






慕了!靠多模态特征融合就发了CCF-A!模型性能飙升了94.4%!
原创 学姐 AI科研技术派 2024年10月28日 00:00 新疆
相比传统的特征融合方法,多模态特征融合,由于整合了多种模态的信息,不仅能提高模型的准确性,还使模型能够更好地应对数据缺失、噪声等问题,增强鲁棒性和泛化能力!
正因如此,其也成为各大顶会的常客!光是CVPR24就有多篇:模型SRMF,在情感分析任务中,性能飙升了94.4%;模型IS-Fusion在3D检测中,性能远超SOTA……此外,Nature子刊也不乏其身影,比如模型MMFF,在视频异常检测中,准确率高达97%。
目前主要的融合方法有:与注意力机制结合、引入Mamba、基于多层特征嵌入、由静态视角转向动态等。
为了让大家能够更好地运用该方法,实现快速涨点,我给大家准备了19种创新思路,原文和源码都有,一起来看!
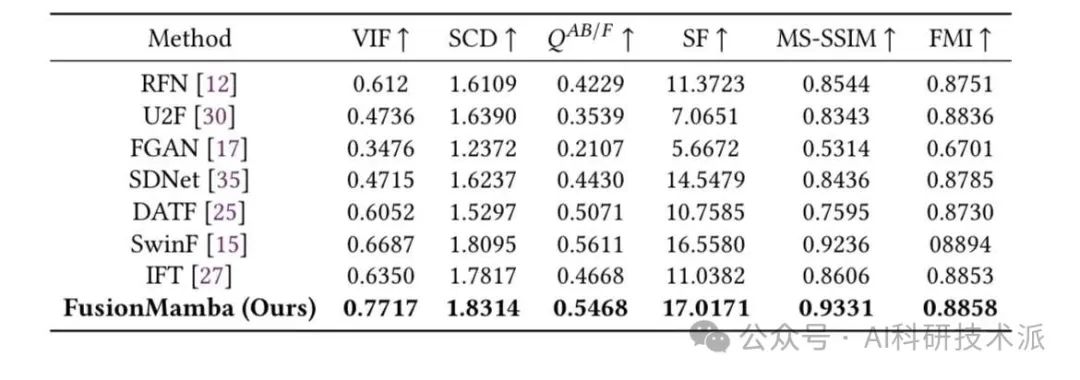
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
方法:
本文提出了一种名为FusionMamba的多模态图像融合方法,该方法旨在通过动态特征增强技术结合Mamba框架来改善不同模式的信息融合,生成包含全面信息和详细纹理的单一图像。FusionMamba通过设计一个改进的高效Mamba模型,集成动态卷积和通道注意力,保持了Mamba的全局建模能力,并减少了通道冗余,同时增强了局部特征提取能力。

创新点:
-
FusionMamba通过动态特征增强模块(DFFM)来提升图像融合中的细节纹理信息和差异信息,从而增强不同模态之间的信息交互。
-
