






Poe
在大语言模型(LLM)推理过程中,使用**KV Cache(Key-Value Cache)**是为了优化生成文本的效率和速度,尤其是在长序列生成任务中(如聊天或生成长段落)。以下是KV Cache的作用及其背后的原理:
1. 背景:Transformer 模型的自注意力机制
Transformer 模型的核心是自注意力机制,它需要计算输入序列中每个词或标记(token)之间的关系。在推理过程中,生成下一个token时,模型会基于已经生成的所有token,计算这些token之间的注意力权重。这涉及到三个矩阵:
- Query (Q):表示当前token的查询向量。
- Key (K):表示输入token的标识向量。
- Value (V):表示输入token的内容向量。
在每一步生成中,模型需要计算所有之前token的Key和Value向量与当前Query之间的注意力权重。这种计算是逐步累积的,随着生成长度增加,计算量呈线性增长。
2. 问题:长序列推理的效率瓶颈
在没有KV Cache的情况下,每次生成新token时,模型需要重新计算整个历史序列的Key和Value向量,并参与注意力计算。这带来了以下问题:
- 重复计算:每次生成新token时,前面已经生成的token的Key和Value向量需要被重新计算,浪费了计算资源。
- 计算复杂度高:自注意力机制的计算复杂度为 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d),其中 nnn 是序列长度,ddd 是向量维度。随着序列长度增加,计算开销会迅速变大。
因此,为了避免重复计算和降低推理的计算复杂度,KV Cache 被引入。
3. KV Cache 的作用
KV Cache 是一种缓存机制,用于存储模型在每一步生成中计算得到的 Key 和 Value 向量:
- 缓存历史序列的 K 和 V:在推理过程中,模型会将每个token的Key和Value向量缓存起来。下一次生成时,无需重新计算这些向量,而是直接使用缓存。
- 仅计算新增的 Query:当生成新token时,模型只需计算当前token的Query向量,并与缓存的Key和Value进行注意力计算。
4. KV Cache 的优点
KV Cache 带来了显著的性能提升:
(1)降低计算复杂度
- 无需重复计算历史Key和Value向量,计算复杂度从 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d) 降低到 O(n⋅d)O(n \cdot d)O(n⋅d),其中 nnn 是序列长度。
(2)加快推理速度
- 随着序列长度增加,缓存机制可以显著减少计算开销,从而加快生成速度。这对于生成长文本或实时对话场景(如聊天机器人)尤为重要。
(3)减少内存占用
- 如果没有KV Cache,模型需要在每一步重新计算整个序列的Key和Value,可能导致额外的内存开销。KV Cache通过存储固定大小的向量,优化内存使用。
5. 应用场景
KV Cache 在以下任务中非常关键:
- 聊天机器人:如 ChatGPT,每次生成的回复可能很长,需要频繁使用上下文信息。
- 长文本生成:如文章续写、小说生成等,需要模型记住并高效使用长上下文。
- 代码生成:生成代码时,通常需要回顾之前生成的代码段。
6. KV Cache 的实现细节
在实际实现中,KV Cache 的工作流程如下:
- 初始化缓存:在推理开始时,KV Cache为空。
- 逐步更新缓存:
- 每次生成新token时,模型会计算该token的Key和Value向量,并将其添加到缓存中。
- 使用缓存:
- 每次计算注意力分数时,直接使用缓存的Key和Value,与当前token的Query进行计算。
- 循环迭代:
- 模型生成下一个token时,重复上述流程,累积更新缓存。
7. 可能的限制
虽然KV Cache显著提升了推理效率,但也有一些需要注意的地方:
- 内存占用:缓存所有生成token的Key和Value会占用一定内存,尤其是生成非常长的序列时。
- 实现复杂性:在分布式推理或多模型并行场景下,KV Cache的管理和更新可能会增加系统复杂性。
总结
KV Cache 是大语言模型推理中不可或缺的加速机制,通过缓存Key和Value向量,避免了重复计算,从而显著提升了推理效率和速度。这对于需要处理长上下文或实时生成的任务至关重要,是大语言模型在实际应用中实现高效推理的核心技术之一。
详细说说LLM推理中的KV cache实现过程和原理

Poe
在大语言模型(LLM)的推理中,KV Cache 是一种关键的优化技术,用于加速自回归生成任务(如对话、文本生成等)。它通过缓存注意力机制中的 Key 和 Value 矩阵,避免重复计算,从而提升推理效率。以下是 KV Cache 的实现过程和原理的详细说明:
1. Transformer 模型中的注意力机制原理
Transformer 的核心是 自注意力机制,它用于捕获不同位置的 token 之间的关系。在每一层的注意力机制中,计算如下公式:
自注意力公式:
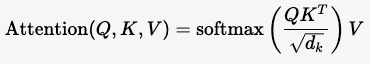
Attention(Q,K,V)=softmax(QKTdk)V
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
- Q(Query): 查询向量,表示当前 token 的特征。
- K(Key): 键向量,表示输入序列中其他 token 的特征。
- V(Value): 值向量,表示输入序列中其他 token 的内容。
- dkd_kdk: 是特征的维度,用于缩放。
在推理过程中,生成每个 token 时,模型需要计算基于所有之前生成的 token 的注意力分数。这意味着:
- 每次生成时,Key 和 Value 必须包含所有历史 token 信息。
- 每次生成新的 token 都需要重新计算历史 token 的 Key 和 Value,计算代价大,效率低下。
2. KV Cache 的核心思想
KV Cache 的核心思想是:缓存历史 token 的 Key 和 Value,避免重复计算。
- Key 和 Value 是固定的历史信息:对于每个已经生成的 token,其 Key 和 Value 是不变的,因此可以直接缓存起来。
- Query 是动态计算的:当前生成的新 token 的 Query 需要与缓存中的 Key 和 Value 进行注意力计算。
通过缓存 Key 和 Value:
- 只需在生成第一个 token 时计算 Key 和 Value。
- 后续生成过程中,直接复用缓存的 Key 和 Value,只计算新增的 Query,大幅降低计算复杂度。
3. KV Cache 的实现过程
在推理过程中,KV Cache 的实现可以分为以下步骤:
3.1 初始化 KV Cache
- 在推理开始时,初始化一个空的 KV Cache,用于存储 Key 和 Value。
- 假设 Transformer 有 LLL 层,每层都会有自己的 KV Cache。
- KV Cache 的数据结构通常是一个 3D 张量,形状为:
- K:[L,n,dk]K: [L, n, d_k]K:[L,n,dk]
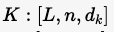 (Key 缓存,表示第 LLL 层中 nnn 个 token 的 Key 向量)
(Key 缓存,表示第 LLL 层中 nnn 个 token 的 Key 向量) - V:[L,n,dv]V: [L, n, d_v]V:[L,n,dv]
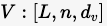 (Value 缓存,表示第 LLL 层中 n 个 token 的 Value 向量)
(Value 缓存,表示第 LLL 层中 n 个 token 的 Value 向量)
- K:[L,n,dk]K: [L, n, d_k]K:[L,n,dk]
其中:
- LLL:Transformer 的层数。
- nnn:当前序列中已有的 token 数。
- dkd_k、d_vdv:Key 和 Value 向量的维度。
3.2 每步生成时更新 KV Cache
假设模型当前已经生成了 nnn 个 token,并缓存了它们的 Key 和 Value。在生成新 token 的过程中:
-
当前 token 的 Query 计算:
- 当前 token 的嵌入向量(embedding)通过模型的前向传播,计算得到当前层的 Query 向量。
-
从缓存中读取历史 Key 和 Value:
- 从 KV Cache 中读取当前层缓存的历史 Key 和 Value。
-
计算注意力分数:
- 使用 Query 和缓存的 Key 计算注意力分数:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dkQKT)V
- 这里的 KKK 和 VVV 是从 KV Cache 中读取的历史 Key 和 Value。
- 使用 Query 和缓存的 Key 计算注意力分数:
-
更新 KV Cache:
- 当前 token 的 Key 和 Value 通过前向传播计算得到,并追加到缓存中:
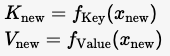
- Knew=fKey(xnew)
- K_{\text{new}} = f_{\text{Key}}(x_{\text{new}})Knew=fKey(xnew)
- Vnew=fValue(xnew)
- V_{\text{new}} = f_{\text{Value}}(x_{\text{new}})
- Vnew=fValue(xnew)
- 将 KnewK_{\text{new}}Knew 和 VnewV_{\text{new}}Vnew 添加到 KV Cache 中。
- 当前 token 的 Key 和 Value 通过前向传播计算得到,并追加到缓存中:
3.3 KV Cache 的存储示意图
假设我们有一个 3 层的 Transformer 模型,KV Cache 的更新过程如下:
-
初始状态:
- KV Cache 为空。
-
第一个 token:
- 计算 Key 和 Value,缓存到 KV Cache 中:

- K1(1)K_1^{(1)}K1(1), V1(1)V_1^{(1)}V1(1) 存储在第 1 层缓存。
- K1(2)K_1^{(2)}K1(2), V1(2)V_1^{(2)}V1(2) 存储在第 2 层缓存。
- K1(3)K_1^{(3)}K1(3), V1(3)V_1^{(3)}V1(3) 存储在第 3 层缓存。
- 计算 Key 和 Value,缓存到 KV Cache 中:
-
第二个 token:
- 读取 KV Cache,计算新 token 的 Query,并更新 KV Cache:

- K2(1)K_2^{(1)}K2(1), V2(1)V_2^{(1)}V2(1) 追加到第 1 层缓存。
- K2(2)K_2^{(2)}K2(2), V2(2)V_2^{(2)}V2(2) 追加到第 2 层缓存。
- K2(3)K_2^{(3)}K2(3), V2(3)V_2^{(3)}V2(3) 追加到第 3 层缓存。
- 读取 KV Cache,计算新 token 的 Query,并更新 KV Cache:
-
以此类推,直至序列生成结束。
4. KV Cache 的优化原理
KV Cache 的优化主要体现在以下几个方面:
4.1 避免重复计算
- 优化前:每次生成新 token,都需重新计算所有历史 token 的 Key 和 Value。
- 优化后:历史 token 的 Key 和 Value 被缓存,生成新 token 时只需计算当前 token 的 Key 和 Value。
4.2 减少计算复杂度
- 对于序列长度为 nnn,特征维度为 ddd 的 Transformer:
- 无 KV Cache 时:每次生成新 token,计算复杂度为 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d)(因为每次注意力计算都涉及整个序列)。
- 有 KV Cache 时:计算复杂度降为
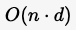 O(n⋅d)O(n \cdot d)O(n⋅d)(只需计算当前 token 的 Query,并与缓存的 Key 和 Value 进行点积)。
O(n⋅d)O(n \cdot d)O(n⋅d)(只需计算当前 token 的 Query,并与缓存的 Key 和 Value 进行点积)。
4.3 提高推理速度
- KV Cache 可以显著减少每步生成时的计算量,尤其是在长序列生成任务中(如文本续写或对话)。
5. KV Cache 的实现代码示例
以下是 KV Cache 的简化伪代码:
python
复制
class TransformerDecoder:
def __init__(self, num_layers, d_model, d_k, d_v):
self.num_layers = num_layers
self.kv_cache = [None] * num_layers # 初始化空的 KV Cache
def forward(self, input_token, layer_states):
output = input_token
for layer_idx in range(self.num_layers):
# 从缓存中读取 K 和 V
K_cache, V_cache = layer_states[layer_idx] if layer_states[layer_idx] else (None, None)
# 计算当前 token 的 Q, K, V
Q = compute_query(output)
K_new = compute_key(output)
V_new = compute_value(output)
# 如果有缓存,拼接历史 K 和 V
if K_cache is not None and V_cache is not None:
K = concat(K_cache, K_new)
V = concat(V_cache, V_new)
else:
K, V = K_new, V_new
# 更新缓存
layer_states[layer_idx] = (K, V)
# 注意力计算
output = attention(Q, K, V)
return output, layer_states
6. KV Cache 的实际应用场景
- 聊天机器人(如 ChatGPT):需要处理长对话上下文,KV Cache 可加速推理。
- 代码生成:生成代码时需要高效利用上下文。
- 长文本生成:生成长篇小说或技术文档时,大幅减少计算量。
7. 总结
- KV Cache 的核心是缓存 Key 和 Value,避免重复计算。
- 实现过程包括初始化缓存、逐步更新缓存,以及在生成新 token 时复用缓存。
- 优势在于显著提升推理速度,减少计算复杂度,是 LLM 推理中的重要优化技术。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











