




万字长文详解AI集群基础设施InfiniBand
以下文章来源于吃果冻不吐果冻皮 ,作者吃果冻不吐果冻皮
详解AI集群通信软硬件。
GPU在高性能计算和深度学习加速中扮演着非常重要的角色,GPU的强大的并行计算能力,大大提升了运算性能。随着运算数据量的不断攀升,GPU间需要大量的交换数据,因此,GPU通信性能成为了非常重要的指标。
在AI集群中进行分布式训练时,通信是必要环节,同时也是相比于单机训练而言多出来的系统开销。通信与计算的时间比例往往决定了分布式机器学习系统加速比的上限。
因此,分布式机器学习的关键是设计通信机制,从而降低通信与计算的时间比例,更加高效地训练出高精度模型。
下面给大家介绍AI集群通信的软硬件、NCLL集合通信库、InfiniBand网络通信技术协议、AI集群和AI框架中对于InfiniBand的应用。
作者撰写的大模型相关的博客及配套代码均整理放置在Github:llm-action,有需要的朋友自取。
01.
通信硬件
1、通信硬件的实现方式
通信的实现方式分为两种类型:机器内通信与机器间通信。
机器内通信:
-
共享内存(QPI/UPI),比如:CPU与CPU之间的通信可以通过共享内存。
-
PCIe,通常是CPU与GPU之间的通信。
-
NVLink,通常是GPU与GPU之间的通信,也可以用于CPU与GPU之间的通信。
机器间通信:
-
TCP/IP 网络协议。
-
RDMA (Remote Direct Memory Access) 网络协议。
-
InfiniBand
-
iWARP
-
RoCE
-
2、PCIe
PCI-Express(peripheral component interconnect express),简称PCIe,是一种高速串行计算机扩展总线标准,主要用于扩充计算机系统总线数据吞吐量以及提高设备通信速度。
PCIe本质上是一种全双工的的连接总线,传输数据量的大小由通道数(lane,信道)决定的。
通常,1个连接通道lane称为X1,每个通道lane由两对数据线组成,一对发送,一对接收,每对数据线包含两根差分线。即X1只有1个lane,4根数据线,每个时钟每个方向1bit数据传输。依此类推,X2就有2个lane,由8根数据线组成,每个时钟传输2bit。类似的还有X12、X16、X32。