该方法整合了高效的视觉状态空间模型、动态卷积和通道注意力机制,以提高全局建模能力,减少通道冗余,并增强局部特征提取能力。
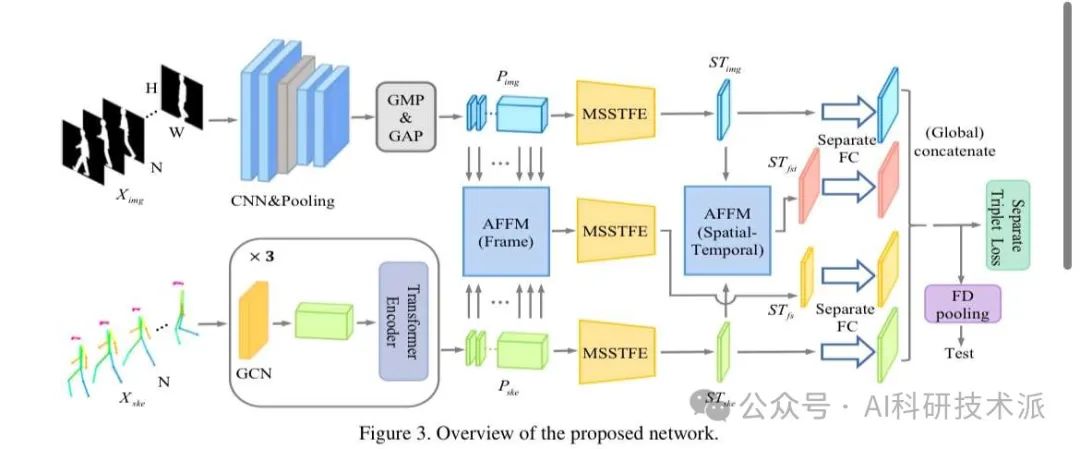
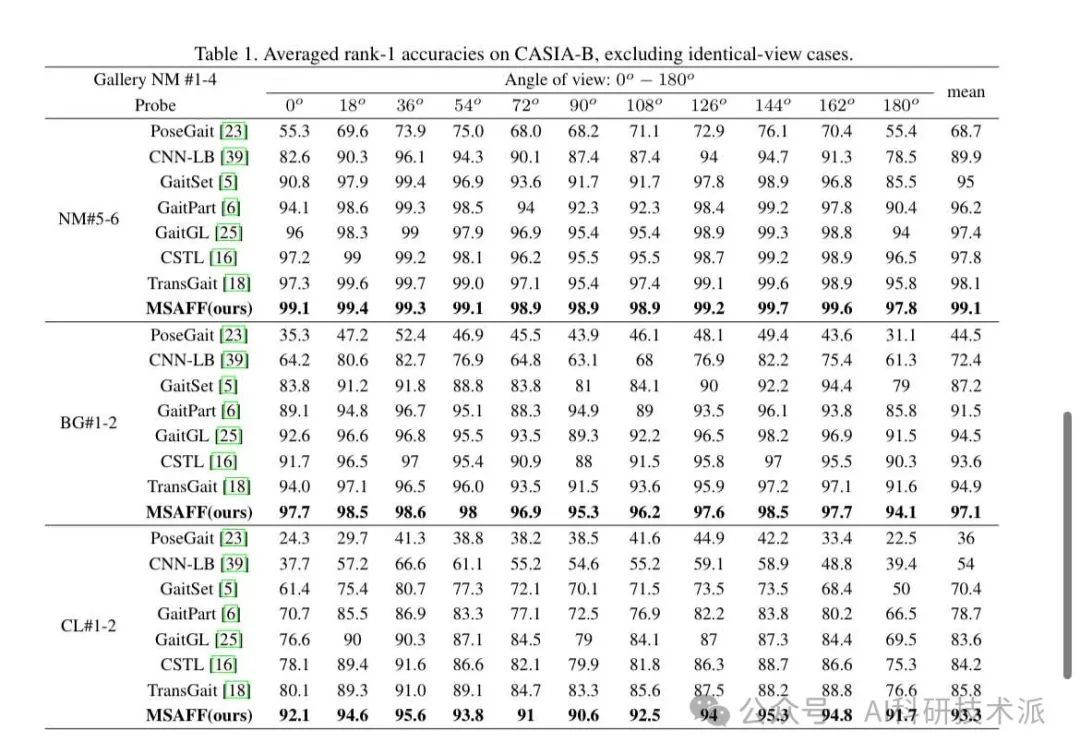
AMulti-Stage Adaptive Feature Fusion Neural Network for Multimodal Gait Recognition
方法:
本文提出了一种用于多模态步态识别的多阶段自适应特征融合神经网络(MSAFF),该网络通过多阶段特征融合策略(MSFFS)和自适应特征融合模块(AFFM)来充分利用轮廓和骨架数据的互补优势。
创新点:
-
本文提出了一种新的方法来融合多模态数据,利用预训练的音频和视频骨干网络从视觉和音频模态中提取动态特征
-
策略在特征提取的不同阶段执行多模态融合,包括帧级别融合、时空级别融合和全局级别融合。这样可以更充分地利用不同模态之间的互补优势。
-
本文模块考虑了轮廓和骨架之间的语义关联,通过动态地调整不同轮廓区域与骨架关节之间的关联权重,实现了更有效的特征融合。
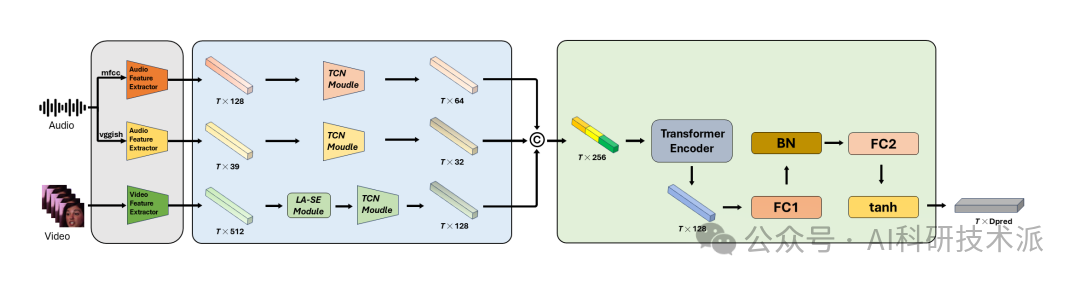
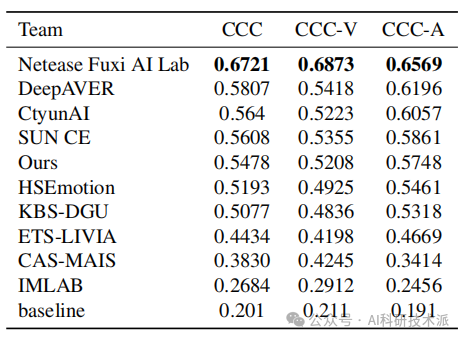
Improving Valence-Arousal Estimation with Spatiotemporal Relationship Learning and Multimodal Fusion
方法:
