






通义千问Qwen2.5-Max登上大模型盲测榜单全球前十,数学及编程能力夺冠
通义千问Qwen 2025年02月05日 15:08 安徽
2月4日凌晨,Chatbot Arena 公布了最新的大模型盲测榜单,通义千问Qwen2.5-Max 凭借1332分的成绩,位列全球第七,并成为非推理类中国大模型的冠军。
同时,Qwen2.5-Max 在数学和编程等单项能力上排名第一,在硬提示(Hard prompts)方面排名第二。
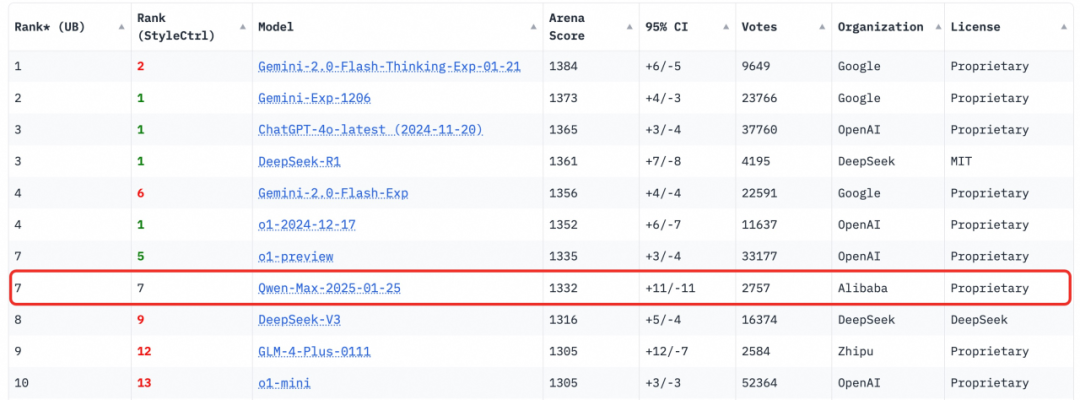
截取自Chatbot Arena LLM LeaderBoard
关于Chatbot Arena
Chatbot Arena 是由 LMSYS Org 推出的大模型性能测试平台,目前集成了190多种模型。该榜单采用匿名方式将大模型两两组队,交给用户进行盲测,用户根据真实对话体验对模型能力进行投票。因此,Chatbot Arena LLM Leaderboard 成为业界公认的最公正、最权威榜单之一,也是全球顶级大模型的最重要竞技场。
Chatbot Arena 官方评价称:阿里巴巴的 Qwen2.5-Max 在多个领域表现强劲,特别是专业技术向的(编程、数学、硬提示等)。
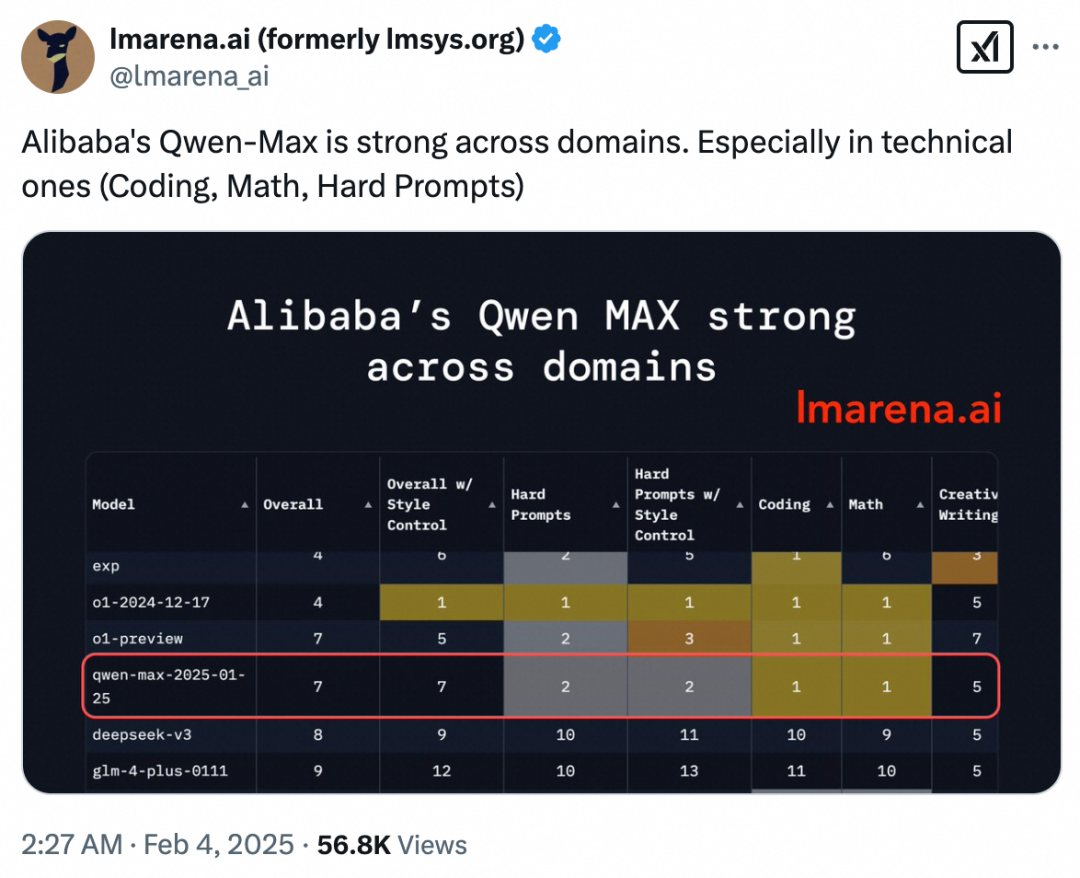