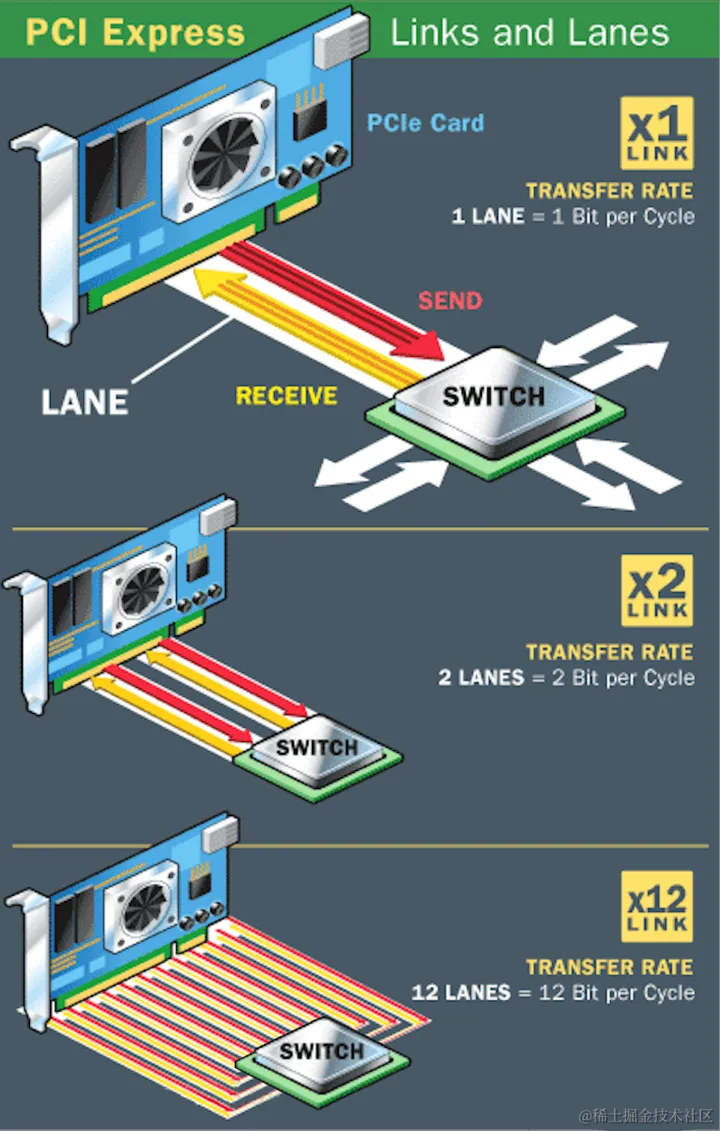
image.png
2003年PCIe 1.0正式发布,可支持每通道传输速率为250MB/s,总传输速率为 2.5GT/s。
2007年推出PCIe 2.0规范。在PCIe 1.0的基础上将总传输速率提高了1倍,达到5 GT/s,每通道传输速率从250MB/s上升至500MB/s。
2022年PCIe 6.0规范正式发布,总传输速率提高至64GT/s。
2022年6月,PCI-SIG联盟宣布PCIe 7.0版规范,单条通道(x1)单向可实现128GT/s 传输速率,计划于2025年推出最终版本。
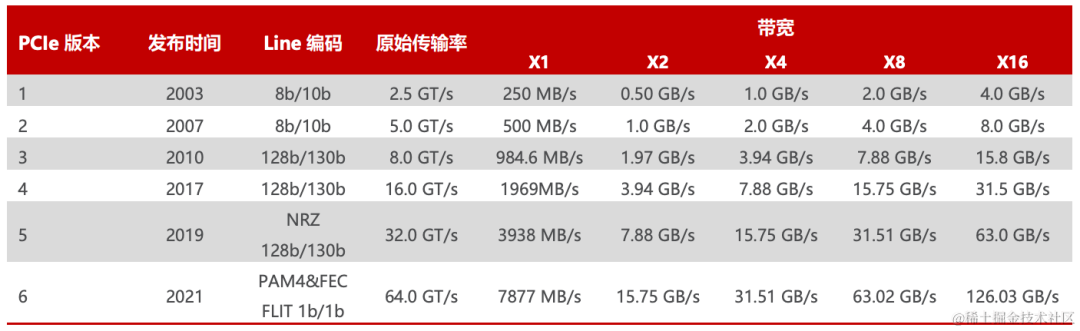
image.png
PCIe吞吐量(可用带宽)计算方法:
吞吐量=传输速率*编码方案
传输速率为每秒传输量(GT/s),而不是每秒位数(Gbps),是因为传输量包括不提供额外吞吐量的开销位,比如:PCIe 1x和PCIe 2x使用8b/10b编码方案,导致占用了20%(=2/10)的原始信道带宽。
-
GT/s,Giga transtion per second(千兆传输/秒),即每一秒内传输的次数,重点在于描述物理层通信协议的速率属性,可以不和链路宽度等关联。
-
Gbps,Giga Bits per second(千兆位/秒)。GT/s和Gbps之间不存在成比例的换算关系。
PCIe 2.0协议支持5.0GT/s,即每一条Lane上支持每秒钟传输5G个Bit,但这并不意味着PCIe 2.0协议的每一条Lane支持5Gbps的速率。为什么这么说呢,因为PCIe 2.0的物理层协议中使用的是8b/10b编码方案,即每传输8个Bit,需要发送10个Bit,这多出来的2Bit并不是对上层有意义的信息。那么,PCIe 2.0协议的每一条Lane支持5*8/10=4Gbps=500MB/s的速率。以一个PCIe 2.0 x8的通道为例,x8的可用带宽为4*8=32Gbps=4GB/s。
