






[ICLR2025] BLEND:通过特权知识蒸馏实现行为引导的神经元群体动力学建模
以下文章来源于AI for Healthcare ,作者Fuxiang HUANG

近日,HKUST SmartLab联合北京大学的研究工作《BLEND: Behavior-guided Neural Population Dynamics Modeling via Privileged Knowledge Distillation》已被机器学习顶级会议 ICLR 2025 接收。本文提出了一种全新的神经群体活动分析框架(BLEND),利用训练阶段的行为数据作为特权信息(Privileged Knowledge),通过教师—学生架构实现神经群体动力学建模。教师模型同时输入神经活动和行为数据,并将所学知识蒸馏给只依赖神经数据的学生模型,从而在推理阶段仅需神经活动即可获得优异的预测效果。实验在神经活动预测、行为解码以及神经元身份预测等任务上均取得显著提升,行为解码任务提升超过50%,神经元身份预测提升超过 15%。
背景介绍
神经群体动力学建模旨在揭示大脑如何通过神经元群体的集体活动实现感知、运动和认知等复杂功能。随着大规模神经记录技术的发展,研究者能够捕捉到海量的神经活动数据。然而,单纯依赖神经活动往往不足以全面理解大脑功能的复杂性。行为信号(如动物的运动轨迹或眼动数据)为神经活动提供了关键的上下文信息,有助于揭示神经活动与行为之间的深层联系。
然而,在现实场景中,行为信号并非总是与神经数据完美配对。例如,在静息状态下,行为信号可能缺失或不完整。现有的神经动力学建模方法通常需要复杂的模型设计或对神经-行为关系做出强假设,这限制了其在实际应用中的灵活性。因此,开发一种能够在训练时利用行为信号指导,但在推理时仅依赖神经活动的模型,成为计算神经科学中的一个重要研究问题。BLEND 的提出正是为了应对这一挑战。
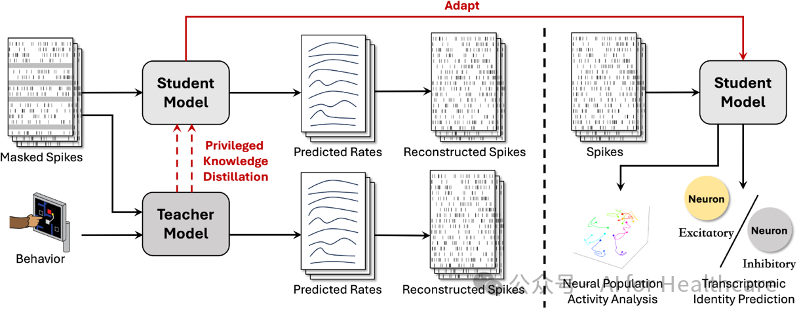
图1: Behavior-guided neural population dynamics modelling framework via privileged knowledge distillation(BLEND)方法框架图。
相关工作
在神经群体动力学建模领域,目前主要存在以下几类方法(图2)
A. 仅依赖神经活动的建模方法
如图2(a)所示,此类方法仅使用神经记录数据构建潜变量模型(例如 PCA、LFADS、NDT 等),虽然结构相对简单,但往往忽略了行为信号中所蕴含的额外信息,导致模型在解释神经活动与实际行为之间的联系时存在局限。
B. 利用行为先验的建模方法
