






大模型训练到底需要什么样的数据(预训练)?
原创 浪子 牛山AI公园 2024年12月29日 20:43 广东
👀
一、前言
我们都知道大模型训练需要提供数据,企业常见的数据有网页、Word、PDF 等文档数据,那么能否直接把 Word、PDF 和网页直接给大模型训练呢? 答案是否定的,因为这些文档格式不统一、内容分散且未经处理,难以直接用于训练,那么大模型训练需要的数据到底长什么样?
👀
二、大模型训练通常会分为哪几个阶段?
要了解大模型训练需要什么样的数据之前,先要搞清楚大模型训练的过程,因为不同的阶段所需要的数据类型不同。 目前大模型的训练主要会分为预训练和微调两个阶段,预训练又可以分为全量预训练和二次预训练。
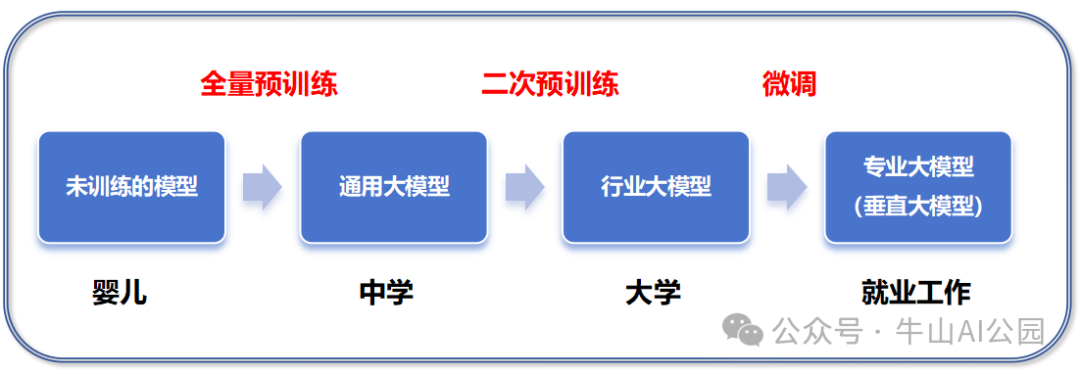
如上图所示,大模型的训练跟一个人从婴儿成长到能独立工作的过程类似,分了多个阶段(后面再单独介绍为什么这样划分),不同阶段训练的目标不同,因此需要用的数据内容和格式也是不同的。本文先重点介绍预训练阶段的数据,后续再介绍微调用的数据。
👀
三、大模型预训练在做什么?需要什么样的数据?
预训练在做什么?
预训练是语言模型学习的初始阶段,通过处理大量未标注的文本数据来进行。这些数据包括书籍、文章和网站内容等。在预训练期间,模型的目标是捕获文本语料库中的底层模式、结构和语义知识。
预训练在实践中可以分为两个阶段:全量预训练和二次预训练。
1、全量预训练:是指从零开始对模型进行训练,生成一个预训练模型。这种模型的特点是通用性强,类似于一个婴儿经过大量培养教育达到高中水平的学生。它具备了语文、数学、英语和地理等通用知识,但对于特定行业领域的专业知识了解有限。举例来说,通用的预训练模型如通义千问、Llama2、GPT-3 等,它们在许多领域都有良好的表现,但在特定行业应用中可能需要进一步的定制。
2、二次预训练:则是在已有的全量预训练模型的基础上,结合具体场景数据进行再次训练。其目的是让模型学习特定领域或场景的知识,使其更具专业化和针对性。例如,我们可以使用地理测绘行业的数据对预训练模型进行二次预训练,让模型能够理解和回答与地理测绘相关的问题。
通过二次预训练,模型可以逐步积累更多的领域知识,提高在特定领域的表现。这种定制化的训练方法使得模型在应用到实际场景时能够更加准确地理解和处理特定领域的问题,提升了模型的实用性和适用性。总的来说,全量预训练和二次预训练相辅相成,共同构建了一个通用性和专业性并存的语言模型体系,为各种应用场景提供了强大的支持和应用基础。
预训练需要提供什么样的数据?