同理,PCIe 3.0协议支持8.0GT/s,即每一条Lane上支持每秒钟传输8G个Bit。而PCIe 3.0的物理层协议中使用的是128b/130b编码方案,即每传输128个Bit,需要发送130个Bit,那么,PCIe 3.0协议的每一条Lane支持8*128/130=7.877GB/s=984.6MB/s的速率。以一个PCIe 3.0 x16的通道为例,x16的可用带宽为7.877*16=126.032 Gbps=15.754GB/s。
PCIE体系架构:
PCIE体系架构一般包含根组件RC(root-complex),交换器switch,终端设备EP(endpoint)等类型的PCIE设备组成。RC在总线架构中只有一个,用于处理器和内存子系统与I/O设备之间的连接,而switch的功能通常是以软件形式提供的,它包括两个或更多的逻辑PCI到PCI的连接桥(PCI-PCI Bridge),以保持与现有PCI兼容。
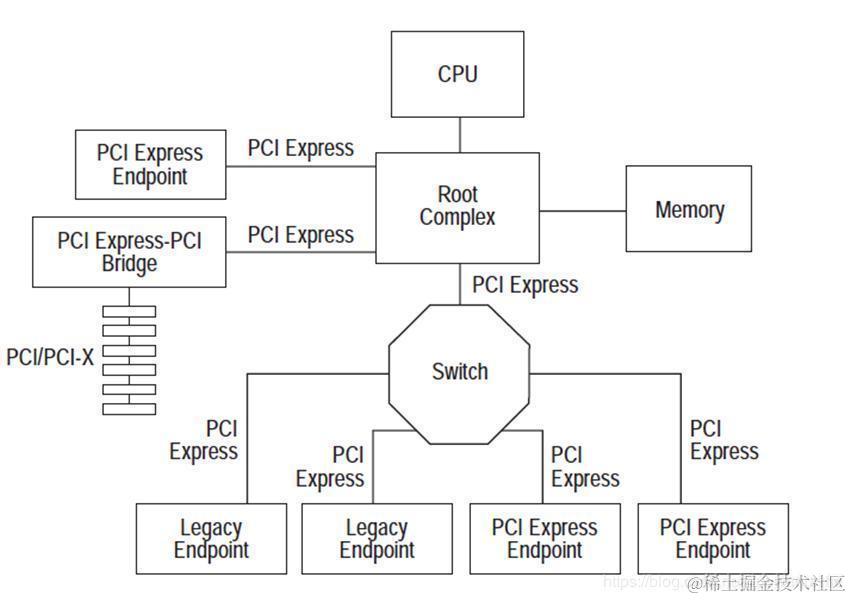
image.png
3、NVLink
背景:
算力的提升不仅依靠单张GPU卡的性能提升,往往还需要多GPU卡组合。在多 GPU 系统内部,GPU间通信的带宽通常在数百GB/s以上,PCIe总线的数据传输速率容易成为瓶颈,且PCIe链路接口的串并转换会产生较大延时,影响GPU并行计算的效率和性能。
GPU发出的信号需要先传递到PCIe Switch, PCIe Switch中涉及到数据的处理,CPU会对数据进行分发调度,这些都会引入额外的网络延迟,限制了系统性能。

image.png
为此,NVIDIA推出了能够提升GPU通信性能的技术——GPUDirect P2P技术,使GPU可以通过 PCI Express 直接访问目标GPU的显存,避免了通过拷贝到CPU host memory作为中转,大大降低了数据交换的延迟,但受限于PCI Express总线协议以及拓扑结构的一些限制,无法做到更高的带宽。此后,NVIDIA提出了 NVLink 总线协议。
NVLink简介:
NVLink是一种高速互连技术,旨在加快CPU 与 GPU、GPU与GPU之间的数据传输速度,提高系统性能。NVLink通过GPU之间的直接互联,可扩展服务器内的多GPU I/O,相较于传统PCIe总线可提供更高效、低延迟的互联解决方案。
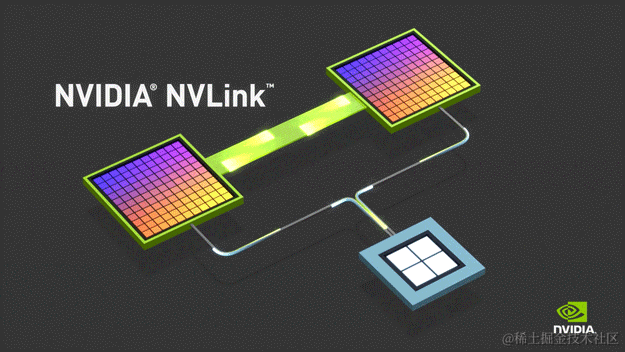
image.png
