






核心异同点
- 并行策略
- Megatron-LM
- 核心:以 张量并行(Tensor Parallelism) 和 流水线并行(Pipeline Parallelism) 为主,结合数据并行。
- 张量并行通过切分模型层(如注意力头、MLP块)到不同设备,利用NVLink高速通信提升效率。
- 流水线并行将不同层分配到不同设备,通过P2P通信协调。
- DeepSpeed
- 核心:ZeRO优化技术(Zero Redundancy Optimizer),通过分片数据并行消除冗余内存占用。
- 支持3D并行(数据并行、模型并行、流水线并行)。
- 针对长序列训练引入 序列并行(Sequence Parallelism) ,优化通信效率。
- 差异:
- Megatron-LM更依赖硬件加速(如NVLink),而DeepSpeed通过ZeRO优化显存。
- 在长序列场景下,DeepSpeed的通信复杂度更低(O(1) vs Megatron-LM的O(N))。
- 内存优化
- Megatron-LM:
- 通过张量切片(如切分QKV矩阵)降低单卡显存需求,但需频繁通信。
- DeepSpeed:
- ZeRO技术将模型状态(参数、梯度、优化器状态)分片到不同设备,显著降低内存占用。
- ZeRO-Infinity支持将部分数据卸载到CPU或NVMe存储,进一步扩展模型容量。
- 差异:DeepSpeed内存优化更彻底,适合训练超大模型(如万亿参数)。
- 通信效率
- Megatron-LM:
- 使用All-Gather和Reduce-Scatter操作,通信量随序列长度线性增长。
- DeepSpeed:
- 序列并行采用All-to-All通信,通信复杂度与设备数量无关,更适合长序列。
- 例如,处理序列长度N时,DeepSpeed通信量为4Nh/P,而Megatron-LM为4Nh(P为设备数)。
- 适用场景
- Megatron-LM:
- 适合中短序列、对计算速度要求高的场景,尤其在NVIDIA GPU集群中表现优异。
- 代表应用:GPT-3、BLOOM。
- DeepSpeed:
- 适合极长序列(如百万Token)和超大模型训练(如万亿参数),内存利用率更高。
- 代表应用:DeepSpeed-Ulysses、MT-530B
优劣对比
| 维度 | Megatron-LM | DeepSpeed |
|---|---|---|
| 并行策略 | 张量并行为主,计算效率高 | ZeRO分片数据并行,显存优化强 |
| 长序列支持 | 通信量随序列增长,效率较低 | 通信复杂度恒定,支持百万Token序列 |
| 硬件适配 | 深度优化NVIDIA GPU(CUDA/NVLink) | 支持多平台(如AMD GPU、CPU卸载) |
| 代码灵活性 | 结构简单,易于修改底层 | 封装较深,定制复杂 |
| 模型转换 | 输出Checkpoint转换麻烦 | 与Hugging Face等框架集成较好 |
| 训练速度 | 混合精度优化好,速度更快 | 通信优化后速度接近或反超(如强缩放场景) |
| 社区生态 | 受工业界欢迎(阿里、vivo等) | 开源影响力大,用户广泛(Meta、Intel等) |
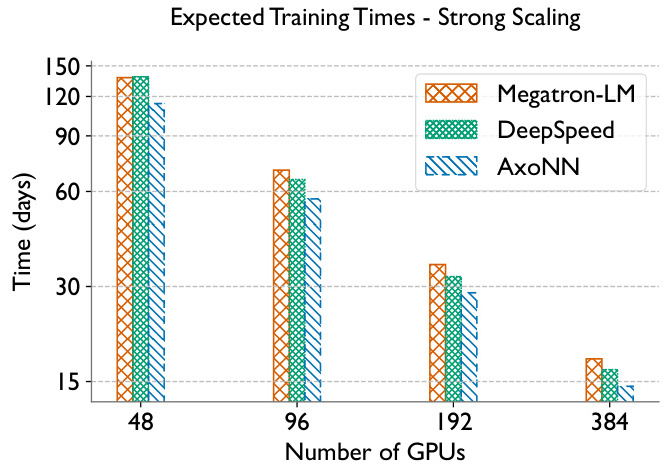
典型性能对比
- 训练时间:在384 GPU规模下,DeepSpeed的预期训练时间比Megatron-LM缩短约30%。
- 长序列吞吐量:相同序列长度下,DeepSpeed-Ulysses的吞吐量是Megatron-LM的2.5倍。
- 显存占用:ZeRO-3可将显存需求降低至1/P(P为设备数),而Megatron-LM需保持完整参数副本。
总结
- 选择Megatron-LM:若追求计算速度、硬件为NVIDIA集群且模型规模适中(如百亿参数)。
- 选择DeepSpeed:若需训练超大模型(如万亿参数)、处理极长序列或希望最大化显存利用率。
- 混合使用:实际场景中常结合Megatron-LM的张量并行与DeepSpeed的ZeRO(如Megatron-DeepSpeed),以平衡速度与内存效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