Chatbot Arena官方配图:
阿里Qwen2.5-Max在多领域表现强劲,数学及编程能力斩获第一
此前,Qwen2.5-72B-Instruct发布后也曾闯入Chatbot Arena榜单全球前十,是当时得分最高的中国大模型;Qwen2-VL-72B-Instruct闯入Vision榜单第九,是彼时成绩最好的开源模型。
Qwen2.5-Max
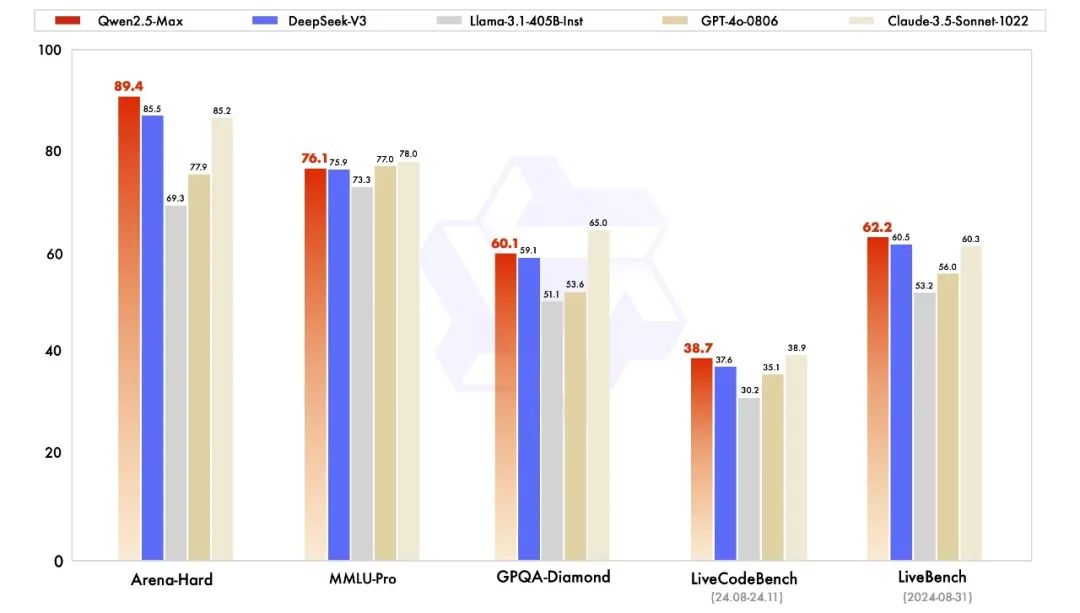
Qwen2.5-Max 是我们发布的最新 MoE 模型,展现出极强劲的性能。
在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond 及 MMLU-Pro 等主流基准测试中,Qwen2.5-Max 比肩 Claude-3.5-Sonnet,并几乎全面超越了 GPT-4o、DeepSeek-V3及 Llama-3.1-405B。
目前,企业可以通过阿里云百炼 API 调用 Qwen2.5-Max 模型,开发者也可以在 Qwen Chat (https://chat.qwenlm.ai)平台免费体验。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