NVLink的首个版本于2014年发布,首次引入了高速GPU互连。2016年发布的P100搭载了第一代NVLink,提供160GB/s的带宽,相当于当时PCIe 3.0 x16带宽(双向)的5倍。之后陆续发布了很多新版本,V100搭载的NVLink 2将带宽提升到300GB/s ,A100搭载了NVLink3带宽为600GB/s。H100中包含18条第四代NVLink链路,总带宽(双向)达到900GB/s,是PCIe 5.0 x16带宽(双向)的7倍。
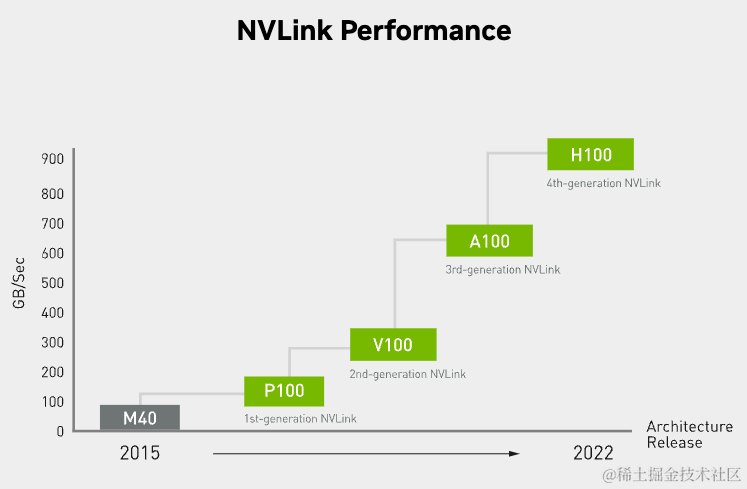
image.png

image.png
NVLink高速互联主要有两种:
-
第一种是以桥接器的形式实现。
-
另一种是在主板上集成
NVLink接口。

image.png
4、NVSwitch
为了解决GPU之间通讯不均衡问题,NVIDIA引入NVSwitch。NVSwitch芯片是一种类似交换机的物理芯片(ASIC),通过NVLink接口可以将多个GPU高速互联到一起,可创建无缝、高带宽的多节点GPU集群,实现所有GPU在一个具有全带宽连接的集群中协同工作,从而提升服务器内部多个GPU之间的通讯效率和带宽。NVLink和NVSwitch的结合使NVIDIA得以高效地将AI性能扩展到多个GPU。
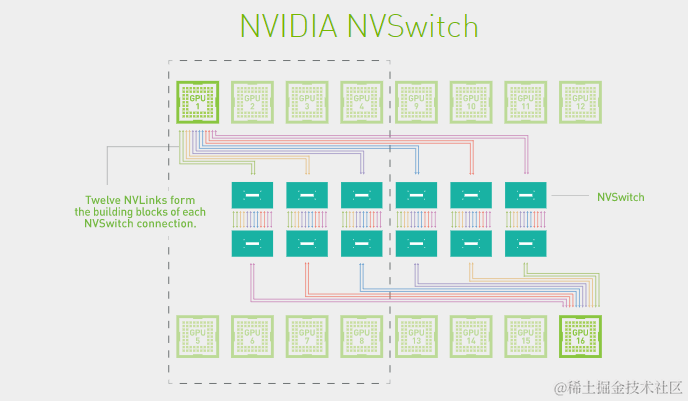
image.png
第一代NVSwitch于2018年发布,采用台积电12nm FinFET工艺制造,共有18个NVLink 2.0接口。目前NVSwitch已经迭代至第三代。
第三代NVSwitch采用台积电4N工艺(台积电 4N 工艺专为NVIDIA定制设计,并进行了一系列优化,它与普通台积电5nm节点相比,可实现更好的电源效率与性能,并且密度有所提升)构建,每个NVSwitch芯片上拥有64个NVLink 4.0端口,GPU间通信速率可达900GB/s。

image.png
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2075
2075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











