







LLM+StableDiffusion合成数据助力多模态研究,谷歌提出新策略SynCLR!
原创 小源 数源AI 2024年01月03日 08:31 浙江
数源AI 最新论文解读系列


论文链接:https://arxiv.org/pdf/2312.17742.pdf
开源代码:https://github.com/google-research/syn-rep-learn
引言
表示学习从原始的、通常未标记的数据中提取和组织信息。数据的质量、数量和多样性决定了模型能够学习到的表征的好坏。模型成为了数据中存在的集体智慧的一种反映。我们得到了我们喂入的东西。
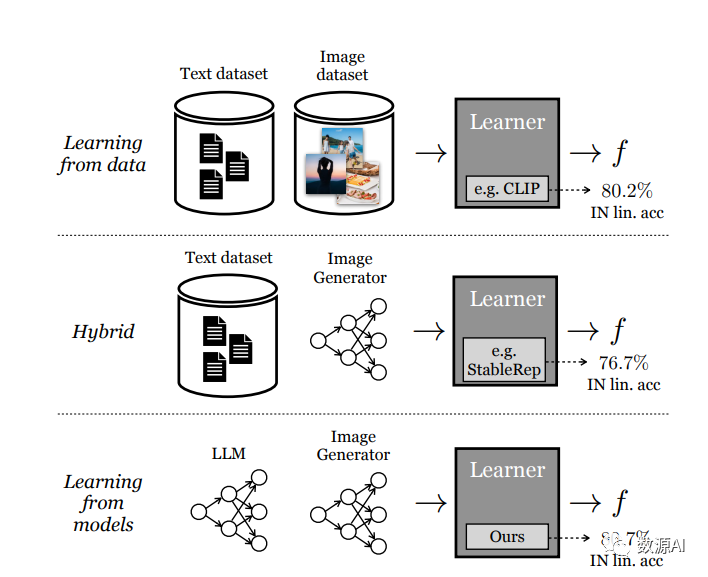
目前最佳性能的视觉表征学习方法依赖于大规模真实数据集。然而,收集真实数据也有其困境。收集大规模未修改的数据相对较便宜,因此相当可行。然而,对于自我监督的表征学习,这种方法在大规模数据情况下表现出较差的扩展性行为——即,增加更多未修改数据在大数据规模下几乎没有效果。为了减轻成本,在本文中,我们提出了一个问题,即合成数据是否是从现成生成模型中采样的一种可行途径,用于训练最先进的视觉表示的大规模策划数据集。
简介
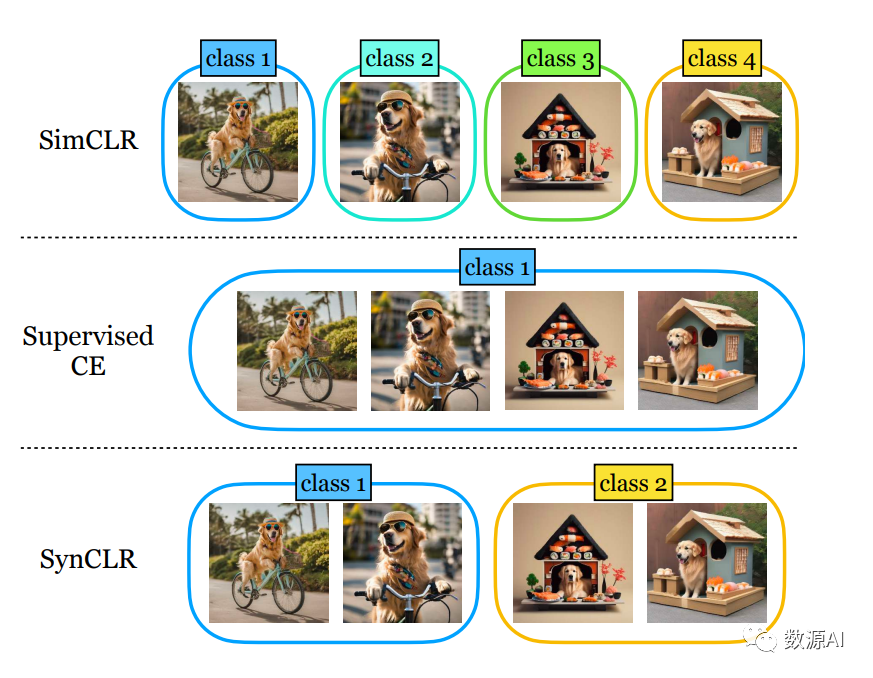
我们介绍了一种新的方法SynCLR,它仅通过合成图像和合成字幕学习视觉表示,而无需任何真实数据。我们使用LLMs合成了一个大规模的图像字幕数据集,然后使用现成的文本到图像模型生成与每个合成字幕相对应的多个图像。我们通过对比学习在这些合成图像上进行视觉表示学习,将共享相同字幕的图像视为正对。所得到的表示在许多下游任务中具有很好的迁移性能,与其他通用视觉表示学习方法(如CLIP和DINOv2)在图像分类任务中具有竞争优势。此外,在密集预测任务(如语义分割)中,与以往的自监督方法相比,SynCLR 在ADE20k数据集上的ViT-B/16模型上的MAE和iBOT分别提高了6.2和4.3 mIoU。
