [75] 是一个基准测试,旨在整合来自各种数学和视觉任务的挑战。 完成这些任务需要对视觉、逻辑思维和数学知识有深入的理解——许多专有商业模型在这些领域遇到了重大困难。 如表2所示,我们的模型在此基准测试中明显优于其他模型,包括 GPT-4V [87],展示了其处理数学要求高的任务的能力。
多轮对话。 与单轮对话相比,多轮对话更符合人类的偏好。 在实际使用中,多轮对话是通用助手与人类合作解决各种任务的首选模式。 因此,我们选择利用 ConvBench [65] 来评估多轮对话,逐步评估 MLLM 的感知、推理和创造力能力。 如表3所示,InternVL 在开源模型中表现出领先的性能,但仍然远远落后于 GPT-4V。 展望未来,我们将继续完善 InternVL 在多轮对话中的能力。
|
|

|
|

图7: 一般 QA 的示例。 蓝色突出显示出色的答案,而红色突出显示错误的答案。
4.3消融研究
更大的大语言模型需要更大的VFM。 在本研究中,我们研究了大语言模型和 VFM 之间的相互作用。 比较涉及两个开源MLLM,LLaVA-NeXT [64]和InternVL 1.2,每个都配备了340亿个参数的大语言模型。 值得注意的是,尽管两个模型都采用相同规模的大语言模型,但与 LLaVA-NeXT 的 3 亿个参数相比,InternVL 1.2 包含了更大的 VFM,具有 60 亿个参数。 由于 LLaVA-NeXT 的数据不可用,我们自己创建了一个类似的数据集。 此外,InternVL 1.2 以 448×448 的固定分辨率进行训练,而 LLaVA-NeXT 使用更高的动态分辨率 672×672。 因此,这种比较并不完全公平或等同。 尽管如此,研究结果仍然揭示了值得注意的见解。 例如,在排除 5 个与 OCR 相关的数据集、ConvBench 和 RealWorldQA 后,InternVL 1.2 在剩余 11 个数据集中的 9 个数据集中优于 LLaVA-NeXT。 这种性能差异支持了我们的假设,即对于大规模大语言模型(例如,34B),更大的VFM(例如,6B)可以有效提高模型的能力处理复杂的多模式任务,从而提高整体性能。
动态分辨率很重要。 如图6所示,我们研究了各种多模态基准中动态分辨率的有效性。 我们发现并非所有任务都需要高分辨率。 具体来说,与 OCR 相关的任务(例如 DocVQA、InfoVQA、TextVQA 和 OCRBench)受益于分辨率的提高。 然而,AI2D、MMMU、MMBench 和 HallusionBench 等任务在更高分辨率下表现出轻微下降。 总体而言,InternVL 1.5 对动态分辨率表现出很强的鲁棒性。 它可以根据每个任务的具体要求调整分辨率,确保在高分辨率有利的情况下实现最佳性能,在高分辨率不利的情况下节省资源。
4.3.1不同场景的定性结果
在前面的部分中,我们通过各种基准评估了我们的模型并观察了其强大的性能。 在本节中,我们在不同场景中对我们的模型与 GPT-4V [87] 进行定性比较,包括一般 QA、OCR 相关 QA、科学理解、中国传统文化、对象定位和多图像对话。 我们的目标是展示我们的模型在实际应用中的实用性和多功能性,从实际用户体验的角度提供见解。
一般质量检查。 为了比较 InternVL 1.5 和 GPT-4V 的一般功能,我们首先进行了一项实验,涉及简单的用户查询和需要一般知识的图像。 如图7左侧所示,两个模型都准确地响应了查询,展示了它们对一般主题的熟练程度。 如图7右侧所示,GPT-4V可能会因为涉及个人隐私而过度拒绝回答某些问题。
OCR 相关 QA。 我们进行了一项评估,将 InternVL 1.5 模型与 GPT-4V 的 OCR 功能进行比较。 图8左侧,第一个提示旨在衡量模型理解中文场景的能力。 在这种情况下,GPT-4V 无法提取图像中的所有有用信息。 在图8右侧,GPT-4V和我们的模型在图表理解上都具有良好的性能。
|
|

|
|
图8: OCR 相关 QA 示例。 蓝色突出显示出色的答案,而红色突出显示错误的答案。
|
|

|
|
图9: 科学理解的例子。 蓝色突出显示了杰出的答案。
|
|

|
|

图10:中国传统文化的范例。 蓝色突出显示了杰出的答案。
|
|

|
|

图11:对象本地化示例。 蓝色突出显示出色的答案,而红色突出显示错误的答案。
|
|

图12:多图像对话示例。 蓝色突出显示了杰出的答案。