图2(b)展示了另一类方法,它们在模型中将行为数据作为先验信息引入,例如 pi-VAE、CEBRA 等。这些方法通过对神经数据和行为数据进行联合建模,改善了神经动力学的解释性,但通常需要精心设计专用模块或者复杂的训练策略。
C. 基于特权知识蒸馏的 BLEND 框架
我们的工作正是基于第三类方法(见图2(c)),即在训练阶段利用行为数据作为“特权信息”,通过教师—学生结构实现知识迁移。教师模型在训练时同时接收神经活动和行为信号,从而获得更丰富的表示;而在推理阶段,仅用神经数据的学生模型则能保持较高的性能。与前两类方法相比,BLEND 不仅具备模型无关性,还避免了对复杂模块的依赖,能够更灵活地适应真实场景中行为数据缺失的情况。
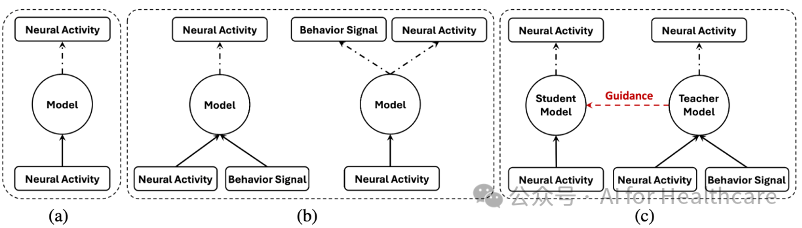
图2: 不同神经群体动力学建模机制的示意图。(a) 仅使用神经群体活动作为输入的神经动力学建模方法。(b) 以行为信息为先验的神经动力学建模方法。 (c) 本工作提出的BLEND框架,它将行为信息视为蒸馏的特权知识。
方法
BLEND 框架基于特权信息学习的思想,采用教师—学生结构,将训练阶段获得的行为数据信息传递给仅依赖神经数据的模型。具体过程分为两个阶段:
A. 教师模型训练阶段
在此阶段,教师模型同时接收神经活动数据和对应的行为信息。为使模型更好地捕捉神经群体的时序动态与行为之间的关联,我们采用了随机掩码的时序重构任务。通过在神经数据中随机屏蔽部分信息,并利用剩余观测数据结合行为信息对被屏蔽部分进行重构,教师模型可以学习到更丰富的表示。训练目标如以下公式所示,该目标旨在最小化屏蔽部分的重构误差,从而确保模型对数据缺失情况具有较高的鲁棒性和预测能力。
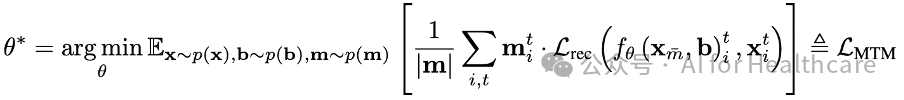
B. 学生模型知识蒸馏阶段
学生模型的目标是在仅使用神经活动数据的前提下,复现教师模型在融合行为信息后所获得的丰富表示。为此,我们设计了一个结合重构损失与知识蒸馏损失的混合训练目标。该目标在保证学生模型能够完成时序数据重构的同时,通过知识蒸馏使得其输出接近教师模型的结果。训练目标如以下公式所示,其中一个平衡系数用于调节两部分损失的贡献。
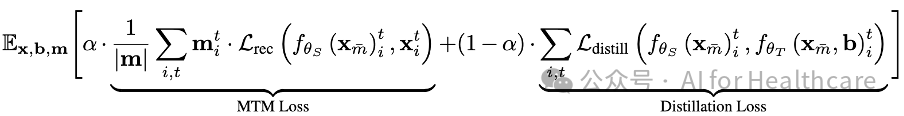
在知识蒸馏过程中,我们探讨了多种策略,以便从不同角度传递教师模型的知识,主要包括:
· 硬蒸馏:直接最小化学生模型与教师模型输出之间的均方误差(MSE),从而使得两者的预测尽可能接近,如以下公式所示。
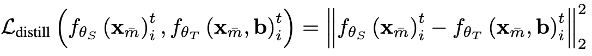
· 软蒸馏:利用温度参数对教师与学生的输出进行软化,通过计算二者概率分布之间的 KL 散度来实现更平滑的知识传递。
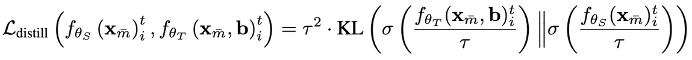