方法与模型
本文研究了在没有实际图像或文本数据的情况下学习视觉编码器 f 的问题。我们的方法依赖于三个关键资源的利用:语言生成模型 (g1)、文本到图像生成模型 (g2) 和一个精选的视觉概念列表 (C)。我们的研究包括三个步骤:(1) 我们使用 g1 合成了一个全面的图像描述集合 T,其中包含了 C 中的各种视觉概念;(2) 对于T 中的每个图像描述,我们使用 g2 生成多个图像,得到一个广泛的合成图像数据集 X;(3) 我们在 X 上进行训练,得到一个视觉表示编码器 f。
我们选择使用 Llama-2 7B和 Stable Diffusion1.5 作为 g1 和 g2,因为它们具有快速的推理速度。我们预计未来更好的 g1 和 g2 将进一步增强该方法的效果。
1
Synthesizing captions
为了利用强大的文本到图像模型来生成大量的训练图像数据集,我们起初需要一个标题的集合,这些标题不仅准确地描述图像,而且还展示多样性以涵盖广泛的视觉概念。
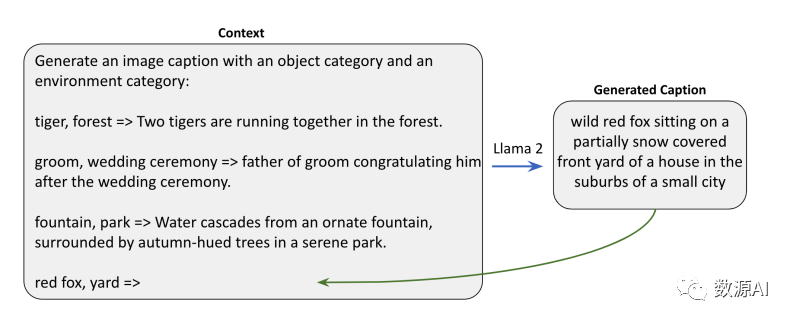
我们开发了一种可扩展的方法来创建这样一个大规模标题集合, 借助LLM的上下文学习能力[9]。我们的方法涉及制作特定的提示工程模板,指导LLM生成所需的标题。我们首先从一些现有数据集,如ImageNet-21k和Places-365中收集概念列表C。对于每个概念c ∈ C,我们考虑使用三种直接的模板来有效生成标题。

在生成上下文中的标题阶段,我们选择一个概念和三个模板之一。接下来,我们从所选模板中随机选取三个示例,并将生成标题的过程构建为一个文本补全任务。
2
Synthesizing Images
对于每个文本标题,我们通过使用不同的随机噪声来启动反向扩散过程,生成各种图像。分类器无关的指导(CFG)尺度是此过程中的关键因素。较高的CFG尺度提高了样本的质量和文本与图像之间的对齐程度,而较低的尺度则产生了更多样化的样本,并更好地遵循基于给定文本的原始条件图像分布。根据StableRep的方法,我们选择较低的CFG尺度,具体为2.5,并为每个标题生成4张图像。