科学理解。 评估模型在科学理解推理任务中的能力对于推进计算智能至关重要,特别是在需要领域内知识和逻辑推理的情况下。 在我们的研究中,我们通过管理复杂的多学科问题来比较 InternVL 1.5 模型与 GPT-4V 的性能,这些问题旨在评估其推理的准确性。 在图9中,对于第一个问题,两个模型都准确回答并从空气动力学角度进行了分析。 对于第二个问题,我们的模型精确分析了图像中描绘的元素并提供了正确的响应,而 GPT-4V 则推测了氨基酸转运的趋势。 这些结果表明我们的方法和 GPT-4V 在科学理解和推理方面表现出相当的能力。
中国传统文化。 我们选择了两个与中国传统艺术相关的典型多模态例子来评估我们的模型。 如图10所示,InternVL 1.5和GPT-4V都正确识别了图像中描绘的中国传统文化。 值得注意的是,InternVL 1.5 展示了对这种文化的更深入的理解,其响应中对文化元素的更详细描述就证明了这一点。
对象本地化。 评估机器学习模型在对象定位任务中的熟练程度至关重要,特别是在需要精确空间感知的应用中。 在我们的比较分析中,InternVL 1.5 模型的性能与 GPT-4V 并列,重点关注它们在各种环境中准确检测和定位物体的能力。 我们的评估范围从杂乱场景中的简单对象识别到涉及多个实体之间动态交互的复杂场景。 如图11所示,结果表明,InternVL 1.5不仅可以高精度定位目标,而且还表现出对空间关系的可比理解,与GPT-4V的性能相匹配。
多图像对话。 如图12所示,在本实验中,我们让InternVL 1.5和GPT-4V比较两幅图像的异同。 可以看出,GPT-4V 和 InternVL 1.5 都提供了详细且准确的响应。 通过这个实验,我们发现虽然InternVL 1.5仅在单图像输入上进行训练,但它在多图像对话方面表现出了强大的零样本能力。
5结论
这项工作引入了 InternVL 1.5,这是一种开源 MLLM,旨在缩小多模态理解中开源模型和专有模型之间的性能差距。 通过将强大的视觉编码器与持续学习功能相集成、采用动态高分辨率策略以及利用高质量的双语数据集,InternVL 1.5 在各种基准测试中展现了强大的性能。 我们的评估表明,该模型与领先的专有模型相比具有竞争优势,特别是在 OCR 相关任务中表现出色,并且在中文相关场景理解方面表现出显着改进。 虽然 InternVL 1.5 为开源多模式理解做出了贡献,但该领域仍在不断发展,面临着许多挑战。 我们渴望进一步增强 InternVL 的能力,并邀请与全球研究界的合作,希望共同丰富和扩大开源模型的影响范围。
参考
- Achiam et al. [2023]Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al.Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023.
- Alayrac et al. [2022]Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al.Flamingo: a visual language model for few-shot learning.NeurIPS, 35:23716–23736, 2022.
- Anthropic [2024]Anthropic.The claude 3 model family: Opus, sonnet, haiku.https://www.anthropic.com, 2024.
- Bai et al. [2023a]Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu.Qwen technical report.arXiv preprint arXiv:2309.16609, 2023a.
- Bai et al. [2023b]Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou.Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 2023b.
- Bai et al. [2024]Yuelin Bai, Xinrun Du, Yiming Liang, Yonggang Jin, Ziqiang Liu, Junting Zhou, Tianyu Zheng, Xincheng Zhang, Nuo Ma, Zekun Wang, et al.Coig-cqia: Quality is all you need for chinese instruction fine-tuning.arXiv preprint arXiv:2403.18058, 2024.