· 特征蒸馏:不局限于输出结果,而是对齐教师和学生在中间层所提取的特征表示,从而实现深层次的知识迁移。
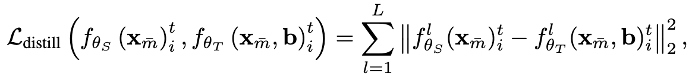
· 相关性蒸馏:强调保持教师模型输出的相关性结构,计算两者相关矩阵之间的差异,确保学生模型能够捕捉到输出内部的关系模式。
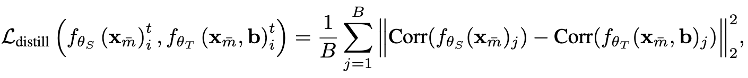
通过上述各阶段和策略的精心设计,BLEND框架在训练阶段利用行为数据获得了更为全面的神经动力学信息,并通过多样化的蒸馏方式传递给学生模型。最终,在推理阶段仅依赖神经数据的学生模型,依然能够展现出优于传统方法的预测性能和鲁棒性。
实验结果
BLEND 在两个基准测试上进行了广泛验证,展示了其卓越的性能:
· NLB'21 基准测试(表1):包括 MC-Maze、MC-RTT 和 Area2-Bump 数据集,测试任务涵盖神经活动预测(Co-bps)、行为解码(Vel-R2)和与PSTHs匹配(PSTH-R2)。结果显示:
-
在MC-Maze数据集上,BLEND将行为解码的Vel-R2提升了 14.6%。
-
在 Area2-Bump 数据集上,行为解码性能提升了 51.8%,PSTH-R2提升了66.6%。
·多模态钙成像数据集(表2):在转录组神经元身份预测任务中,BLEND 将兴奋性/抑制性(EI)神经元预测准确率提升了 5.5%,抑制性神经元子类预测准确率提升了 15.4%。
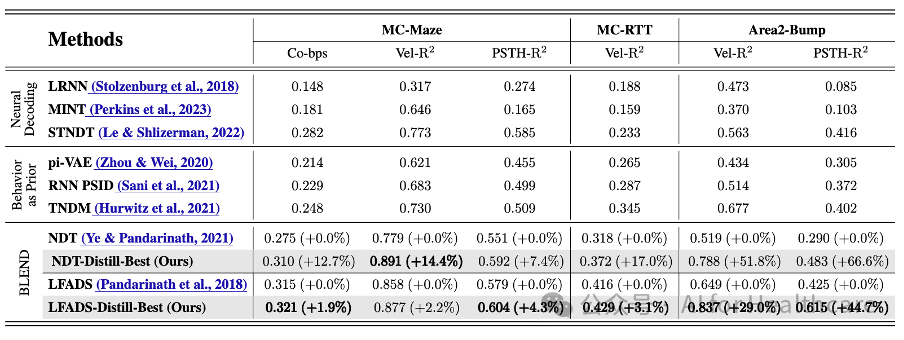
表1.在NLB‘21基准数据集上的BLEND与其他神经元群体活动分析方法的比较。
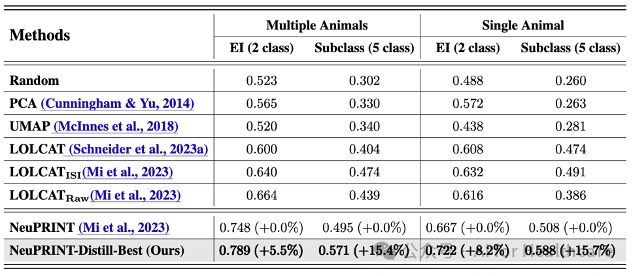
表2. 在多模态钙信号神经活动基准数据集BLEND与SOTA神经元群体活动分析方法的比较。
实验结果表明,通过引入行为特权信息进行知识蒸馏,BLEND 框架能够显著提升模型对神经活动的理解和预测能力。此外,本方法避免了复杂模型设计和强假设限制,具有较好的普适性。未来,我们计划探索更复杂的行为与神经数据融合策略,以及将该方法扩展至非时序或离散行为数据的场景,进一步拓宽在神经科学和相关领域的应用。
模型分析
为了更直观地展示模型的有效性,我们对 MC-Maze 数据集上的行为解码任务进行了定性评估。图3 展示了两组关键可视化结果:
A. 二维手部运动轨迹(图3(a))
基线模型在预测二维轨迹时能够捕捉到整体的 U 形趋势,但在轨迹的底部弯曲部分以及端点处与真实运动轨迹存在明显偏差。相比之下,通过行为特权知识蒸馏训练得到的学生模型,不仅在整体趋势上与真实轨迹保持一致,而且在局部细节(如弯曲程度和终点位置)上具有更高的精度。这说明蒸馏过程有效地将教师模型中融合了行为信息的丰富表示传递给了学生模型,从而提升了对手部运动动态的刻画能力。