前面提到预训练的目的,是让模型学习到文本语料库中的底层模式、结构和语义知识。这其实和我们学生时期学习语文或英语很相似。我们在学习语文和英语时,也是在掌握语言的结构和语义知识,最终能够做到阅读理解、写作和总结。
举个例子,当你看到填空题“村里有个姑娘叫__ ",你的第一反应是什么?相信 99% 的人都会回答“小芳”,而不是“刘亦菲”。为什么会这样?这是因为在我们接触的语言环境中,“村里有个姑娘叫小芳”这个搭配出现的概率最高。经过长时间的影响(可以看作大脑在学习),形成了固定的搭配模式。
类似的,大语言模型在预训练阶段,就是通过输入大量的文本语料,学习语言的这种规律。语料通常来自数百万本书籍、文章和网站内容,内容形式包括百科知识、新闻报道、社交媒体对话、技术文档、文学作品等。通过预训练,模型能够理解和生成符合语言习惯的文本,从而具备强大的语言处理能力,以下列举一个用于预训练的新闻数据(新浪体育):
“马晓旭意外受伤让国奥警惕 无奈大雨格外青睐殷家军
记者傅亚雨沈阳报道 来到沈阳,国奥队依然没有摆脱雨水的困扰。7 月 31 日下午 6 点,国奥队的日常训练再度受到大雨的干扰,无奈之下队员们只慢跑了 25 分钟就草草收场。
31 日上午 10 点,国奥队在奥体中心外场训练的时候,天就是阴沉沉的,气象预报显示当天下午沈阳就有大雨,但幸好队伍上午的训练并没有受到任何干扰。
下午 6 点,当球队抵达训练场时,大雨已经下了几个小时,而且丝毫没有停下来的意思。抱着试一试的态度,球队开始了当天下午的例行训练,25 分钟过去了,天气没有任何转好的迹象,为了保护球员们,国奥队决定中止当天的训练,全队立即返回酒店“
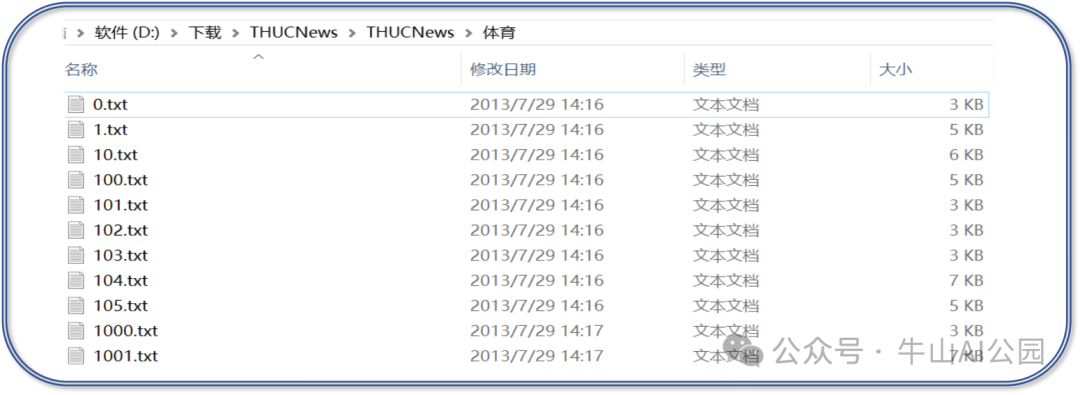
以上是一个简单的体育新闻内容例子,这些内容是从网站爬取后,经过整理形成的文本文档。回到最初的问题,用户手中的 Word、PDF 等文档并不能直接用来训练大模型,而是需要将文档中的内容清洗成文本文档(如 TXT 或 JSON 格式)。
大模型如何从这些整理好的文本中学习的?