- Baichuan [2023]Baichuan.Baichuan 2: Open large-scale language models.arXiv preprint arXiv:2309.10305, 2023.
- Bi et al. [2024]Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al.Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024.
- Biten et al. [2019]Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas.Scene text visual question answering.In ICCV, pages 4291–4301, 2019.
- Byeon et al. [2022]Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim.Coyo-700m: Image-text pair dataset, 2022.
- Cai et al. [2024]Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al.Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024.
- Cao and Xiao [2022]Jie Cao and Jing Xiao.An augmented benchmark dataset for geometric question answering through dual parallel text encoding.In COLING, pages 1511–1520, 2022.
- Chen et al. [2023a]Guo Chen, Yin-Dong Zheng, Jiahao Wang, Jilan Xu, Yifei Huang, Junting Pan, Yi Wang, Yali Wang, Yu Qiao, Tong Lu, et al.Videollm: Modeling video sequence with large language models.arXiv preprint arXiv:2305.13292, 2023a.
- Chen et al. [2024]Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang.Allava: Harnessing gpt4v-synthesized data for a lite vision-language model.arXiv preprint arXiv:2402.11684, 2024.
- Chen et al. [2023b]Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao.Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195, 2023b.
- Chen et al. [2023c]Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin.Sharegpt4v: Improving large multi-modal models with better captions.arXiv preprint arXiv:2311.12793, 2023c.
- Chen et al. [2015]Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick.Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015.
- Chen et al. [2023d]Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Zhong Muyan, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al.Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238, 2023d.
- Chng et al. [2019]Chee Kheng Chng, Yuliang Liu, Yipeng Sun, Chun Chet Ng, Canjie Luo, Zihan Ni, ChuanMing Fang, Shuaitao Zhang, Junyu Han, Errui Ding, et al.Icdar2019 robust reading challenge on arbitrary-shaped text-rrc-art.In ICDAR, pages 1571–1576, 2019.
- Clark and Gardner [2018]Christopher Clark and Matt Gardner.Simple and effective multi-paragraph reading comprehension.In ACL, pages 845–855, 2018.
- Contributors [2023]OpenCompass Contributors.Opencompass: A universal evaluation platform for foundation models.GitHub - open-compass/opencompass: OpenCompass is an LLM evaluation platform, supporting a wide range of models (Llama3, Mistral, InternLM2,GPT-4,LLaMa2, Qwen,GLM, Claude, etc) over 100+ datasets., 2023.
- Das et al. [2017]Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra.Visual dialog.In CVPR, pages 326–335, 2017.
- Dong et al. [2024a]Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, et al.Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model.arXiv preprint arXiv:2401.16420, 2024a.
- Dong et al. [2024b]Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, et al.Internlm-xcomposer2-4khd: A pioneering large vision-language model handling resolutions from 336 pixels to 4k hd.arXiv preprint arXiv:2404.06512, 2024b.
- Du et al. [2022]Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang.Glm: General language model pretraining with autoregressive blank infilling.In ACL, pages 320–335, 2022.
- Fu et al. [2023]Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, et al.Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023.
- Gao et al. [2023]Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al.Llama-adapter v2: Parameter-efficient visual instruction model.arXiv preprint arXiv:2304.15010, 2023.
- Goyal et al. [2017]Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh.Making the v in vqa matter: Elevating the role of image understanding in visual question answering.In CVPR, pages 6904–6913, 2017.
- Gu et al. [2022]Jiaxi Gu, Xiaojun Meng, Guansong Lu, Lu Hou, Niu Minzhe, Xiaodan Liang, Lewei Yao, Runhui Huang, Wei Zhang, Xin Jiang, et al.Wukong: A 100 million large-scale chinese cross-modal pre-training benchmark.NeurIPS, 35:26418–26431, 2022.
- Guan et al. [2023]Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al.Hallusionbench: An advanced diagnostic suite for entangled language hallucination & visual illusion in large vision-language models.arXiv preprint arXiv:2310.14566, 2023.