本文提出了一种改进的情感维度估计方法,即Valence-Arousal(VA)估计,通过结合时空关系学习和多模态融合来实现。研究者们设计了一个全面的模型,首先对视频帧和音频片段进行预处理以提取视觉和音频特征。
创新点:
-
提出了一种新的方法来融合多模态数据,利用预训练的音频和视频骨干网络从视觉和音频模态中提取动态特征
-
策略在特征提取的不同阶段执行多模态融合,包括帧级别融合、时空级别融合和全局级别融合。这样可以更充分地利用不同模态之间的互补优势。
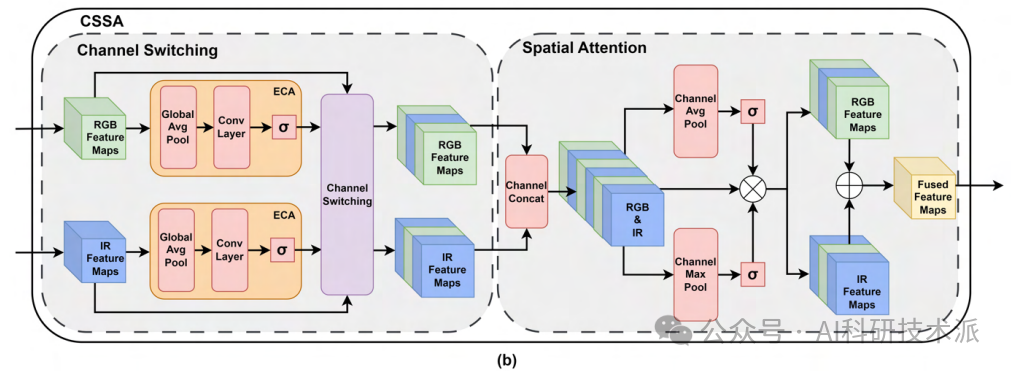
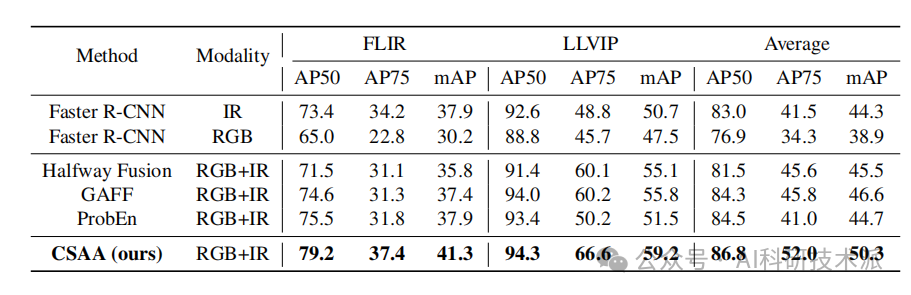
Multimodal Object Detection by Channel Switching and Spatial Attention
方法:
本文提出了一种轻量级的多模态融合模块,用于提高多模态目标检测的准确性和效率。CSSA模块通过通道切换和空间注意力机制高效地融合来自不同模态的输入。在通道切换部分,使用高效通道注意力层为每个模态的特征图分配权重,并将对最终预测影响较小的通道替换为另一个模态的相应通道。空间注意力部分则通过最大池化和平均池化操作来评估特征图中每个位置的重要性,不增加额外参数。
创新点:
-
引入通道切换(Channel Switching)到多模态目标检测中,这是首次将该概念应用于这一领域,并通过实验验证了其有效性。
-
将通道切换与空间注意力(Spatial Attention)相结合,使检测模型能够从通道和空间两个层面分析输入模态,从而实现最先进的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