想想我们是如何学习中文或英语的——通过大量阅读培养语感。所谓语感,其实就是学会如何组词造句。当你看到“窈窕淑女”,自然会联想到“君子好逑”。你可能说不清具体原因,但这是因为你看到和听到的这种组合次数最多,在大脑中形成了强烈的联想模式。
大模型的学习原理和这个过程类似。在预训练阶段,通常采用无监督学习方法。模型被要求根据输入的数据预测一些内容,比如被掩盖的部分或周围的上下文(如下图所示)。训练时会根据一定规则掩盖某个字、词或句子,然后让模型自动尝试预测,生成结果后与正确答案对比,再进行反馈和迭代优化。
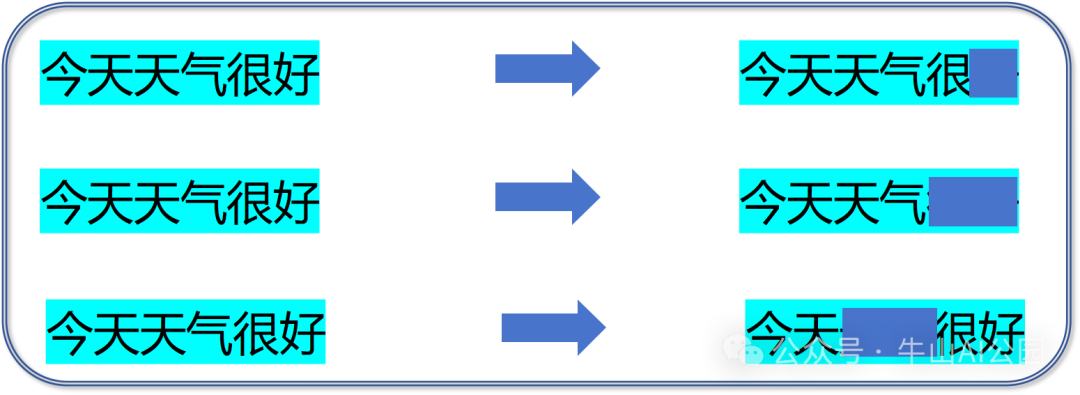
这种训练方式其实和我们学习语文或英语时做填空题很像,通过不断尝试和纠正,模型逐步学习到丰富的语言或数据表示形式。这种预训练的特点是可以从大规模数据中提取有用的特征和模式,而无需人工标注的标签信息。具备训练背后的技术原理可以参考本文末尾附录的往期文章。
👀
四、总结
大模型的预训练阶段对其性能和应用意义至关重要。以通义千问、 LLaMA 2 等开源模型为例,这些模型通过在大规模通用数据集上进行预训练,学习到丰富的语言模式、语义结构和知识库。预训练让模型具备广泛的语言理解和生成能力,能够在多种任务中表现出色,例如文本分类、机器翻译和问答系统。预训练的意义在于提升了模型的泛化能力,为后续微调奠定坚实基础,使开发者能够快速针对特定任务调整模型,大幅减少了数据需求和训练成本。
常见预训练中文语料库:
1、通用知识类语料
维基百科(中文部分):提供系统化的百科知识,覆盖广泛主题,常被用作模型的基本通识知识来源。
百度百科、互动百科:类似于维基百科的本地化知识库,内容丰富且结构化,增强模型对中文知识的理解。
2、网络文本
中文社区和论坛数据:如知乎、豆瓣、天涯论坛的公开数据,用于增强对中文用户交互场景的建模能力,包括问答形式、评论和讨论内容。
新闻语料:来自新华网、人民网等主流新闻网站的公开文本,内容涵盖政治、经济、社会、科技等领域,用于增强模型对正式语体和时事的理解。
3、文学与书籍
中国现代文学数据:例如 Project Gutenberg 中的中文文学作品,提升模型在中文文学语言生成中的表现。
开放书籍项目:开源中文书籍数据,如青少年读物、经典文学等。
4、技术与专业领域数据
学术数据:来自中国知网(CNKI)的公开论文摘要或科研报告,提供领域知识。
开源代码和技术文档:开源代码库(如 Gitee)以及相关的技术问答社区(如 SegmentFault)。
推荐阅读:

牛山AI公园
分享个人在学习和使用大语言模型中的总结心得
16篇原创内容
公众号
大模型4
自然语言处理4
GPT2
模型4
大模型 · 目录
上一篇什么是AI模型推理,与训练有什么差异?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