- He et al. [2023]Conghui He, Zhenjiang Jin, Chao Xu, Jiantao Qiu, Bin Wang, Wei Li, Hang Yan, Jiaqi Wang, and Dahua Lin.Wanjuan: A comprehensive multimodal dataset for advancing english and chinese large models.arXiv preprint arXiv:2308.10755, 2023.
- Hong et al. [2023]Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al.Cogagent: A visual language model for gui agents.arXiv preprint arXiv:2312.08914, 2023.
- Hu et al. [2024]Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, et al.mplug-docowl 1.5: Unified structure learning for ocr-free document understanding.arXiv preprint arXiv:2403.12895, 2024.
- Hudson and Manning [2019]Drew A Hudson and Christopher D Manning.Gqa: A new dataset for real-world visual reasoning and compositional question answering.In CVPR, pages 6700–6709, 2019.
- HyperGAI Research Team [2024]HyperGAI Research Team.Introducing hpt: A family of leading multimodal llms.https://www.hypergai.com/blog/introducing-hpt-a-family-of-leading-multimodal-llms, 2024.
- Ilharco et al. [2021]Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt.Openclip.Zenodo. Version 0.1. OpenCLIP, 2021.DOI: 10.5281/zenodo.5143773.
- Jimmycarter [2023]Jimmycarter.Textocr gpt-4v dataset.https://huggingface.co/datasets/jimmycarter/textocr-gpt4v, 2023.
- Kafle et al. [2018]Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan.Dvqa: Understanding data visualizations via question answering.In CVPR, pages 5648–5656, 2018.
- Kembhavi et al. [2016]Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi.A diagram is worth a dozen images.In ECCV, pages 235–251, 2016.
- Kembhavi et al. [2017]Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi.Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension.In CVPR, pages 4999–5007, 2017.
- Kim et al. [2022]Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park.Ocr-free document understanding transformer.In ECCV, 2022.
- Krishna et al. [2017]Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al.Visual genome: Connecting language and vision using crowdsourced dense image annotations.IJCV, 123:32–73, 2017.
- Lai et al. [2023]Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia.Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692, 2023.
- LAION [2023]LAION.Gpt-4v dataset.https://huggingface.co/datasets/laion/gpt4v-dataset, 2023.
- Lerner et al. [2022]Paul Lerner, Olivier Ferret, Camille Guinaudeau, Hervé Le Borgne, Romaric Besançon, José G Moreno, and Jesús Lovón Melgarejo.Viquae, a dataset for knowledge-based visual question answering about named entities.In SIGIR, pages 3108–3120, 2022.
- Li et al. [2023a]Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan.Seed-bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023a.
- Li et al. [2023b]Bo Li, Peiyuan Zhang, Jingkang Yang, Yuanhan Zhang, Fanyi Pu, and Ziwei Liu.Otterhd: A high-resolution multi-modality model.arXiv preprint arXiv:2311.04219, 2023b.
- Li et al. [2023c]Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu.Otter: A multi-modal model with in-context instruction tuning.arXiv preprint arXiv:2305.03726, 2023c.
- Li et al. [2022a]Chenxia Li, Weiwei Liu, Ruoyu Guo, Xiaoting Yin, Kaitao Jiang, Yongkun Du, Yuning Du, Lingfeng Zhu, Baohua Lai, Xiaoguang Hu, et al.Pp-ocrv3: More attempts for the improvement of ultra lightweight ocr system.arXiv preprint arXiv:2206.03001, 2022a.
- Li et al. [2023d]Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi.Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.In ICML, pages 19730–19742. PMLR, 2023d.
- Li et al. [2023e]KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao.Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023e.
- Li et al. [2022b]Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer.Mvitv2: Improved multiscale vision transformers for classification and detection.In CVPR, pages 4804–4814, 2022b.
- Li et al. [2024]Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia.Mini-gemini: Mining the potential of multi-modality vision language models.arXiv preprint arXiv:2403.18814, 2024.
- Li et al. [2023f]Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille.Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning.In CVPR, pages 14963–14973, 2023f.