3
Representation Learning
我们的表示学习方法基于StableRep [91]。我们方法的关键组成部分是多正对比学习损失 [50],通过在嵌入空间中对由相同标题生成的图像进行对齐来工作。我们还结合了其他自监督学习方法的多种技术,包括基于图像局部遮蔽的建模目标。
StableRep
将基于对比的分配分布和基于真实分配的交叉熵损失最小化。考虑一个编码的锚样本 a 和一组编码的候选样本 {b1, b2, ..., bK}。对比分配分布 q 描述了模型预测 a 和每个 b 生成自相同标题的可能性,而真实分配分布则是 a 和 b 之间的实际匹配(a 可以与多个 b 匹配):
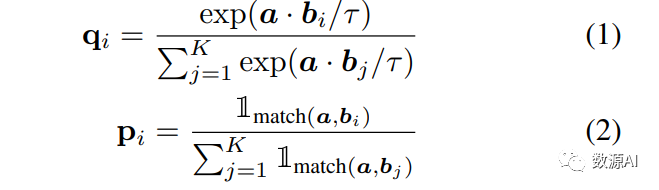
其中,τ ∈ R+ 是温度标量,a 和所有的 b 都已经进行了 ℓ2 规范化,而指示函数 1match(·,·) 则表示两个样本是否来自同一个标题。对于 a 的对比损失定义为
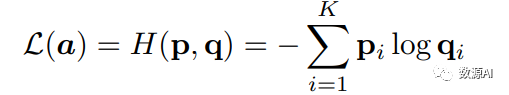
iBOT(遮蔽图像建模目标)
iBOT是一种遮蔽图像建模目标,其中局部补丁被遮蔽,模型的任务是预测被遮蔽补丁的标记化表示。它将 DINO(DINO)目标从图像层级调整为补丁层级。我们遵循 ,用迭代 Sinkhorn-Knopp(SK)算法 替换了 softmaxcentering 方法。我们使用 SK 运行了 3 次迭代来构建预测目标。
指数移动平均(EMA)
EMA是由 MoCo(MoCo)首次引入到自监督学习中的。我们使用 EMA 将裁剪作为 b 编码,并生成 iBOT 损失的目标。我们按照一个余弦时间表,在训练中将 EMA 模型更新为 θema ←λθema + (1 − λ)θ,其中 λ 从 0.994 变化到 1。我们发现EMA 模块不仅提高了最终性能,还改善了长训练周期下的训练稳定性。