B. 一维速度变化曲线(图3(b))
图中分别展示了 X 轴和 Y 轴速度随时间变化的预测结果与真实值的对比。基线模型在两轴上均存在峰值捕捉不足以及预测波动较大的问题,难以准确反映实际运动过程中的速度变化。经过蒸馏后的模型则表现出更高的平滑性和准确性,能够较好地捕捉到速度的起伏和关键转折点,充分体现了模型在理解和解码复杂行为动态方面的优势。
通过上述定性分析,我们可以看出,利用行为特权知识蒸馏不仅在数值指标上带来显著提升,也使模型在直观视觉效果上表现出更高的准确性和鲁棒性。图3 清晰地展示了这一效果,为我们验证 BLEND 框架在行为解码任务中的有效性提供了有力支撑。
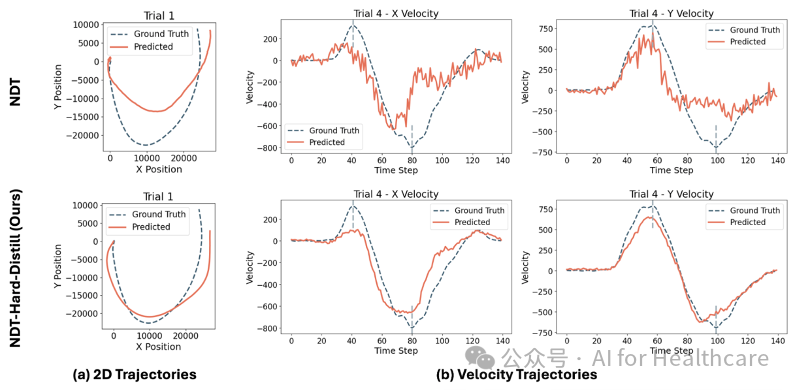
图3. MC-Maze 数据集上行为解码的可视化。 (a) 预测和真实情况2D 手部运动轨迹。(b) X 和 Y 速度的预测和真实值。
结论
本文提出的 BLEND 框架充分利用了训练阶段行为数据作为特权信息,通过教师—学生结构及多种知识蒸馏策略,实现了神经群体动力学建模的显著性能提升。实验结果表明,无论是在神经活动预测、行为解码,还是在神经元身份预测任务上,BLEND 均优于传统仅依赖神经数据的方法,尤其在处理现实场景中行为数据缺失或不完整的情况下,依然能够保持出色的鲁棒性和准确性。
与传统方法相比,BLEND 通过引入行为先验信息,有效克服了复杂模型设计和强假设带来的局限性,为神经数据的深层次表征学习提供了新的思路。同时,该框架具有良好的模型无关性,可便捷嵌入现有神经动力学建模系统中,进一步拓宽了其在计算神经科学及其他领域的应用前景
未来,我们计划探索更复杂的行为与神经数据融合策略,包括将方法扩展到非时序或离散行为数据的情景,并在更大规模和多模态数据集上进行验证。此外,将 BLEND 推广至医疗影像分析、情感识别等其他特权知识蒸馏问题,也将为相关领域带来新的突破。总体而言,BLEND 不仅丰富了神经群体动力学建模的理论与方法体系,也为实际应用中如何充分利用辅助信息提升模型性能提供了有力支持。
更多详情,请点击【阅读原文】访问原论文。
参考文献
Guo, Zhengrui, et al. "BLEND: Behavior-guided Neural Population Dynamics Modeling via Privileged Knowledge Distillation." arXiv preprint arXiv:2410.13872 (2024).



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