- Li et al. [2023g]Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, and Xiang Bai.Monkey: Image resolution and text label are important things for large multi-modal models.arXiv preprint arXiv:2311.06607, 2023g.
- Lin et al. [2024]Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Junwu Zhang, Munan Ning, and Li Yuan.Moe-llava: Mixture of experts for large vision-language models.arXiv preprint arXiv:2401.15947, 2024.
- Lin et al. [2023]Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al.Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models.arXiv preprint arXiv:2311.07575, 2023.
- Lindström and Abraham [2022]Adam Dahlgren Lindström and Savitha Sam Abraham.Clevr-math: A dataset for compositional language, visual and mathematical reasoning.arXiv preprint arXiv:2208.05358, 2022.
- Liu et al. [2023a]Fangyu Liu, Guy Emerson, and Nigel Collier.Visual spatial reasoning.TACL, 11:635–651, 2023a.
- Liu et al. [2023b]Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang.Aligning large multi-modal model with robust instruction tuning.arXiv preprint arXiv:2306.14565, 2023b.
- Liu et al. [2023c]Fuxiao Liu, Xiaoyang Wang, Wenlin Yao, Jianshu Chen, Kaiqiang Song, Sangwoo Cho, Yaser Yacoob, and Dong Yu.Mmc: Advancing multimodal chart understanding with large-scale instruction tuning.arXiv preprint arXiv:2311.10774, 2023c.
- Liu et al. [2023d]Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee.Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744, 2023d.
- Liu et al. [2023e]Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee.Visual instruction tuning.NeurIPS, 36, 2023e.
- Liu et al. [2024a]Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee.Llava-next: Improved reasoning, ocr, and world knowledge, 2024a.
- Liu et al. [2024b]Shuo Liu, Kaining Ying, Hao Zhang, Yue Yang, Yuqi Lin, Tianle Zhang, Chuanhao Li, Yu Qiao, Ping Luo, Wenqi Shao, et al.Convbench: A multi-turn conversation evaluation benchmark with hierarchical capability for large vision-language models.arXiv preprint arXiv:2403.20194, 2024b.
- Liu et al. [2023f]Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al.Mmbench: Is your multi-modal model an all-around player?arXiv preprint arXiv:2307.06281, 2023f.
- Liu et al. [2023g]Yuliang Liu, Zhang Li, Hongliang Li, Wenwen Yu, Mingxin Huang, Dezhi Peng, Mingyu Liu, Mingrui Chen, Chunyuan Li, Lianwen Jin, et al.On the hidden mystery of ocr in large multimodal models.arXiv preprint arXiv:2305.07895, 2023g.
- Liu et al. [2024c]Yuliang Liu, Biao Yang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, and Xiang Bai.Textmonkey: An ocr-free large multimodal model for understanding document.arXiv preprint arXiv:2403.04473, 2024c.
- Liu et al. [2023h]Zhaoyang Liu, Yinan He, Wenhai Wang, Weiyun Wang, Yi Wang, Shoufa Chen, Qinglong Zhang, Zeqiang Lai, Yang Yang, Qingyun Li, Jiashuo Yu, et al.Interngpt: Solving vision-centric tasks by interacting with chatgpt beyond language.arXiv preprint arXiv:2305.05662, 2023h.
- Liu et al. [2023i]Zhaoyang Liu, Zeqiang Lai, Zhangwei Gao, Erfei Cui, Xizhou Zhu, Lewei Lu, Qifeng Chen, Yu Qiao, Jifeng Dai, and Wenhai Wang.Controlllm: Augment language models with tools by searching on graphs.arXiv preprint arXiv:2310.17796, 2023i.
- Lu et al. [2024]Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al.Deepseek-vl: Towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024.
- Lu et al. [2021]Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu.Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning.arXiv preprint arXiv:2105.04165, 2021.
- Lu et al. [2022a]Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan.Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS, 35:2507–2521, 2022a.
- Lu et al. [2022b]Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan.Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning.arXiv preprint arXiv:2209.14610, 2022b.
- Lu et al. [2023]Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao.Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023.