多裁剪策略
多裁剪策略是作为提高计算效率的智能方法,并在本文中采用。对于这些局部裁剪,我们仅使用对比损失,省略 iBOT 损失。局部裁剪仅由学生网络编码,并与由 EMA 模型编码的相同标题的全局裁剪进行匹配。这样重用全局裁剪可以节省计算量。对于每个图像 x,我们生成一个单独的全局裁剪 xg 和 n 个局部裁剪 xl,最终的损失可以表达如下:
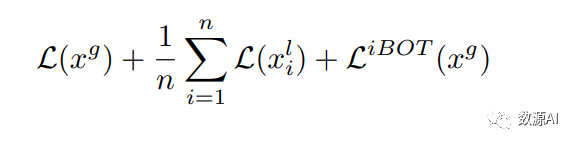
实验与结果
我们首先进行了一项消融研究,以评估我们的流水线中不同设计和模块的效果。然后我们继续扩大合成数据的量。
不同标题合成策略的比较
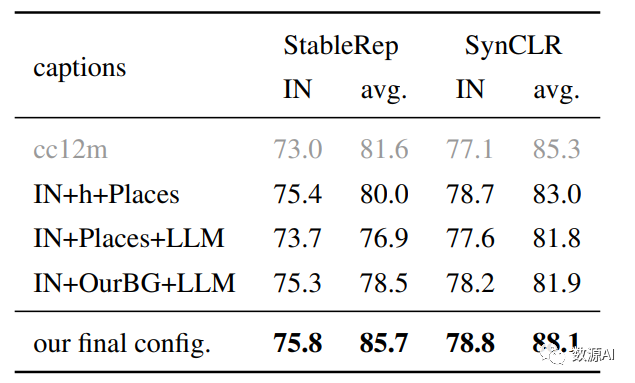
模型的重要组成部分消融实验
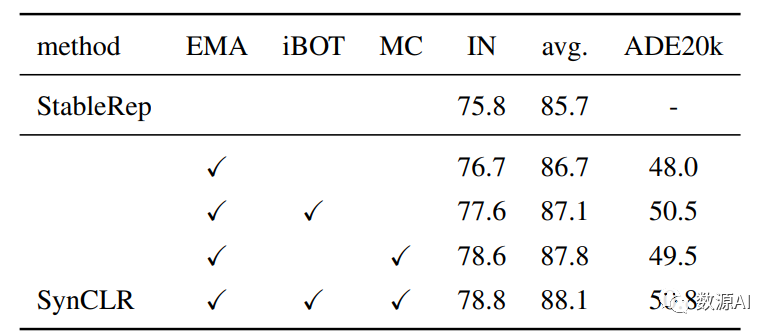
不同学习目标的比较
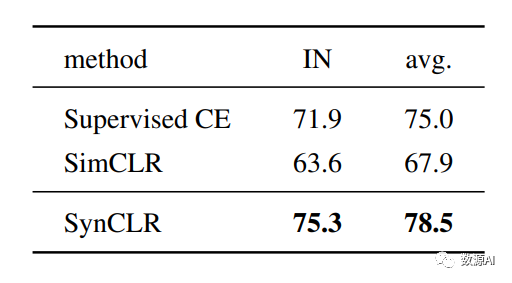
微调评估在ImageNet上的Top-1准确率
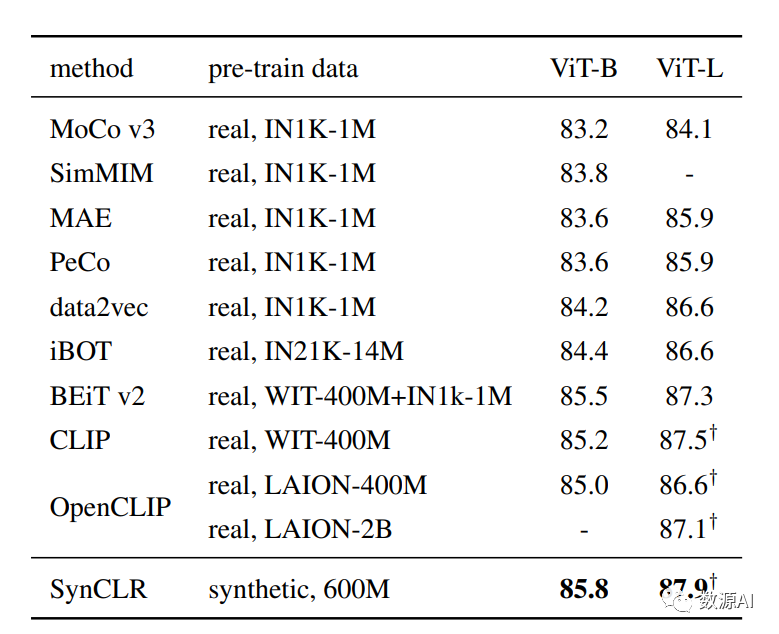
ADE20K语义分割结果
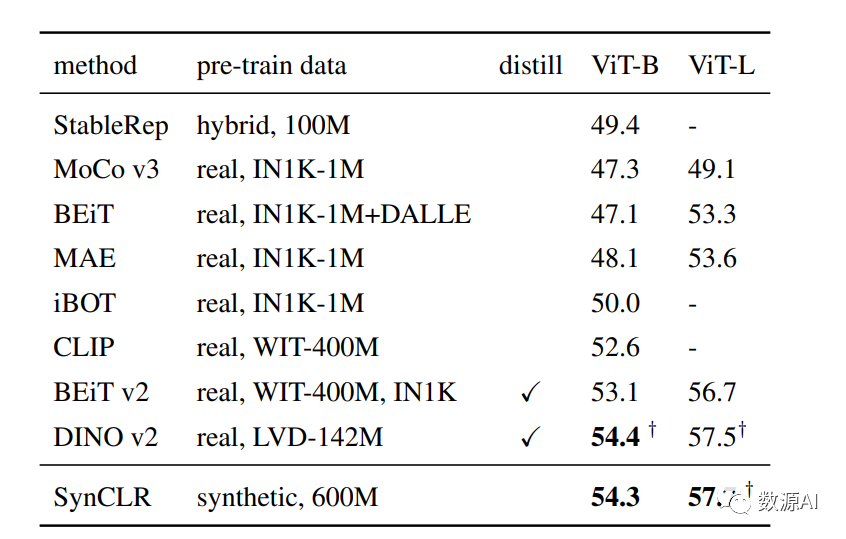
我们评估SynCLR在ImageNet上的微调能力。我们在表中与其他最先进的自监督方法进行比较。我们的SynCLR优于在ImageNet图像或大规模图像数据集上训练的模型。具体地,SynCLR优于Laion-2B上训练的OpenCLIP ViTL,Laion-2B是我们使用的文本到图像模型Stable Diffusion的数据集。我们的发现表明,合成图像有利于训练表示,稍后可以将其轻松地适应具有有限真实数据量的下游任务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