- Luo et al. [2024]Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xiaoshuai Sun, and Rongrong Ji.Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models.arXiv preprint arXiv:2403.03003, 2024.
- Lv et al. [2023]Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, et al.Kosmos-2.5: A multimodal literate model.arXiv preprint arXiv:2309.11419, 2023.
- Ma et al. [2024]Chuofan Ma, Yi Jiang, Jiannan Wu, Zehuan Yuan, and Xiaojuan Qi.Groma: Localized visual tokenization for grounding multimodal large language models.arXiv preprint arXiv:2404.13013, 2024.
- Mao et al. [2016]Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy.Generation and comprehension of unambiguous object descriptions.In CVPR, pages 11–20, 2016.
- Marino et al. [2019]Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi.Ok-vqa: A visual question answering benchmark requiring external knowledge.In CVPR, pages 3195–3204, 2019.
- Masry et al. [2022]Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque.Chartqa: A benchmark for question answering about charts with visual and logical reasoning.In ACL, pages 2263–2279, 2022.
- Mathew et al. [2021]Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar.Docvqa: A dataset for vqa on document images.In WACV, pages 2200–2209, 2021.
- Mathew et al. [2022]Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar.Infographicvqa.In WACV, pages 1697–1706, 2022.
- McKinzie et al. [2024]Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, et al.Mm1: Methods, analysis & insights from multimodal llm pre-training.arXiv preprint arXiv:2403.09611, 2024.
- Methani et al. [2020]Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar.Plotqa: Reasoning over scientific plots.In WACV, pages 1527–1536, 2020.
- Mishra et al. [2019]Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty.Ocr-vqa: Visual question answering by reading text in images.In ICDAR, pages 947–952, 2019.
- OpenAI [2023]OpenAI.Gpt-4v(ision) system card.https://cdn.openai.com/papers/GPTV_System_Card.pdf, 2023.
- Oquab et al. [2023]Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al.Dinov2: Learning robust visual features without supervision.TMLR, 2023.
- Ormazabal et al. [2024]Aitor Ormazabal, Che Zheng, Cyprien de Masson d’Autume, Dani Yogatama, Deyu Fu, Donovan Ong, Eric Chen, Eugenie Lamprecht, Hai Pham, Isaac Ong, et al.Reka core, flash, and edge: A series of powerful multimodal language models.arXiv preprint arXiv:2404.12387, 2024.
- Peng et al. [2023]Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei.Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023.
- Radford et al. [2021]Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al.Learning transferable visual models from natural language supervision.In ICML, pages 8748–8763, 2021.
- Reid et al. [2024]Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al.Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024.
- Schuhmann et al. [2022a]Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al.Laion-5b: An open large-scale dataset for training next generation image-text models.NeurIPS, 35:25278–25294, 2022a.
- Schuhmann et al. [2022b]Christoph Schuhmann, Andreas Köpf, Richard Vencu, Theo Coombes, and Romain Beaumont.Laion coco: 600m synthetic captions from laion2b-en.https://laion.ai/blog/laion-coco/, 2022b.
- Schwenk et al. [2022]Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi.A-okvqa: A benchmark for visual question answering using world knowledge.In ECCV, pages 146–162, 2022.
- Shah et al. [2019]Sanket Shah, Anand Mishra, Naganand Yadati, and Partha Pratim Talukdar.Kvqa: Knowledge-aware visual question answering.In AAAI, pages 8876–8884, 2019.
- Shao et al. [2019]Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun.Objects365: A large-scale, high-quality dataset for object detection.In ICCV, pages 8430–8439, 2019.
- Shi et al. [2017]Baoguang Shi, Cong Yao, Minghui Liao, Mingkun Yang, Pei Xu, Linyan Cui, Serge Belongie, Shijian Lu, and Xiang Bai.Icdar2017 competition on reading chinese text in the wild (rctw-17).In ICDAR, pages 1429–1434, 2017.
- Sidorov et al. [2020]Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh.Textcaps: a dataset for image captioning with reading comprehension.In ECCV, pages 742–758, 2020.
- Singh et al. [2019]Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach.Towards vqa models that can read.In CVPR, pages 8317–8326, 2019.
- Singh et al. [2021]Amanpreet Singh, Guan Pang, Mandy Toh, Jing Huang, Wojciech Galuba, and Tal Hassner.Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text.In CVPR, pages 8802–8812, 2021.
- StepFun Research Team [2024]StepFun Research Team.Step-1v: A hundred billion parameter multimodal large model.https://platform.stepfun.com, 2024.
- Sun et al. [2024]Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang.Generative pretraining in multimodality.In ICLR, 2024.
- Sun et al. [2023]Tianxiang Sun, Xiaotian Zhang, Zhengfu He, Peng Li, Qinyuan Cheng, Hang Yan, Xiangyang Liu, Yunfan Shao, Qiong Tang, Xingjian Zhao, et al.Moss: Training conversational language models from synthetic data.arXiv preprint arXiv:2307.15020, 7, 2023.
- Sun et al. [2019]Yipeng Sun, Zihan Ni, Chee-Kheng Chng, Yuliang Liu, Canjie Luo, Chun Chet Ng, Junyu Han, Errui Ding, Jingtuo Liu, Dimosthenis Karatzas, et al.Icdar 2019 competition on large-scale street view text with partial labeling-rrc-lsvt.In ICDAR, pages 1557–1562, 2019.
- Taori et al. [2023]Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto.Alpaca: A strong, replicable instruction-following model.Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7, 2023.
- Team et al. [2023]Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al.Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023.
- Team [2023]InternLM Team.Internlm: A multilingual language model with progressively enhanced capabilities.GitHub - InternLM/InternLM: Official release of InternLM2.5 7B base and chat models. 1M context support, 2023.
- Teknium [2023]Teknium.Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants.https://huggingface.co/datasets/teknium/OpenHermes-2.5, 2023.
- Tian et al. [2024]Changyao Tian, Xizhou Zhu, Yuwen Xiong, Weiyun Wang, Zhe Chen, Wenhai Wang, Yuntao Chen, Lewei Lu, Tong Lu, Jie Zhou, et al.Mm-interleaved: Interleaved image-text generative modeling via multi-modal feature synchronizer.arXiv preprint arXiv:2401.10208, 2024.
- Tong et al. [2024]Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie.Eyes wide shut? exploring the visual shortcomings of multimodal llms.arXiv preprint arXiv:2401.06209, 2024.
- Touvron et al. [2023a]Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al.Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. [2023b]Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al.Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023b.
- Veit et al. [2016]Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, and Serge Belongie.Coco-text: Dataset and benchmark for text detection and recognition in natural images.arXiv preprint arXiv:1601.07140, 2016.
- Wang et al. [2023a]Junke Wang, Lingchen Meng, Zejia Weng, Bo He, Zuxuan Wu, and Yu-Gang Jiang.To see is to believe: Prompting gpt-4v for better visual instruction tuning.arXiv preprint arXiv:2311.07574, 2023a.
- Wang et al. [2023b]Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al.Visionllm: Large language model is also an open-ended decoder for vision-centric tasks.NeurIPS, 36, 2023b.
- Wang et al. [2023c]Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al.Cogvlm: Visual expert for pretrained language models.arXiv preprint arXiv:2311.03079, 2023c.
- Wang et al. [2024a]Weiyun Wang, Yiming Ren, Haowen Luo, Tiantong Li, Chenxiang Yan, Zhe Chen, Wenhai Wang, Qingyun Li, Lewei Lu, Xizhou Zhu, et al.The all-seeing project v2: Towards general relation comprehension of the open world.arXiv preprint arXiv:2402.19474, 2024a.
- Wang et al. [2024b]Weiyun Wang, Min Shi, Qingyun Li, Wenhai Wang, Zhenhang Huang, Linjie Xing, Zhe Chen, Hao Li, Xizhou Zhu, Zhiguo Cao, et al.The all-seeing project: Towards panoptic visual recognition and understanding of the open world.In ICLR, 2024b.
- Wang et al. [2024c]Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, et al.Internvideo2: Scaling video foundation models for multimodal video understanding.arXiv preprint arXiv:2403.15377, 2024c.
- Wei et al. [2023a]Haoran Wei, Lingyu Kong, Jinyue Chen, Liang Zhao, Zheng Ge, Jinrong Yang, Jianjian Sun, Chunrui Han, and Xiangyu Zhang.Vary: Scaling up the vision vocabulary for large vision-language models.arXiv preprint arXiv:2312.06109, 2023a.
- Wei et al. [2022]Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al.Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 35:24824–24837, 2022.
- Wei et al. [2023b]Tianwen Wei, Liang Zhao, Lichang Zhang, Bo Zhu, Lijie Wang, Haihua Yang, Biye Li, Cheng Cheng, Weiwei Lü, Rui Hu, et al.Skywork: A more open bilingual foundation model.arXiv preprint arXiv:2310.19341, 2023b.
- Wu et al. [2023]Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua.Next-gpt: Any-to-any multimodal llm.arXiv preprint arXiv:2309.05519, 2023.
- X.ai [2024]X.ai.Grok-1.5 vision preview.Grok-1.5 Vision Preview, 2024.
- Xu et al. [2024]Ruyi Xu, Yuan Yao, Zonghao Guo, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, Maosong Sun, and Gao Huang.Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images.arXiv preprint arXiv:2403.11703, 2024.
- Ye et al. [2023a]Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, et al.Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model.arXiv preprint arXiv:2310.05126, 2023a.
- Ye et al. [2023b]Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou.mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration.arXiv preprint arXiv:2311.04257, 2023b.
- Ying et al. [2024]Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, Jiayi Lei, Quanfeng Lu, Runjian Chen, Peng Xu, Renrui Zhang, Haozhe Zhang, Peng Gao, Yali Wang, Yu Qiao, Ping Luo, Kaipeng Zhang, and Wenqi Shao.Mmt-bench: A comprehensive multimodal benchmark for evaluating large vision-language models towards multitask agi.arXiv preprint arXiv:2404.16006, 2024.
- Young et al. [2024]Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, et al.Yi: Open foundation models by 01. ai.arXiv preprint arXiv:2403.04652, 2024.
- Yu et al. [2016]Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg.Modeling context in referring expressions.In ECCV, pages 69–85, 2016.
- Yu et al. [2023a]Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu.Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284, 2023a.
- Yu et al. [2023b]Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang.Mm-vet: Evaluating large multimodal models for integrated capabilities.arXiv preprint arXiv:2308.02490, 2023b.
- Yuan et al. [2019]Tai-Ling Yuan, Zhe Zhu, Kun Xu, Cheng-Jun Li, Tai-Jiang Mu, and Shi-Min Hu.A large chinese text dataset in the wild.Journal of Computer Science and Technology, 34:509–521, 2019.
- Yue et al. [2023]Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al.Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi.arXiv preprint arXiv:2311.16502, 2023.
- Zhai et al. [2023]Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer.Sigmoid loss for language image pre-training.In ICCV, pages 11975–11986, 2023.
- Zhang et al. [2019]Rui Zhang, Yongsheng Zhou, Qianyi Jiang, Qi Song, Nan Li, Kai Zhou, Lei Wang, Dong Wang, Minghui Liao, Mingkun Yang, et al.Icdar 2019 robust reading challenge on reading chinese text on signboard.In ICDAR, pages 1577–1581, 2019.
- Zhang et al. [2024]Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao.Llama-adapter: Efficient fine-tuning of language models with zero-init attention.In ICLR, 2024.
- Zhang et al. [2023]Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Kai Chen, and Ping Luo.Gpt4roi: Instruction tuning large language model on region-of-interest.arXiv preprint arXiv:2307.03601, 2023.
- Zhao et al. [2023]Bo Zhao, Boya Wu, and Tiejun Huang.Svit: Scaling up visual instruction tuning.arXiv preprint arXiv:2307.04087, 2023.
- Zheng et al. [2024]Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al.Judging llm-as-a-judge with mt-bench and chatbot arena.NeurIPS, 36, 2024.
- Zhu et al. [2024]Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny.Minigpt-4: Enhancing vision-language understanding with advanced large language models.In ICLR, 2024.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











